This blog post explores TwelveLabs’ new Bedrock integration for its video embedding model, Marengo, and demonstrates how to use the resulting video embeddings with the Elasticsearch vector database. The walkthrough below details how this combination can be used to search through trailers for recent summer blockbuster movies.
Motivation
Real data isn’t just text. In today’s world of TikTok, work video calls, and live-streamed conferences, content is increasingly video-based. This is also true in the enterprise space. Whether for public safety, compliance audits, or customer satisfaction, multi-modal AI has the potential to unlock audio and video for knowledge applications.
However, when I search through mountains of content, I often get frustrated that I can’t find a video unless the words I am searching for were captured in metadata or spoken aloud in the recording. The expectation of “it just works” in the era of mobile apps has shifted to “it just understands my data” in the era of AI. To achieve this, AI needs to access video natively, without first converting it to text.
Terms like spatial reasoning and video understanding have applications in both video and robotics. Adding video understanding to our toolset will be an important step toward building AI systems that can go beyond text.
Video model superpowers
Before working with dedicated video models, my standard approach was to generate audio transcriptions using a model like Whisper, combined with dense vector embeddings from an image model for still frames extracted from the video. This approach works well for some videos, but fails when the subject changes rapidly or when the information concept is really in the motion of filmed subjects.
Simply put, relying solely on an image model leaves out much of the information stored in the video content.

I was first introduced to TwelveLabs a few months ago through their SaaS platform, which allows you to upload videos for one-stop-shop asynchronous processing. They have two model families:
Marengo is a multi-modal embedding model that can capture meaning not just from still images but also from moving video clips—similar to how a text embedding model can capture meaning from a whole paragraph chunk and not just single words.
Pegasus is a video understanding model that can be used to generate captions or answer RAG-style questions about clips as context.
While I liked the ease of use and APIs of the SaaS service, uploading data isn’t always permissible. My customers often have terabytes of sensitive data that is not allowed to leave their control. This is where AWS Bedrock comes into play.
TwelveLabs has made their premier models available on the on-demand Bedrock platform, allowing source data to remain in my controlled S3 buckets and only be accessed in a secure-computing pattern, without needing to persist in a 3rd-party system. This is fantastic news because video use cases from enterprise customers often contain trade secrets, records with PII, or other information subject to strict security and privacy regulations.
I suspect Bedrock integration unblocks many use cases.
Let’s search some movie trailers
Note: Full code for Python imports and working with environment variables through a .env file is in the Python notebook version of the code.
Dependencies:
- You will need an S3 bucket that can be written to by your AWS ID
- You will need the host URL and an API key for your Elasticsearch, either deployed locally or in Elastic Cloud
- This code assumes Elasticsearch version 8.17+ or 9.0+
A great data source for quick testing is movie trailers. They have fast edits, are visually stunning, and often contain high-action scenes. Grab your own .mp4 files or use https://github.com/yt-dlp/yt-dlp to access files from YouTube at a small scale.
