

Elasticsearch: Búsqueda en bases de datos y sistemas empresariales
Visión general
Introducción a Elasticsearch
Elasticsearch ofrece una variedad de técnicas de búsqueda, comenzando con BM25, el estándar de la industria para la búsqueda textual. También ofrece búsqueda semántica impulsada por modelos de AI, lo que mejora los resultados según el contexto y la intención.
En esta guía, aprenderás a sincronizar datos de una base de datos externa con Elasticsearch y a usar la búsqueda semántica para buscar fácilmente en tu base de datos.
Incorporar tus datos
Cómo ingestar y enriquecer los datos para la búsqueda
Elasticsearch incluye una amplia variedad de capacidades de ingesta de datos que ayudan a resolver tus desafíos empresariales. Echa un vistazo a este webinar para:
- Aprender a incorporar datos dispares en un solo lugar para crear experiencias de búsqueda.
- Comprender qué herramientas usar para tus tipos específicos de datos, incluidos Open Crawler, el catálogo de conectores, los pipelines de inferencia de ML y datos, y más.
- Ver demostraciones en vivo con sets de datos de atención al cliente.
Crear un proyecto de Elastic Cloud
Comienza con una prueba de 14 días. Una vez que vayas a cloud.elastic.co y crees una cuenta, sigue los pasos para lanzar tu primer proyecto de Elasticsearch Serverless.
Para empezar, selecciona Elasticsearch.
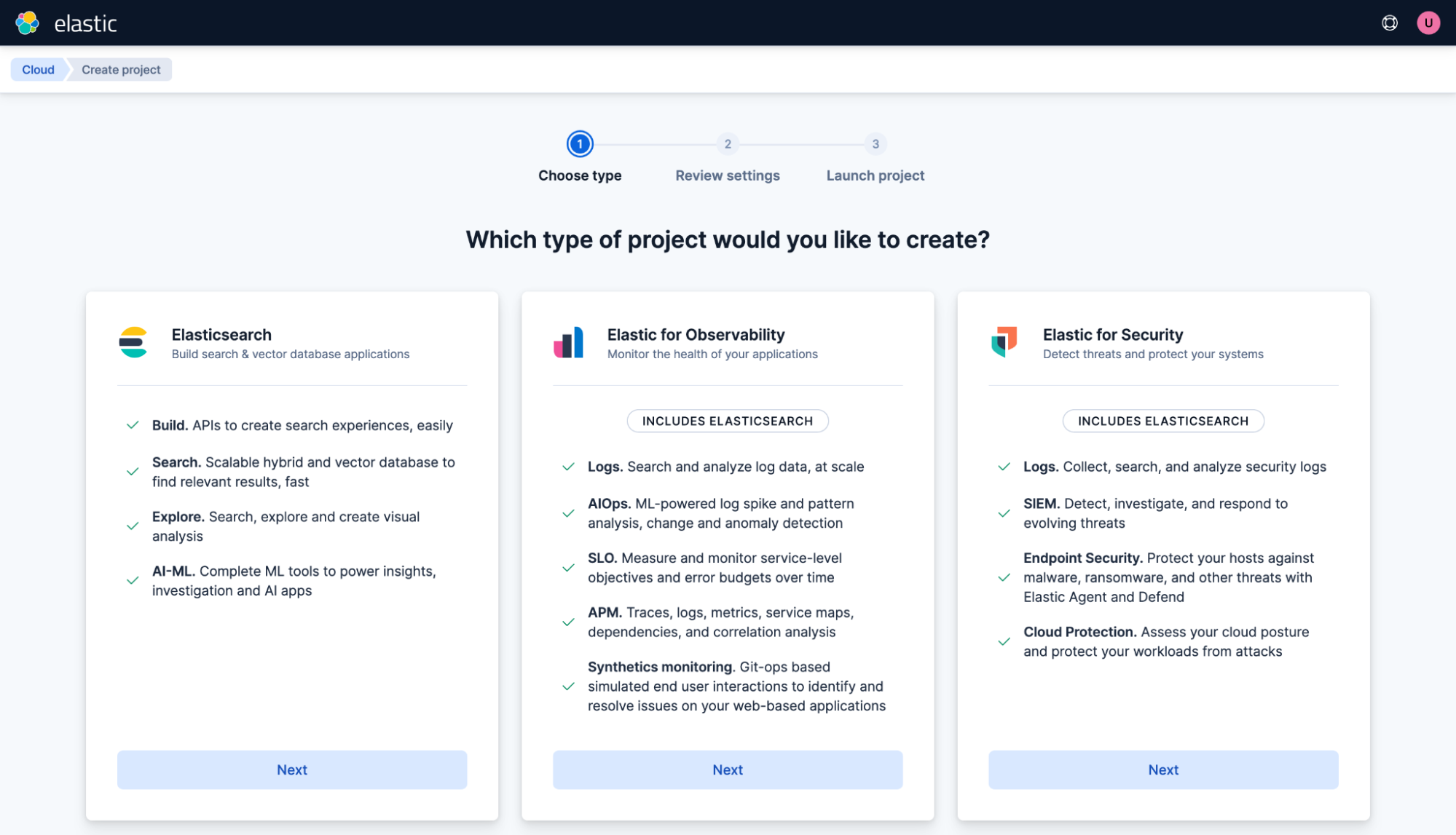
Crea un proyecto para un propósito general. Llámalo "Mi proyecto" y haz clic en Crear proyecto.
