

Observabilidad de LLM
Monitorea y optimiza el rendimiento, el costo, la seguridad y la confiabilidad de la AI
Ten una imagen completa con los dashboards de un vistazo
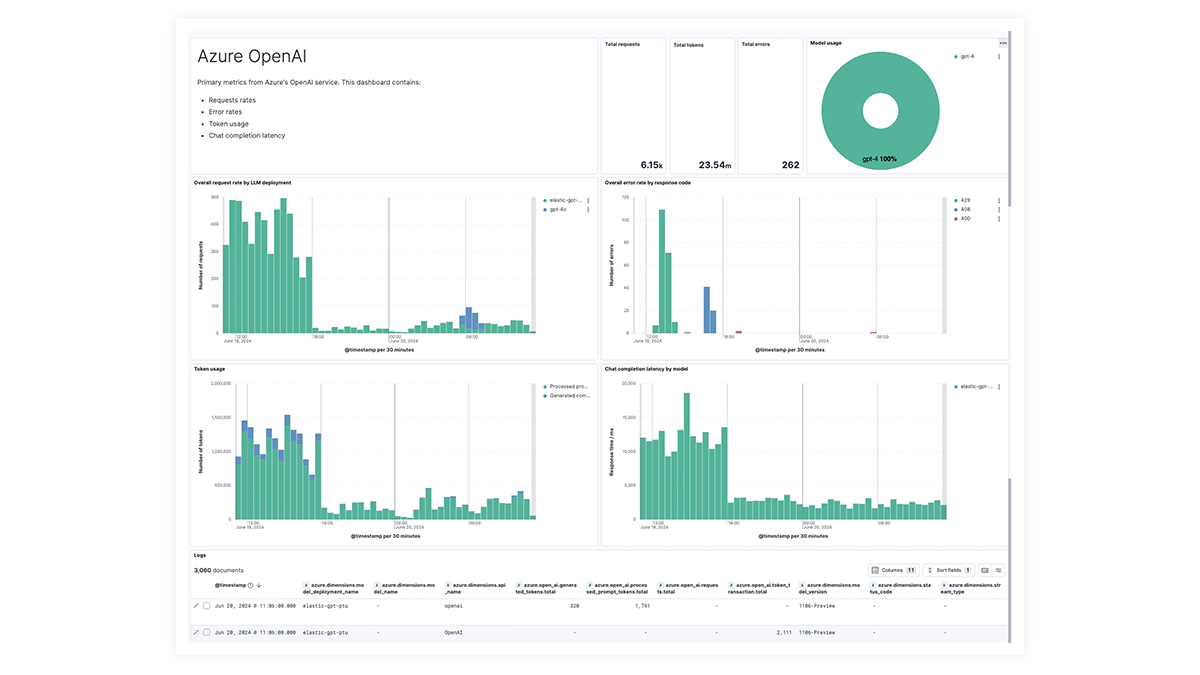
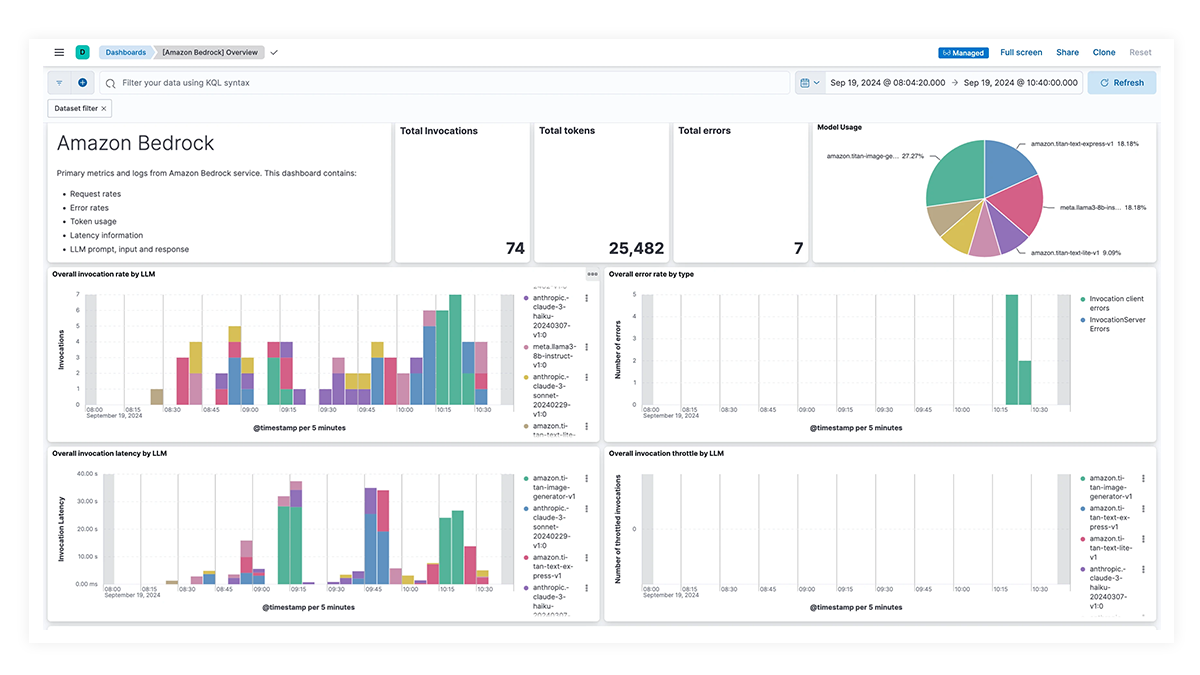
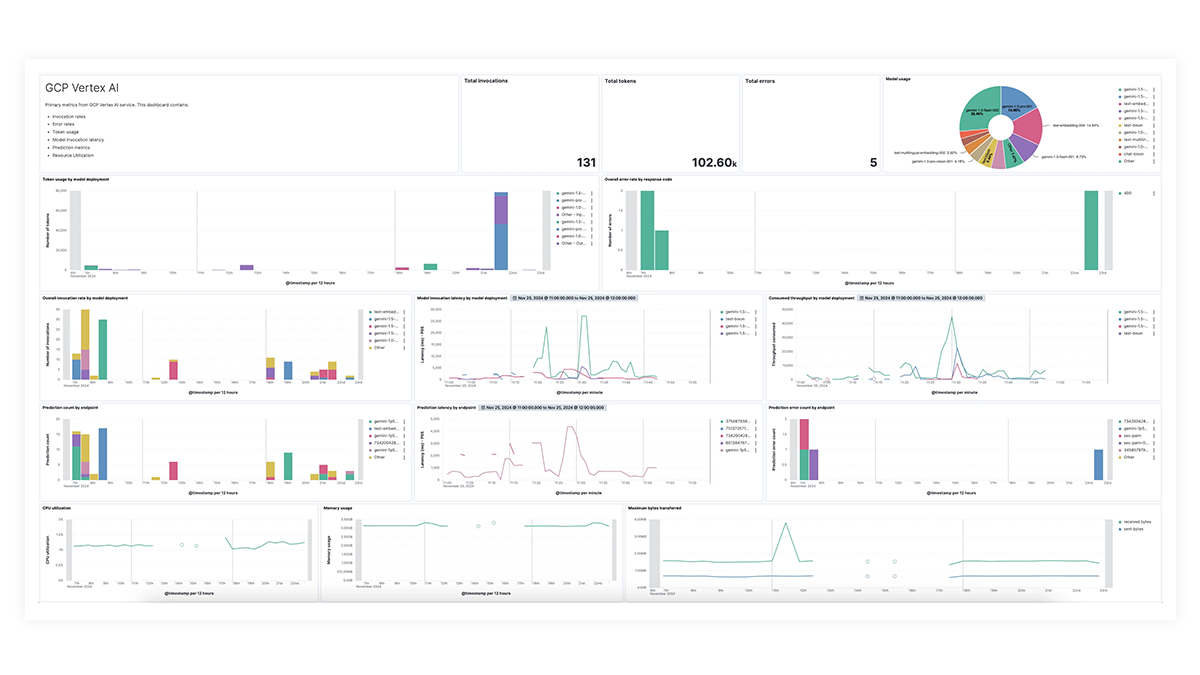
Los dashboards prediseñados para OpenAI, AWS Bedrock, Azure OpenAI y Google Vertex AI ofrecen información completa sobre los recuentos de invocaciones, las tasas de error, la latencia, las métricas de utilización y el uso de tokens, lo que permite a los SRE identificar y abordar los cuellos de botella de rendimiento, optimizar la utilización de recursos y mantener la confiabilidad del sistema.
