Context engineering is easy with Elasticsearch, we will demonstrate that using Mistral Chat completions.
Throwing axes from a skateboard
I have vivid memories of me playing Super Adventure Island, a Super Nintendo game that featured a caveman character on a skateboard throwing stone axes at enemies. However, none of the LLMs I asked, by the time of this writing, could tell me what game that was. In this blog, I will show you how to influence LLMs by using some context engineering.
Why is this important? Enterprises often deal with complex domain-specific knowledge—product catalogs, internal documentation, regulations, or customer support data. Out-of-the-box LLMs might give generic answers. By applying Context Engineering, you ensure the model’s responses are grounded in your company’s data, increasing reliability and trust, of course it works for video game titles as well.
Contextualizing context engineering
We can outline context as a set of attributes that are intended to skew or influence the data passed to an LLM, to ground its responses. Context engineering is then considered the practice of carefully designing, structuring, and selecting these contextual attributes so that the LLM produces outputs that are more accurate, relevant, or aligned with a specific goal.
As Dexter Horthy outlines as his 3rd principal of 12-Factor Agents, it's important to own your context to ensure LLMs generate the best outputs possible.
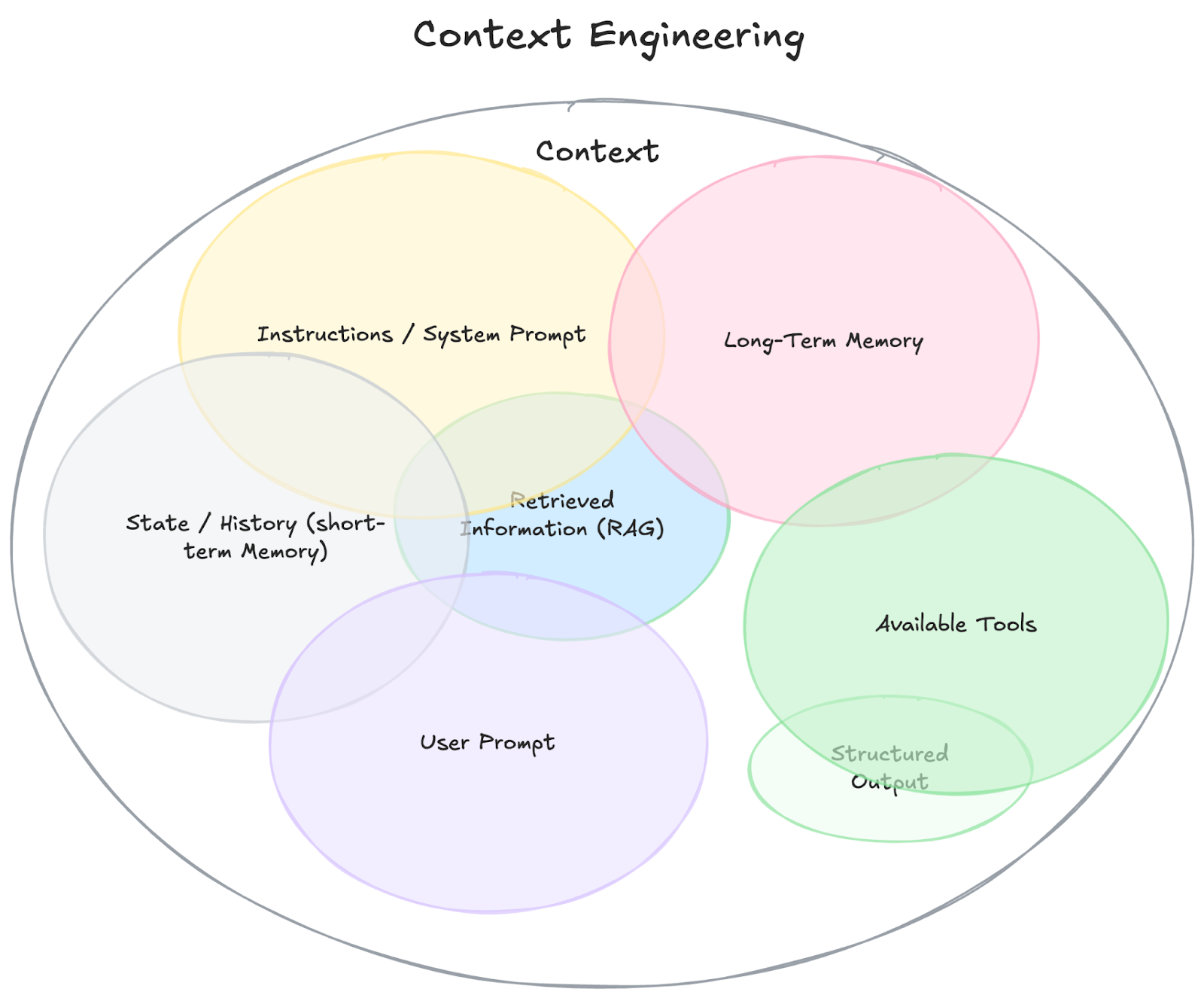
It’s effectively a combination of prompt design, data curation, and system instruction tuning, aimed at controlling the behavior of the model without modifying its underlying parameters.
Using Mistral Chat completions in Elasticsearch
You can run all the code below on the mistral-chat-completions.ipynb notebook. We are going to ask Mistral about Super Nintendo games from the 90’s, and then try to skew its response towards mentioning a very popular game called Super Adventure Island.
Install Elasticsearch
Get Elasticsearch up and running either by creating a cloud deployment (instructions here) or by running it in Docker (instructions here).
Assuming you are using the cloud deployment, grab the API Key and the Elasticsearch host for the deployment as mentioned in the instructions. We will use them later.
Get a Mistral API key
To call Mistral models from Elasticsearch you need:
- A Mistral account (La Plateforme / console).
