For years, Apache Lucene and Elasticsearch have supported filtered search with kNN queries, allowing users to retrieve the nearest neighbors that meet a specified metadata filter. However, performance has always suffered when dealing with semi-restrictive filters. In Apache Lucene, we are introducing a variation of ACORN-1—a new approach for filtered kNN search that achieves up to 5x faster searches with little drop in recall.
This blog goes over the challenges of filtered HNSW search, explaining why performance slows as filtering increases, and how we improved HNSW vector search in Apache Lucene with the ACORN-1 algorithm.
Why searching fewer docs is actually slower in HNSW
Counterintuitively, filtering documents—thereby reducing the number of candidates—can actually make kNN searches slower. For traditional lexical search, fewer documents mean fewer scoring operations, meaning faster search. However, in an HNSW graph, the primary cost is the number of vector comparisons needed to identify the k nearest neighbors. At certain filter set sizes, the number of vector comparisons can increase significantly, slowing down search performance.
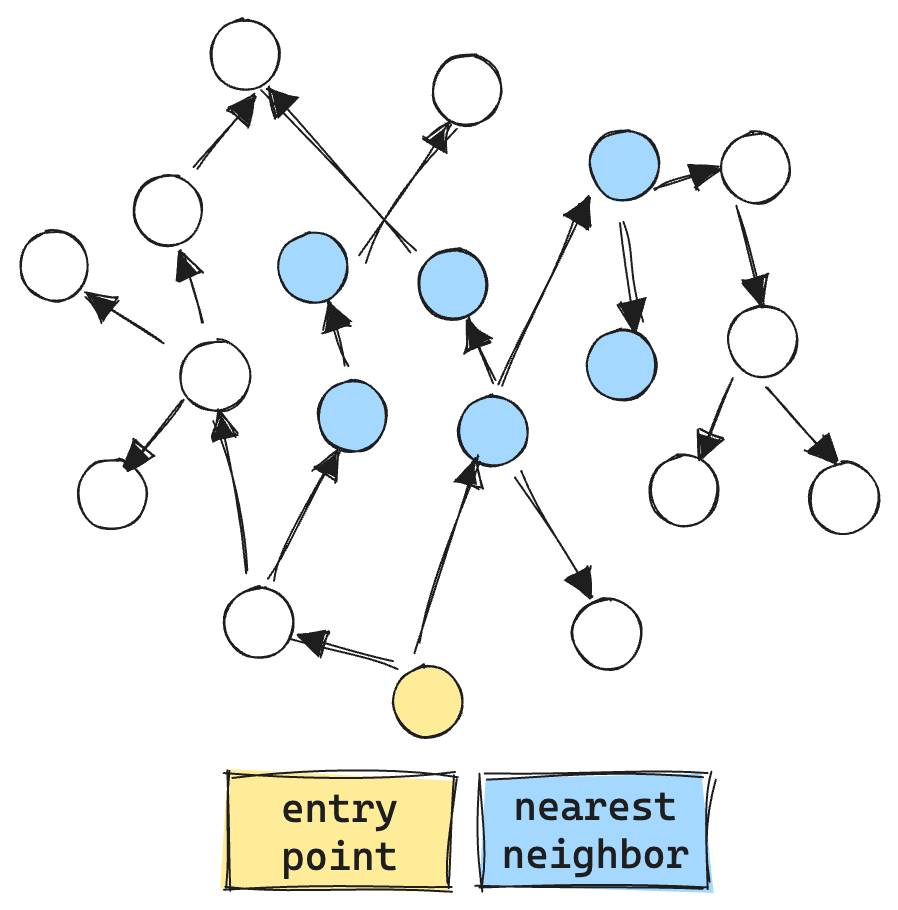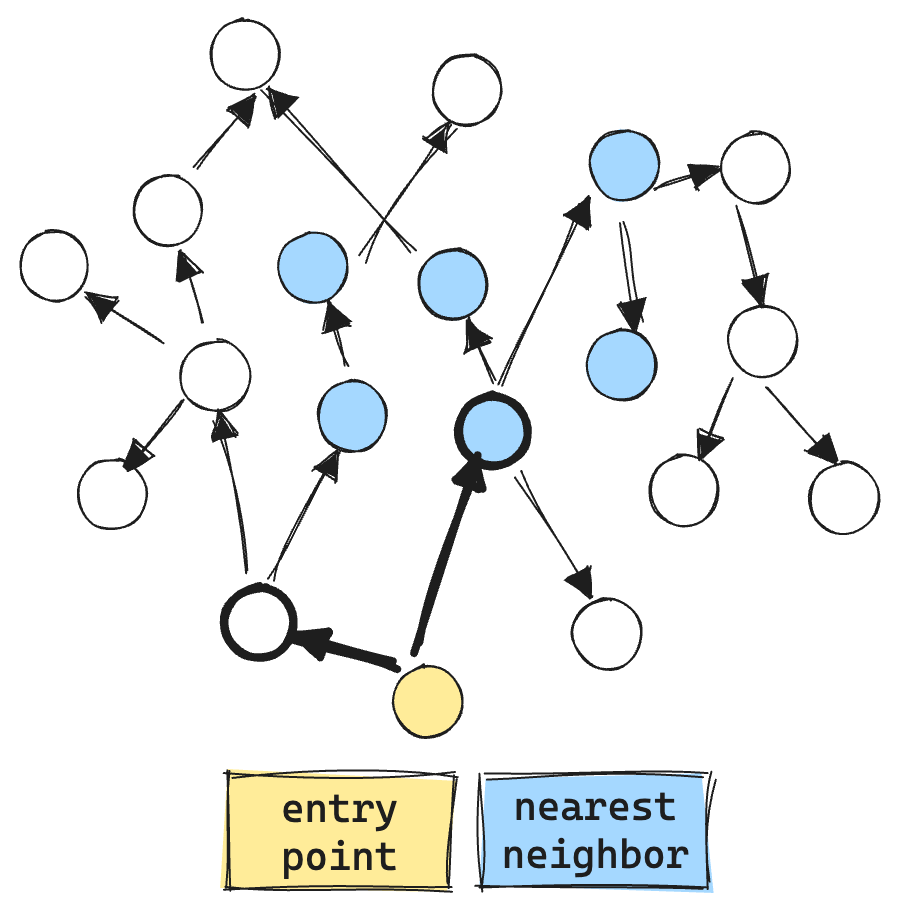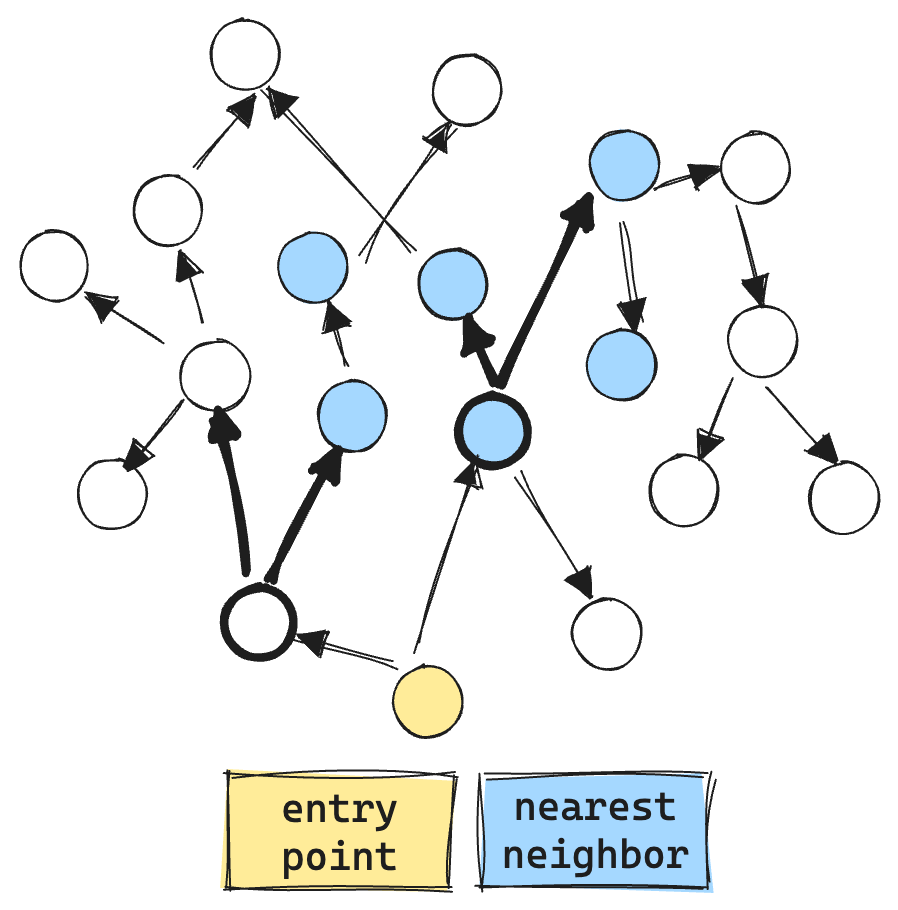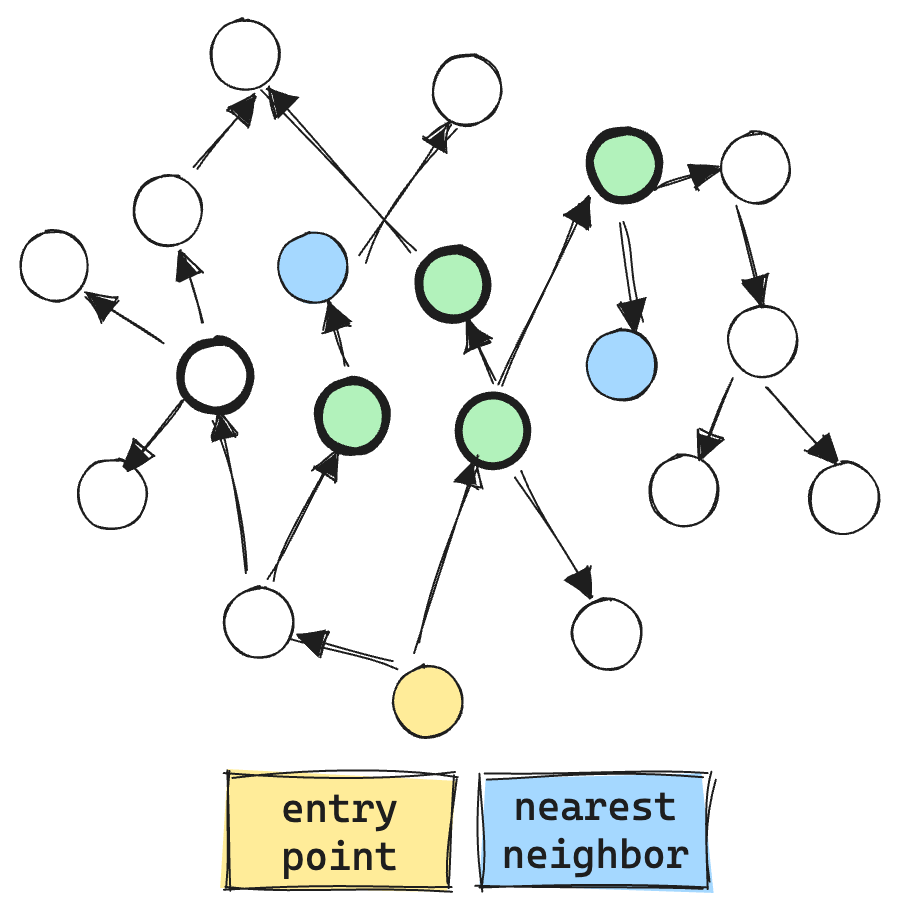
Here is an example of unfiltered graph search. Note there are about 6 vector operations.
Because the HNSW graph in Apache Lucene has no knowledge of filtering criteria when built, it constructs purely based on vector similarity. When applying a filter to retrieve the k nearest neighbors, the search process traverses more of the graph. This happens because the natural nearest neighbors within a local graph neighborhood may be filtered out, requiring deeper exploration and increasing the number of vector comparisons.
