When building search applications, we often need to deal with documents that have complex structures—tables, figures, multiple columns, and more. Traditionally, this meant setting up complicated retrieval pipelines including OCR (optical character recognition), layout detection, semantic chunking, and other processing steps. In 2024, the model ColPali was introduced to address these challenges and simplify the process.

From Elasticsearch version 8.18 onwards, we added support for late-interaction models such as ColPali as a tech preview feature. In this blog, we will take a look at how we can use ColPali to search through documents in Elasticsearch.
ColPali performance
While we have many benchmarks that are based on previously cleaned-up text data to compare different retrieval strategies, the authors of the ColPali paper argue that real-world data in many organizations is messy and not always available in a nice, cleaned-up format.

Example documents from the ColPali paper: https://arxiv.org/pdf/2407.01449
To better represent these scenarios, the ViDoRe benchmark was released alongside the ColPali model. This benchmark includes a diverse set of document images from sectors such as government, healthcare, research, and more. A range of different retrieval methods, including complex retrieval pipelines or image embedding models, were compared with this new model.
The following table shows that ColPali performs exceptionally well on this dataset and is able to retrieve relevant information from these messy documents reliably.
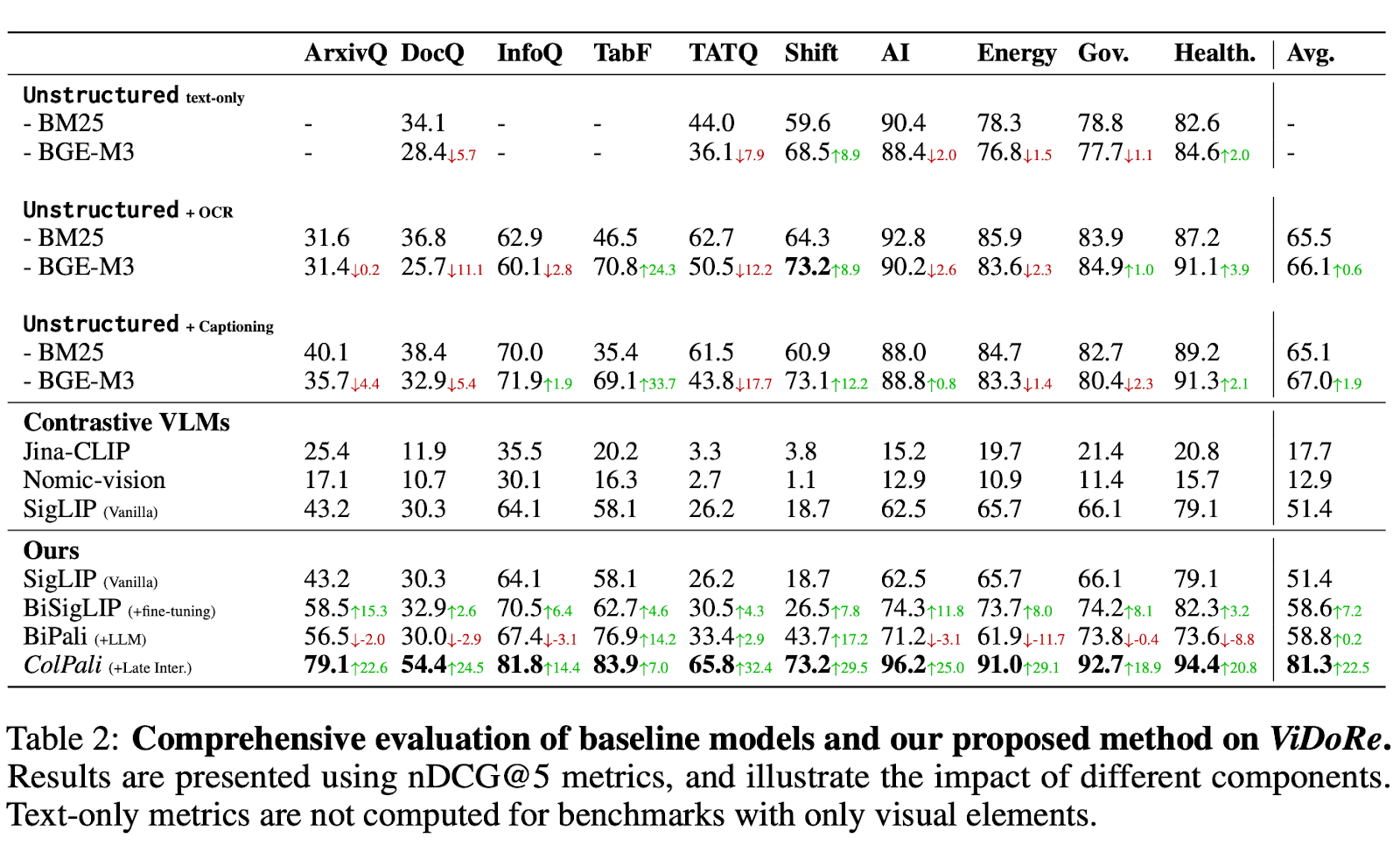
Source: https://arxiv.org/pdf/2407.01449 Table 2
How ColPali works
As teased in the beginning, the idea of ColPali is to just embed the image instead of extracting the text via complicated pipelines. ColPali builds on the vision capabilities of the PaliGemma model and the late-interaction mechanism introduced by ColBERT.
