In the world of AI-powered search, three things matter above all else: query speed, ranking accuracy, and the cost of the resources required to achieve them. At Elastic, we're constantly pushing the boundaries on all three fronts. I'm excited to share two recent dense vector search improvements in Elasticsearch 9.1: a novel algorithm named ACORN for faster filtered vector search, and new evidence showing our default quantization method, BBQ, not only reduces costs but can actually improve ranking quality.
ACORN: A smarter path to filtered search
Real-world search is rarely a simple "find me things like this." It’s "find me products like this in my size," or "find me documents similar to this one from last quarter." Even avoiding deleted documents is a filter, so in practice, filtered search is a very common scenario.
Making filtered vector search fast without compromising accuracy is a deep technical challenge. The HNSW algorithm is based on a graph search in which nodes represent vectors. The graphs are constructed during indexing and not per query. When supporting pre-filter, for accurate result sets, as Elasticsearch does, the naive method for filtered search is to traverse the graph and only collect nodes that pass the filter. The problem with that naive approach is that nodes are being evaluated even if they do not pass the filter in order to continue the search to their neighboring nodes and to the rest of the graph, resulting in a slower search. This phenomenon is significant in restrictive filters, when the majority of documents do not pass the filter. We had a partial solution for that even before, but we thought we could do better.
We chose to use the ACORN-1 (ANN Constraint-Optimized Retrieval Network), a new algorithm described in an academic article published in 2024, for performing filtered k-Nearest Neighbor (kNN) search. ACORN works by integrating the filtering process directly into the HNSW graph traversal. With ACORN-1, only nodes that are accepted by the filter are evaluated, but to reduce the chances of missing relevant sections of the graph, the second-level neighbors, i.e., the neighbors of the neighbors, are also evaluated (if the filter accepts them). The implementation in Lucene used by Elasticsearch includes certain heuristics to further improve the results (detailed in this blog).
When choosing the specific algorithm and implementation, we explored other alternatives that have theoretical potential to even further improve latency, and decided not to pursue them because they force the user to declare prior to indexing the fields that will be used for filtering. We value the flexibility to define the filtering fields after documents are ingested because in real life indices evolve. The potential minor gain did not justify the loss of flexibility and we can gain the performance using other means, like BBQ (see below).
The results are a step-change in performance. We've measured typical speedups of 5x, with some highly selective filters showing much higher improvement. This is a massive enhancement for the complex, real-world queries. All you need to do to benefit from ACORN-1 is to perform filtered vector queries in Elasticsearch.
BBQ: The surprising superpower of better ranking
Reducing the memory footprint of vectors is crucial for building scalable, cost-effective AI systems. Our Better Binary Quantization (BBQ) method achieves this by compressing high-dimensional float vectors by a factor of ~32x. We've previously discussed how BBQ is superior to other techniques like Product Quantization in terms of recall, latency, and cost in our Search Labs blogs:
- Better Binary Quantization (BBQ) in Lucene and Elasticsearch
- How to implement Better Binary Quantization (BBQ) into your use case and why you should
- Better Binary Quantization (BBQ) vs. Product Quantization
The intuitive assumption, however, is that such a dramatic, lossy compression must come at the cost of ranking quality. Our recent extensive benchmark consistently shows we can completely compensate for that by exploring greater parts of the graph and reranking, and so achieve improvement not only in cost and performance, but also in relevance ranking.
BBQ isn't just a compression trick; it’s a sophisticated two-stage search process:
- Broad scan: First, it uses the tiny, compressed vectors to rapidly scan the corpus and identify a set of top-ranking documents. The size of the set is bigger than the number of top-ranking documents that the user requests (oversampling).
- Precise reranking: Then, it takes the top candidates from this initial scan and reranks them using their original, full-precision float32 vectors to determine the final order.
This process of oversampling and reranking acts as a powerful corrective, often finding highly relevant results that a pure float32 HNSW search, in its more limited traversal of the graph, might have missed.
The proof is in the ranking
To measure this, we used NDCG@10 (Normalized Discounted Cumulative Gain at 10), a standard metric that evaluates the quality of the top 10 search results. A higher NDCG score means more relevant documents are ranked higher. You can learn more about this in our ranking evaluation API documentation.
