Jina AI models
State-of-the-art models for each stage of the retrieval pipeline
Purpose-built for retrieval, Jina models deliver accuracy and speed that outperforms models 5× their size. Multilingual, multimodal — text, images, audio, and video — and now native on Elasticsearch.

Meet the Jina AI models
Our frontier models form the search foundation for high-quality enterprise search and retrieval augmented generation (RAG) systems.



Compact by design, precise by results
Go from raw data to high-precision results in one API.

Use Jina models wherever you build
From fully managed to self-hosted, Jina models meet you where your data lives. Pick the access path that fits.



Our research




Join our open source community
Jina's models are open-weight and freely available on Hugging Face, with millions of monthly downloads. The codebase is public on GitHub. The community has direct access to our developers.




Frequently asked questions
Jina models are open source, frontier AI models for retrieval. They include embedding models for vectors, rerankers for precision, and readers for extracting and structuring content from URLs and docs.
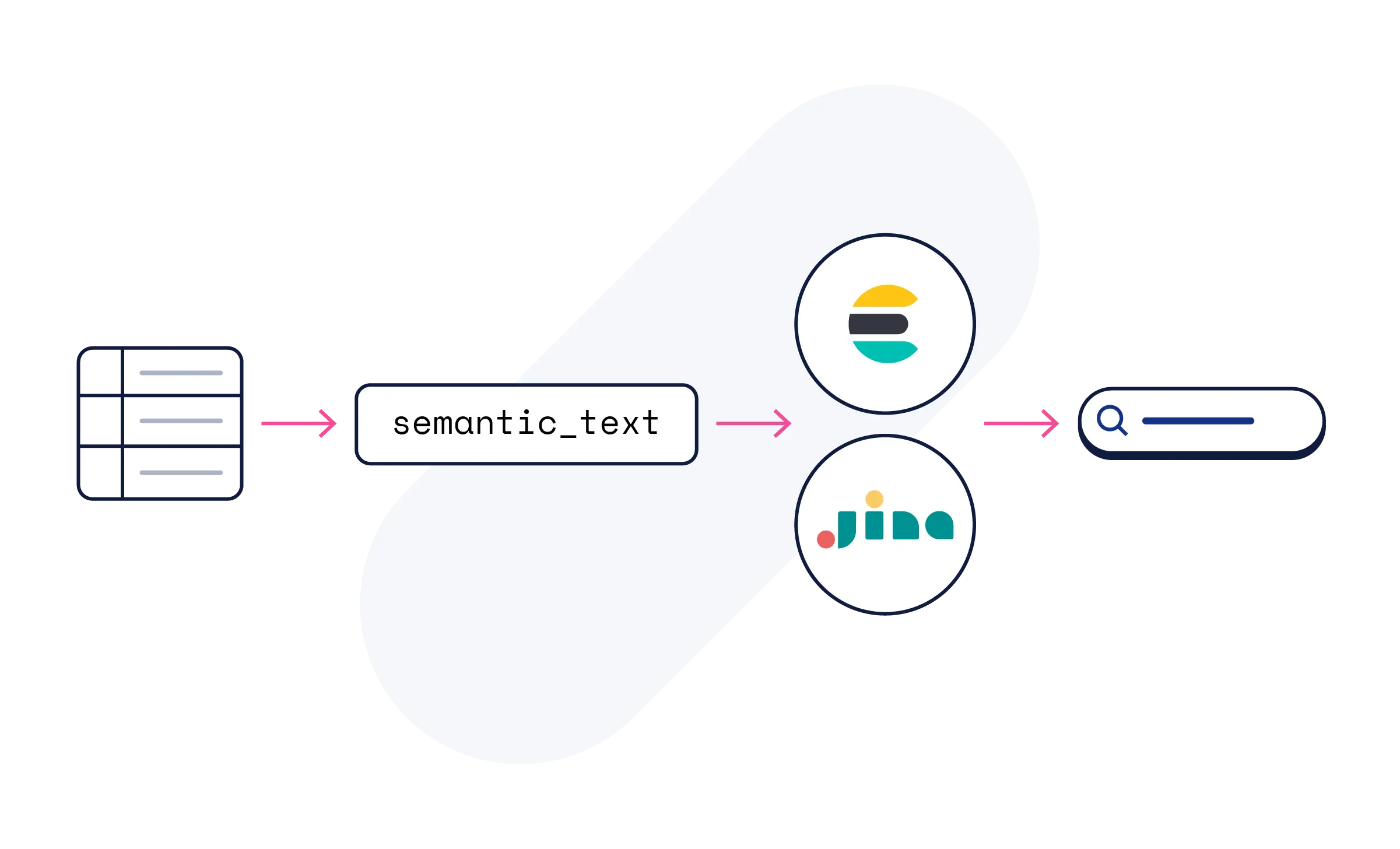
No. Use Elasticsearch's semantic_text field, and the AI processing happens automatically. Jina's models make your content semantically searchable — no model configuration or ML expertise required.
Jina models are available on Elastic Inference Service on Elastic Cloud included in all trials. Start with semantic_text, or explore model sub-pages for code examples, API references, and tutorials.
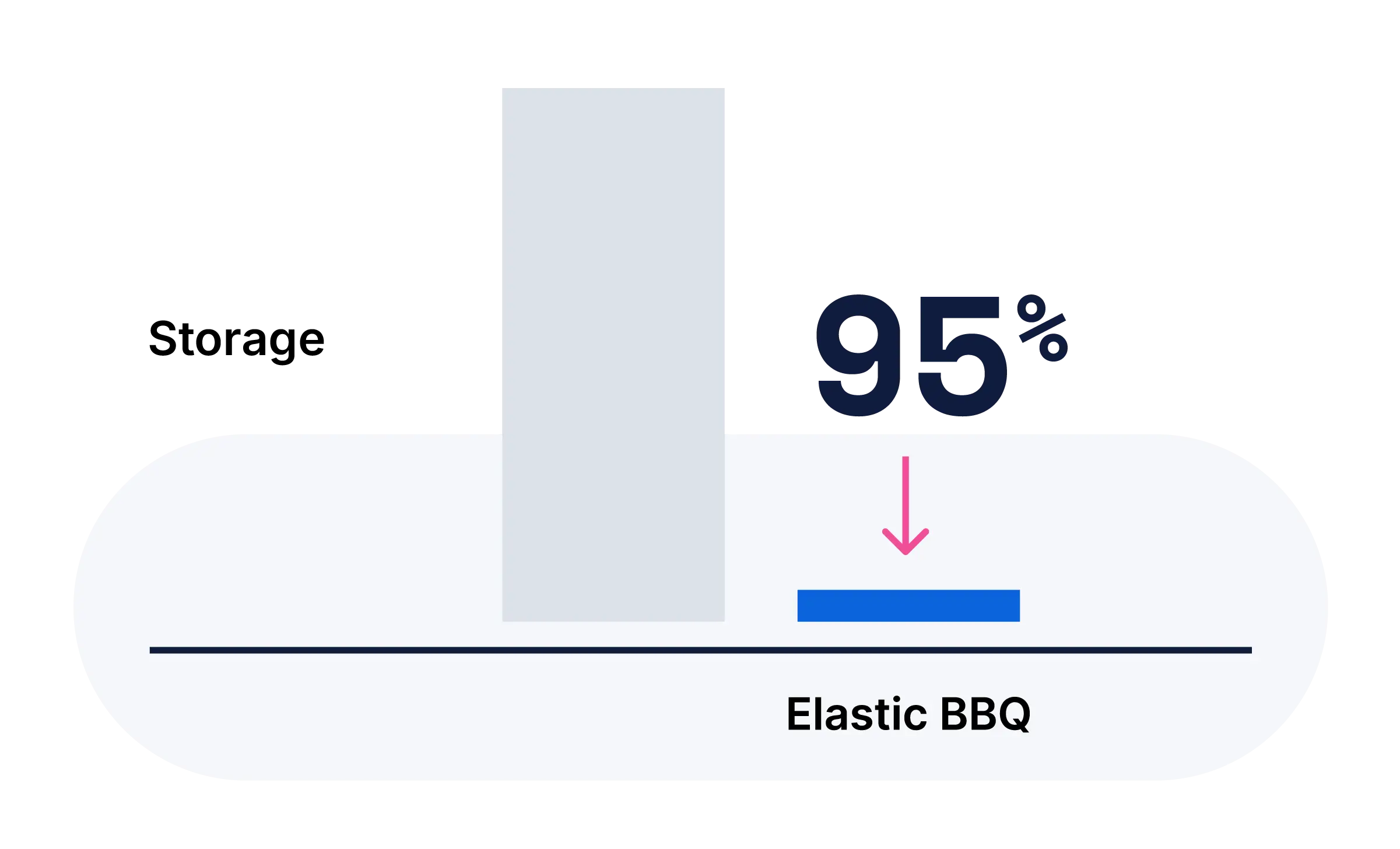