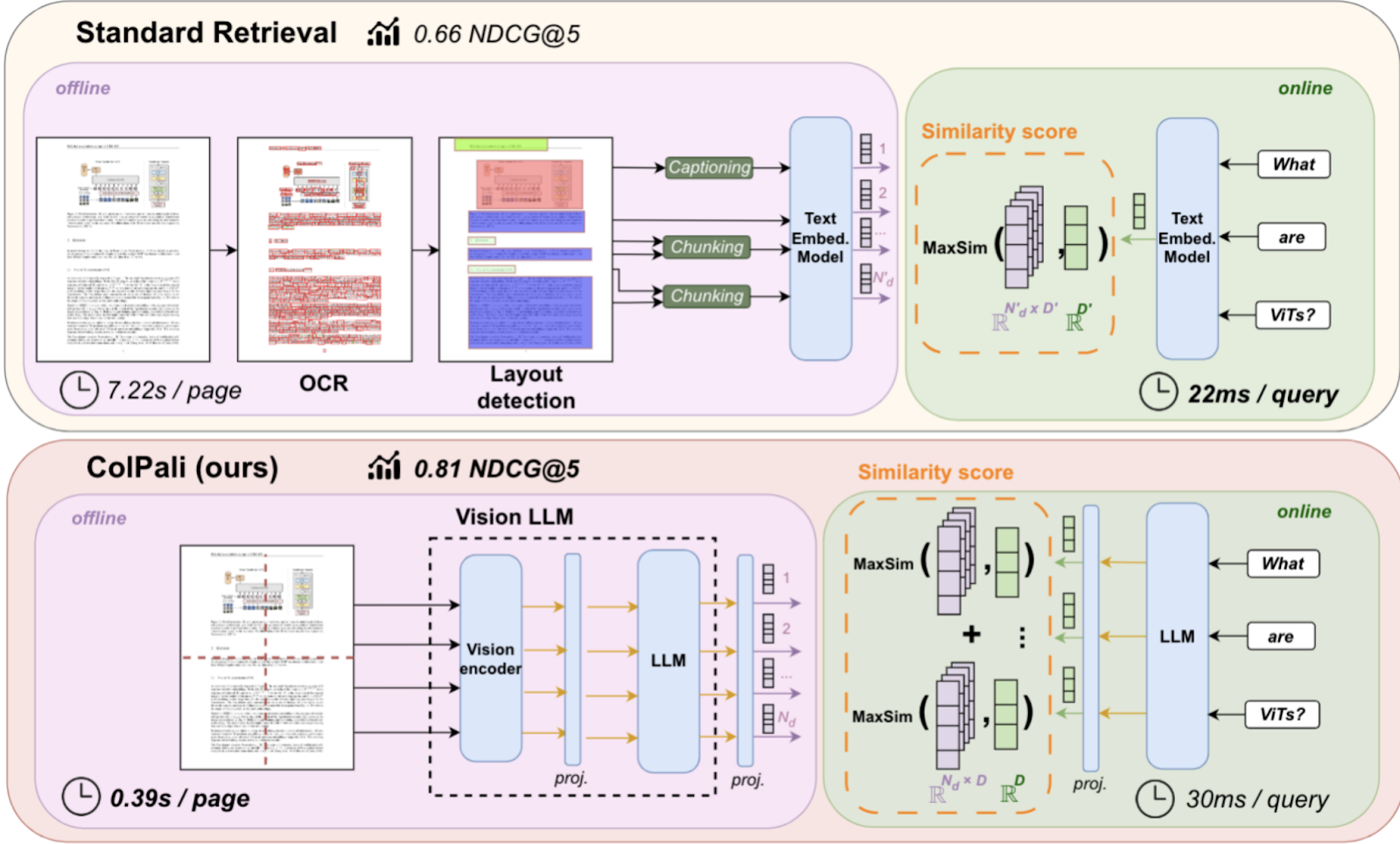
Source: https://arxiv.org/pdf/2407.01449 Figure 1
Let’s first take a look at how we index our documents.