We ran several benchmarks across 10 public datasets from the BEIR data sets, comparing traditional BM25 search, vector search with the e5-small model (float32 vectors), and vector search with the same model using BBQ. We chose e5-small because we know from previous benchmarks that BBQ is at its best with high vector dimensionality, so we wanted to benchmark it where it struggles, with rather low-dimensional vectors like e5-small produces. We measured using NDCG@10, which is a ranking quality metric that takes into account the order of the results. Below is a representative example of the results we saw.
| Data set | BM25 | e5-small float32 | e5-small BBQ with defaults |
|---|---|---|---|
| Climate-FEVER | 0.143 | 0.1998 | 0.2059 |
| DBPedia | 0.306 | 0.3143 | 0.3414 |
| FiQA-2018 | 0.251 | 0.3002 | 0.3136 |
| Natural Questions | 0.292 | 0.4899 | 0.5251 |
| NFCorpus | 0.321 | 0.2928 | 0.3067 |
| Quora | 0.808 | 0.8593 | 0.8765 |
| SCIDOCS | 0.155 | 0.1351 | 0.1381 |
| SciFact | 0.683 | 0.6569 | 0.677 |
| Touché-2020 | 0.337 | 0.2096 | 0.2089 |
| TREC-COVID | 0.615 | 0.7122 | 0.7189 |
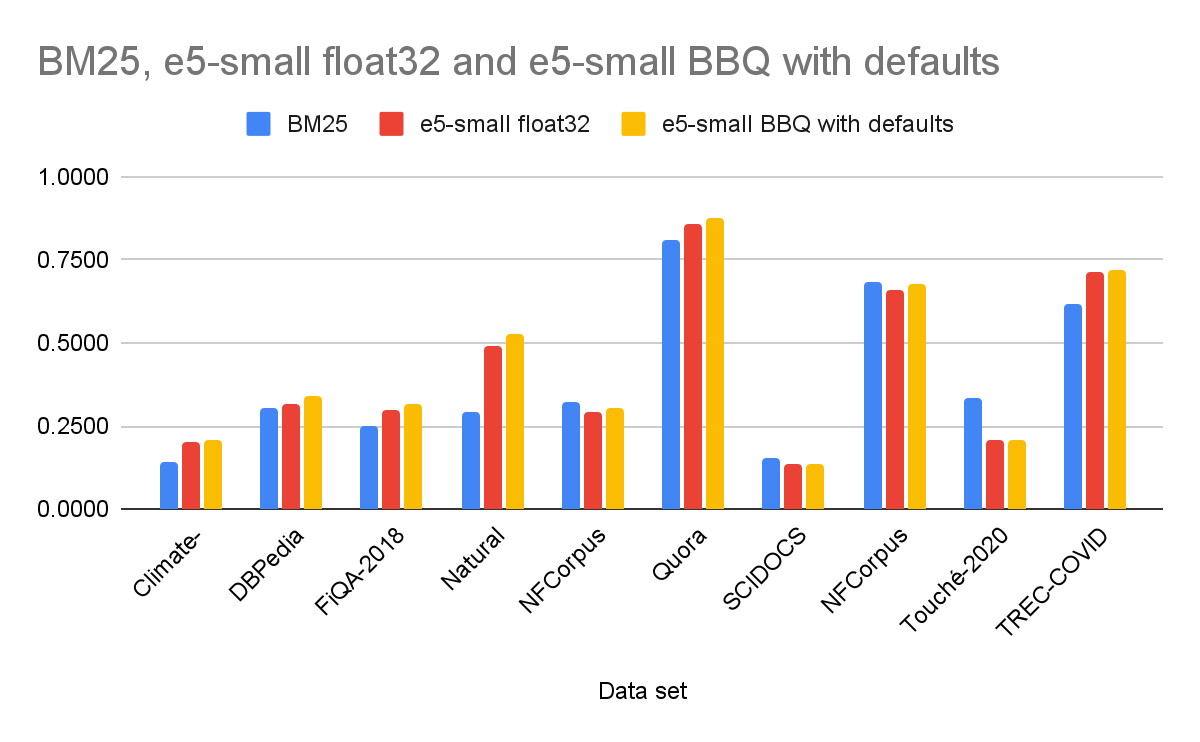
The results are stunning. BBQ achieved better ranking quality than pure float32 search in 9 out of the 10 datasets. Even in the single exception, the difference was negligible. Furthermore, BBQ was the top-performing method overall in 6 of the 10 sets. As a sidenote, often the best ranking is obtained by using a hybrid of BM25 and vector queries, plus other factors like distance, time, and popularity, and Elasticsearch excels in these types of queries.