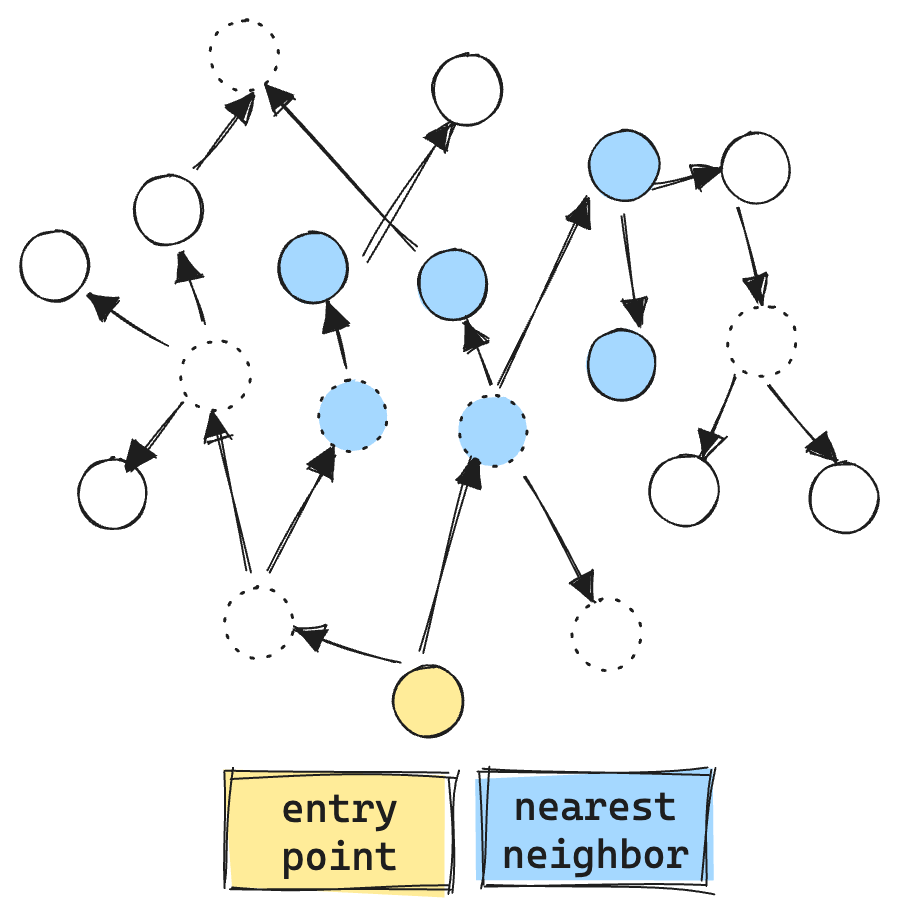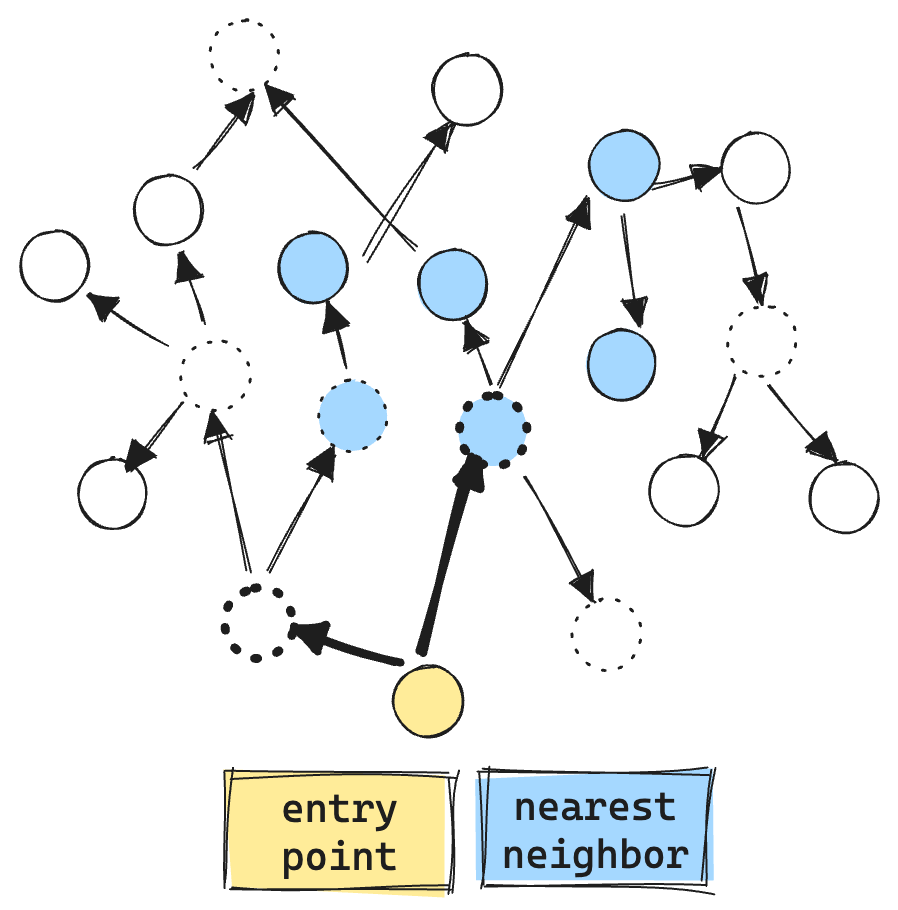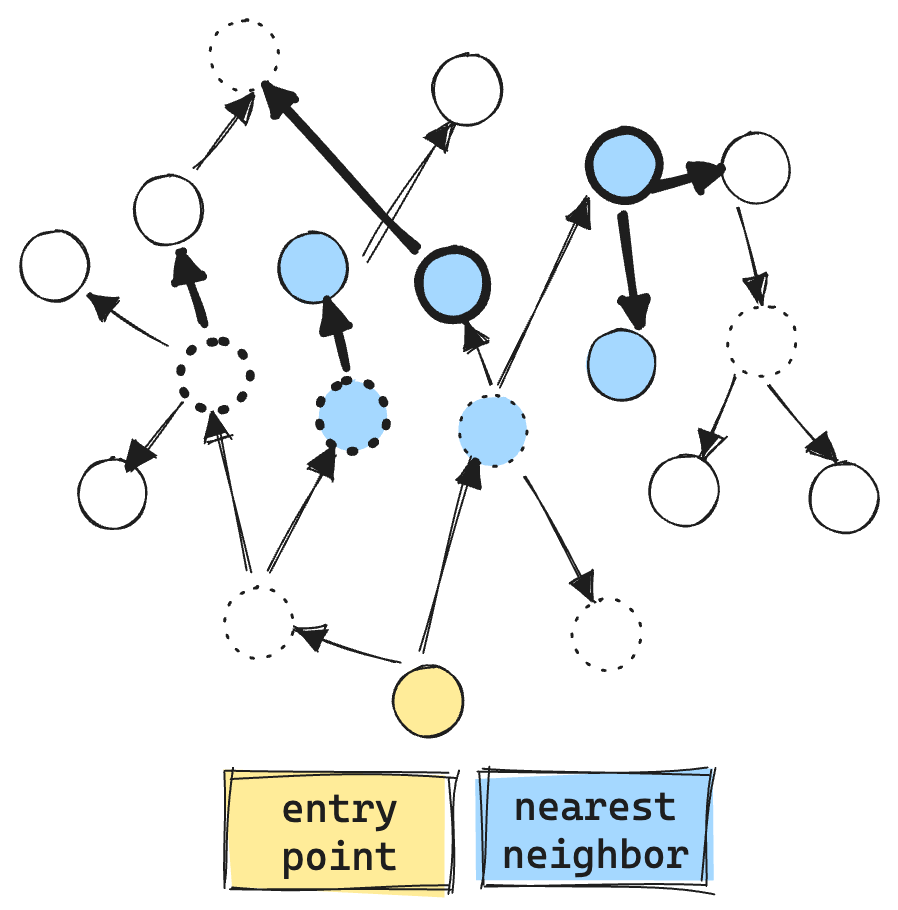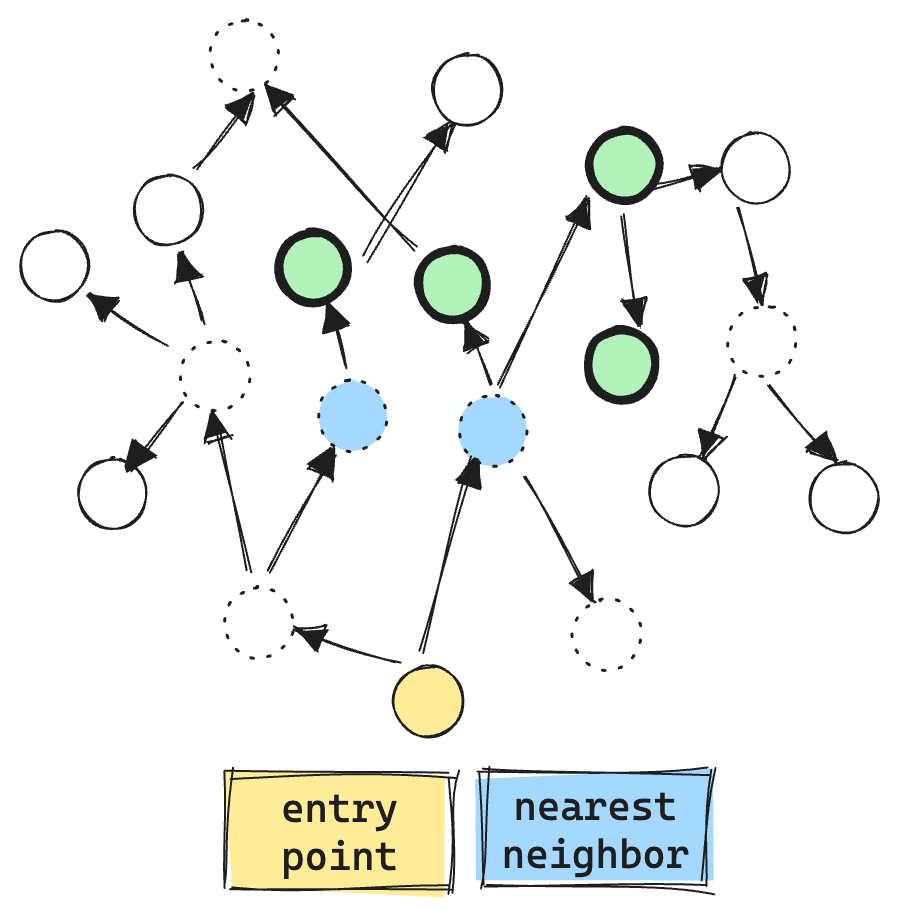
Here is an example of the current filtered graph search. The “dashed circles” are vectors that do not match the filter. We even make vector comparisons against the filtered out vectors, resulting in more vector ops, about 9 total.
You may ask, why perform vector comparisons against nodes that don’t match the filter at all? Well, HNSW graphs are already sparsely connected. If we were to consider only matching nodes during exploration, the search process could easily get stuck, unable to traverse the graph efficiently.