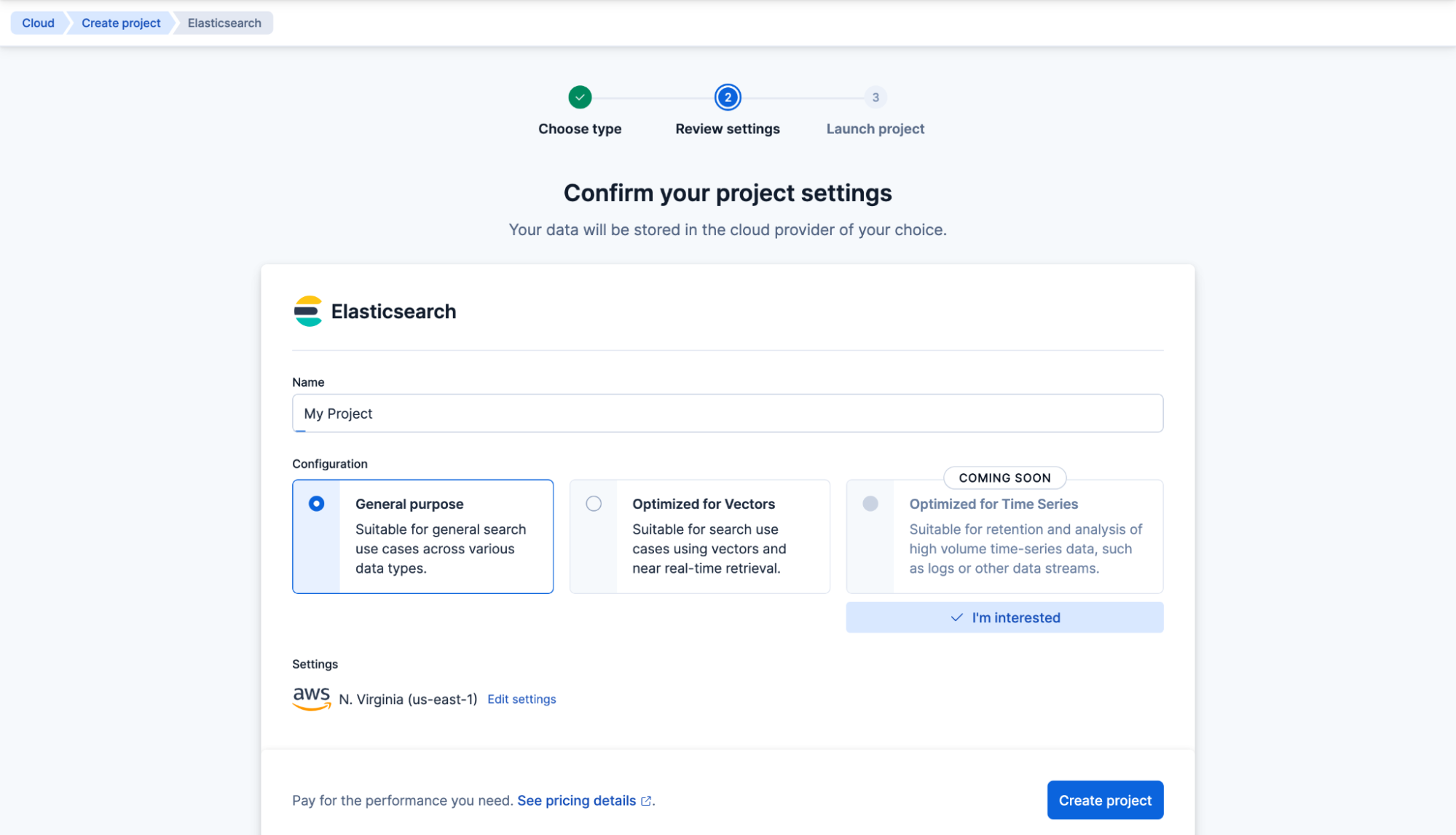
Ahora se creará tu proyecto de Elasticsearch Serverless. A continuación, crea tu primer índice de Elasticsearch y asígnale el nombre "my-index". Haz clic en Crear mi índice.