One may ask how BBQ provides better ranking than float32, since BBQ is a lossy compression. Sure with BBQ we oversample and rerank by the float32 vector, but that shouldn’t matter, since conceptually, with float32, we rank all the documents using the float32 vectors. The answer is that with HNSW we only evaluate a smaller number of vectors per shard, which is defined in the parameter we call num_candidates. The default num_candidates when no quantization is performed is 1.5*k, with k being the number of results returned to the user. You can read more about the benchmarks we performed to get to that default here. When we are quantizing to BBQ, the comparison of vectors is faster and we can afford a larger num_candidates while still reducing latency, so after some benchmarking work we set the default num_candidates for BBQ to max(1.5*k, oversample*k).
For the benchmark above, that relies on our defaults, and in which k=10, we calculate num_candidates as follows:
- Float32: 1.5*k = 1.5*10 = 15
- BBQ: max(1.5*k, oversample*k) = max(1.5*10, 3*10) = 30
Because of the difference in num_candidates, we scan a greater part of the HNSW graphs when using BBQ and get better candidates in the top 30 that are reranked by float32, which explains how BBQ provides better ranking quality. You can set num_candidates for your needs (e.g., see here), or, like most users, you can trust our benchmarks, and rely on the defaults.
This addresses a question I received from a consultant: "Is it better to use e5-large with BBQ or e5-small with float32?" The answer is now unequivocally clear. Using a more powerful model like e5-large with BBQ gives you the best of all worlds:
- Better ranking: From the superior e5-large model, further enhanced by BBQ.
- Lower latency: From the highly efficient BBQ search process.
- Lower cost: From the 32x memory reduction.
It’s a win-win-win, demonstrating that you don't have to trade quality for cost.
Because of this proven superiority, we have made BBQ the default quantization method for dense vectors of 384 dimensions or higher in Elasticsearch 9.1. We recommend this for most modern embedding models, which tend to distribute vectors well across the available space, making them ideal for BBQ's approach.
Get started today
These advancements in ACORN and BBQ empower you to build more powerful, scalable, and cost-effective AI applications on Elastic. You can execute complex, filtered queries at high speed while simultaneously improving ranking relevance and dramatically reducing memory costs.
Upgrade to Elasticsearch 9.1 to take advantage of these new capabilities.
- Learn more about kNN search and vector quantization in our documentation.
- Dive deep into ranking quality with our Ranking Evaluation API
We handle the complexity so you can focus on building incredible search experiences. Happy searching.
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content

October 23, 2025
Low-memory benchmarking in DiskBBQ and HNSW BBQ
Benchmarking Elasticsearch latency, indexing speed, and memory usage for DiskBBQ and HNSW BBQ in low-memory environments.

October 23, 2025
Semantic search with GPU inference in Elastic
Learn how Elastic's EIS leverages GPU inference and ELSER to power fast, accurate semantic search.
October 23, 2025
Elastic's Kibana navigation refresh in 9.2 from user feedback
Learn how the Elastic team made it easier to navigate in Kibana 9.2 with an on-hover menu access, a visible menu in collapsed mode, and icon-driven navigation.
October 24, 2025
The evolution of Elastic's Discover, from ESQL to context awareness
Learn about the evolution of Elastic's Discover, covering ES|QL integration, context-aware querying, multi-exploration tabs, and the new CRUD experience in 9.2.

October 16, 2025
Elasticsearch Inference API adds open customizable service
Learn how to leverage the new custom service integration with the Elasticsearch Open Inference API for seamless REST API model integration.