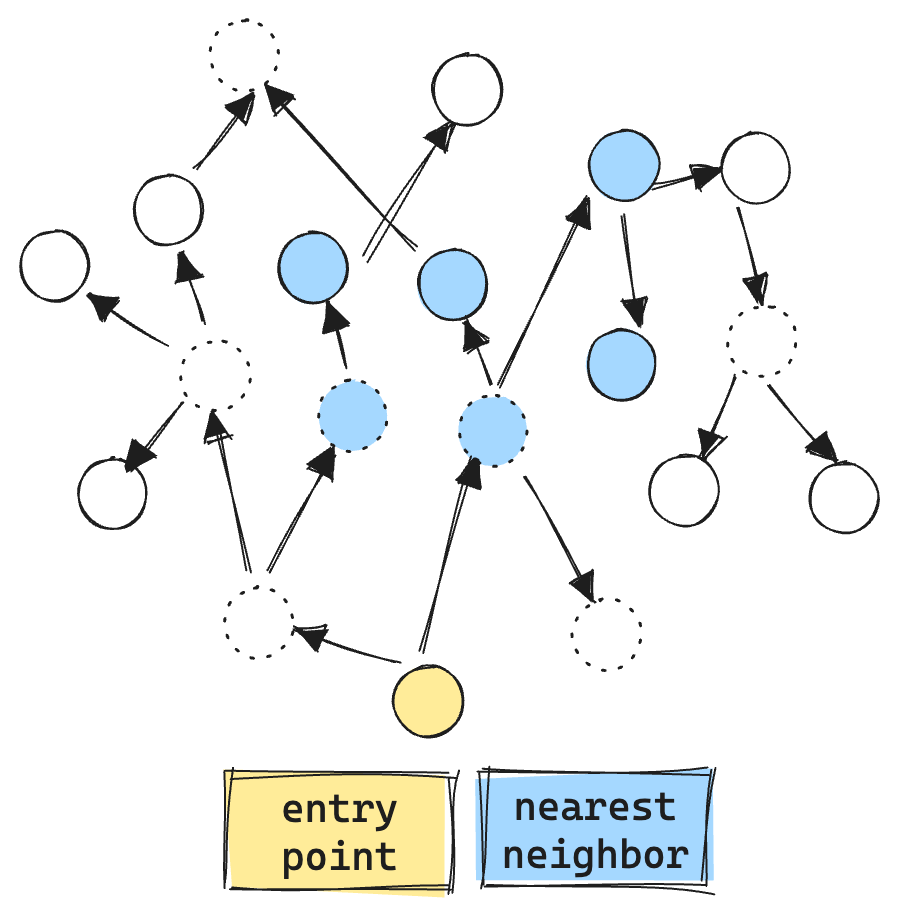
Note the filtered “gulf” between the entry point and the first valid filtered set. In a typical graph, it's possible for such a gap to exist, causing exploration to end prematurely and resulting in poor recall.
We gotta make this faster: Improving HNSW vector search in Lucene
Since the graph doesn’t account for filtering criteria, we have to explore the graph more. Additionally, to avoid getting stuck, we must perform vector comparisons against filtered-out nodes. How can we reduce the number of vector operations without getting stuck? This is the exact problem tackled by Liana Patel et. al. in their ACORN paper.
While the paper discusses multiple graph techniques, the specific algorithm we care about with Apache Lucene is their ACORN-1 algorithm. The main idea is that you only