

¿Qué es una base de datos vectorial?
Definición de base de datos vectorial
Una base de datos vectorial es una base de datos que almacena información en forma de vectores, que son representaciones numéricas de objetos de datos, también conocidos como incrustaciones de vectores. Aprovecha el poder de estas incrustaciones de vectores para indexar y buscar en un masivo set de datos no estructurados y datos semiestructurados, como imágenes, texto o datos de sensores. Las bases de datos vectoriales están hechas para gestionar las incrustaciones de vectores y, por lo tanto, ofrecen una solución completa para la gestión de datos no estructurados y semiestructurados.
Una base de datos vectorial es distinta de una biblioteca de búsqueda de vectores o un índice de vectores: es una solución de gestión de datos que permite el almacenamiento y filtrado de metadatos, es escalable, permite cambios de datos dinámicos, realiza backups y ofrece características de seguridad.
Una base de datos vectorial organiza los datos a través de vectores de alta dimensionalidad. Los vectores de alta dimensionalidad contienen cientos de dimensiones, y cada dimensión corresponde a una característica o propiedad específica del objeto de datos al que representa.
¿Qué son las incrustaciones de vectores?
Las incrustaciones de vectores son una representación numérica de un tema, una palabra, una imagen o cualquier otro dato. Las incrustaciones de vectores, también conocidas como incrustaciones, son generadas por modelos de lenguaje grandes y otros modelos de AI.
La distancia entre cada incrustación de vectores es lo que posibilita que una base de datos vectorial, o un motor de búsqueda de vectores, determine la similitud entre los vectores. Las distancias pueden representar varias dimensiones de objetos de datos, lo que permite la comprensión por parte del machine learning y la AI de los patrones, las relaciones y las estructuras subyacentes.
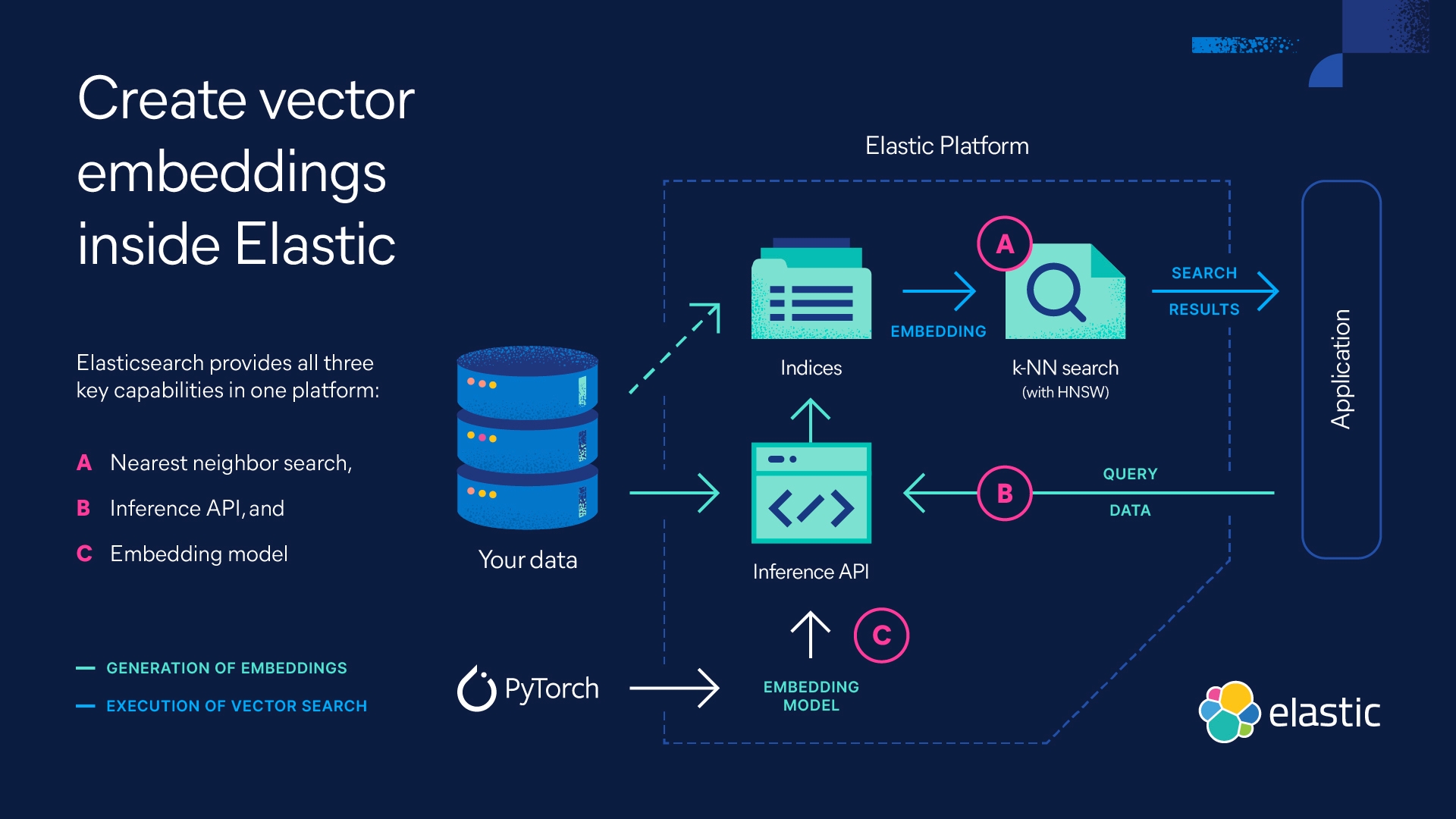
¿Cómo funciona una base de datos vectorial?
Una base de datos vectorial funciona usando algoritmos para indexar y buscar incrustaciones de vectores. Los algoritmos habilitan la búsqueda de vecino más cercano aproximado (ANN) a través del uso de hash, la cuantificación o la búsqueda basada en grafos.
Para recuperar información, una búsqueda de ANN encuentra el vecino vector más cercano de una búsqueda. Además de requerir menos recursos informáticos que una búsqueda kNN (vecino más cercano conocido o algoritmo de vecino más cercano k verdadero), una búsqueda de vecino más cercano aproximado también es menos precisa. Sin embargo, funciona de forma eficiente y a escala para sets de datos grandes de vectores de alta dimensionalidad.