! pip install yt-dlp boto3 ipython tqdm elasticsearch ipywidgets python-dotenv
## See python notebook for imports and environment variable setup
## Videos for the top five 2025 summer boxoffice leaders in the USA
videos = [
"https://www.youtube.com/watch?v=VWqJifMMgZE", ## Lilo and Stitch 2025
"https://www.youtube.com/watch?v=Ox8ZLF6cGM0", ## Superman 2025 trailer
"https://www.youtube.com/watch?v=jan5CFWs9ic", ## Jurassic World Rebirth
"https://www.youtube.com/watch?v=qpoBjOg5RHU", ## Fantastic Four: First Steps
"https://www.youtube.com/watch?v=22w7z_lT6YM", ## How to Train Your Dragon 2025
]
#########
## Data Class
#########
class VideoIntelligence:
def __init__(self, url, platform, video_id):
self.url = url
self.platform = platform
self.video_id = video_id
self.video_string = f"{self.platform}_{self.video_id}"
self.base_path = f"{DATA_PATH}/videos/{self.video_string}"
self.images = []
self.video_path = None
self.metadata_file = None
self.s3_key = None
self.metadata = None
self.title = None
self.description = None
self.enmbedings_list = None
### ... rest of data object class omitted ... see notebook for full code
video_objects = []
for video_str in videos:
if "youtube.com" in video_str:
platform = "youtube"
video_id = video_str.split("v=")[1]
video_objects.append(VideoIntelligence(video_str, platform, video_id))
for video_object in video_objects:
get_video(video_object)
## See python notebook for YT-DLP codeOnce the files are in our local file system, we’ll need to upload them to our S3 bucket:
# Initialize AWS session
session = boto3.session.Session(
aws_access_key_id=AWS_ACCESS_KEY_ID,
aws_secret_access_key=AWS_SECRET_ACCESS_KEY,
region_name=AWS_REGION
)
#########
## Validate S3 Configuration
#########
aws_account_id = session.client('sts').get_caller_identity()["Account"]
print(f"AWS Account ID: {aws_account_id}")
s3_client = session.client('s3')
# Verify bucket access
try:
s3_client.head_bucket(Bucket=S3_BUCKET_NAME)
print(f"✅ Successfully connected to S3 bucket: {S3_BUCKET_NAME}")
except Exception as e:
print(f"❌ Error accessing S3 bucket: {e}")
print("Please ensure the bucket exists and you have proper permissions.")
#########
## Upload videos to S3, and make note of where we put them in data object
#########
for video_object in video_objects:
# Get the video file path
video_path = video_object.get_video_path()
# Skip if video path is not set
if not video_path:
print(f"Skipping {video_object.get_video_string()} - No video path set")
continue
# Define S3 destination key - organize by platform and video ID
# put this information in our data object for later
s3_key = video_object.get_s3_key()
if not s3_key:
s3_key = f"{S3_VIDEOS_PATH}/{video_object.get_platform()}/{video_object.get_video_id()}/{os.path.basename(video_path)}"
video_object.set_s3_key(s3_key)
try:
# Check if file already exists in S3
try:
s3_client.head_object(Bucket=S3_BUCKET_NAME, Key=s3_key)
print(f"Video {video_object.get_video_string()} already exists in S3. Skipping upload.")
continue
except botocore.exceptions.ClientError as e:
if e.response['Error']['Code'] == '404':
# File doesn't exist in S3, proceed with upload
pass
else:
# Some other error occurred
raise e
# Upload the video to S3
print(f"Uploading {video_object.get_video_string()} to S3...")
s3_client.upload_file(video_path, S3_BUCKET_NAME, s3_key)
print(f"Successfully uploaded {video_object.get_video_string()} to S3")
except Exception as e:
print(f"Error uploading {video_object.get_video_string()} to S3: {str(e)}")Now we can create our video embeddings using asynchronous Bedrock calls:
#########
## Use Bedrock hosted Twelve Labs models to create video embeddings
#########
# Helper function to wait for async embedding results
def wait_for_embedding_output(s3_bucket: str, s3_prefix: str, invocation_arn: str, verbose: bool = False) -> list:
"""
Wait for Bedrock async embedding task to complete and retrieve results
Args:
s3_bucket (str): The S3 bucket name
s3_prefix (str): The S3 prefix for the embeddings
invocation_arn (str): The ARN of the Bedrock async embedding task
Returns:
list: A list of embedding data
Raises:
Exception: If the embedding task fails or no output.json is found
"""
# Wait until task completes
status = None
while status not in ["Completed", "Failed", "Expired"]:
response = bedrock_client.get_async_invoke(invocationArn=invocation_arn)
status = response['status']
if verbose:
clear_output(wait=True)
tqdm.tqdm.write(f"Embedding task status: {status}")
time.sleep(5)
if status != "Completed":
raise Exception(f"Embedding task failed with status: {status}")
# Retrieve the output from S3
response = s3_client.list_objects_v2(Bucket=s3_bucket, Prefix=s3_prefix)