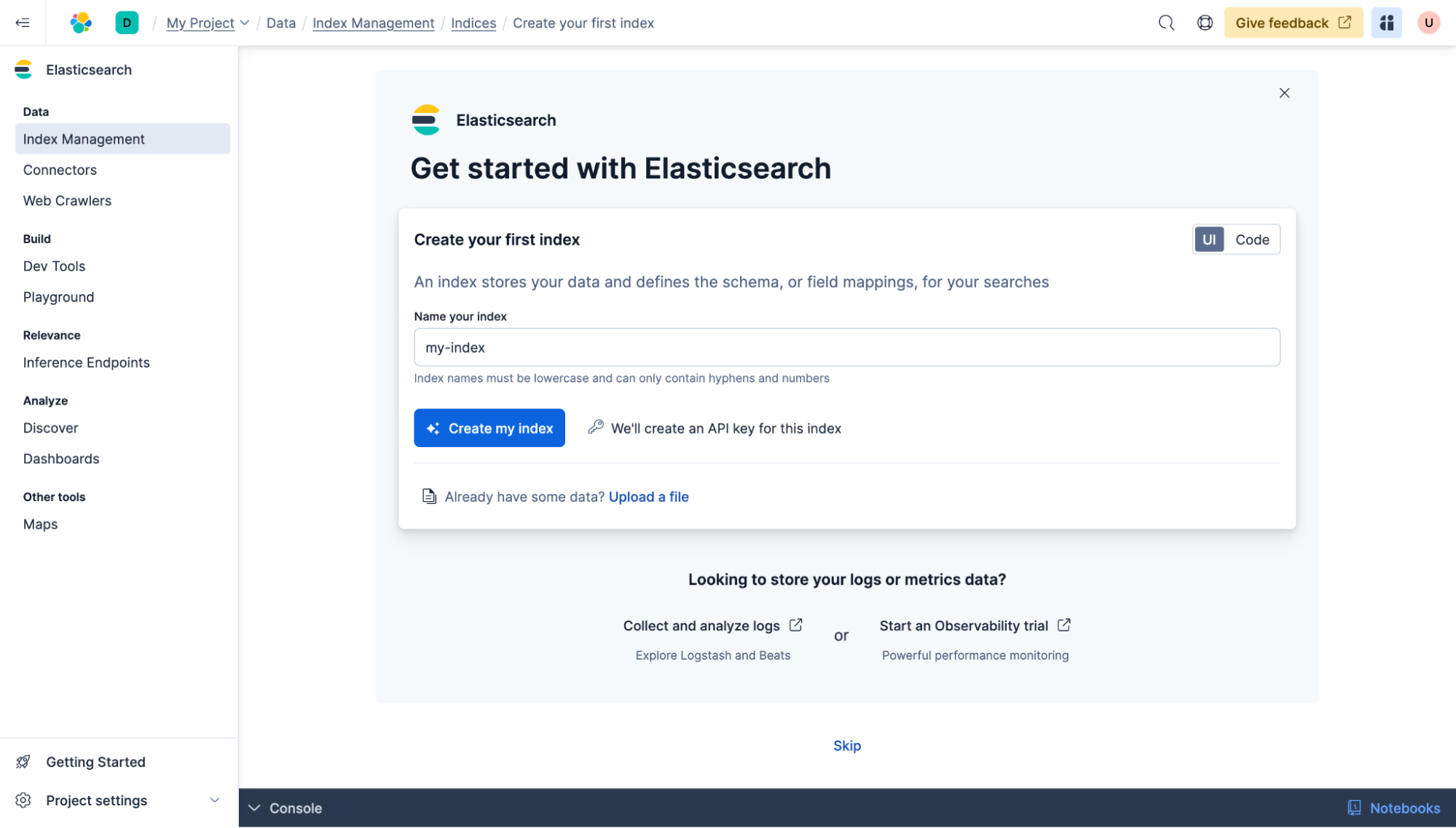
Luego puedes agregar fuentes de datos de terceros a Elasticsearch. En este ejemplo, tenemos una base de datos de MongoDB con unos 150 000 títulos de videojuegos y las columnas "id", "name", "description" y "date". Sincronizaremos esta base de datos con Elasticsearch y, como paso adicional, le agregaremos capacidades de búsqueda semántica.
Vamos a crear un mapping de indexación básico con los mismos nombres de campo y el "description_semantic" adicional que contendrá nuestros vectores para la búsqueda semántica. Abre Herramientas