

Observabilidade do LLM
Monitore e otimize o desempenho, o custo, a segurança e a confiabilidade da IA
Obtenha uma visão geral completa com painéis de controle rápidos
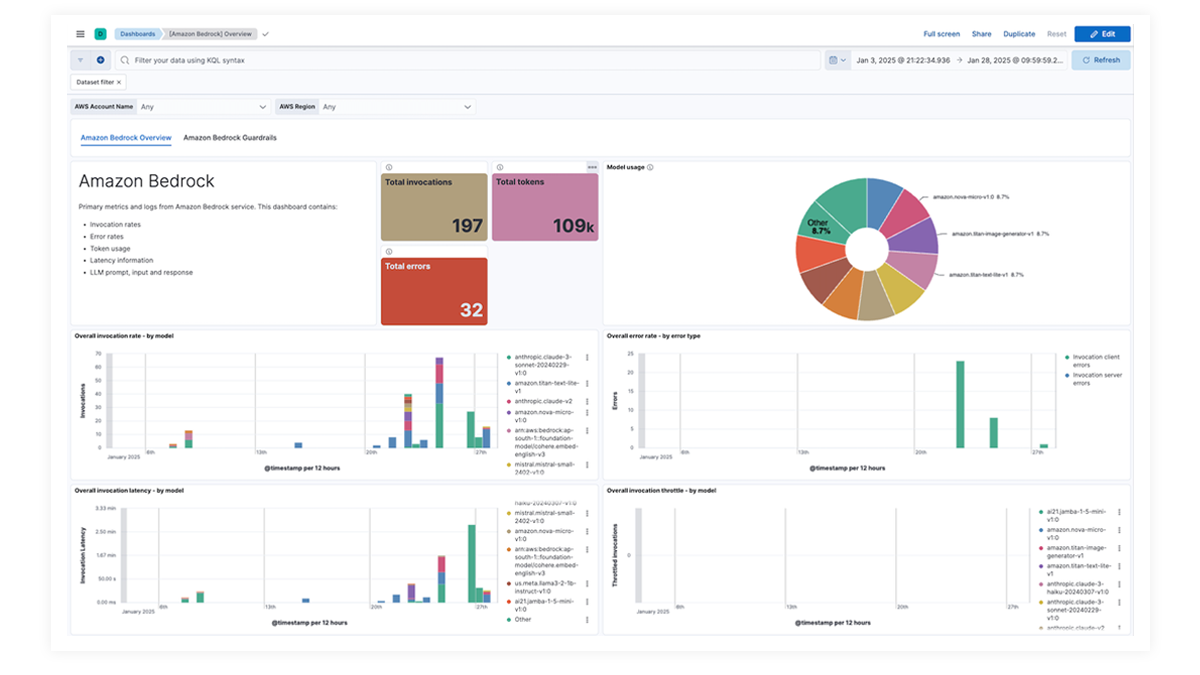
Dashboards pré-criados para OpenAI, AWS Bedrock, Azure OpenAI e Google Vertex AI oferecem insights abrangentes sobre contagens de invocações, taxas de erro, latência, métricas de utilização e uso de tokens, permitindo que os SREs identifiquem e resolvam gargalos de desempenho, otimizem a utilização de recursos e mantenham a confiabilidade do sistema.