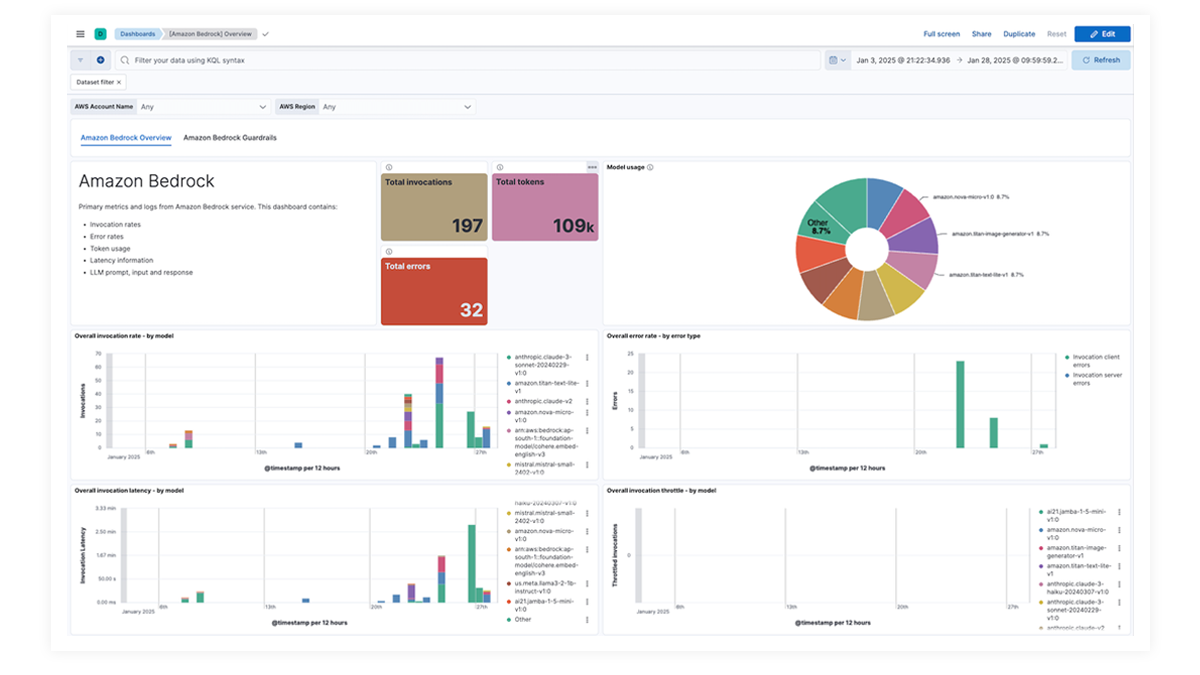
¿Rendimiento lento? Identifica las causas raíz
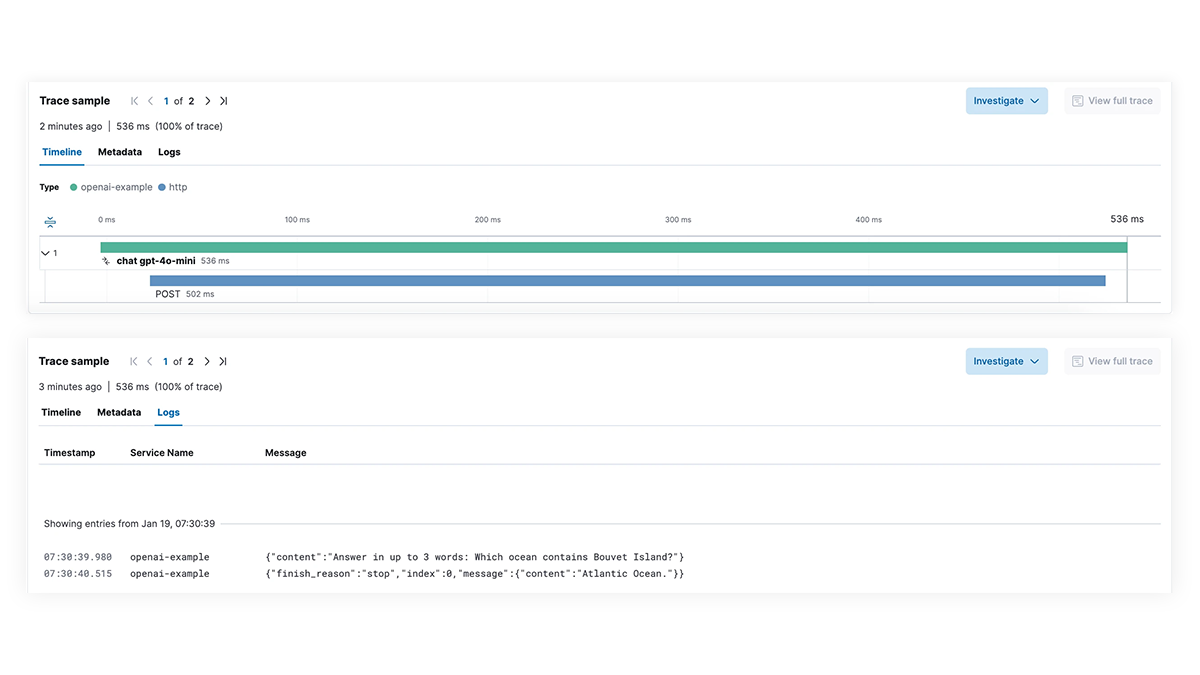
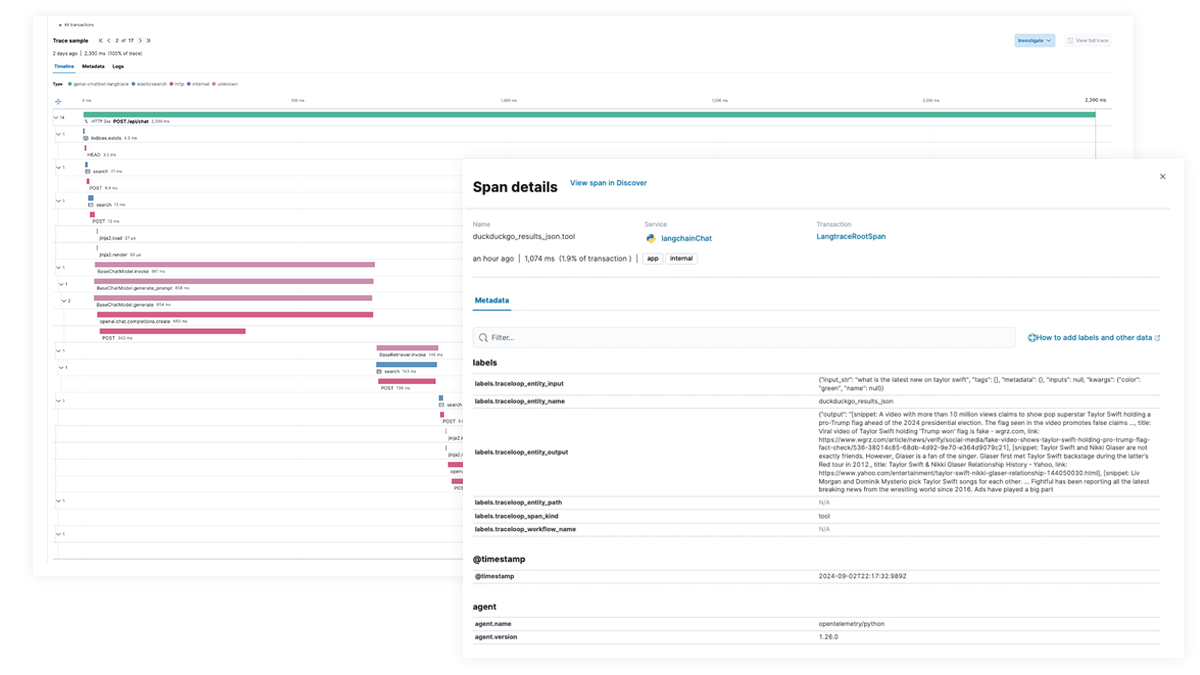
Obtén visibilidad completa de cada paso de la ruta de ejecución de LLM para aplicaciones que integran capacidades de AI generativa. Permite una depuración más profunda con seguimiento de extremo a extremo, mapping de dependencias de servicio y