de desarrollo y pega el siguiente comando para actualizar tus mappings de indexación:
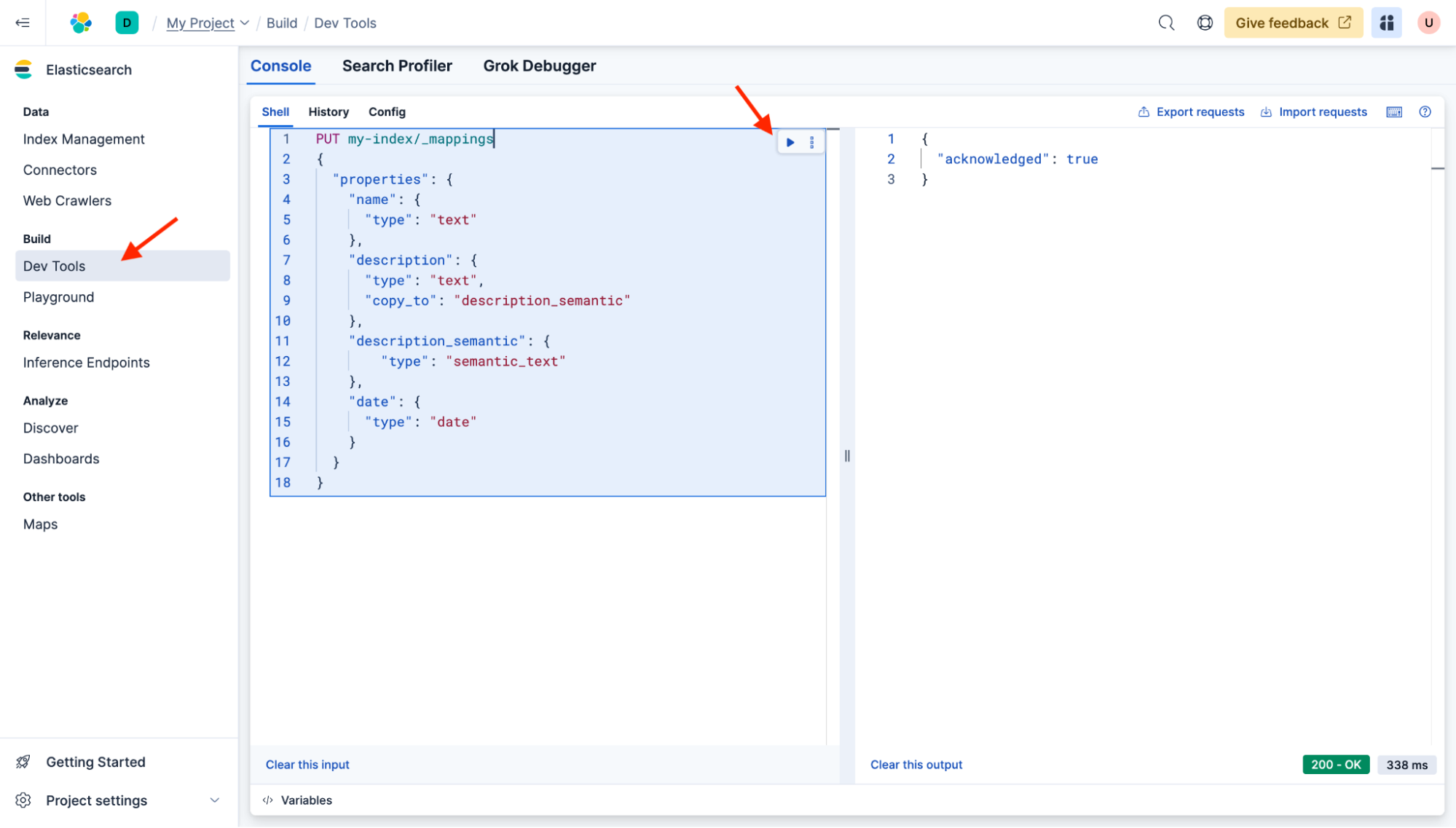
PUT my-index/_mappings
{
"properties": {
"name": {
"type": "text"
},
"description": {
"type": "text",
"copy_to": "description_semantic"
},
"description_semantic": {
"type": "semantic_text"
},
"date": {
"type": "date"
}
}
}
Extracción de datos de una base de datos actual
Estás listo para conectarte a una base de datos actual. Haz clic en Conectores y en + Conector autoadministrado.
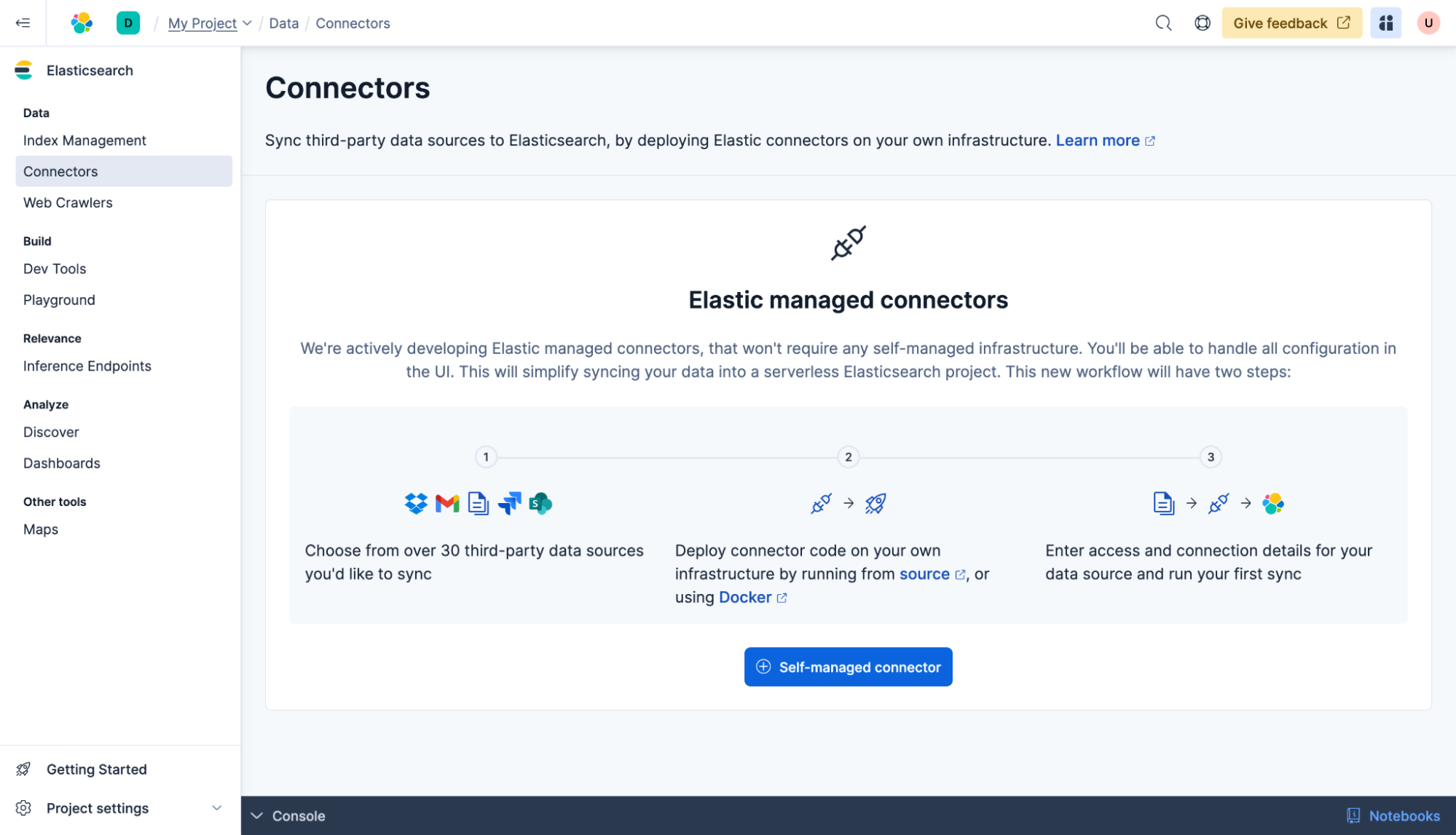