for obj in response.get('Contents', []):
if obj['Key'].endswith('output.json'):
output_key = obj['Key']
obj = s3_client.get_object(Bucket=s3_bucket, Key=output_key)
content = obj['Body'].read().decode('utf-8')
data = json.loads(content).get("data", [])
return data
raise Exception("No output.json found in S3 prefix")
# Create video embedding
def create_video_embedding(video_s3_uri: str, video_id: str) -> list:
"""
Create embeddings for video using Marengo on Bedrock
Args:
video_s3_uri (str): The S3 URI of the video to create an embedding for
video_id (str): the identifying unique id of the video, to be used as a uuid
Returns:
list: A list of embedding data
"""
unique_id = video_id
s3_output_prefix = f'{S3_EMBEDDINGS_PATH}/{S3_VIDEOS_PATH}/{unique_id}'
response = bedrock_client.start_async_invoke(
modelId=MARENGO_MODEL_ID,
modelInput={
"inputType": "video",
"mediaSource": {
"s3Location": {
"uri": video_s3_uri,
"bucketOwner": aws_account_id
}
}
},
outputDataConfig={
"s3OutputDataConfig": {
"s3Uri": f's3://{S3_BUCKET_NAME}/{s3_output_prefix}'
}
}
)
invocation_arn = response["invocationArn"]
print(f"Video embedding task started: {invocation_arn}")
# Wait for completion and get results
try:
embedding_data = wait_for_embedding_output(S3_BUCKET_NAME, s3_output_prefix, invocation_arn)
except Exception as e:
print(f"Error waiting for embedding output: {e}")
return None
return embedding_data
def check_existing_embedding(video_id: str) -> bool:
"""Check S3 folder to see if this video already has an embedding created to avoid re-inference"""
s3_output_prefix = f'{S3_EMBEDDINGS_PATH}/{S3_VIDEOS_PATH}/{video_id}'
print(s3_output_prefix)
try:
# Check if any files exist at this prefix
response = s3_client.list_objects_v2(Bucket=S3_BUCKET_NAME, Prefix=s3_output_prefix)
if 'Contents' in response and any(obj['Key'].endswith('output.json') for obj in response.get('Contents', [])):
print(f"Embedding {video_object.get_video_string()} already has an embedding. Skipping embedding creation.")
# Find the output.json file
for obj in response.get('Contents', []):
if obj['Key'].endswith('output.json'):
output_key = obj['Key']
# Get the object from S3
obj = s3_client.get_object(Bucket=S3_BUCKET_NAME, Key=output_key)
# Read the content and parse as JSON
content = obj['Body'].read().decode('utf-8')
embedding_data = json.loads(content).get("data", [])
return embedding_data
else:
print(f"No existing embedding found for {video_object.get_video_string()}.")
return None
except botocore.exceptions.ClientError as e:
if e.response['Error']['Code'] == '404':
# File doesn't exist in S3, proceed with upload
print("Did not find embedding in s3")
return None
else:
# Some other error occurred
raise e
def create_s3_uri(bucket_name: str, key: str)-> str:
video_uri = f"s3://{bucket_name}/{key}"
return video_uri
## Generate the embeddings one at a time, use S3 as cache to prevent double embedding generations
for video_object in tqdm.tqdm(video_objects, desc="Processing videos"):
s3_key = video_object.get_s3_key()
video_id = video_object.get_video_id()
video_uri = create_s3_uri(S3_BUCKET_NAME, s3_key)
retrieved_embeddings = check_existing_embedding(video_id)
if retrieved_embeddings:
video_object.set_embeddings_list(retrieved_embeddings)
else:
video_embedding_data = create_video_embedding(video_uri, video_id)
video_object.set_embeddings_list(video_embedding_data)Now that we’ve got the embeddings in our local in-memory video objects, here’s a quick test-print to show what came back:
video_embedding_data = video_objects[0].get_embeddings_list()
##Preview Print
for i, embedding in enumerate(video_embedding_data[:3]):
print(f"{i}")
for key in embedding:
if "embedding" == key:
print(f"\t{key}: len {len(embedding[key])}")
else:
print(f"\t{key}: {embedding[key]}")The output is as follows:
0
embedding: len 1024
embeddingOption: visual-text
startSec: 0.0
endSec: 6.199999809265137
1
embedding: len 1024
embeddingOption: visual-text
startSec: 6.199999809265137
endSec: 10.399999618530273
2
embedding: len 1024
embeddingOption: visual-text
startSec: 10.399999618530273
endSec: 17.299999237060547Inserting into Elasticsearch
We’ll upload the objects—in my case, the metadata and embeddings for about 155 video clips—to Elasticsearch. At such a small scale, using a flat float32 index for brute-force nearest neighbor is the most efficient and cost-effective approach. However, the example below demonstrates how to create a different index for each popular quantization level supported by Elasticsearch for large-scale use cases. See this article on Elastic’s Better Binary Quantization (BBQ) feature.