explore nodes that satisfy your filter. To compensate for the increased sparsity, ACORN-1 extends the exploration beyond the immediate neighborhood. Now, instead of exploring just the immediate neighbors, each neighbor’s neighbor is also explored. This means that for a graph with 32 connections, instead of only looking at the nearest 32 neighbors, exploration will attempt to find matching neighbors in 32*32=1024 extended neighborhood.
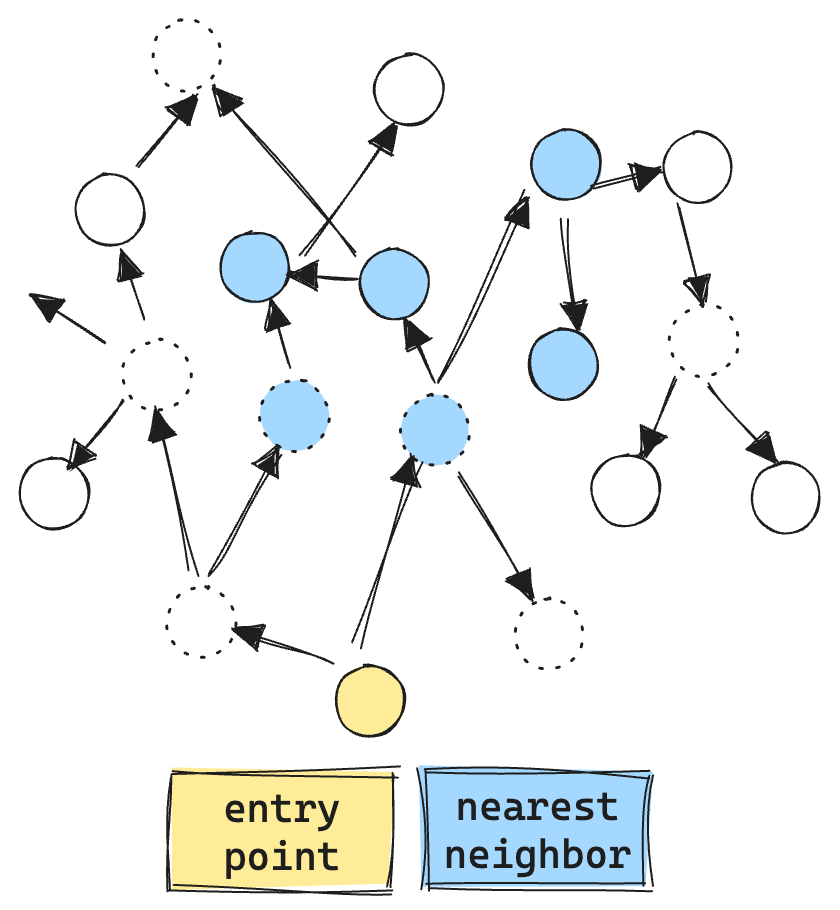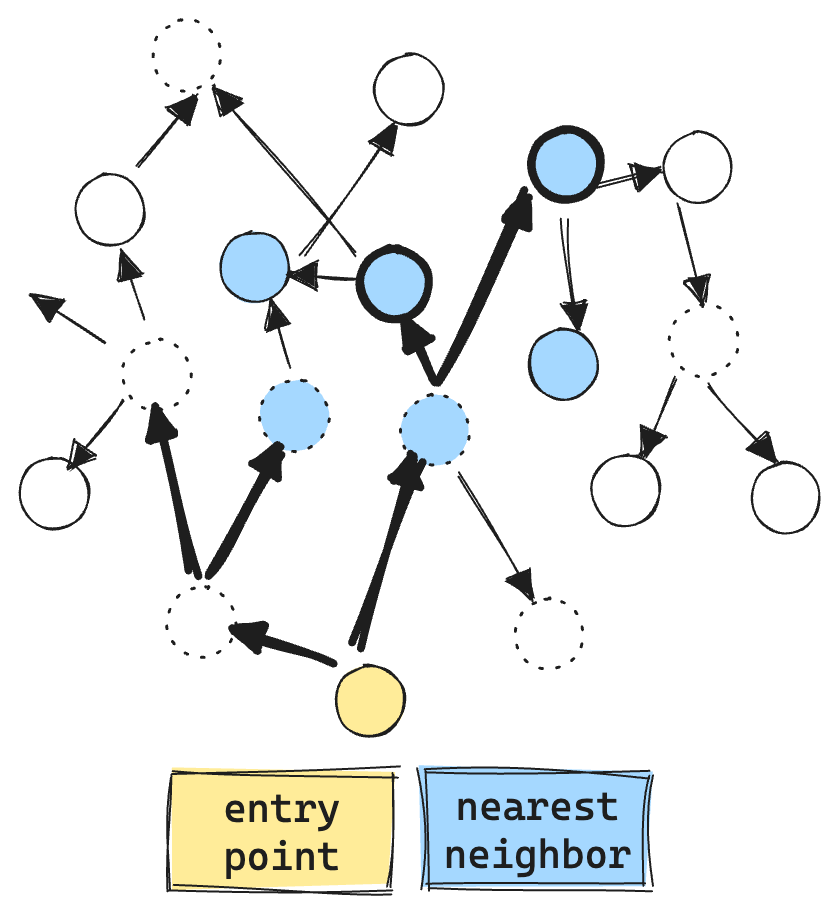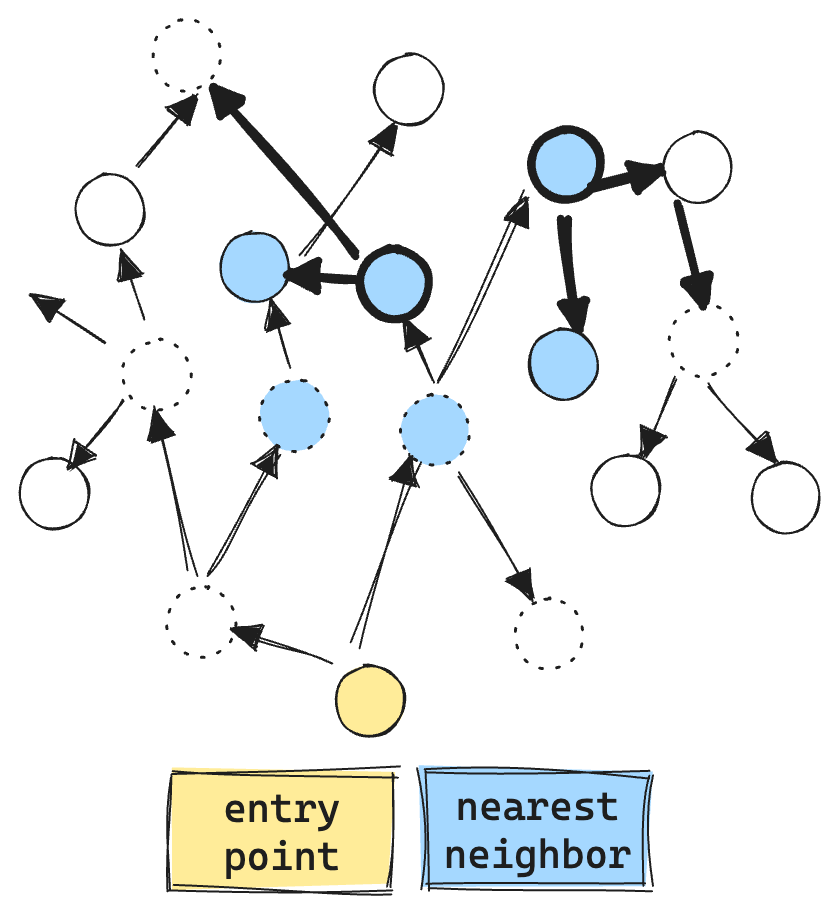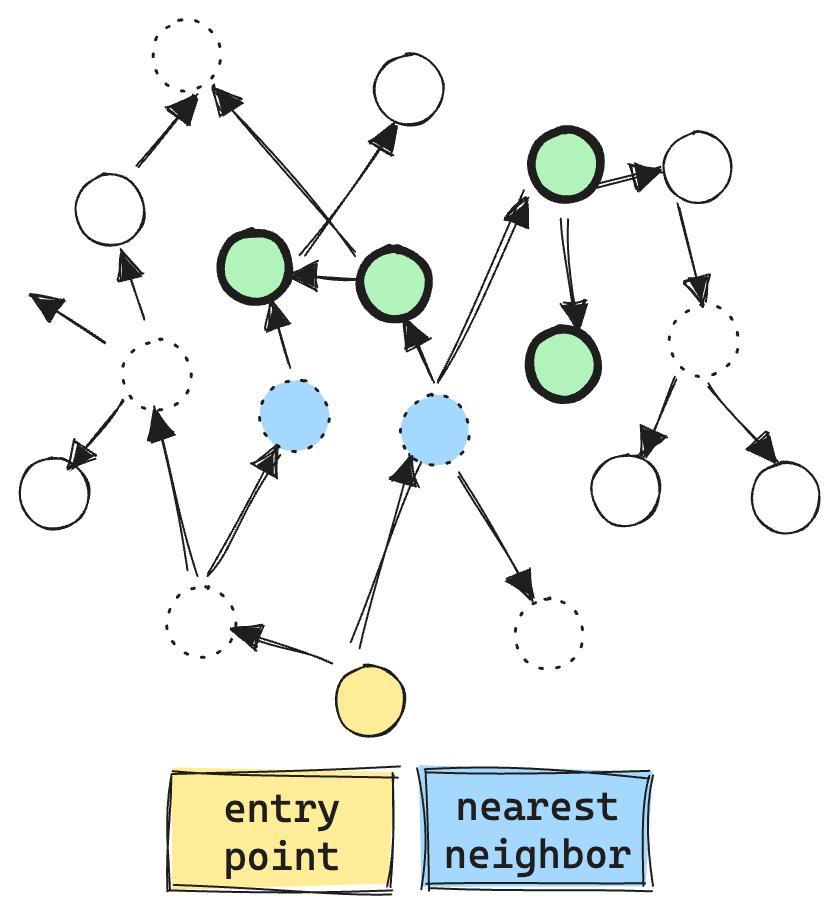
Here you can see the ACORN algorithm in action. Only doing vector comparisons and exploration for valid matching vectors, quickly expanding from the immediate neighborhood. Resulting in much fewer vector ops, about 6 in total.