Un pipeline de base de datos vectorial se ve así:
Indexación: Usando técnicas de hash, cuantificación o basadas en grafos, una base de datos vectorial indexa los vectores haciéndoles mapping a una estructura de datos dada. Esto permite una búsqueda más rápida.
- Hashing: Un algoritmo de hash, como el algoritmo de hash sensible a localización (LSH), es más adecuado para una búsqueda de vecino más cercano aproximado, ya que permite obtener resultados rápidos y genera resultados aproximados. LSH usa tablas hash —piensa en un Sudoku— para mapear vecinos más cercanos. Una búsqueda se hasheará en una tabla y luego se comparará con un conjunto de vectores de la misma tabla, a fin de determinar la similitud.
- Cuantificación: Una técnica de cuantificación, como la cuantificación de productos (PQ), desglosará los vectores en partes más pequeñas y representará esas partes con código, y luego volverá a juntarlas. El resultado es una representación de código de un vector y sus componentes. La combinación de estos códigos se conoce como libro de códigos. Cuando se hace la búsqueda, una base de datos vectorial que usa cuantificación desglosará la búsqueda en código y luego la comparará con el libro de códigos para encontrar el código más similar y generar los resultados.
- Basado en grafos: Un algoritmo de grafo, como el algoritmo de mundo pequeño jerárquico navegable (HNSW), usa nodos para representar vectores. Reúne los nodos en clústeres y dibuja líneas o bordes entre nodos similares, creando grafos jerárquicos. Cuando se lanza una búsqueda, el algoritmo recorre la jerarquía de grafos para encontrar nodos que contengan los vectores más similares al vector de la búsqueda.
Una base de datos vectorial también indexará los metadatos de un objeto de datos. Por este motivo, una base de datos vectorial contendrá dos índices: un índice de vectores y un índice de metadatos.
Consulta: Cuando una base de datos vectorial recibe una búsqueda, compara los vectores indexados con el vector de búsqueda para determinar los vecinos de vectores más cercanos. Para establecer los vecinos más cercanos, una base de datos vectorial depende de métodos matemáticos conocidos como medidas de similitud. Existen distintos tipos de medidas de similitud:
- La similitud de coseno establece la similitud en un rango de -1 a 1. Al medir el coseno del ángulo entre dos vectores en un espacio vectorial, se determinan vectores que son diametralmente opuestos (representados por -1), ortogonales (representados por 0) o idénticos (representados por 1).
