Elasticsearch Serverless
Paga solo lo que usas, sin complicaciones de infraestructura. Descubre el arte de lo posible con la búsqueda por AI, herramientas listas para RAG y capacidades de analíticas de datos.
General purposeBest for general search use cases across various data types Try for freeIngest*
As low as $0.14
Per VCU per hour Search*
As low as $0.09
Per VCU per hour Machine Learning
As low as $0.07
Per VCU per hour Storage & Retention
As low as $0.047
Per GB retained per month Egress
As low as $0.05 Per GB
Per GB transferred per month Elastic Managed Large Language Model (LLM) for AI Playground and AI Assistant
$4.50 Per million input tokens$21 Per million output tokens |
Vector searchBest for semantic search use cases using vectors with near-real-time retrieval Try for freeIngest*
As low as $0.14
Per VCU per hour Search*
As low as $0.09
Per VCU per hour Machine Learning
As low as $0.07
Per VCU per hour Storage & Retention
As low as $0.047
Per GB retained per month Egress
50 GB free, then $0.05 Per GB
Per GB transferred per month Elastic Managed Large Language Model (LLM) for AI Playground and AI Assistant
$4.50 Per million input tokens$21 Per million output tokens |
Time seriesBest for retention and analysis of high volume time series data, such as logs of other data streams Ingest
Coming soon
Per VCU per hour Search*
Coming soon
Per VCU per hour Machine Learning
Coming soon
Per VCU per hour Storage & Retention
Coming soon
Per GB retained per month Egress
Coming soon
Per GB transferred per month Elastic Managed Large Language Model (LLM) for AI Playground and AI Assistant
Coming soon
|
|
| Ingest*Per VCU per hour | As low as $0.14 |
As low as $0.14 |
Coming soon |
