It's my pleasure to announce LOOKUP JOIN—a new ES|QL command available in tech preview in Elasticsearch 8.18, designed to perform left joins for data enrichment. With ES|QL, one can query and combine documents from one index with documents from a second index based on a criterion defining how the documents should be paired natively in Elasticsearch. This approach enhances data management by dynamically correlating documents at query time across multiple indices, thus removing duplication.
For instance, the following query connects employee data from one index with their corresponding department information from another index using a shared field key name:
FROM employees
| LOOKUP JOIN departments ON dep_idAs the name indicates, LOOKUP JOIN performs a complementing, or left (outer), join at query time between any regular index (employees) - the left side and any lookup index (departments) - the right side. All the rows from the left side are returned along with their corresponding equivalent (if any) from the right side.
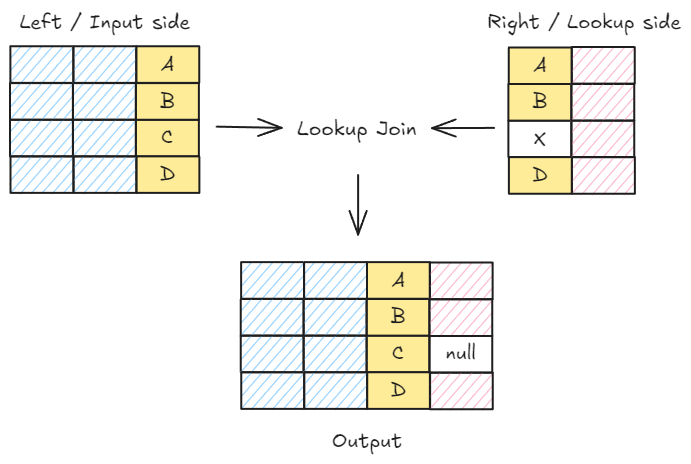
The lookup side's index mode must be set to lookup. This means that the underlying index can only have one shard. This current solution addresses the cardinality challenges of one side of the join and the issues that distributed systems like Elasticsearch encounter, which are outlined in the next section.
Apart from using the lookup index mode, there are no limitations on the source data or the commands used. Additionally, no data preparation is needed.
The join can be performed before or after the filtering:
// associate employees hired in the last year in departments in US and sort by department name
FROM employees
| WHERE hire_date > now() - 1 year
| LOOKUP JOIN departments ON dep_id
| WHERE dep_location == "US"
| KEEP last_name, dep_name, dep_location
| SORT dep_nameBe mixed with aggregations:
// count employees per country
FROM employees
| STATS c = COUNT(*) BY country_code
| LOOKUP JOIN countries ON country_code
| KEEP c, country_name
| SORT country_nameOr be combined with another join:
// find the error messages in the last hour alongside their source host name and error description
FROM logs
| WHERE message_type :"error"
| LOOKUP JOIN message_types ON err_code
| LOOKUP JOIN host_to_ips ON src_ip
| WHERE log_date > now() - 1 hour
| KEEP log_date, log_type, err_description, host_nameExecuting a Lookup Join
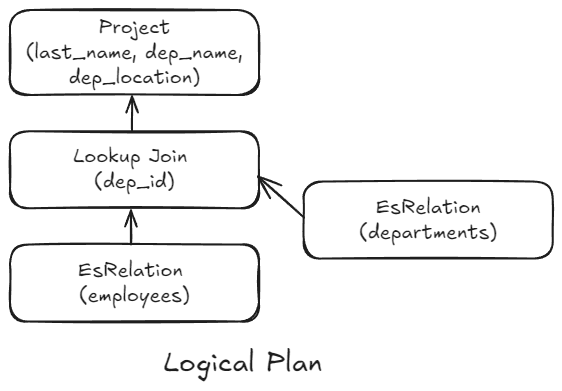
Let's illustrate what happens during runtime by looking at a basic query that doesn't include any other commands, such as filter. This will allow us to concentrate on the execution aspect as opposed to the planning phase.
FROM employees
| LOOKUP JOIN departments ON dep_id
| KEEP last_name, dep_name, dep_locationThe logical plan, a tree structure representing the data flow and necessary transformations, is the result of translating the query above. This logical plan centers on the semantics of the query.