Our latest v5-text (nano/small) features 32K context, Matryoshka dimensions, and the latest architecture — alongside Jina-embeddings-v3 and Reranker v2 and v3 — all available on Elastic Inference Service.
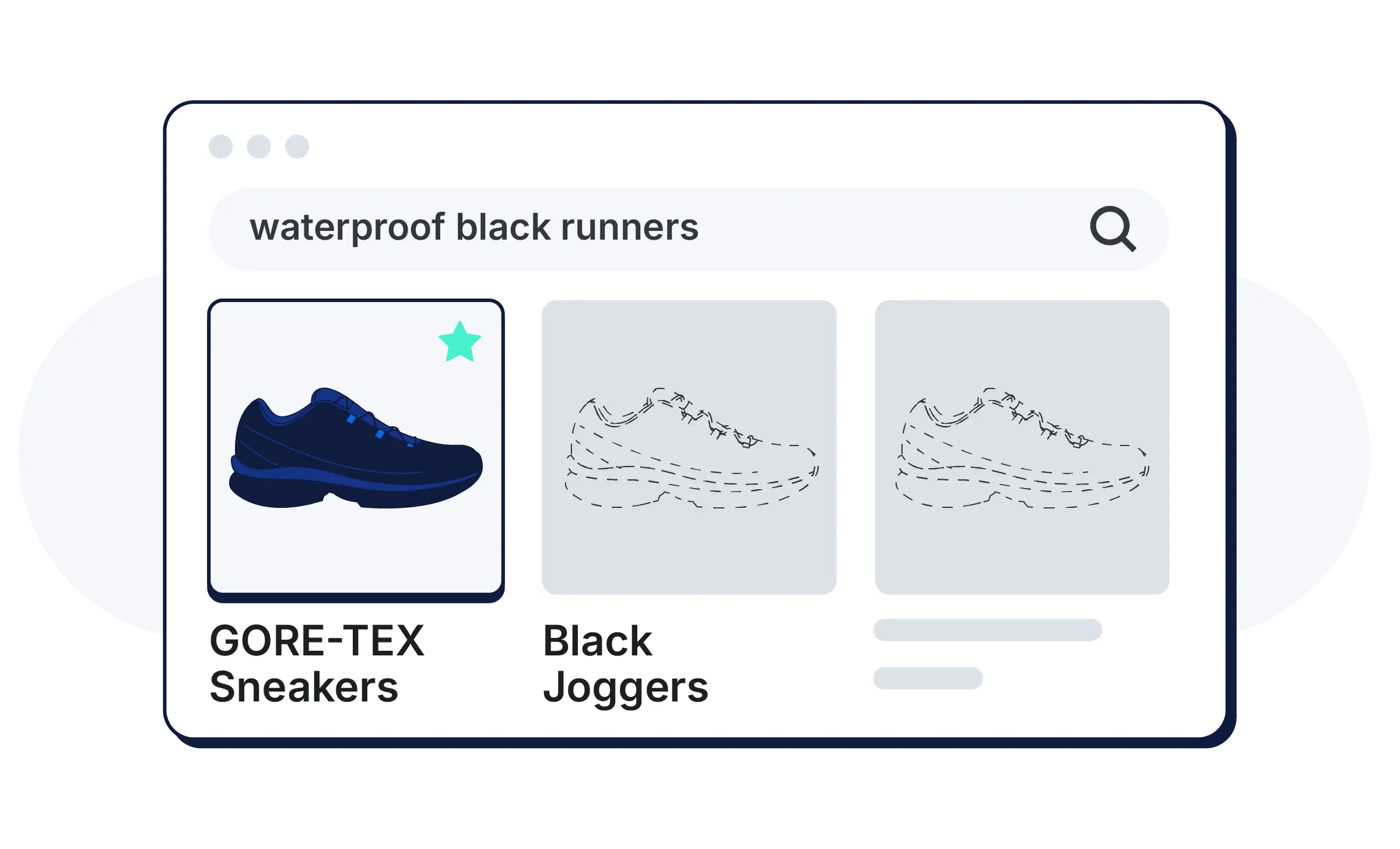
Jina-embeddings-v5-text supports 30+ languages — a query in one language finds relevant content written in another, with no translation pipelines required.
ELSER covers English-language semantic search. Jina adds multilingual coverage across 30+ languages with leading accuracy — both work within Elasticsearch's hybrid search framework.
No. Jina search models on the Elastic Inference Service are available to all Elastic Cloud users with consumption-based pricing. No separate license, subscription, or API key required.
The vector database page covers how vectors are stored and searched at scale. This page covers the AI models that generate and rerank them. Together: storage, compute, and application.