Esta guía usará una base de datos de MongoDB. Selecciona MongoDB en la lista Tipo de conector.
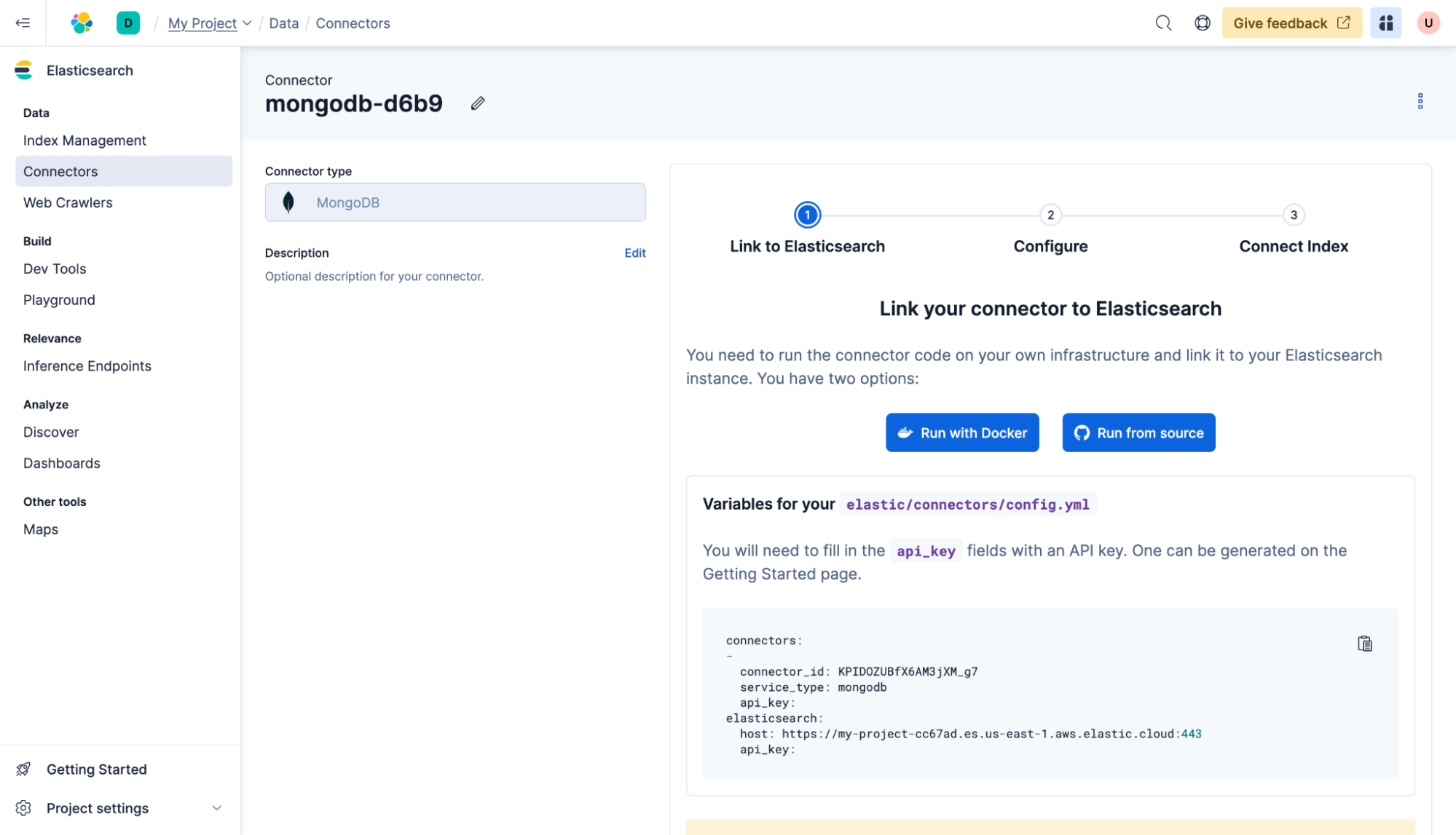
Sigue las instrucciones para implementar un conector autohospedado mediante Docker. Tendrás que crear un archivo config.yml. Ten en cuenta que api_key tanto en el conector como en elasticsearch es igual. Por ejemplo:
connectors:
-
connector_id: KPIDOZUBfX6AM3jXM_g7
service_type: mongodb
api_key: RGZMUU9KVUJmWDZBTTNqWFRQano6R3RRb01jR2kxRkNqWTA5eGtSa3NFZw==
elasticsearch:
host: https://my-project-cc67ad.es.us-east-1.aws.elastic.cloud:443