| Search*Per VCU per hour | As low as $0.09 |
As low as $0.09 |
Coming soon |
| Machine LearningPer VCU per hour | As low as $0.07 |
As low as $0.07 |
Coming soon |
| Storage & RetentionPer GB retained per month | As low as $0.047 |
As low as $0.047 |
Coming soon |
| EgressPer GB transferred per month |
As low as $0.05
|
50 GB free, then $0.05 |
Coming soon |
| Elastic Managed Large Language Model (LLM) for AI Playground and AI Assistant |
$4.50
Per million input tokens
$21
Per million output tokens
|
$4.50
Per million input tokens
$21
Per million output tokens
|
Coming soon |
*These prices take effect December 1, 2024.
Ingest and retention metering is based on the uncompressed, normalized, fully enriched data volume that you ingest into your serverless project. Metered volumes will be much higher than the "raw" or compressed data size "on the wire."
Paquete de soporte
El soporte limitado se incluye con una suscripción estándar; todos los otros precios de soporte se basan en el porcentaje de tu consumo. Para obtener más información sobre lo que se incluye en cada nivel de soporte, visita elastic.co/support.
| Elastic Cloud organization subscription level* | Standard | Gold | Platinum | Enterprise |
|---|---|---|---|---|
| Support and total bill | ||||
| Support level | Limited | Base | Enhanced | Premium |
| % of charge | Included | 5% | 10% | 15% |
*Subscription level is selected during sign up
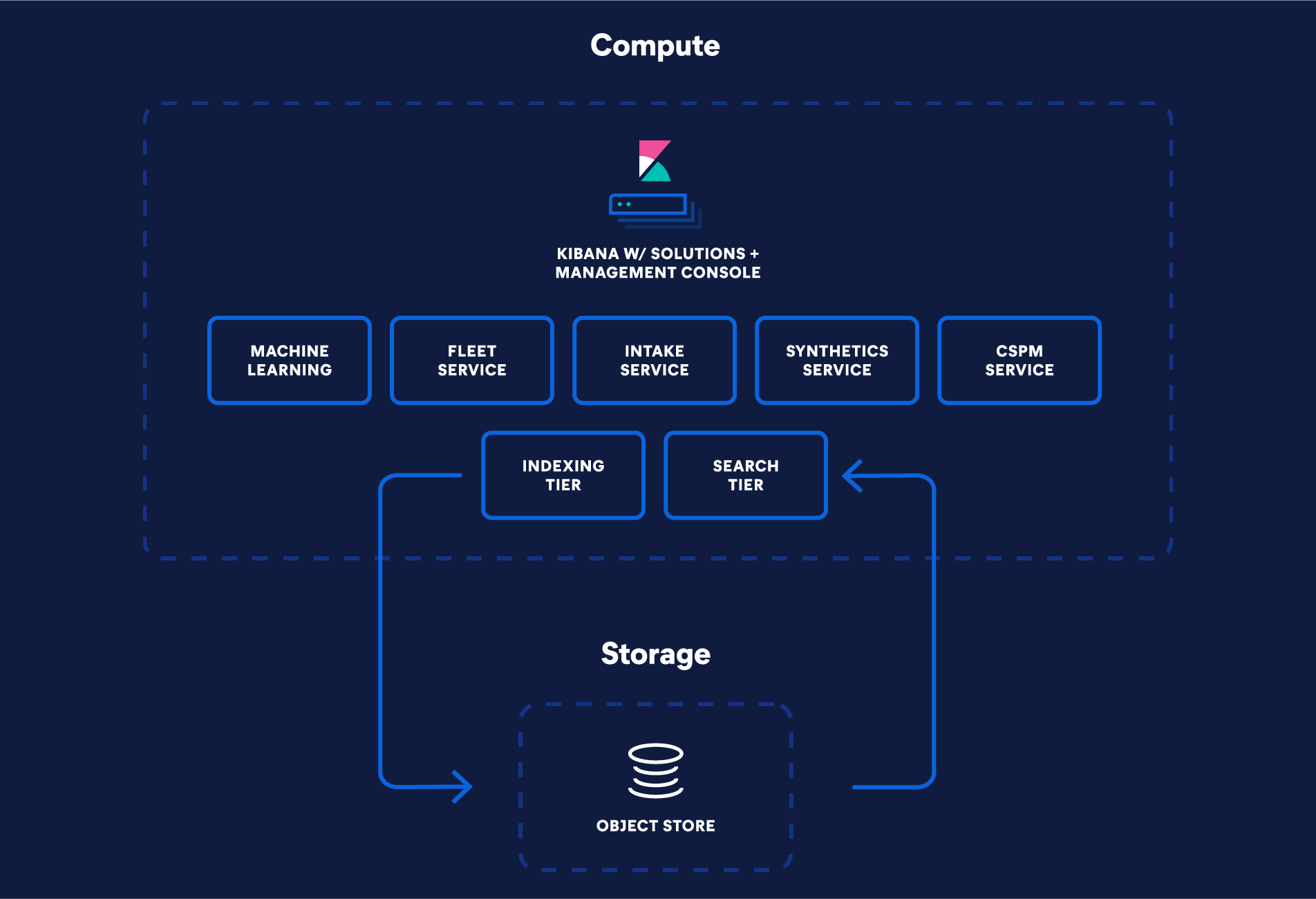
Componentes de precios de Elasticsearch Serverless
Elasticsearch Serverless cobra por separado por el procesamiento (VCU con 1 GB de RAM) y el almacenamiento (GB), al ofrecer precios escalables y basados en el rendimiento para cumplir con tus objetivos de latencia y rendimiento.