Desempenho lento? Identifique as causas raiz
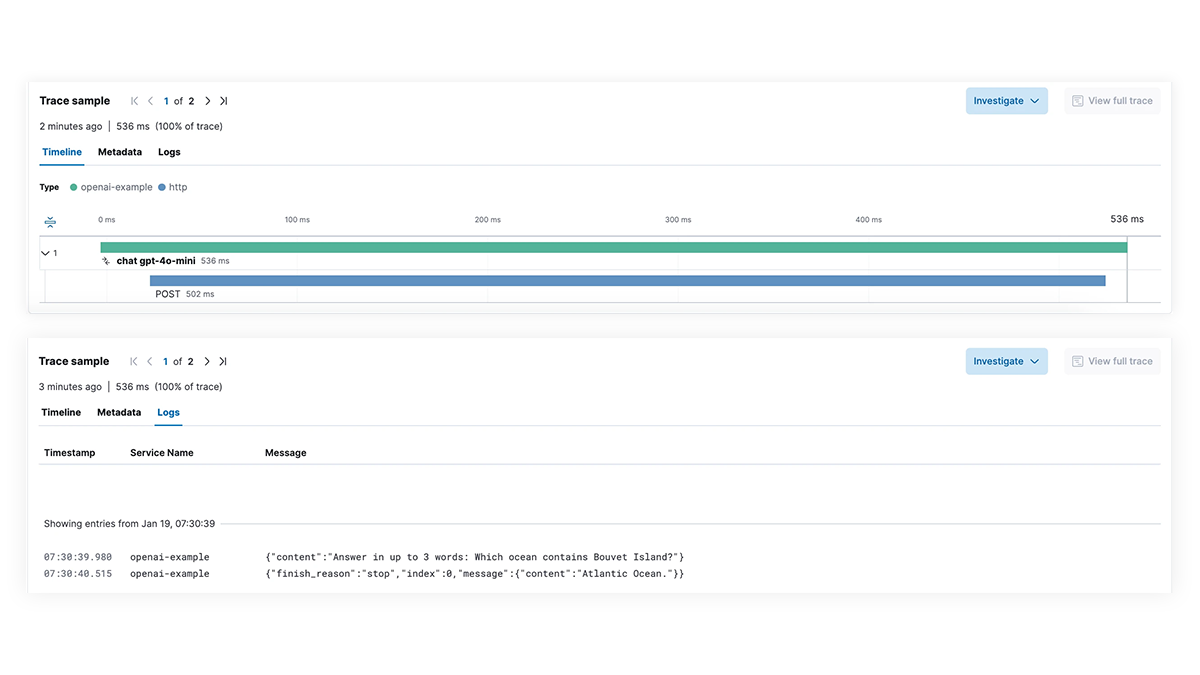
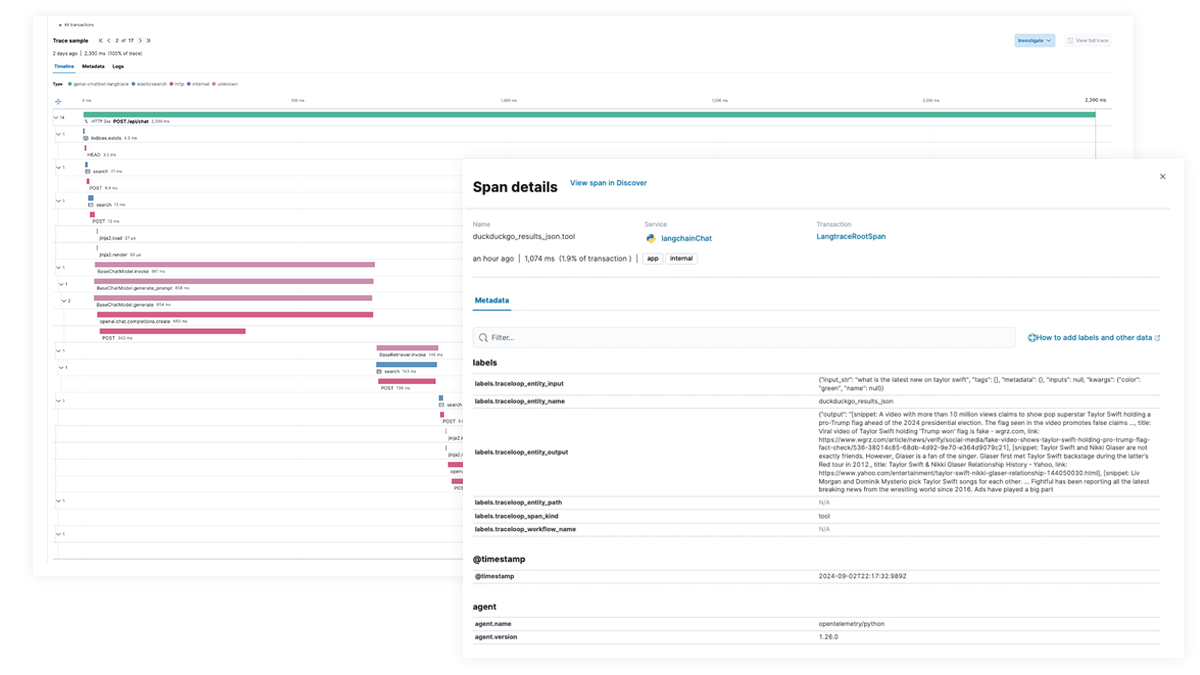
Obtenha visibilidade total de cada etapa do caminho de execução do LLM para aplicativos que integram recursos de IA generativa. Habilite uma depuração mais profunda com rastreamento de ponta a ponta, mapeamento de dependências de serviço e visibilidade de solicitações do LangChain, chamadas LLM com falha e interações de serviço externo. Solucione rapidamente as falhas e os picos de latência para garantir o desempenho ideal.