es = Elasticsearch(
hosts=[ELASTICSEARCH_ENDPOINT],
api_key=ELASTICSEARCH_API_KEY
)
es_detail = es.info().body
if "version" in es_detail:
identifier = es_detail['version']['build_flavor'] if 'build_flavor' in es_detail['version'] else es_detail['version']['number']
print(f"✅ Successfully connected to Elasticsearch: {es_detail['version']['build_flavor']}")
docs = []
for video_object in video_objects:
persist_object = video_object.get_video_object()
embeddings = video_object.get_embeddings_list()
for embedding in embeddings:
if embedding["embeddingOption"] == "visual-image":
# Create a copy of the persist object and add embedding details
doc = copy.deepcopy(persist_object)
doc["embedding"] = embedding["embedding"]
doc["start_sec"] = embedding["startSec"]
doc["end_sec"] = embedding["endSec"]
docs.append(doc)
index_varieties = [
"flat", ## brute force float32
"hnsw", ## float32 hnsw graph data structure
"int8_hnsw", ## int8 hnsw graph data structure, default for lower dimension models
"bbq_hnsw", ## Better Binary Qunatization HNSW, default for higher dimension models
"bbq_flat" ## brute force + Better Binary Quantization
]
for index_variety in index_varieties:
# Create an index for the movie trailer embeddings
# Define mapping with proper settings for dense vector search
index_name = f"twelvelabs-movie-trailer-{index_variety}"
mappings = {
"properties": {
"url": {"type": "keyword"},
"platform": {"type": "keyword"},
"video_id": {"type": "keyword"},
"title": {"type": "text", "analyzer": "standard"},
"embedding": {
"type": "dense_vector",
"dims": 1024,
"similarity": "cosine",
"index_options": {
"type": index_variety
}
},
"start_sec": {"type": "float"},
"end_sec": {"type": "float"}
}
}
# Check if index already exists
if es.indices.exists(index=index_name):
print(f"Deleting Index '{index_name}' and then sleeping for 2 seconds")
es.indices.delete(index=index_name)
sleep(2)
# Create the index
es.indices.create(index=index_name, mappings=mappings)
print(f"Index '{index_name}' created successfully")
for index_variety in index_varieties:
# Create an index for the movie trailer embeddings
# Define mapping with proper settings for dense vector search
index_name = f"twelvelabs-movie-trailer-{index_variety}"
# Bulk insert docs into Elasticsearch index
print(f"Indexing {len(docs)} documents into {index_name}...")
# Create actions for bulk API
actions = []
for doc in docs:
actions.append({
"_index": index_name,
"_source": doc
})
# Perform bulk indexing with error handling
try:
success, failed = bulk(es, actions, chunk_size=100, max_retries=3,
initial_backoff=2, max_backoff=60)
print(f"\tSuccessfully indexed {success} documents into {index_name}")
if failed:
print(f"\tFailed to index {len(failed)} documents")
except Exception as e:
print(f"Error during bulk indexing: {e}")
print(f"Completed indexing documents into {index_name}")Running a search
The Bedrock implementation for TwelveLabs allows for an async call to generate text-to-vector embeddings to S3. Below, however, we’ll use the lower-latency synchronous invoke_model to get a text embedding directly for our search query. (Text Marengo documentation samples are here.)