Unidad de cómputo virtual (VCU)
Hay tres tipos de VCU especializadas disponibles para realizar tareas específicas.
Ingesta de VCU: maneja la indexación de datos en Search AI Lake.
VCU de búsqueda: gestiona las búsquedas del usuario, las reglas de alerta, las agregaciones, las transformaciones y las consultas geoespaciales contra los datos en el Search AI Lake.
VCU de machine learning: gestionan la inferencia, las cargas de trabajo de ELSER y los trabajos de machine learning.

Uso de tokens
Uso del modelo de lenguaje grande gestionado por Elastic por millón de tokens de entrada y salida: aprovecha la búsqueda impulsada por AI como servicio sin desplegar un modelo de lenguaje grande (LLM) en tu proyecto.

Aprovisionamiento adaptable de recursos
Los recursos de cómputo de ingesta y ML se escalan automáticamente para satisfacer las demandas de carga de trabajo.
Los recursos de cómputo de búsqueda se ajustan dinámicamente a las cargas de trabajo, lo que garantiza un rendimiento y una capacidad de respuesta constantes. Con la configuración flexible de Search Power, tienes control sobre las asignaciones de recursos para satisfacer tus necesidades de rendimiento.

Almacenamiento y retención
Elasticsearch Serverless usa almacenes de objetos para el almacenamiento persistente en Search AI Lake.
Todos los datos, independientemente del tipo, la fecha reciente y la frecuencia de uso, son accesibles desde Search AI Lake. El tamaño de Search AI Lake se puede controlar con políticas de retención de datos manuales o administradas.
El almacenamiento se mide en GB.
El mismo Elasticsearch, pero más fácil
Preguntas frecuentes
Los proyectos sin servidor usan los componentes principales del Elastic Stack, como Elasticsearch y Kibana, y se basan en la arquitectura Search AI Lake de Elastic que desvincula el cómputo y el almacenamiento. Las operaciones de búsqueda e indexación están separadas, lo que te ofrece flexibilidad para escalar tus cargas de trabajo y, al mismo tiempo, garantiza un alto nivel de rendimiento.
Disfruta de los siguientes beneficios con Elasticsearch Serverless:
- Gestión gratis. Elastic gestiona el cluster de Elastic subyacente para que puedas concentrarte en tus datos. Con los proyectos sin servidor, Elastic se encarga de las actualizaciones automáticas, los backups de los datos y la continuidad del negocio.
- Escalamiento automático. Para cumplir con tus requisitos de rendimiento, el sistema se ajusta automáticamente a tus cargas de trabajo.
- Almacenamiento de datos optimizado. Tus datos se almacenan en el Search Lake de tu proyecto, que sirve como un almacenamiento rentable y de alto rendimiento. Hay una capa de alto rendimiento disponible sobre el Search Lake para tus datos más consultados.
- Paga por el rendimiento que necesitas. Pagas los recursos de ingesta, búsqueda y ML por separado según sea necesario por las cargas de trabajo que ejecutas.
Elastic Cloud es una potente plataforma que se adapta a muchas necesidades informáticas. Los proyectos sin servidor están diseñados específicamente para casos de uso, proporcionando una experiencia completamente gestionada con escalado automático. Esta especialización y modelo operativo es lo que diferencia a los proyectos sin servidor hoy en día.
Elasticsearch Serverless está actualmente disponible en regiones seleccionadas de proveedores cloud, con algunas características que aún están por llegar en el futuro. Estamos completamente comprometidos en expandir nuestra oferta de servicios sin servidor a más regiones y proveedores cloud. Te recomendamos que revises la documentación para verificar la compatibilidad técnica, como la seguridad, el cumplimiento y la disponibilidad.
Es sencillo empezar a usar Elasticsearch Serverless:
- Crea proyectos de Elasticsearch Serverless en la consola del cloud.
- Elige el tipo de proyecto optimizado según el caso de uso que mejor se adapte a tus necesidades.
- Comienza con tu experiencia de proyecto optimizada para tu caso de uso.
Recomendamos enviar los datos directamente desde tu aplicación o usando clientes de conectores. Para enviar los datos en una instancia actual de Elasticsearch, te recomendamos que uses Logstash para migrar grandes volúmenes.
La configuración de Search Power te permite gestionar los recursos computacionales para optimizar el rendimiento de búsqueda (rendimiento y latencia) y gestionar los costos. Existen tres configuraciones de Search Power para proyectos de Elasticsearch Serverless. La configuración Performant está activada de forma predeterminada y proporciona una experiencia de búsqueda eficiente para datos de todos los tamaños. Es posible elegir cualquiera de las siguientes configuraciones:
Bajo demanda: se ajusta automáticamente según la carga de datos y búsqueda, con un umbral mínimo más bajo para el uso de recursos. Esta flexibilidad da como resultado una latencia de consulta más variable y una reducción del rendimiento máximo.
Eficiente: proporciona una latencia consistentemente baja y se autoescalará para acomodar un alto rendimiento de consultas moderado.
Alto rendimiento: optimizado para escenarios de alto rendimiento, con autoescalado para mantener la latencia de las consultas incluso con volúmenes de consulta muy altos.
En Elasticsearch Serverless, pagas por los recursos utilizados para gestionar tus cargas de trabajo y necesidades de rendimiento. Tenemos algunos ejemplos para darte una idea de lo que podrías pagar y cómo pensar en los costos.
Ejemplo 1: entorno de desarrollo con 2 GB de datos buscables, 1 % de uso de ingesta (15 minutos al día), 8 % de uso de búsqueda (2 horas al día)
- A demanda: USD 24/mes
- Performant: USD 27/mes
Ejemplo 2: entorno de producción con 20 GB de datos buscables, 5 % de uso de ingesta (1 hora al día), 33 % de uso de búsqueda (8 horas al día)
- A demanda: USD 190/mes
- Performant: USD 210/mes
* Las estimaciones de precios proporcionadas en los ejemplos son únicamente para fines ilustrativos. Los costos reales pueden variar según factores como el tipo de datos, la complejidad de las consultas, los patrones de tráfico, la duración del uso y las configuraciones específicas. Estas estimaciones están destinadas a ayudarte a comprender los posibles escenarios de costos, pero no deben ser consideradas como un costo definitivo. Para cálculos de costos precisos, recomendamos monitorear tu uso.
Descubre todo lo que puedes hacer con Elastic Cloud Serverless

Demostración interactiva
Experimenta lo que ofrece la tecnología sin servidor.

Prueba gratis
Comienza con precios sencillos, orientados a soluciones y según el uso.