Preocupações com a segurança da IA? Obtenha visibilidade das solicitações e respostas
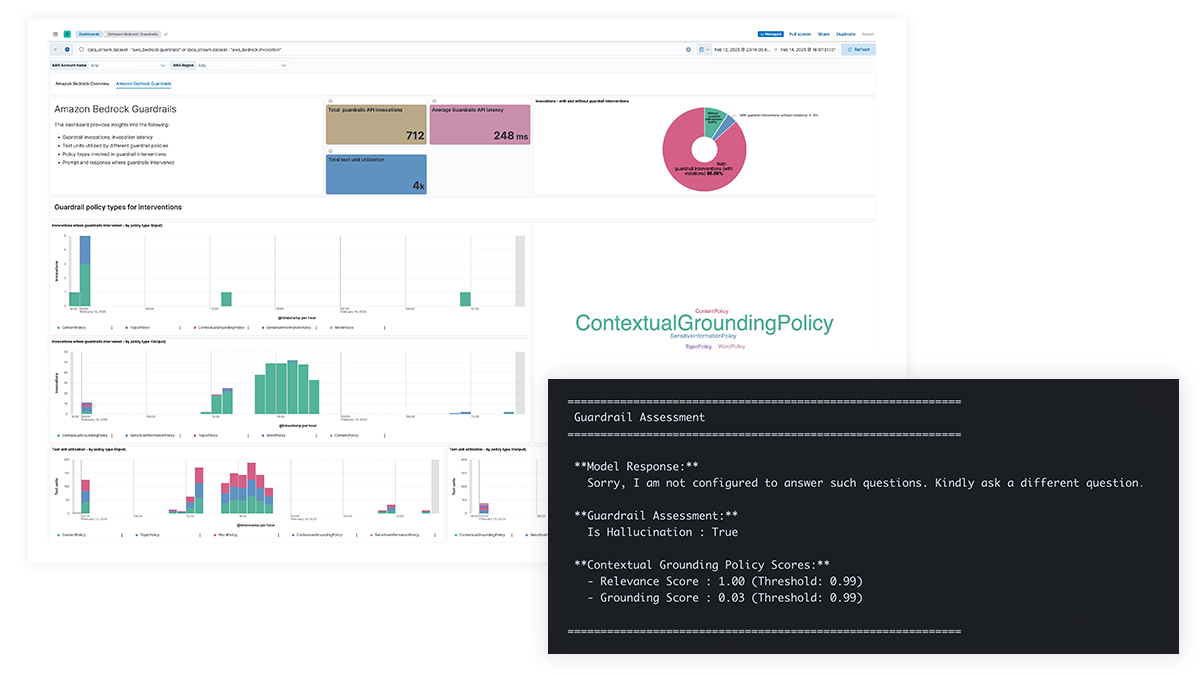
Obtenha transparência sobre os prompts e respostas do LLM para proteger contra vazamentos de dados de informações confidenciais, conteúdo prejudicial ou indesejável e questões éticas, bem como abordar erros factuais, vieses e alucinações. O suporte para o Amazon Bedrock Guardrails e a filtragem de conteúdo para o Azure OpenAI permitem intervenções baseadas em políticas e fornecem uma base contextual para aprimorar a precisão do modelo.
