Elasticsearch just turned 15-years-old. It all started back in February 2010 with the announcement blog post (featuring the iconic “You Know, for Search” tagline), first public commit, and the first release, which happened to be 0.4.0.
Let’s take a look back at the last 15 years of indexing and searching, and turn to the next 15 years of relevance.
GET _cat/stats
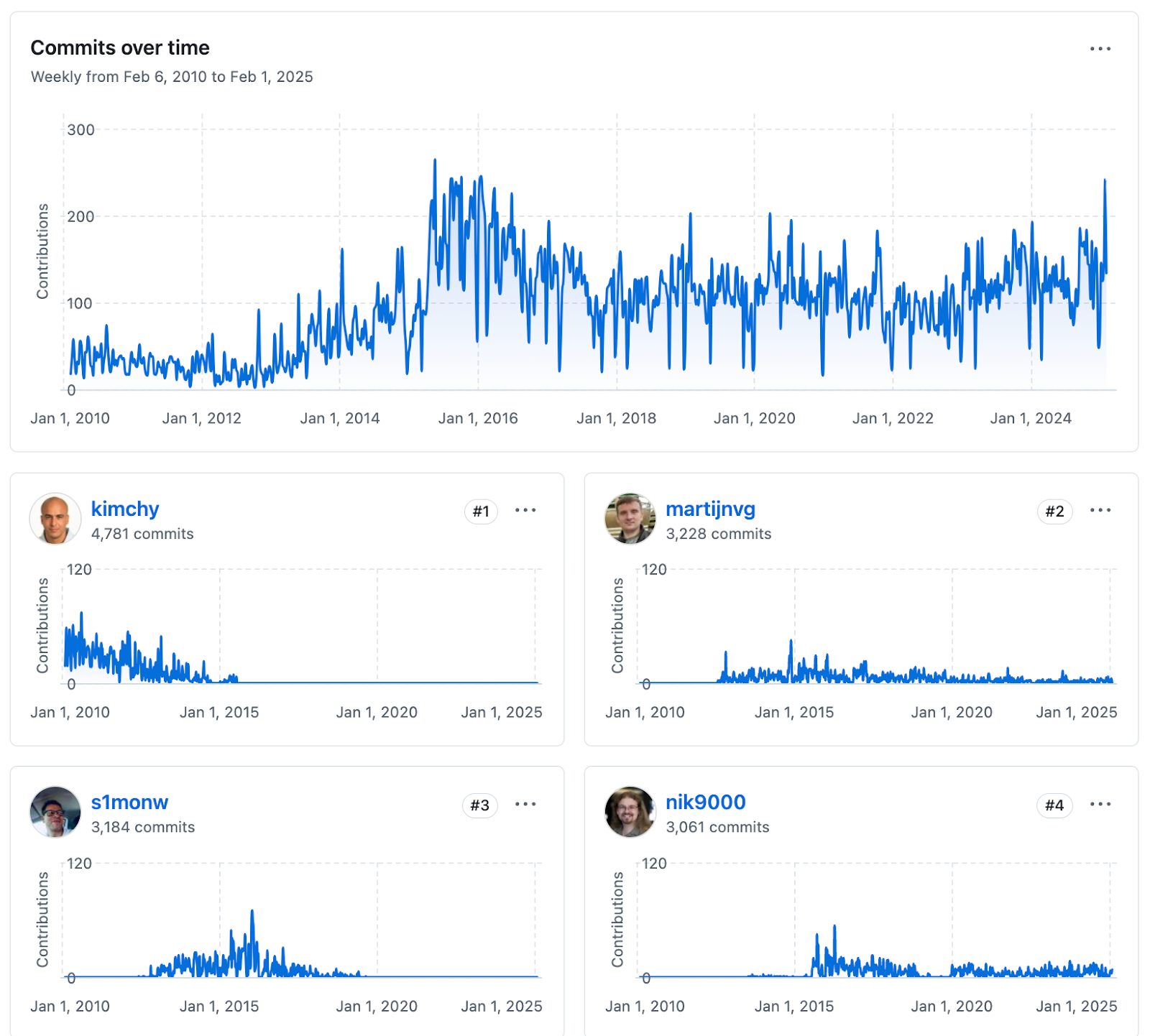
Since its launch, Elasticsearch has been downloaded an average of 3 times per second, totaling over 1.45 billion downloads.
The GitHub stats are equally impressive: More than 83,000 commits from 2,400 unique authors, 38,000 issues, 25,000 forks, and 71,500 stars. And there is no sign of slowing down.
All of this is on top of countless Apache Lucene contributions. We’ll get into those for the 25 year anniversary of Lucene, which is also this year. In the meantime, you can check out the 20 year anniversary page to celebrate one of the top Apache projects.
A search (hi)story
There are too many highlights to list them all, but here are 15 releases and features from the last 15 years that got Elasticsearch to where it is today:
- Elasticsearch, the company (2012): The open source project became an open source company, setting the stage for its growth.
- ELK Stack (2013): Elasticsearch joined forces with Logstash and Kibana to form the ELK Stack, which is now synonymous with logging and analytics.
- Version 1 (2014): The first stable release introduced key features like snapshot/restore, aggregations, circuit breakers, and the _cat API.
- Shield and Found (2015): Shield brought security to Elasticsearch clusters in the form of a (paid) plugin. And the acquisition of found.no brought Elasticsearch to the cloud, evolving into what is now Elastic Cloud. As an anecdote, nobody could find Found — SEO can be hard for some keywords.
- Version 2 (2015): Introduced pipelined aggregations, security hardening with the Java Security Manager, and performance and resilience improvements.
- Version 5 and the Elastic Stack (2016): Skipping two major versions to unify the version numbers of the ELK Stack and turning it into the Elastic Stack after adding Beats. This version also introduced ingest nodes and the scripting language Painless.
- Version 6 (2017): Brought zero-downtime upgrades, index sorting, and the removal of types to simplify data modeling.
- Version 7 (2019): Changed the cluster coordination to the more scalable and resilient Zen2, single-shard default settings, built-in JDK, and adaptive replica selection.
- Free security (2019): With the 6.8 and 7.1 releases, core security became free to help everyone secure their cluster.
- ILM, data tiers, and searchable snapshots (2020): Made time-series data more manageable and cost-effective with Index Lifecycle Management (ILM), tiered storage, and searchable snapshots.
- Version 8 (2022): Introduced native dense vector search with HNSW and enabled security by default.
- ELSER (2023): Launched Elastic Learned Sparse EncodeR model, bringing sparse vector search for better semantic relevance.
- Open source again (2024): Added AGPL as a licensing option to bring back open source Elasticsearch.
- Start Local (2024): Made it easier than ever to run Elasticsearch and Kibana:
curl -fsSL https://elastic.co/start-local | sh - LogsDB (2024): A new specialized index mode that reduces log storage by up to 65%.
The future of search is bright