- La distancia euclidiana determina la similitud en un rango de 0 a infinito midiendo la distancia en línea recta entre los vectores. Los vectores idénticos están representados por 0, mientras que los valores más grandes representan una mayor diferencia entre los vectores.
- Las medidas de similitud de producto punto determinan la similitud de vectores en un rango de menos infinito a infinito. A través de la medición del producto de la magnitud de dos vectores y el coseno del ángulo entre ellos, el producto punto asigna valores negativos a los vectores que apuntan de forma tal que se alejan entre sí, 0 a los vectores ortogonales, y valores positivos a los vectores que apuntan en la misma dirección.
Posprocesamiento: El último paso en un pipeline de base de datos vectorial, a veces, es el posprocesamiento (o posfiltrado), durante el cual la base de datos vectorial usará una medida de similitud diferente para reclasificar los vecinos más cercanos. En esta etapa, la base de datos filtrará los vecinos más cercanos de la búsqueda identificados en la búsqueda según sus metadatos.
Algunas bases de datos vectoriales pueden aplicar filtros antes de ejecutar una búsqueda de vectores. En este caso, se denomina preprocesamiento o prefiltrado.
¿Por qué son importantes las bases de datos vectoriales?
Las bases de datos vectoriales son importantes porque contienen incrustaciones de vectores y permiten establecer un conjunto de capacidades, como la indexación, las métricas de distancia y la búsqueda por similitud. En otras palabras, las bases de datos vectoriales se especializan en la gestión de datos no estructurados y datos semiestructurados. Como resultado, las bases de datos vectoriales son una herramienta vital en el panorama digital de machine learning y AI.
Componentes básicos de las bases de datos vectoriales
Una base de datos vectorial puede tener los siguientes componentes básicos:
- Rendimiento y tolerancia a fallos: Los procesos de sharding y replicación garantizan que una base de datos vectorial tenga buen rendimiento y tolere fallos. El sharding involucra particionar los datos en varios nodos, mientras que la replicación consiste en hacer varias copias de datos en diferentes nodos. En caso de que un nodo falle, esto permite la tolerancia a errores y el rendimiento ininterrumpido.
- Capacidades de monitoreo: Para garantizar el rendimiento y la tolerancia a fallos, una base de datos vectorial requiere el monitoreo del uso de recursos, del rendimiento de las búsquedas y del estado general del sistema.
- Capacidades de control de acceso: Las bases de datos vectoriales también requieren gestión de seguridad de datos. Las normas de control de acceso aseguran el cumplimiento, la responsabilidad y la capacidad de auditar el uso de bases de datos. Esto también significa que los datos están protegidos: pueden acceder a ellos quienes tienen permisos, y se mantiene un registro de la actividad del usuario.
- Escalabilidad y capacidad de ajuste: Buenas capacidades de control de acceso impactan en la escalabilidad y la capacidad de ajuste de una base de datos vectorial. A medida que aumenta la cantidad de datos almacenados, la capacidad de escalar horizontalmente se torna obligatoria. Las distintas tasas de búsqueda e inserción, así como las diferencias en el hardware subyacente, afectan las necesidades de las aplicaciones.
- Múltiples usuarios y aislamiento de datos: De la mano de la escalabilidad y las capacidades de control de acceso, una base de datos vectorial debe admitir múltiples usuarios o multitenencia. En sintonía con esto, las bases de datos vectoriales deben habilitar el aislamiento de datos, de modo que cualquier actividad de los usuarios (como inserciones, eliminaciones o búsquedas) se mantenga privada frente a otros usuarios, a menos que se requiera lo contrario.
- Backups: Las bases de datos vectoriales crean backups de datos con regularidad. Este es un componente clave de una base de datos vectorial en caso de que se produzca una falla en el sistema; en el caso de pérdida o corrupción de datos, los backups pueden ayudar a restaurar la base de datos a un estado anterior. Esto minimiza el tiempo de inactividad.