Within Lucene, we have slightly adapted the ACORN-1 algorithm in the following ways. The extended neighborhoods are only explored if more than 10% of the vectors are filtered out in the immediate neighborhood. Additionally, the extended neighborhood isn’t explored if we have already scored at least neighborCount * 1.0/(1.0 - neighborFilterRatio). This allows the searcher to take advantage of more densely connected neighborhoods where the neighborhood connectedness is highly correlated with the filter.
We also have noticed both in inversely correlated filters (e.g. filters that only match vectors that are far away from the query vector) or exceptionally restrictive filters, only exploring the neighborhood of each neighbor isn’t enough. The searcher will also attempt branching further than the neighbors’ neighbors when no valid vectors passing the filter are found. However, to prevent getting lost in the graph, this additional exploration is bounded.
Numbers don’t lie
Across multiple real-world datasets, this new filtering approach has delivered significant speed improvements. Here is randomly filtering at 0.05% 1M Cohere vectors:
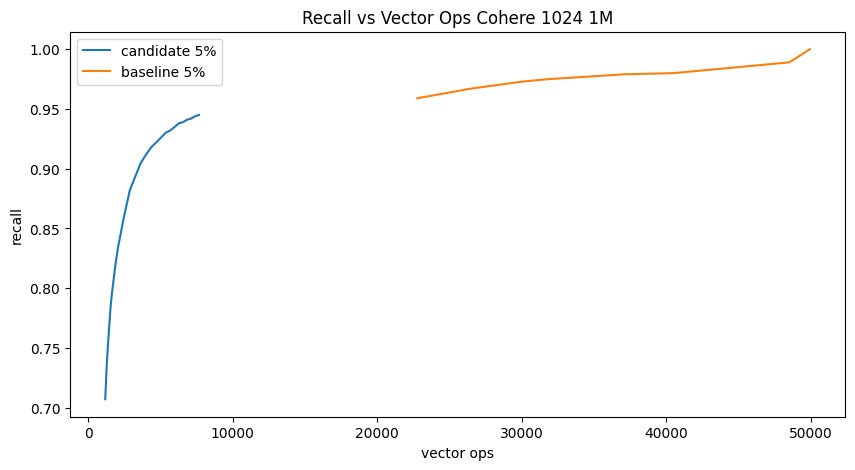
Up and to the left is “winning”, which shows that the candidate is significantly better. Though, to achieve the same recall, search parameters (e.g. num_candidates) need to be adjusted.
To further investigate this reduction in improvement as more vectors pass the filter, we did another test over an 8M Cohere Wiki document data set. Generally, no matter the number of vectors filtered, you want higher recall, with fewer visited vectors. A simple way to quantify this is by examining the recall-to-visited ratio.
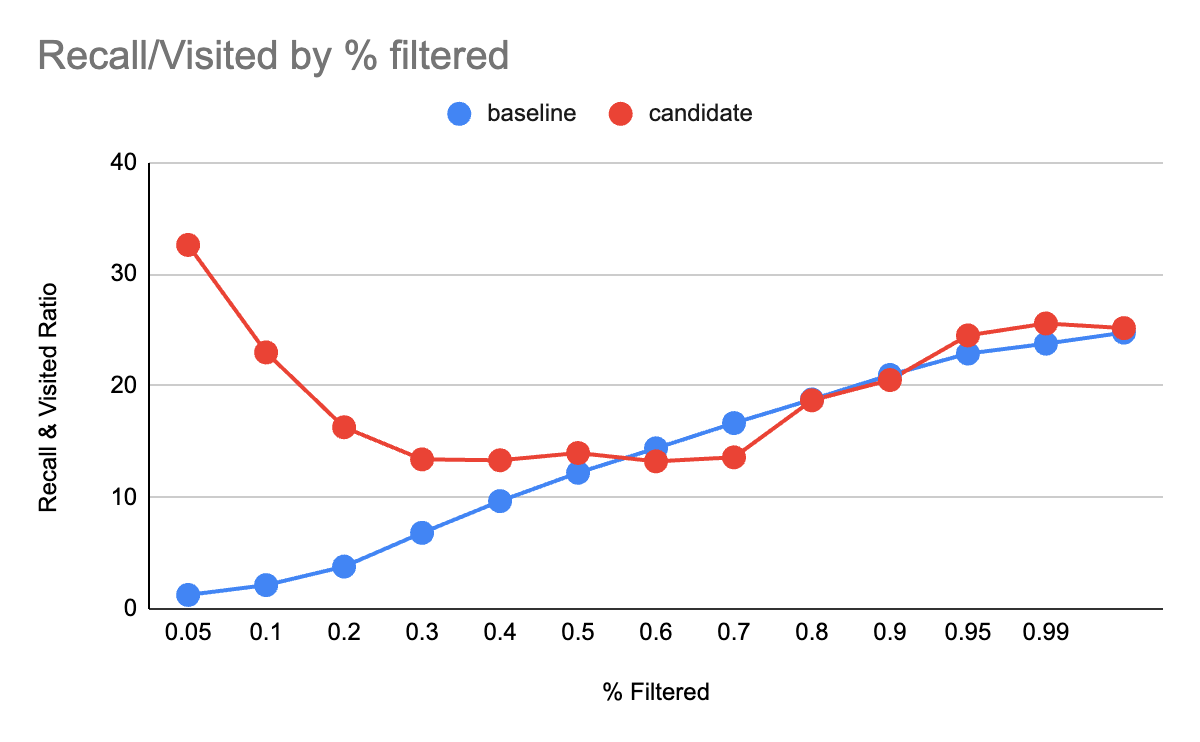
Here we see how the new filtered search methodology achieves much better recall vs. visited ratio.
