Jina AI 模型
检索管道各阶段的先进模型
Jina 模型专为检索而打造,以更小的体量实现更优的准确性与速度,性能可超越体量为其 5 倍的模型。它支持多语言、多模态,适用于文本、图像、音频和视频,如今还可在 Elasticsearch 中原生使用。

认识 Jina AI 模型
我们的前沿模型为高质量企业搜索和检索增强生成(RAG)系统提供搜索基础。



设计紧凑,结果精准
通过一个 API,即可从原始数据获得高精度结果。

无论您在哪里构建,都可以使用 Jina 模型
从完全托管到自托管,Jina 模型能完美适配你数据所在的任何环境。选择最适合您的访问路径。



我们的研究




加入我们的开源社区
Jina 的模型采用开放权重,可在 Hugging Face 上免费获取,每月下载量达数百万次。其代码库也已在 GitHub 上公开。社区成员还可直接与我们的开发人员交流。




常见问题
Jina 模型是开源的、前沿的检索 AI 模型。它们包括用于向量的嵌入模型、用于提高精确度的重排序器,以及用于从 URL 和文档中提取和构建内容的读取器。
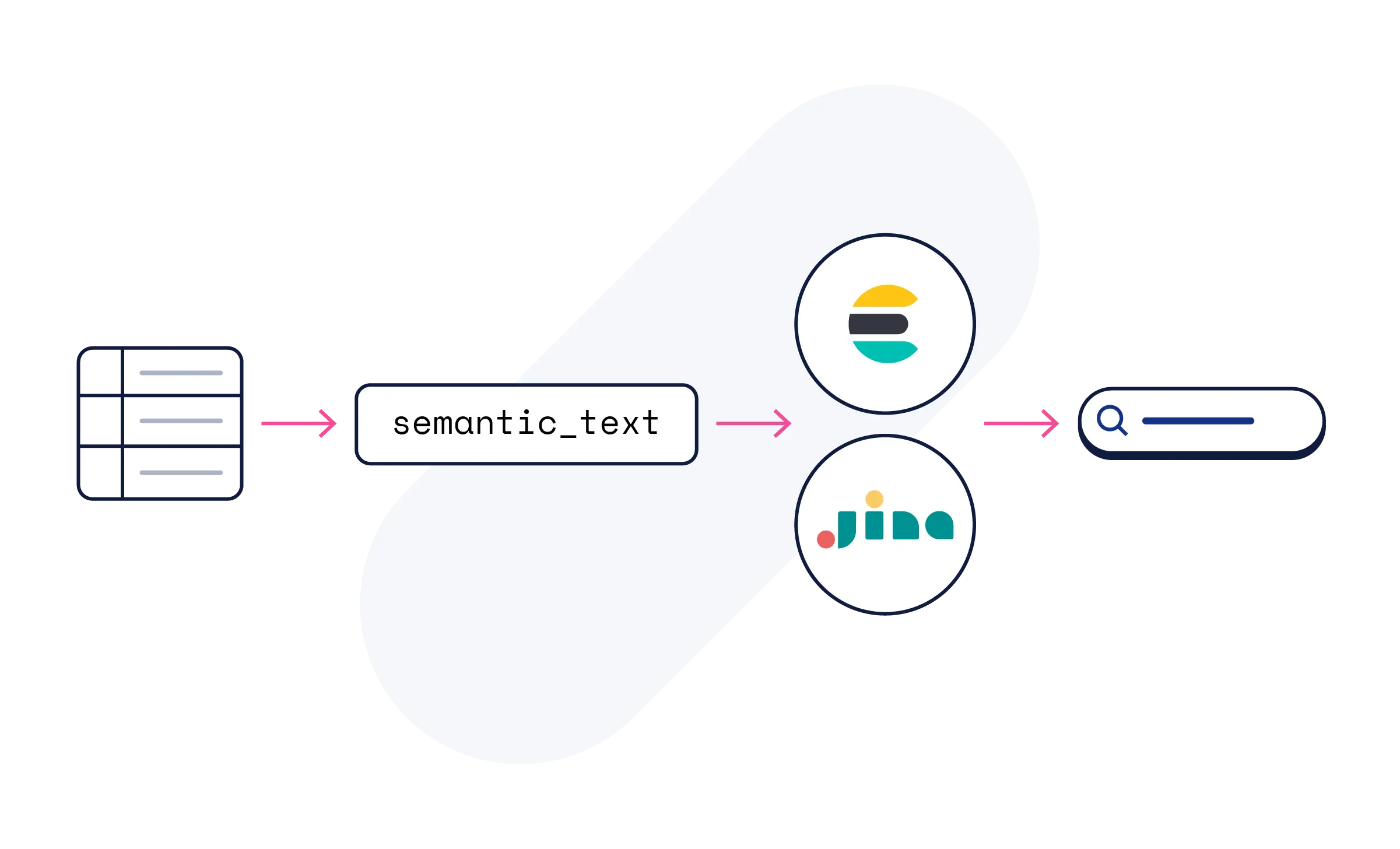
不需要。使用 Elasticsearch 的 semantic_text 字段,AI 处理会自动完成。Jina 模型可让您的内容具备语义搜索能力,无需模型配置,也无需机器学习专业知识。