- An API key created in your console (the key is displayed once — copy it and store it securely).
Mistral also announced a free API tier and pricing adjustments, so there’s often a free or low-cost way to start.
Testing
We can use Dev Tools to test the _inference endpoint creation and the _stream API. The inference endpoint can be created like below:
PUT _inference/chat_completion/mistral-embeddings-chat-completion
{
"service": "mistral",
"task_type": "chat_completion",
"service_settings": {
"api_key": "--yourmistralapikey--",
"model": "mistral-large-latest"
}
}Now let’s ask Mistral about Super Nintendo games from the 90s, but let’s pick one that is not popular at all. There was a game called Super Adventure Island that featured a character on a skateboard throwing stone axes. We will use _inference/chat_completion API to stream the response.
POST _inference/chat_completion/mistral-embeddings-chat-completion/_stream
{
"messages": [
{
"role": "system",
"content": "You are a helpful gaming expert that provides concise answers about video games."
},
{
"role": "user",
"content": "What SNES games had a character on a skateboard throwing stone axes?"
}
]
}Unsurprisingly, the answer will not mention Super Adventure Island, since it’s not a popular game; instead, Mistral would answer with games like Joe & Mac (featuring stone axes but not skateboards) and will tell you that there is no game featuring both. Note: This is not Mistral’s fault necessarily, as none of the other LLMs we tested answered with the correct game.
The response structure is like below, with:
event: The type of event being sent (here always "message").
data: The JSON payload with the actual chunk of response
event: message
data: {
"id" : "8135d95c85b4475e8099b8e9aab42315",
"choices" : [
{
"delta" : {
"content" : "There's one",
"role" : "assistant"
},
"index" : 0
}
],
"model" : "mistral-large-latest",
"object" : "chat.completion.chunk"
}
event: message
data: {
"id" : "8135d95c85b4475e8099b8e9aab42315",
"choices" : [
{
"delta" : {
"content" : "notable SNES game"
},
"index" : 0
}
],
"model" : "mistral-large-latest",
"object" : "chat.completion.chunk"
}
event: message
data: {
"id" : "8135d95c85b4475e8099b8e9aab42315",
"choices" : [
{
"delta" : {
"content" : "but without"
},
"index" : 0
}
],
"model" : "mistral-large-latest",
"object" : "chat.completion.chunk"
}
...
event: message
data: {
"id" : "8135d95c85b4475e8099b8e9aab42315",
"choices" : [
{
"delta" : {
"content" : " match."