- API y SDK: Una base de datos vectorial usa las API para ofrecer una interfaz fácil de usar. Una API es una interfaz de programación de aplicaciones, o un tipo de software, que permite a las aplicaciones "hablarse" entre sí a través de solicitudes y respuestas. Las capas de API simplifican la experiencia de búsqueda de vectores. Los SDK, o kits de desarrollo de software, suelen envolver las API. Son los lenguajes de programación que usa la base de datos para comunicarse y administrar. Los SDK contribuyen a un uso sencillo para desarrolladores de bases de datos vectoriales, ya que no tienen que preocuparse por la estructura subyacente al desarrollar casos de uso específicos (búsqueda semántica, sistemas de recomendaciones, etc.).
¿Cuál es la diferencia entre una base de datos vectorial y una base de datos tradicional?
Una base de datos tradicional almacena información de manera tabulada e indexa los datos asignando valores a los puntos de datos. Al ser consultada, una base de datos tradicional devolverá resultados que coincidan exactamente con la búsqueda.
Una base de datos vectorial almacena vectores en forma de incrustaciones y permite la búsqueda de vectores, lo que devuelve resultados de búsqueda basados en métricas de similitud (en lugar de coincidencias exactas). Una base de datos vectorial "da un paso al frente" donde una base de datos tradicional no puede: está diseñada intencionadamente para operar con incrustaciones de vectores.
Una base de datos vectorial también es más adecuada que una base de datos tradicional en ciertas aplicaciones, como la búsqueda por similitud, la inteligencia artificial y las aplicaciones de machine learning, porque permite hacer una búsqueda de alta dimensionalidad e indexación personalizada, y porque es escalable, flexible y eficiente.
Aplicaciones de las bases de datos vectoriales
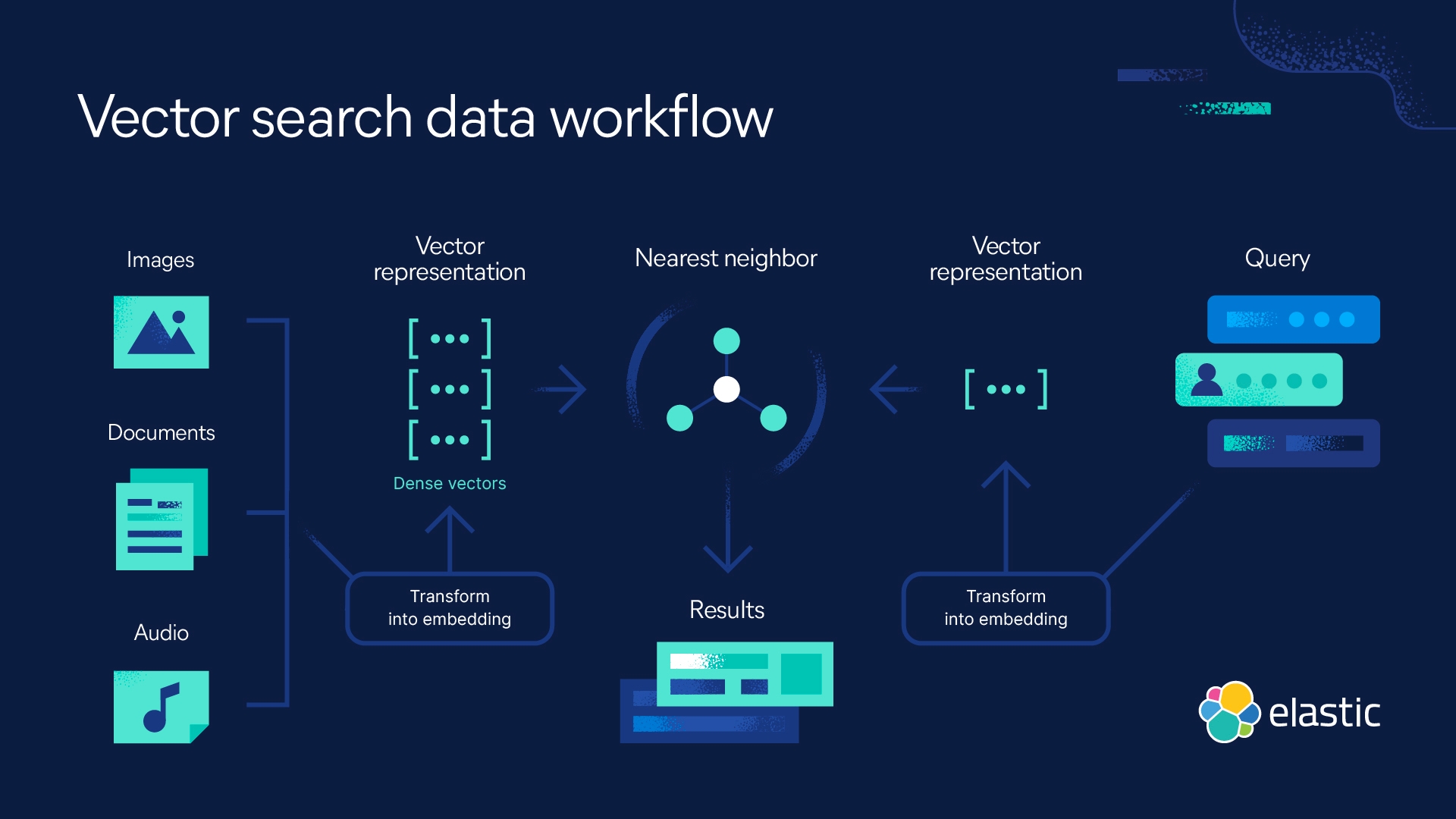
Las bases de datos vectoriales se utilizan en aplicaciones de AI, machine learning (ML), procesamiento de lenguaje natural (NLP) y reconocimiento de imágenes.