It's clear that near 60%, the improvements level off or disappear. Consequently, in Lucene, this new algorithm will only be utilized when 40% or more of the vectors are filtered out.
Even our nightly Lucene benchmarks saw an impressive improvement with this change.
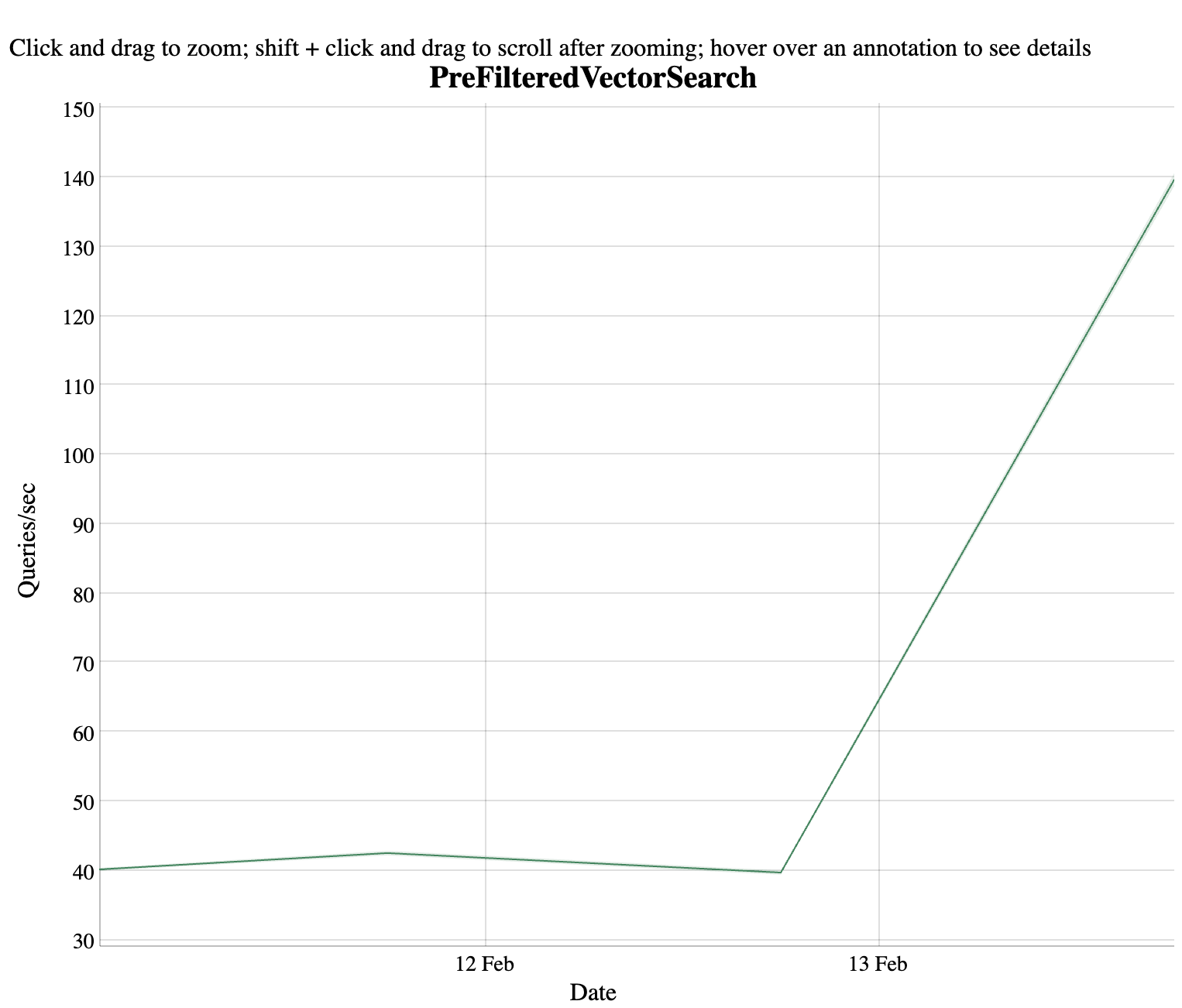
Apache Lucene runs over 8M 768 document vectors with a random filter that allows 5% of the vectors to pass. These kinds of graphs make me happy.
Gotta go fast
Filtering kNN search over metadata is key for real-world use cases. In Lucene 10.2, we have made it as much as 5x faster, using fewer resources, and keeping high recall. I am so excited about getting this in the hands of our users in a future Elasticsearch v9 release.
Ready to try this out on your own? Start a free trial.
Elasticsearch and Lucene offer strong vector database and search capabilities. Dive into our sample notebooks to learn more.
Related content

September 3, 2025
Vector search filtering: Keep it relevant
Performing vector search to find the most similar results to a query is not enough. Filtering is often needed to narrow down search results. This article explains how filtering works for vector search in Elasticsearch and Apache Lucene.

April 7, 2025
Speeding up merging of HNSW graphs
Explore the work we’ve been doing to reduce the overhead of building multiple HNSW graphs, particularly reducing the cost of merging graphs.
April 7, 2025
Speeding up HNSW graph merge
We describe a new strategy we developed that reduces HNSW merge time by up to 70% whilst maintaining similar graph quality
February 7, 2025
Concurrency bugs in Lucene: How to fix optimistic concurrency failures
Thanks to Fray, a deterministic concurrency testing framework from CMU’s PASTA Lab, we tracked down a tricky Lucene bug and squashed it

January 7, 2025
Early termination in HNSW for faster approximate KNN search
Learn how HNSW can be made faster for KNN search, using smart early termination strategies.