},
"finish_reason" : "stop",
"index" : 0
}
],
"model" : "mistral-large-latest",
"object" : "chat.completion.chunk",
"usage" : {
"completion_tokens" : 100,
"prompt_tokens" : 34,
"total_tokens" : 134
}
}
event: message
data: [DONE]Note that the final object also contains metadata like finish_reason and usage. Our notebook will take care of parsing this structure and displaying it like text from a chat.
Running the example
You will need the ELASTICSEARCH_HOST,ELASTICSEARCH_API_KEY and MISTRAL_API_KEY credentials set in the mistral-chat-completions.ipynb notebook, first and foremost.
# Credentials - Enter your API keys securely
ELASTICSEARCH_URL = getpass.getpass("Enter your Elasticsearch URL: ").strip()
ELASTICSEARCH_API_KEY = getpass.getpass("Enter your Elasticsearch API key: ")
MISTRAL_API_KEY = getpass.getpass("Enter your Mistral API key: ")The model we are using is the mistral-large-latest, set in MISTRAL_MODEL - the list of available models can be found at Mistral’s Models Overview,
# Configurations, no need to change these values
MISTRAL_MODEL = "mistral-large-latest"
INFERENCE_ENDPOINT_NAME = (
"mistral-embeddings-chat-completion"
)The notebook has code to send requests to Elasticsearch, parse the response, and stream it in the console. Let's ask the question again, now using Python.
user_question = "What SNES games had a character on a skateboard and stone axes?"
messages = [
{"role": "system", "content": "You are a helpful gaming expert that provides concise answers about video games."},
{"role": "user", "content": user_question}
]
print(f"User: {user_question}")
print("Assistant: \n")
for chunk in stream_chat_completion(ELASTICSEARCH_URL, INFERENCE_ENDPOINT_NAME, messages):
print(chunk, end="", flush=True)
Engineering the context for Mistral with Elasticsearch
Alongside the notebook we have a dataset called snes_games.csv containing all 1700+ Super Nintendo Games, including title, publisher, category, year of release in both United States and Japan and a short description - this will serve as our internal database, which we are going to index to Elasticsearch like so:
INDEX_NAME = "snes-games"
snes_mapping = {
"mappings": {
"properties": {
"id": {"type": "keyword"},
"title": {"type": "text", "copy_to": "description_semantic"},
"publishers": {"type": "keyword"},
"year_US": {"type": "keyword"},
"year_JP": {"type": "keyword"},
"category": {"type": "keyword", "copy_to": "description_semantic"},
"description": {"type": "text", "copy_to": "description_semantic"},
"description_semantic": {"type": "semantic_text"}
}
}
}Note, we are copying title, category, and description fields to description_semantic (of type semantic_text); this is all we need to generate sparse vector embeddings for our fields without requiring separate embedding models or complex vector operations - it uses ELSER.
Semantic search
Once we indexed our dataset (follow the notebook for details), we are ready to search on the index. There are many ways to combine lexical search with semantic search, but for this example we are going to use only description_semantic field to issue a semantic search query:
search_body = {
"size": max_results,
"query": {
"semantic": {
"field": "description_semantic",
"query": query
}
}
}The initial results are encouraging; the same query, "What SNES games had a character on a skateboard throwing axes?", successfully identifies the game we're seeking, including the previously unknown (to me) Super Adventure Island II or 高橋名人の大冒険島II in Japan!
Searching for: 'What SNES games had a character on a skateboard throwing axes?'