visibilidad de las solicitudes de LangChain, las llamadas de LLM fallidas y las interacciones de servicios externos. Soluciona rápidamente los errores y los picos de latencia para garantizar un rendimiento óptimo.
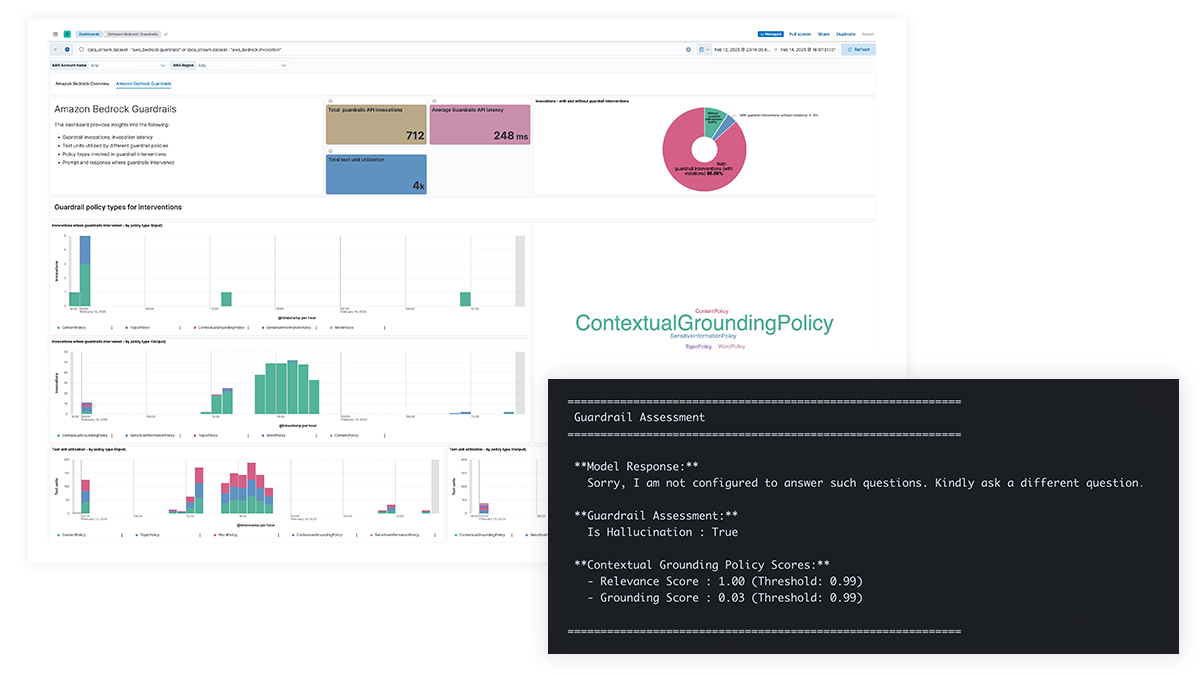
¿Preocupaciones de seguridad de AI? Obtén visibilidad de las indicaciones y las respuestas
Obtén transparencia en las indicaciones y las respuestas de LLM para la protección contra fugas de datos de información confidencial, contenido dañino o no deseado, y problemas éticos, así como para el abordaje de errores fácticos, sesgos y alucinaciones. La compatibilidad con las barreras de protección de Amazon Bedrock y el filtrado de contenido para Azure OpenAI permite intervenciones basadas en políticas y proporciona una base contextual para mejorar la precisión del modelo.