To ensure efficient scaling, standard Elasticsearch indices are divided into multiple shards spread across the cluster. In a join scenario, sharding both the left (L) and right (R) sides would result in L*R partitions. To minimize the need for data movement, lookup joins require the right side (which provides the enriching data) to have a single shard, similar to an enrich index, with the replication dictated by the index settings (default is 1).
This decreases the amount of nodes needed to execute the join, thereby reducing the problem space. As a result, L*R becomes L*1, which equals L.
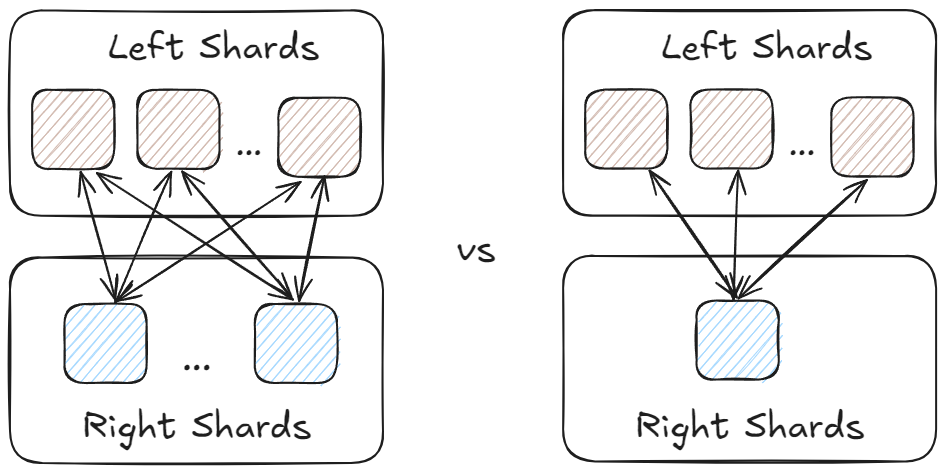
Thus, the coordinator needs to dispatch the plan only to the left side data nodes, with the hash join performed locally using the lookup/right index to “build” the underlying hash map while the left side is used for “probing” for matching keys in batches.
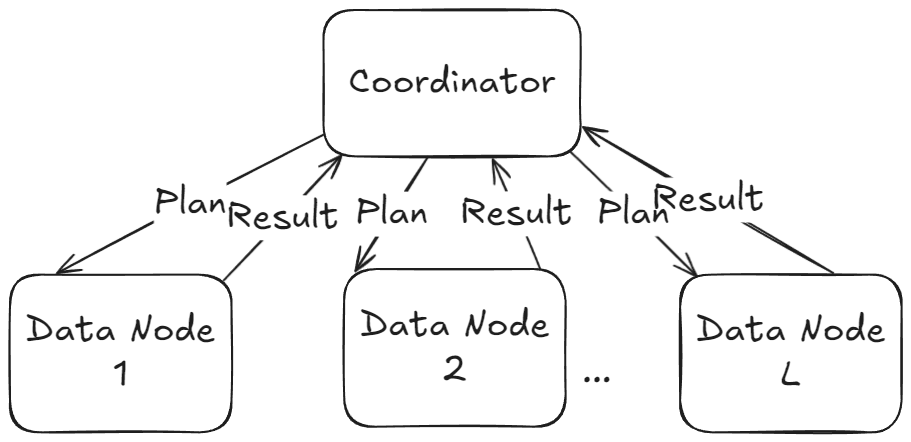
The resulting distributed physical plan, which focused on the distributed execution of the query, looks as follows:
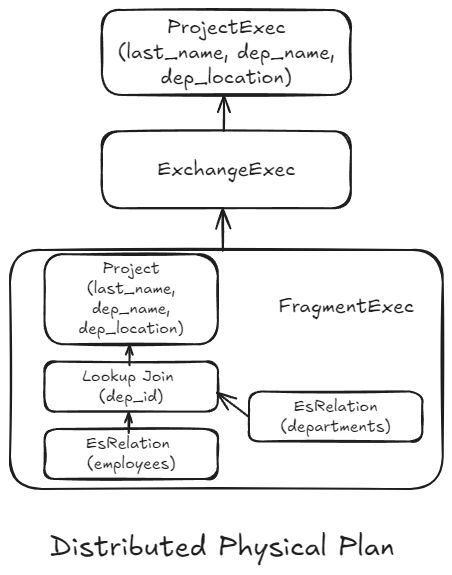
The plan consists of two main parts or sub-plans: the physical plan that gets executed on the coordinator (generally speaking, the node receiving/responsible for the query completion) and the plan fragment, which is executed on the data nodes (the nodes holding the data). Since the coordinator does not have the data, it sends a plan fragment to the relevant data nodes for local execution. The results are then sent back to the coordinator node, which computes the final results.
The communication between the two entities is represented in the plan through the Exchange block. The coordinator doesn't have to do much work for this query because most of the processing happens on the data nodes.
The fragment encapsulates the logical subplan, enabling optimization based on the specific characteristics of each shard's data (e.g., missing fields, local minimum and maximum values). This local replanning also helps manage differences in node code that might exist between nodes or between a node and the coordinator, for example, during cluster upgrades.
The local physical plan looks something like this:
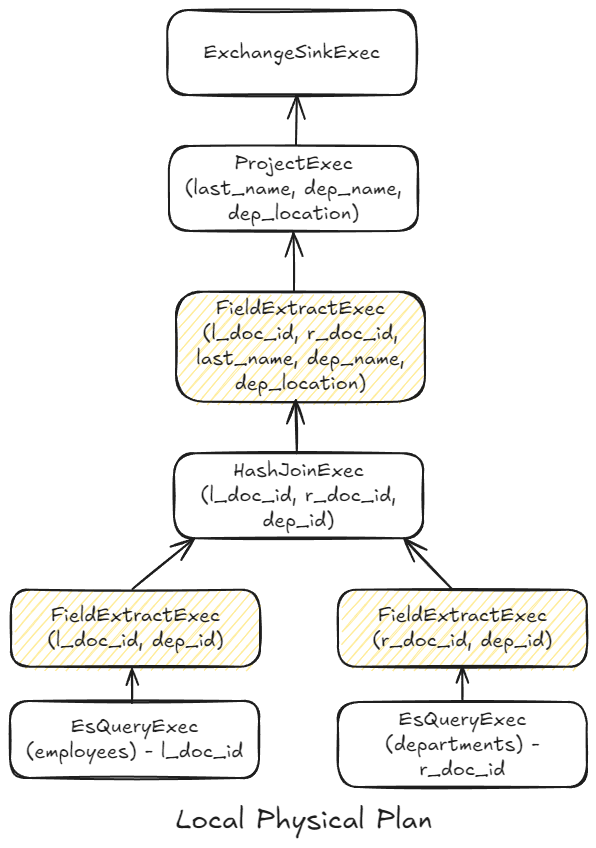
The plan is designed to reduce I/O by using efficient data extraction methods. The two nodes at the bottom of the tree act as roots, supplying the nodes above. Each one outputs references to the underlying Elasticsearch documents (doc_id). This is done intentionally to delay the loading of columns (fields) or documents for as long as possible through the designated extraction nodes (in yellow). In this particular plan, loading takes place right before the hash join on each of the joining sides and prior to the final project just before the data exits the node using only the join resulting data.
Future work
Qualifiers
At the moment, the lookup join syntax requires the key to have the same name in both tables (similar to JOIN USING in some SQL dialects). This can be addressed through RENAME or EVAL :
FROM employees_new
| RENAME dep AS dep_id // align the names of the group key
| LOOKUP JOIN departments ON dep_idIt’s an unnecessary inconvenience that we’re working on removing in the near future by introducing (source) qualifiers.