1. Super Adventure Island II•Takahashi Meijin no Daibouken Jima II - In Adventure Island II, Master Higgins keeps his stone axe and skateboard but also gains the help of four dinosaur companions, each with unique abilities on land, sea, or air. Players collect fruit to stay alive, find eggs for power-ups, and ride dinos to tackle tougher stages with new variety. (Score: 19.44)
2. Super Adventure Island•Takahashi Meijin no Daibouken Jima - In this Adventure Island entry, Master Higgins wields either his classic stone axe or a boomerang, with fireballs as power-ups. He can super-jump, but no longer runs faster like in the NES. Higgins must collect fruit to survive, and can ride a skateboard to speed through stages. (Score: 19.14)
3. Frogger - Frogger is a classic arcade game brought to the SNES by Morning Star Multimedia and Majesco Entertainment. Players guide a frog across busy roads and rivers, avoiding obstacles to reach safety. (Score: 10.63)
4. Kikuni Masahiko no Jantoushi Dora Ou 2 - Board game (Score: 9.58)
5. Kindai Mahjong Special - Board game (Score: 9.58)Now that we have more domain knowledge available, we are ready to feed this data to Mistral to help it make better responses, but without completely taking over Mistral’s ability to reason.
RAG chat as part of context engineering
Here is a simple RAG-augmenting function to include our search results (the full document _source) in the context:
def rag_chat(user_question: str, max_context_docs: int = 10) -> str:
context_docs = search_documents(user_question, max_context_docs)
context_text = ""
if context_docs:
context_text = "\n\nRelevant context information:\n"
for i, doc in enumerate(context_docs, 1):
context_text += f"\n{i}. {doc['_source']}\n"
system_prompt = """
You are a helpful assistant that answers about Super Nintendo games.
Use the provided context information to answer the user's question accurately.
If the context doesn't contain relevant information, you can use your general knowledge mixed with the context,
Treat the context as your general knowledge in the answer"""
user_prompt = user_question
if context_text:
user_prompt = f"{context_text}\n\nQuestion: {user_question}"
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
]
full_response = ""
for chunk in stream_chat_completion(ELASTICSEARCH_URL, INFERENCE_ENDPOINT_NAME, messages):
print(chunk, end="", flush=True)
full_response += chunk
return full_responseAsking again, we get a much more concise, and grounded, response:
Based on the provided context, the **Super Adventure Island** series on the SNES features a character (Master Higgins) who uses a **skateboard** and **axes**:
1. **Super Adventure Island (1992)** â Master Higgins wields a **stone axe** (or boomerang) and can ride a **skateboard** to speed through stages.
2. **Super Adventure Island II (1995)** â Master Higgins keeps his **stone axe** and **skateboard**, while also gaining dinosaur companions for additional abilities.
These are the only SNES games in the given context that match your description.Conclusion
We have covered most of context engineering with user prompt, instructions/system prompt, and RAG, but this example can be extended to include short and long-term memory as well, as they can be easily represented as documents in a separate index in Elasticsearch itself.
Learn more about what we covered in this blog:
Elasticsearch Inference Endpoint API
Perform chat completion inference
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content

October 23, 2025
Low-memory benchmarking in DiskBBQ and HNSW BBQ
Benchmarking Elasticsearch latency, indexing speed, and memory usage for DiskBBQ and HNSW BBQ in low-memory environments.

October 23, 2025
Semantic search with GPU inference in Elastic
Learn how Elastic's EIS leverages GPU inference and ELSER to power fast, accurate semantic search.
October 23, 2025
Elastic's Kibana navigation refresh in 9.2 from user feedback
Learn how the Elastic team made it easier to navigate in Kibana 9.2 with an on-hover menu access, a visible menu in collapsed mode, and icon-driven navigation.
October 24, 2025
A new era for Elastic Discover: ES|QL, context & multi-tabs
Learn about the evolution of Elastic's Discover, covering ES|QL integration, context-aware querying, multi-exploration tabs, and the new CRUD experience in 9.2.

October 16, 2025
Elasticsearch Inference API adds open customizable service
Learn how to leverage the new custom service integration with the Elasticsearch Open Inference API for seamless REST API model integration.