- Aplicaciones de AI/ML: Una base de datos vectorial puede mejorar las capacidades de AI con recuperación de información semántica y memoria a largo plazo.
- Aplicaciones de NLP: Búsqueda por similitud de vectores, un componente clave de las bases de datos vectoriales, es útil para las aplicaciones de procesamiento de lenguaje natural. Una base de datos vectorial puede procesar incrustaciones de texto, lo que permite a una computadora "entender" el lenguaje humano (o natural).
- Aplicaciones de reconocimiento y recuperación de imágenes: Las bases de datos vectoriales transforman las imágenes en incrustaciones de imágenes. Con la búsqueda por similitud, pueden recuperar imágenes similares o identificar imágenes que coincidan.
Las bases de datos vectoriales también pueden servir a aplicaciones de detección de anomalías y detección de rostros.
Conoce cómo las bases de datos vectoriales impulsan la búsqueda de AI. Mira nuestro webinar y descubre cómo crear una experiencia de búsqueda moderna para tu proyecto.
Tendencias futuras en las bases de datos vectoriales
El futuro de las bases de datos vectoriales está íntimamente relacionado con el desarrollo de la AI y el ML, así como con la investigación relacionada con el uso del aprendizaje profundo para generar incrustaciones más poderosas para datos estructurados y no estructurados1.
A medida que progresa la capacidad para crear mejores incrustaciones, la capacidad de una base de datos vectorial para procesar y gestionar mejor estas incrustaciones requiere nuevas técnicas y algoritmos. De hecho, métodos nuevos de este tipo están en constante desarrollo.
La investigación adicional está dedicada al desarrollo de bases de datos híbridas. Su objetivo es combinar el poder de las bases de datos relacionales tradicionales y las bases de datos vectoriales a modo de respuesta ante la creciente necesidad de tener bases de datos escalables y eficientes.
Base de datos vectorial para Elasticsearch
Elasticsearch incluye una base de datos vectorial para la búsqueda de vectores. Elastic permite a los desarrolladores crear sus propios motores de búsqueda de vectores con Elasticsearch Relevance Engine (ESRE).
Con las herramientas de Elasticsearch, puedes crear un motor de búsqueda de vectores que pueda buscar datos estructurados y no estructurados, aplicar filtros y facetting, aplicar búsqueda híbrida en datos de vectores y texto, y usar la seguridad a nivel de campo y documento, todo esto mientras se ejecuta en forma local, en el cloud o en entornos híbridos. La base de datos vectorial de Elasticsearch y Search AI Platform ofrecen a los desarrolladores capacidades integrales de búsqueda híbrida y acceso a innovaciones de los principales proveedores de LLM. Con el área de pruebas de bajo código de Elastic, los desarrolladores pueden probar rápidamente los LLM con sus propios datos privados en cuestión de minutos.
Explora más recursos de bases de datos vectoriales
Notas al pie
1 Gu, Huaping. "Unleashing the Power of Vectors: Embeddings and Vector Databases - Linkedin." LinkedIn, 2 de abril de 2023, www.linkedin.com/pulse/unleashing-power-vectors-embeddings-vector-databases-huaping-gu