The previous query could be rewritten as (syntax wip):
FROM employees_new e
| LOOKUP JOIN departments ON e.dep == departments.dep_idNotice that the join key was replaced by an equality comparison, where each side is using a field name qualifier, which can be implicit (departments) or explicit (e).
More join types and performance
We are currently working on enhancing the lookup join algorithm to better exploit the data topology with a focus on specializations that leverage the underlying search structures and statistics in Lucene for data skipping.
In the long term, we plan to support additional join types, such as inner join (or intersection, which combines documents that have the same field on both sides) and full outer join (or union, which combines the documents from both sides even when there is no common key).
Feedback
The path to native JOIN support in Elasticsearch has been a long one, dating back to version 0.90. Early attempts included nested and `_parent ` field types, with the latter eventually being rewritten (in 2.0), deprecated (in 5.0), and replaced by the join field (in 6.0).
More recent features like Transforms (7.3) and the Enrich ingest pipeline (7.5) also aimed to address join-like use cases. In the wider Elasticsearch ecosystem, Logstash and Apache Spark (via the ES-Hadoop connector) have provided alternative solutions. Elasticsearch SQL, which debuted in 6.3.0, is also worth mentioning due to the grammar similarity: while it supports a wide range of SQL functionality, native JOIN support has remained elusive.
All these solutions work and continue to be supported. However, we think ES|QL, due to its query language and execution engine, significantly simplifies the user experience!
ESQL Lookup join is in tech preview, freely available in Elasticsearch 8.18 and Elastic Cloud—try it out and let us know how it works for you!
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content

September 18, 2025
Elasticsearch’s ES|QL Editor experience vs. OpenSearch’s PPL Event Analyzer
Discover how ES|QL Editor’s advanced features accelerate your workflow, directly contrasting OpenSearch’s PPL Event Analyzer’s manual approach.

Introducing the ES|QL query builder for the Elasticsearch Ruby Client
Learn how to use the recently released ES|QL query builder for the Elasticsearch Ruby Client. A tool to build ES|QL queries more easily with Ruby code.

Introducing the ES|QL query builder for the Python Elasticsearch Client
Learn how to use the ES|QL query builder, a new Python Elasticsearch client feature that makes it easier to construct ES|QL queries using a familiar Python syntax.

Using ES|QL COMPLETION + an LLM to write a Chuck Norris fact generator in 5 minutes
Discover how to use the ES|QL COMPLETION command to turn your Elasticsearch data into creative output using an LLM in just a few lines of code.

July 29, 2025
Introducing a more powerful, resilient, and observable ES|QL in Elasticsearch 8.19 & 9.1
Exploring ES|QL enhancements in Elasticsearch 8.19 & 9.1, including built-in resilience to failures, new monitoring and observability capabilities, and more.