api_key: RGZMUU9KVUJmWDZBTTNqWFRQano6R3RRb01jR2kxRkNqWTA5eGtSa3NFZw==
A continuación, inicia el conector autohospedado mediante:
docker run -v "./connectors-config:/config" --tty --rm docker.elastic.co/enterprise-search/elastic-connectors:8.17.0 /app/bin/elastic-ingest -c /config/config.yml
A continuación, agrega la configuración a tu base de datos de MongoDB y haz clic en Siguiente.
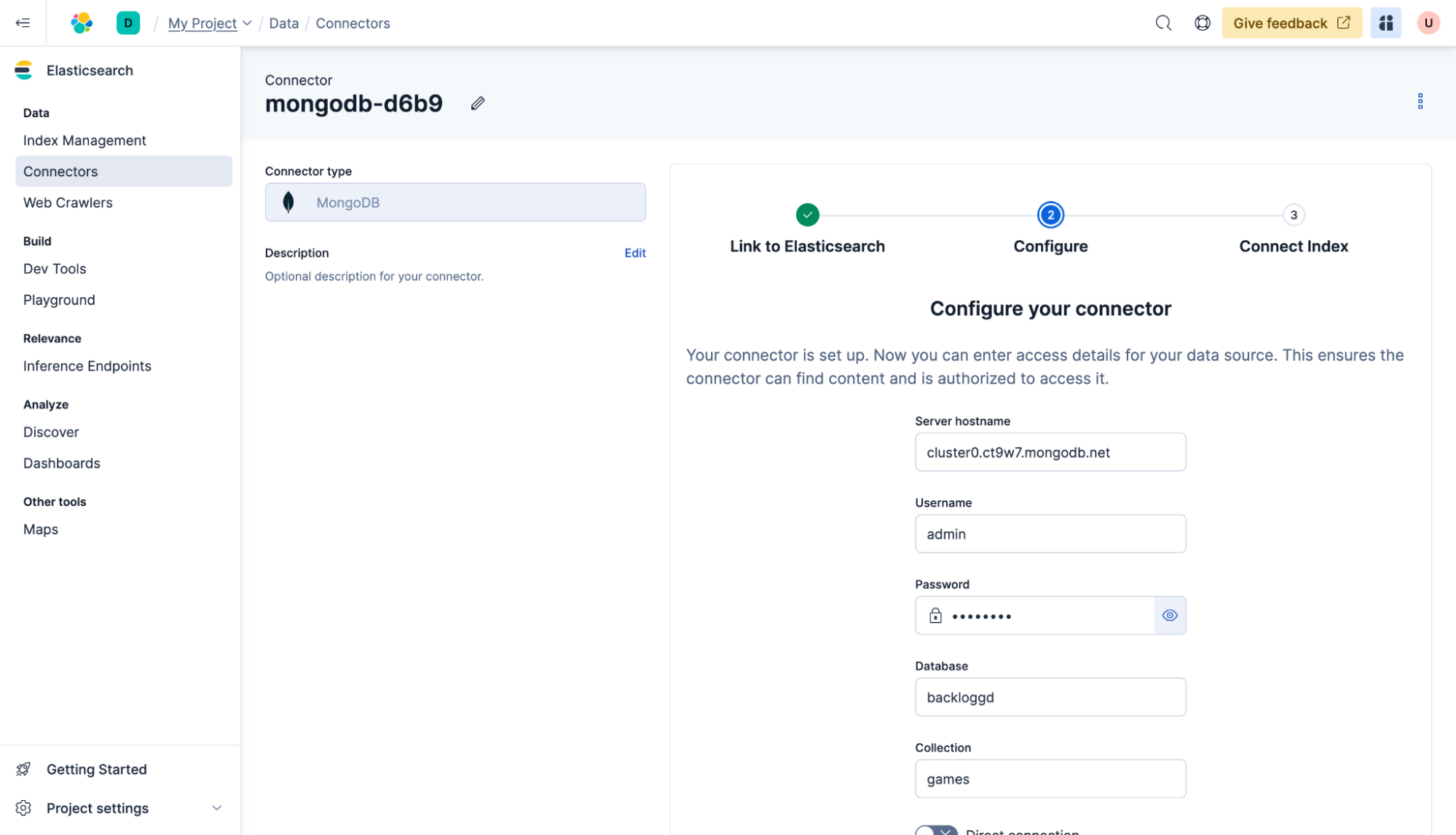
Selecciona el índice con el que se deben sincronizar los datos; en este caso, es "my-index", el índice que creamos antes. Haz clic en Sincronizar.