¿Problemas para rastrear costos? Consulta los desgloses de uso por modelo
Las organizaciones necesitan visibilidad sobre el uso de tokens, las búsquedas de alto costo y las llamadas de API, las estructuras de indicaciones ineficientes y otras anomalías de costos para optimizar el gasto de LLM. Elastic proporciona información para modelos multimodales, incluidos texto, video e imágenes, lo que permite a los equipos rastrear y gestionar los costos de LLM de manera efectiva.

Primeros pasos con la observabilidad de LLM
PASO 2: dashboards instantáneos, disponibles listos para usar en segundos
PASO 3: Crea alertas: convierte datos en acciones
Visibilidad de las apps GenAI
Usa Elastic para obtener información integral sobre las aplicaciones de AI a través de bibliotecas de rastreo de terceros, así como visibilidad lista para usar en los modelos hospedados por todos los principales servicios de LLM.












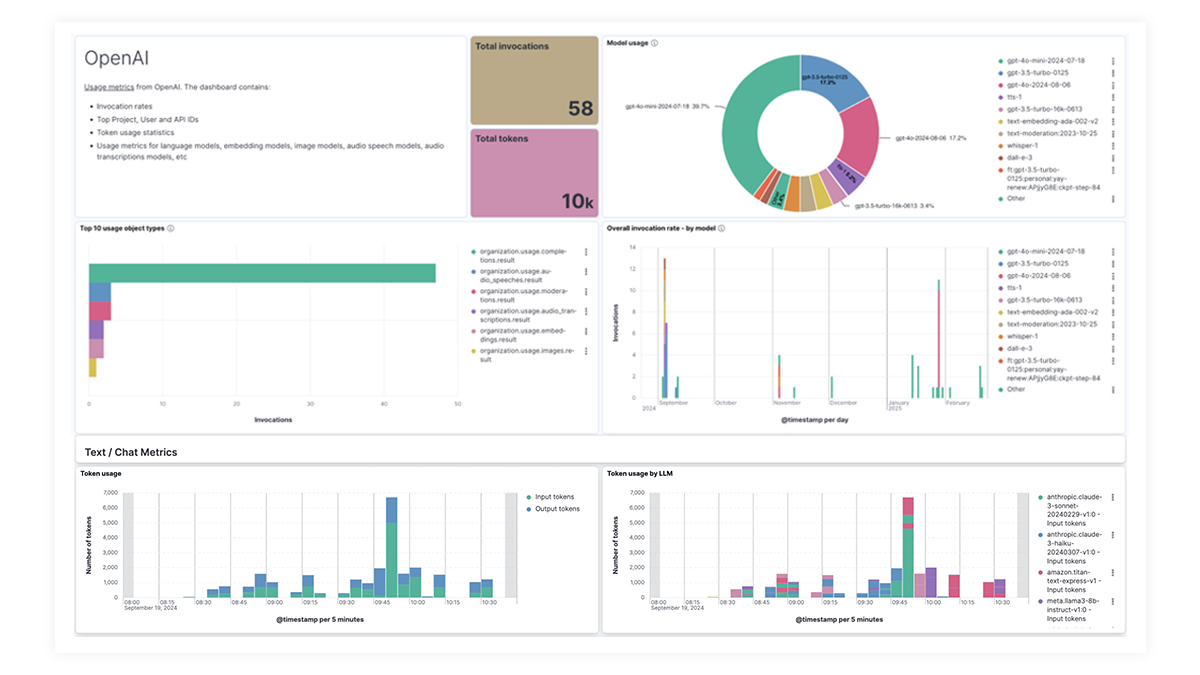
LLM observability dashboard gallery
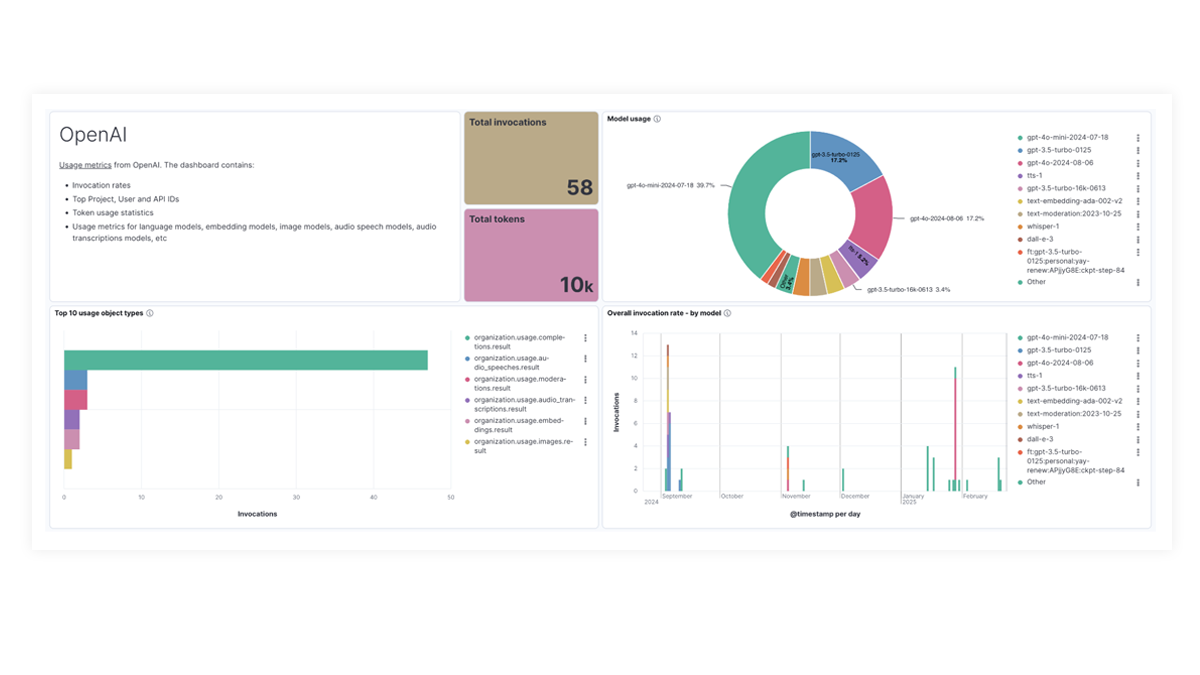
The OpenAI integration for Elastic Observability includes prebuilt dashboards and metrics so you can effectively track and monitor OpenAI model usage, including GPT-4o and DALL·E.
Rastreo de extremo a extremo con EDOT y bibliotecas de terceros
Usa Elastic APM para analizar y depurar apps de LangChain con OpenTelemetry. Esto puede ser soportado con EDOT (Java, Python, Node.js) o bibliotecas de seguimiento de terceros, como LangTrace, OpenLIT u OpenLLMetry.
¡Prueba la app de chatbot RAG de Elastic! Esta app de muestra combina Elasticsearch, LangChain y distintos LLM para potenciar un chatbot con ELSER y tus datos privados.
Ve más allá de la observabilidad de LLM

APM

Monitoreo de la experiencia digital

Analíticas de logs

Monitoreo de infraestructura

Asistente de IA

Consolidación de herramientas