Thanks to the rise of AI capabilities, search is more relevant and interesting than ever. So what is next for Elasticsearch? There’s way too much to name, so we’ll stick to three areas and the challenges they address.
Serverless
No shards, nodes, or versions. Elasticsearch Serverless — which is GA on AWS and just entered technical preview on Azure — takes care of the operational issues you might have experienced in the past:
- 15 years in, and someone is still setting
number_of_shards: 100for no reason. - 15 years, and we’re still debating
refresh_interval: 1s vs 30slike it’s a life-or-death decision. - 15 years of major versions, minor heart attacks, and the thrill of migrating to the latest version.
You can try out Elasticsearch Serverless today.
ES|QL
“Cheers to 15 years of Elasticsearch — where the Query DSL is still the most complex part of your day.” But it doesn’t have to be. The new Elasticsearch Piped Query Language (ES|QL) brings a much simpler syntax and a significant investment into a new compute engine with performance in mind. While we’re building out more features, you can already use ES|QL today. Don’t worry; the Query DSL will understand.
AI everywhere
- 15 years of query tuning, and we’re still just throwing
boost: 10at the problem. - 15 years of making your logs searchable while you still have no idea what’s happening in production.
- Still the best at finding that one log line… if you remember how you indexed it.
AI is redefining what’s possible — from turning raw logs into actionable insights with the AI Assistant for observability and security, to more relevant search with semantic understanding and intelligent re-ranking..
This is only the beginning. More AI-powered features are on the horizon — bringing smarter search, enhanced observability, and stronger security. The future of Elasticsearch isn’t just about finding data; it’s about understanding it. Stay tuned — the best is yet to come.
Thanks to all of you
Thanks to all contributors, users, and customers over the last 15 years to make Elasticsearch what it is today. We couldn’t have done it without you and are grateful for every query you send to Elasticsearch.
Here’s to the next 15 years. Enjoy!
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content

September 3, 2025
Vector search filtering: Keep it relevant
Performing vector search to find the most similar results to a query is not enough. Filtering is often needed to narrow down search results. This article explains how filtering works for vector search in Elasticsearch and Apache Lucene.

August 26, 2025
Lighter by default: Excluding vectors from source
Elasticsearch now excludes vectors from source by default, saving space and improving performance while keeping vectors accessible when needed.
August 13, 2025
Failure store: see what didn’t make it
Learn about failure store, a new feature in the Elastic Stack that captures and indexes previously lost events.

July 29, 2025
Introducing a more powerful, resilient, and observable ES|QL in Elasticsearch 8.19 & 9.1
Exploring ES|QL enhancements in Elasticsearch 8.19 & 9.1, including built-in resilience to failures, new monitoring and observability capabilities, and more.

July 29, 2025
Unify your data: Cross-cluster search with ES|QL is now generally available!
Cross-Cluster search with ES|QL is now GA! Query data across multiple clusters with a single, elegant query. Learn about its performance, resilience, and syntax.