# Create text embedding
def create_text_embedding(text_query: str) -> list:
text_model_id = TEXT_EMBEDDING_MODEL_ID
text_model_input = {
"inputType": "text",
"inputText": text_query
}
response = bedrock_client.invoke_model(
modelId=text_model_id,
body=json.dumps(text_model_input)
)
response_body = json.loads(response['body'].read().decode('utf-8'))
embedding_data = response_body.get("data", [])
if embedding_data:
return embedding_data[0]["embedding"]
else:
return None
def vector_query(index_name: str, text_query: str) -> dict:
query_embedding = create_text_embedding(text_query)
query = {
"retriever": {
"knn": {
"field": "embedding",
"query_vector": query_embedding,
"k": 10,
"num_candidates": "25"
}
},
"size": 10,
"_source": False,
"fields": ["title", "video_id", "start_sec"]
}
return es.search(index=index_name, body=query).body
text_query = "Show me scenes with dinosaurs"
print (vector_query("twelvelabs-movie-trailer-flat", text_query))The returned JSON is our search result! But to create an easier-to-use user interface for testing, we can use some quick iPython widgets:
from ipywidgets import widgets, HTML as WHTML, HBox, Layout
from IPython.display import display
def display_search_results_html(query):
results = vector_query("twelvelabs-movie-trailer-flat", query)
hits = results.get('hits', {}).get('hits', [])
if not hits:
return "<p>No results found</p>"
items = []
for hit in hits:
fields = hit.get('fields', {})
title = fields.get('title', ['No Title'])[0]
score = hit.get('_score', 0)
video_id = fields.get('video_id', [''])[0]
start_sec = fields.get('start_sec', [0])[0]
url =
f"https://www.youtube.com/watch?v={video_id}&t={int(start_sec)}s"
items.append(f'<li><a href="{url}" target="_blank">{title} (Start: {float(start_sec):.1f}s)</a> <span>Score: {score}</span></li>')