Jina 模型可在 Elastic Cloud 的 Elastic Inference Service 上使用,所有试用版均已包含。您可以从 semantic_text 开始,或访问各模型子页面,查看代码示例、API 参考和教程。
我们最新的 v5-text(nano/small)支持 32K 上下文、Matryoshka 维度和最新架构;此外,Jina-embeddings-v3 以及 Reranker v2 和 v3 也都可在 Elastic Inference Service 上使用。
Jina-embeddings-v5-text 支持 30 多种语言——使用一种语言发起查询,也能找到以另一种语言编写的相关内容,无需翻译管道。
ELSER 覆盖英文语义搜索。Jina 则以领先的准确率将多语言覆盖扩展至 30 多种语言——两者都可在 Elasticsearch 的混合搜索框架中运行。
不需要。Elastic Inference Service 上的 Jina 搜索模型面向所有 Elastic Cloud 用户开放,采用按量计费模式。无需单独许可证、订阅或 API 密钥。
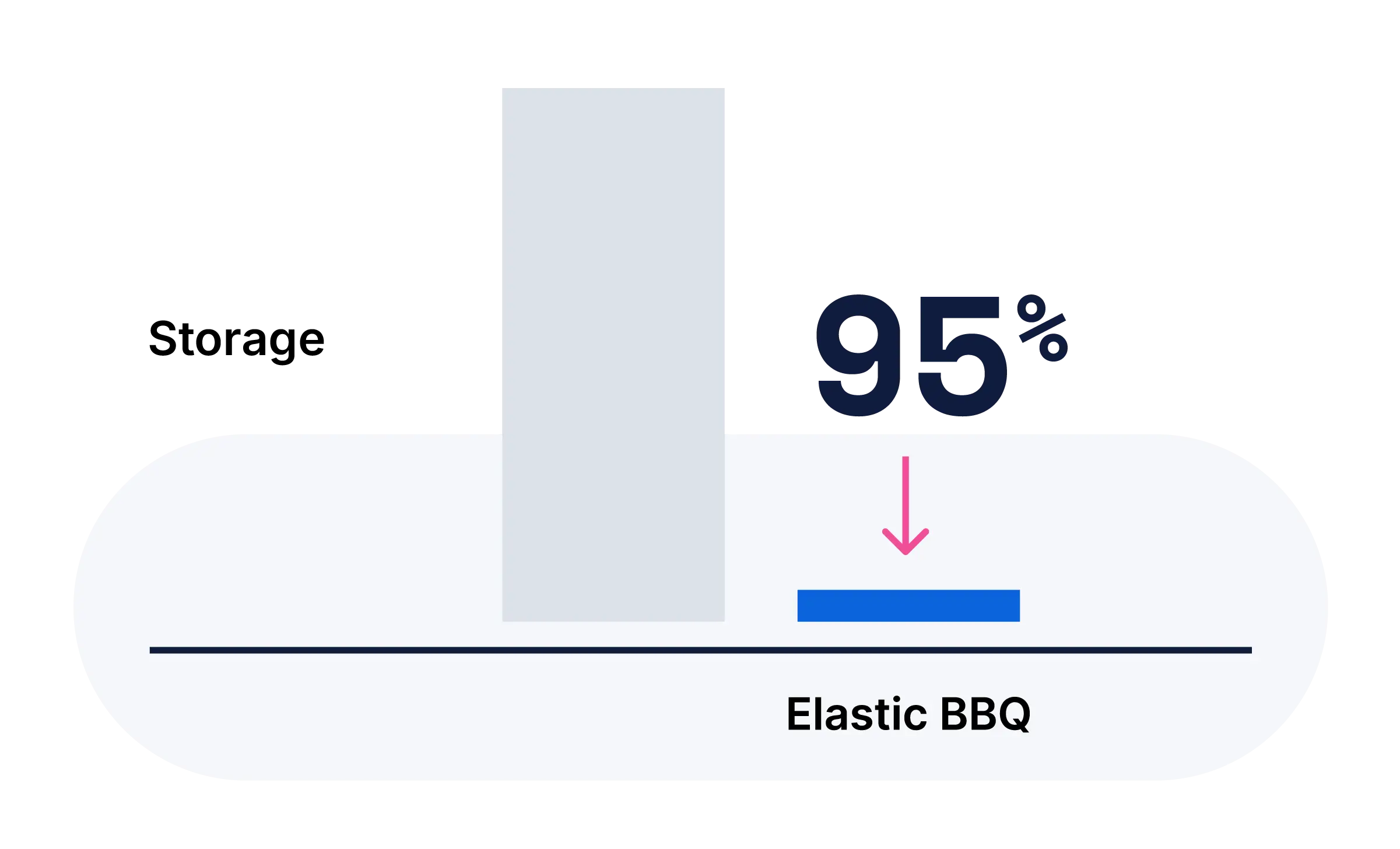
向量数据库页面介绍了如何大规模存储和搜索向量;本页面则介绍了生成和重排序这些向量的 AI 模型。两者结合,涵盖存储、计算和应用。