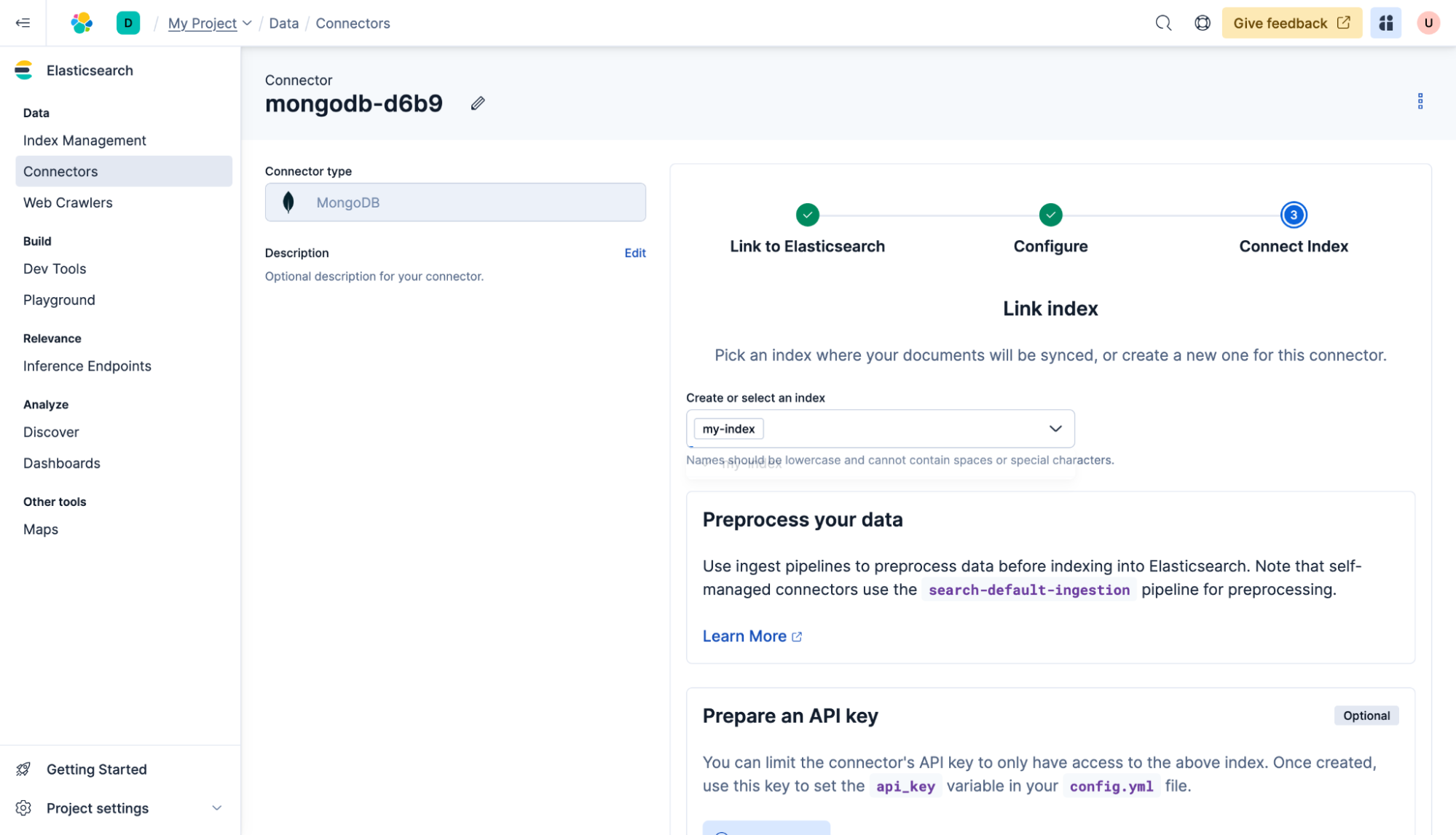
¡Eso es todo! El conector atravesará la base de datos y sincronizará los documentos con "my-index." La página principal de conectores mostrará el estado actual.