return "<h3>Search Results:</h3><ul>" + "\n".join(items) + "</ul>"
def search_videos():
search_input = widgets.Text(
value='',
placeholder='Enter your search query…',
description='Search:',
layout=Layout(width='70%')
)
search_button = widgets.Button(
description='Search Videos',
button_style='primary',
layout=Layout(width='20%')
)
# Use a single HTML widget for output; update its .value to avoid double-rendering
results_box = WHTML(value="")
def on_button_click(_):
q = search_input.value.strip()
if not q:
results_box.value = "<p>Please enter a search query</p>"
return
results_box.value = "<p>Searching…</p>"
results_box.value = display_search_results_html(q)
# Avoid multiple handler attachments if the cell is re-run
try:
search_button._click_handlers.callbacks.clear()
except Exception:
pass
search_button.on_click(on_button_click)
display(HBox([search_input, search_button]))
display(results_box)
# Call this to create the UI
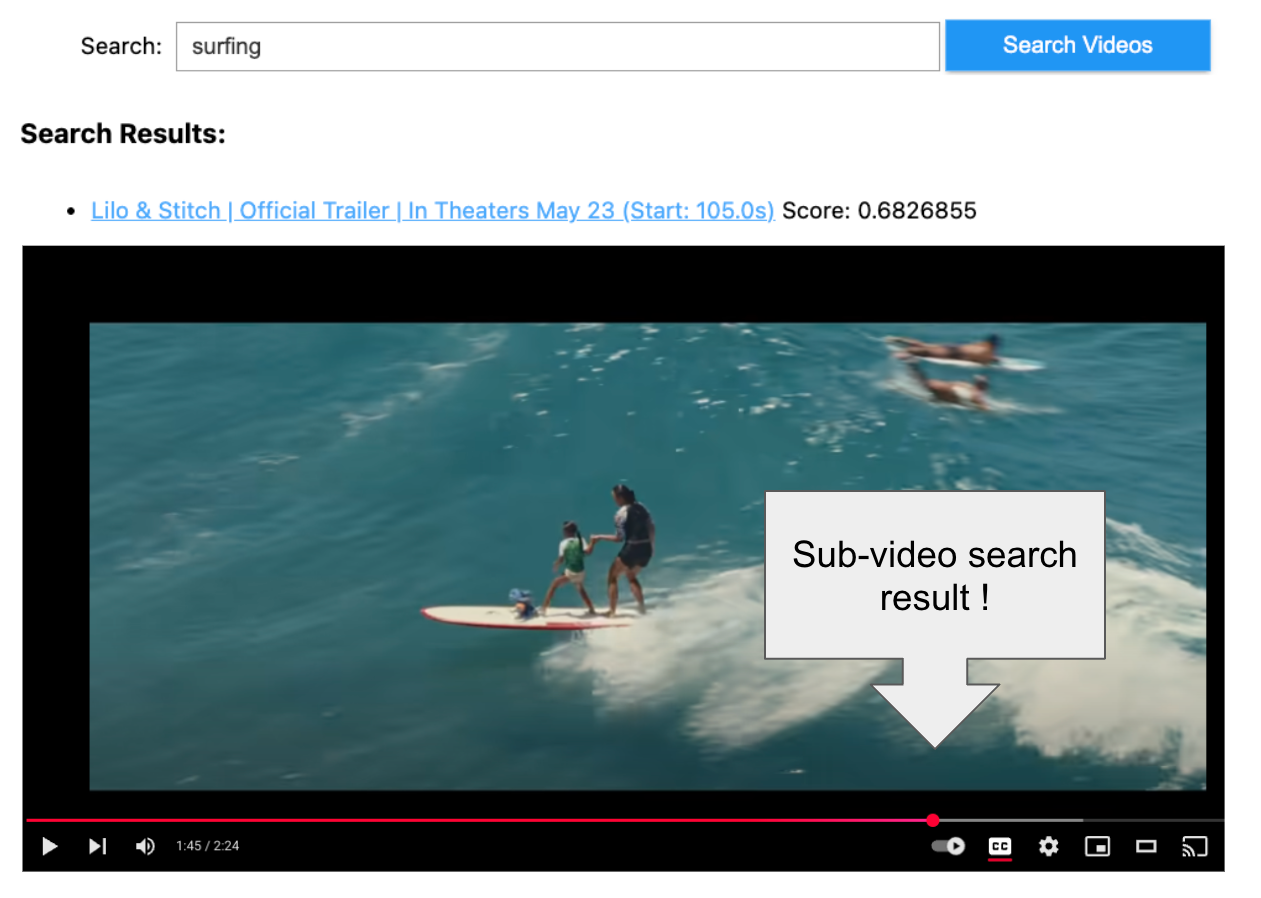
search_videos()Let’s run a search for something visual in our trailers.
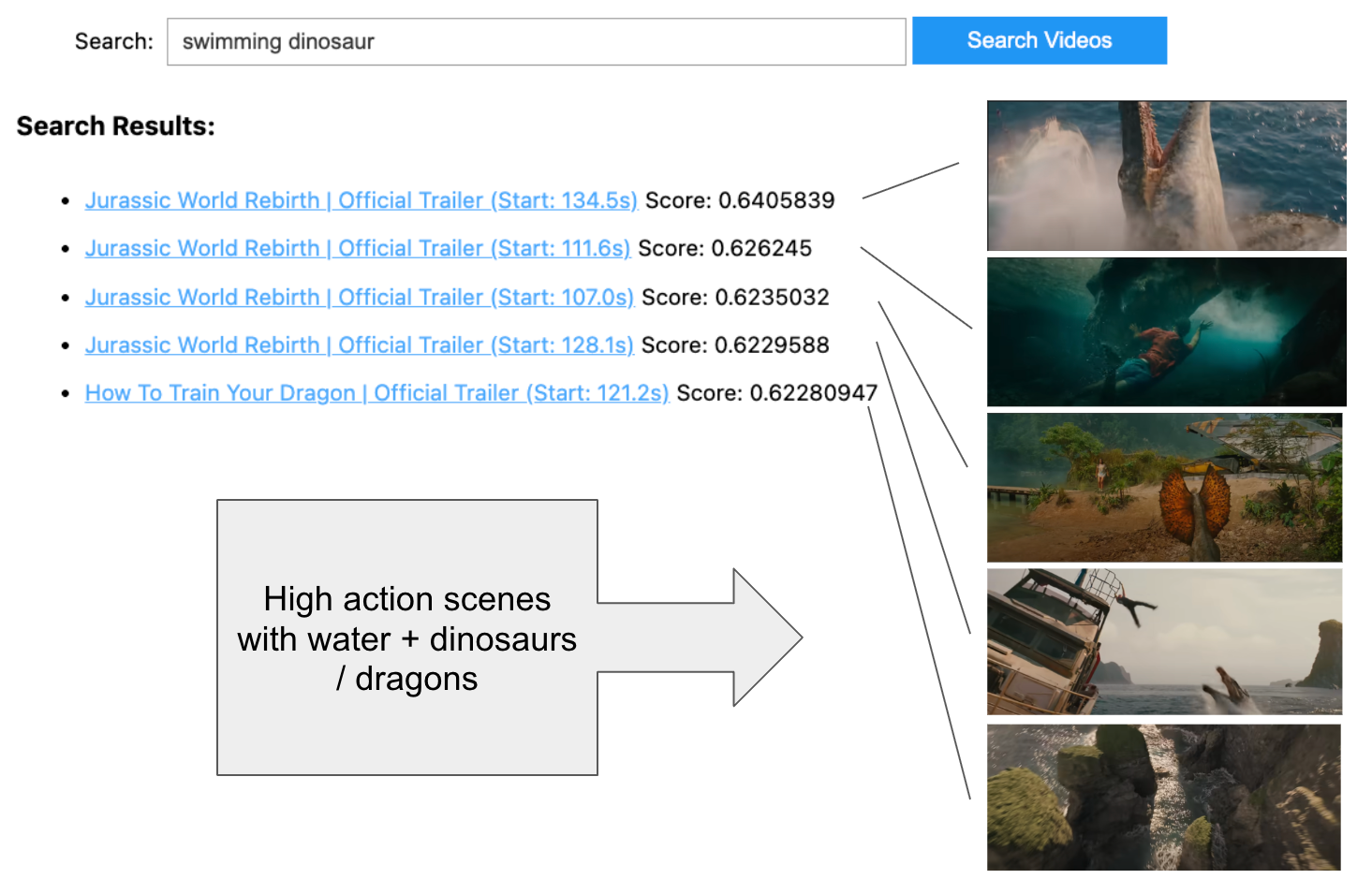
Comparing quantization methods
Newer versions of Elasticsearch default to bbq_hnsw for 1024-dimension dense vectors, which provide the best speed and scalability while preserving accuracy through rescoring on the original float32 within an oversampled candidate window.
For a simple UI to compare the impact of quantization on search results, check out a new project called Relevance Studio.
If we check our index management in Kibana or with a curl to GET /_cat/indices , we’ll see that each option is roughly the same size in storage. At first glance, this can be confusing, but remember that the storage size is about equal because the indices contain the float32 representation of the vector for rescoring. In the bbq_hnsw, only the quantized binary representation of the vector is used in the graph, leading to cost and performance savings for indexing and search.