Problemas para rastrear custos? Veja os detalhamentos de uso por modelo
As organizações precisam de visibilidade sobre o uso de tokens, consultas de alto custo e chamadas de API, estruturas de prompt ineficientes e outras anomalias de custo para otimizar os gastos com LLM. O Elastic fornece insights para modelos multimodais, incluindo texto, vídeo e imagens, permitindo que as equipes monitorem e gerenciem os custos do LLM de forma eficaz.

Comece com a observabilidade do LLM
ETAPA 2: Dashboards instantâneos — disponíveis imediatamente em segundos
ETAPA 3: Crie alertas — transforme dados em ações
Visibilidade para apps GenAI
Use o Elastic para obter insights completos sobre aplicativos de IA por meio de bibliotecas de rastreamento de terceiros, bem como visibilidade pronta para uso em modelos hospedados por todos os principais serviços de LLM.












LLM observability dashboard gallery
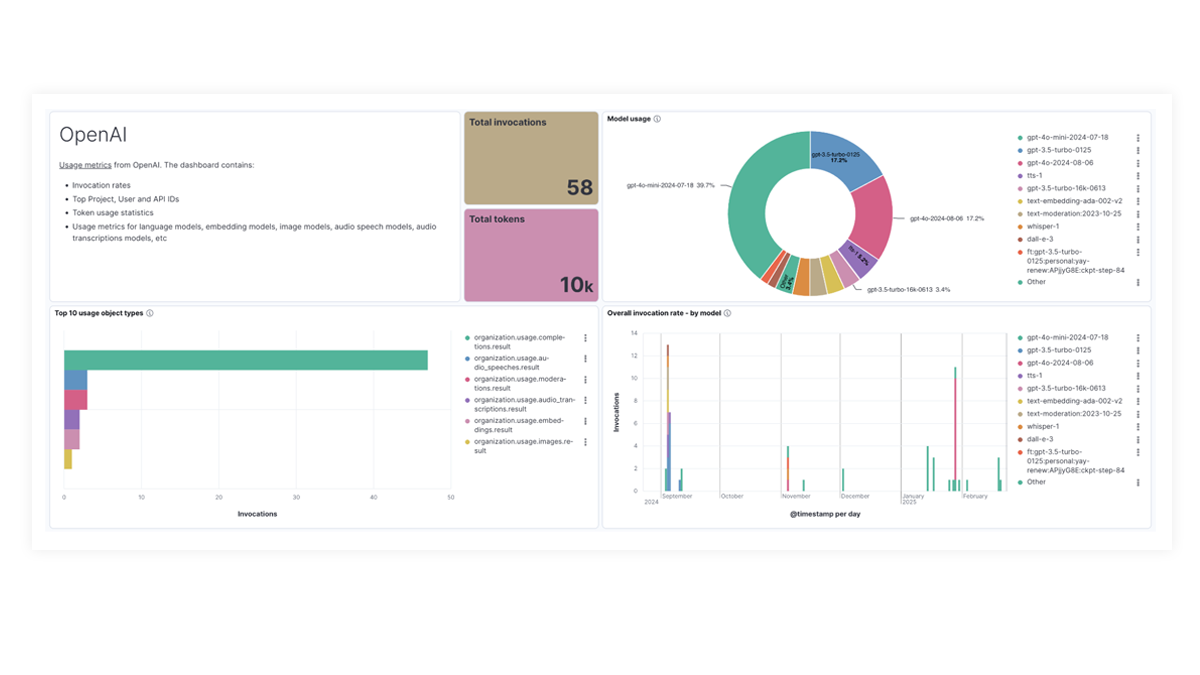
The OpenAI integration for Elastic Observability includes prebuilt dashboards and metrics so you can effectively track and monitor OpenAI model usage, including GPT-4o and DALL·E.