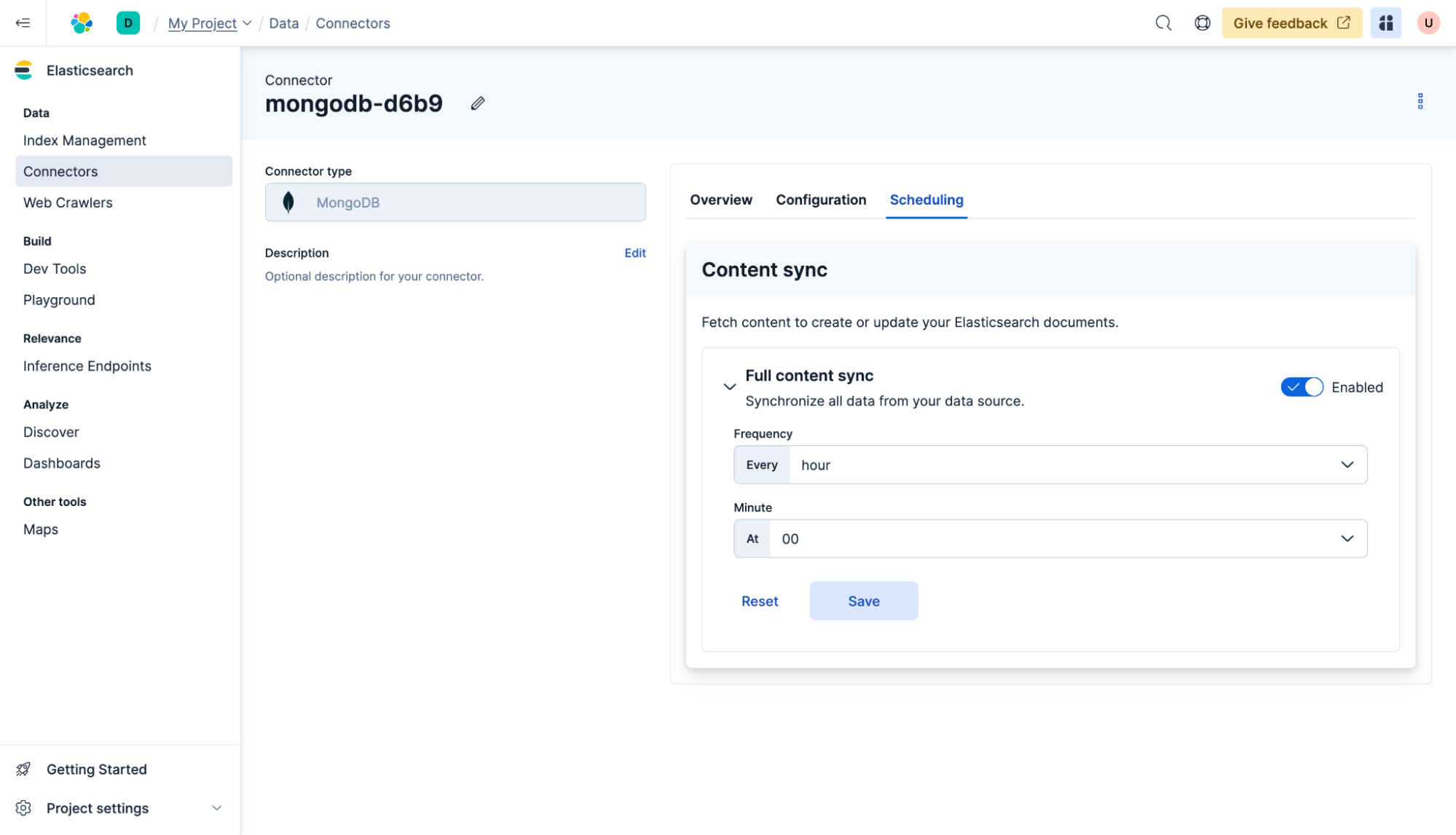
Los conectores también se pueden configurar para sincronizar periódicamente la base de datos con Elasticsearch. Para hacerlo, haz clic en el conector y luego, en Programación, selecciona cada hora y haz clic en Guardar. Ahora el contenido se sincronizará al inicio de cada hora, siempre que el conector autohospedado esté en funcionamiento.
Trabajar con Elasticsearch
Consultando datos
Ahora viene la parte divertida. Ve a Crear > Herramientas de desarrollo (la misma sección que usamos para actualizar los mappings de indexación) y envía la siguiente consulta que realizará una búsqueda de texto en los campos "nombre" y "descripción":
GET my-index/_search
{
"query": {
"multi_match": {
"query": "adventure game on a desert island",
"fields": [
"name",
"description"
]
}
}
}
Dado que el índice ahora tiene un campo semantic_text, puedes consultarlo de la siguiente manera:
GET my-index/_search
{
"query": {
"semantic": {
"field": "description_semantic",
"query": "game about ghosts in medieval times"
}
}
}
¡Acabas de aprender a sincronizar datos de una base de datos externa a Elasticsearch y a agregar una búsqueda semántica!
Pasos siguientes
Gracias por tomarte el tiempo de aprender cómo crear tu primera consulta de búsqueda con Python en Elastic Cloud. A medida que inicias tu recorrido con Elastic, debes comprender algunos componentes operativos, de seguridad y de datos que deberías gestionar como usuario al desplegarlo en todo el entorno.
¿Listo para comenzar? Activa una prueba gratuita de 14 días en Elastic Cloud o prueba estos aprendizajes prácticos de 15 minutos en Search AI 101.