Last thoughts
These are impressive results for single 1024-dimensional dense vectors, and I’m excited to try combining the power of the Marengo model with hybrid search approaches that include audio transcriptions as well as Elasticsearch’s geospatial filters and RBAC/ABAC access controls. What videos do you wish AI knew everything about?
Ready to try this out on your own? Start a free trial.
Elasticsearch has integrations for tools from LangChain, Cohere and more. Join our advanced semantic search webinar to build your next GenAI app!
Related content

November 3, 2025
Improving multilingual embedding model relevancy with hybrid search reranking
Learn how to improve the relevancy of E5 multilingual embedding model search results using Cohere's reranker and hybrid search in Elasticsearch.

October 23, 2025
Low-memory benchmarking in DiskBBQ and HNSW BBQ
Benchmarking Elasticsearch latency, indexing speed, and memory usage for DiskBBQ and HNSW BBQ in low-memory environments.

October 22, 2025
Deploying a multilingual embedding model in Elasticsearch
Learn how to deploy an e5 multilingual embedding model for vector search and cross-lingual retrieval in Elasticsearch.

October 23, 2025
Introducing a new vector storage format: DiskBBQ
Introducing DiskBBQ, an alternative to HNSW, and exploring when and why to use it.

September 15, 2025
Balancing the scales: Making reciprocal rank fusion (RRF) smarter with weights
Exploring weighted reciprocal rank fusion (RRF) in Elasticsearch and how it works through practical examples.