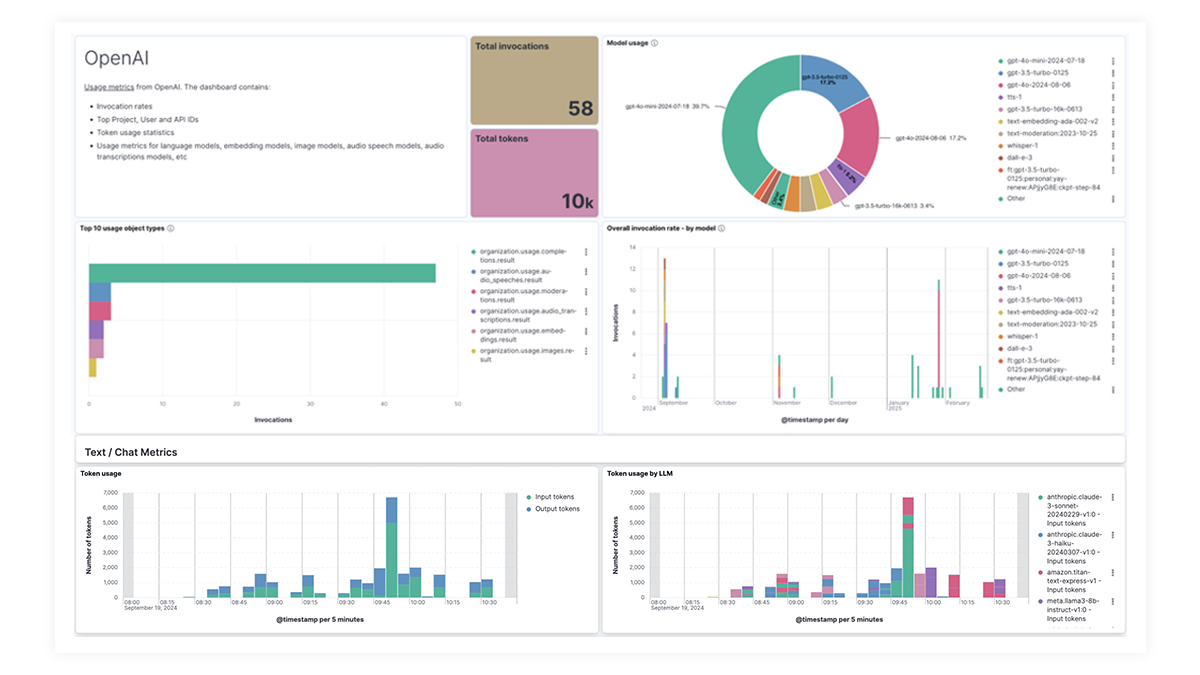
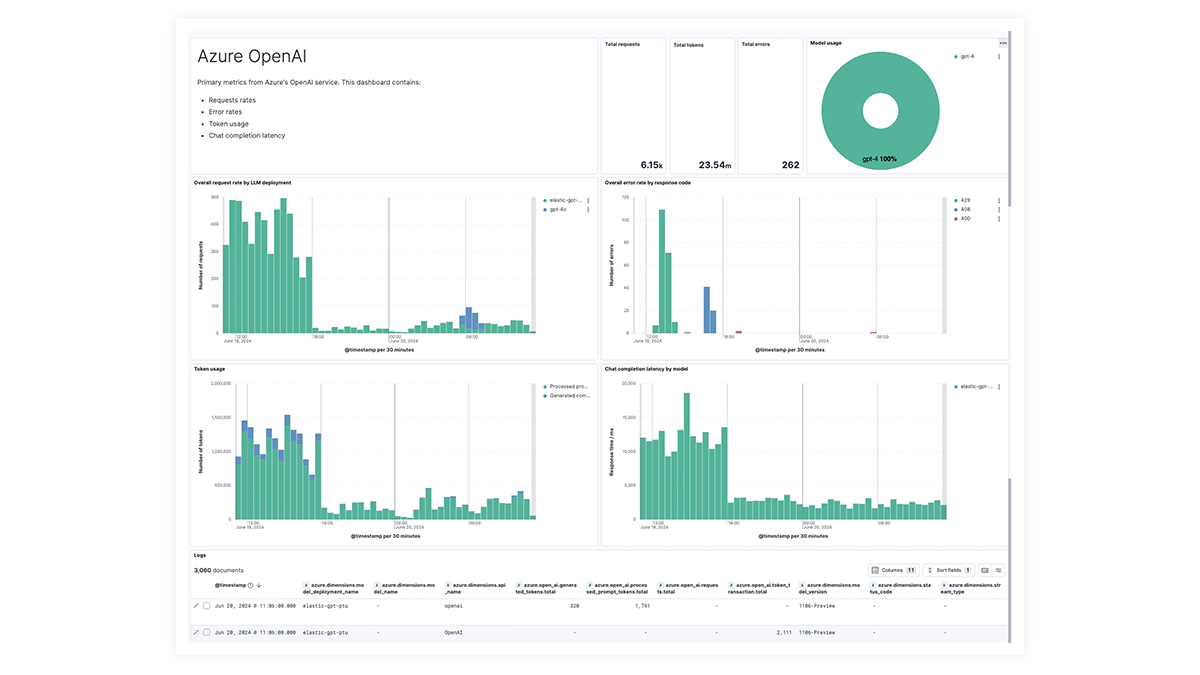
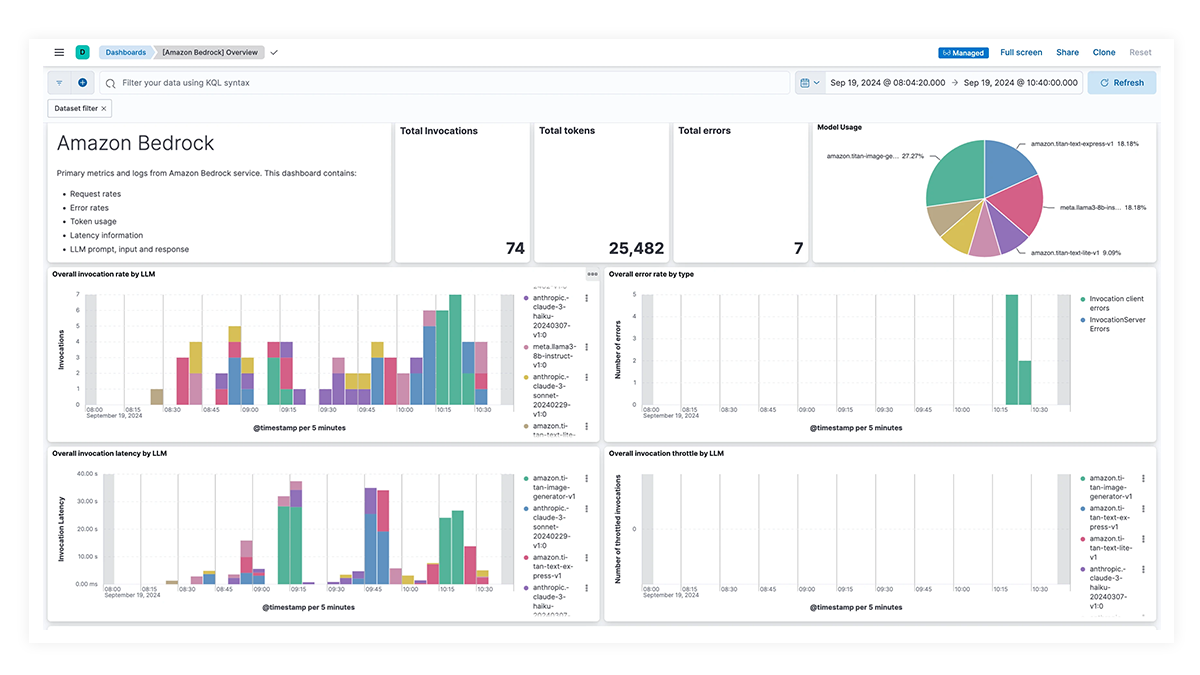
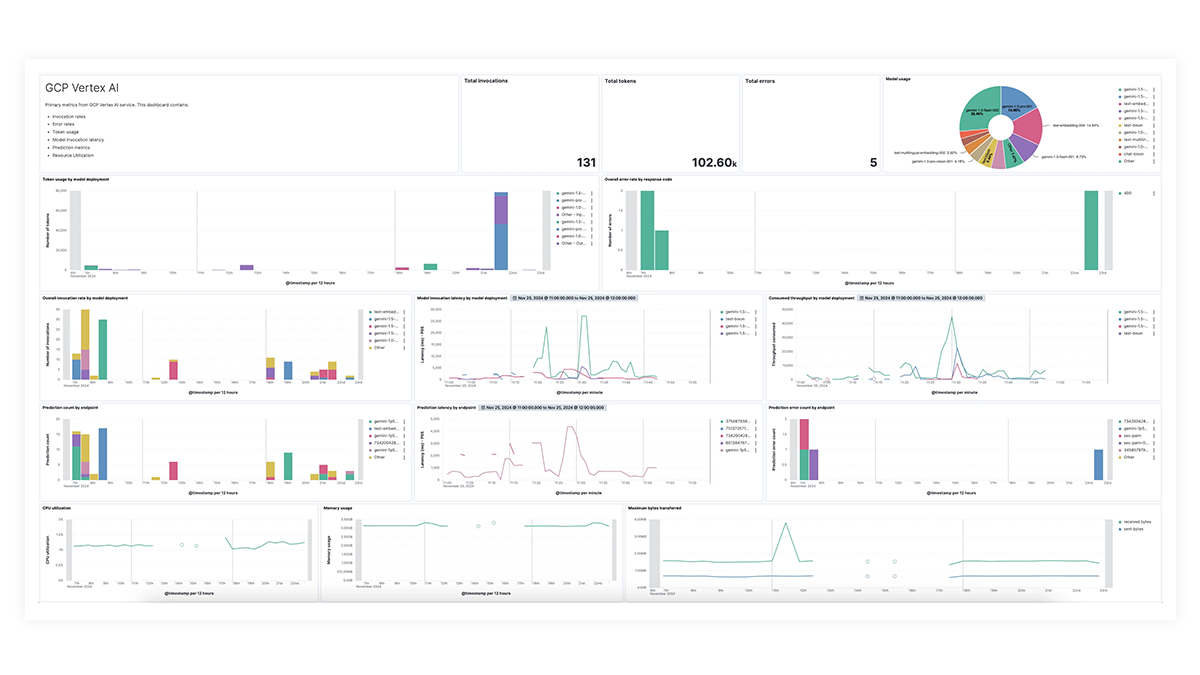
Rastreamento de ponta a ponta com o EDOT e bibliotecas de terceiros
Use o Elastic APM para analisar e fazer debug de apps LangChain com o OpenTelemetry. Isso pode ser suportado com EDOT (Java, Python, Node.js) ou bibliotecas de rastreamento de terceiros, como LangTrace, OpenLIT ou OpenLLMetry.
Experimente você mesmo o aplicativo Elastic chatbot RAG! Este aplicativo de exemplo combina Elasticsearch, LangChain e vários LLMs para alimentar um chatbot com ELSER e seus dados privados.
Vá além da observabilidade do LLM

APM

Monitoramento da experiência digital

Analítica de logs

Monitoramento de infraestrutura

AI Assistant

Consolidação de ferramentas