Instead of converting the document into a textual format, ColPali processes documents by dividing a screenshot into small rectangles and converts each into a 128-dimensional vector. This vector represents the contextual meaning of this patch within the document. In practice, a 32x32 grid generates 1024 vectors per document.
For our query, the ColPali model creates a vector for each token.
To score documents during search, we calculate the distance between each query vector and each document vector. We keep only the highest score per query vector and sum those scores for a final document score.
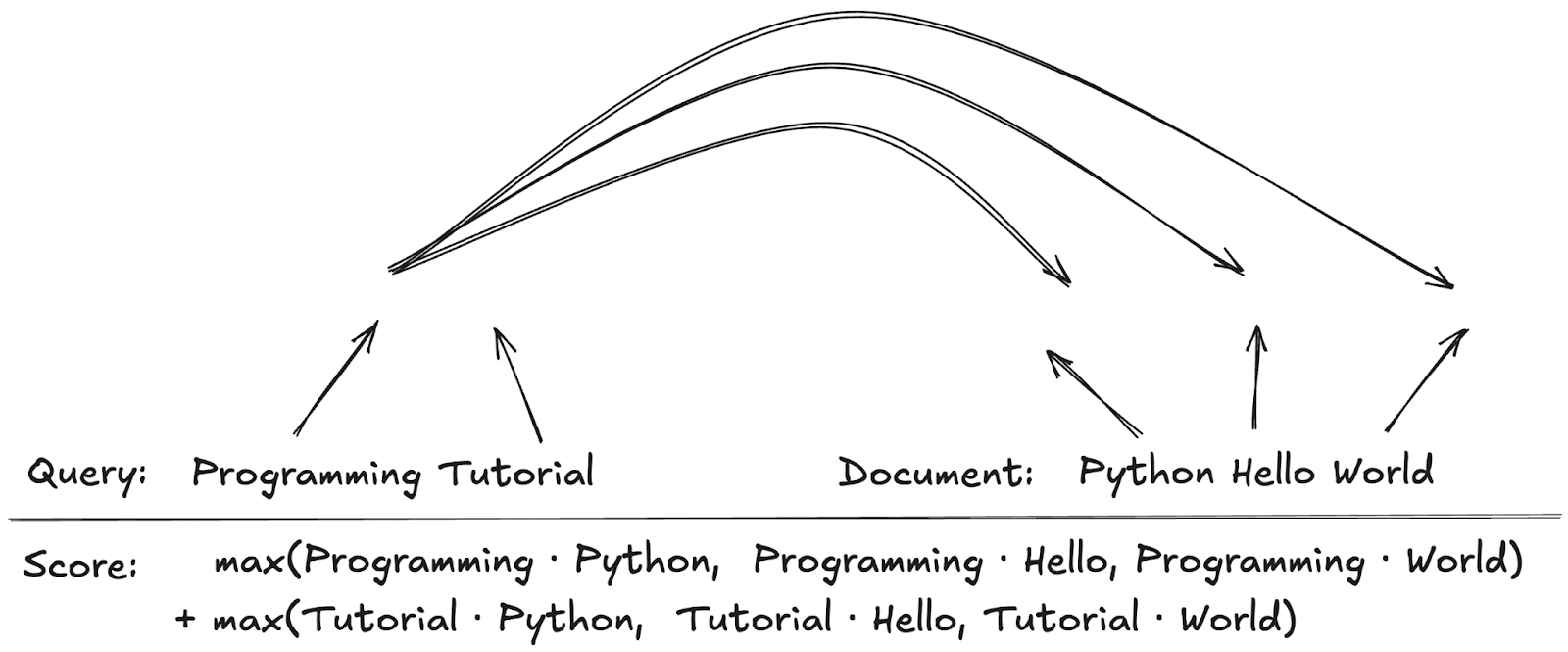
Late interaction mechanism for scoring ColBERT
ColPali interpretability
Vector search with bi-encoders struggle with the fact that the results are sometimes not very interpretable—meaning we don’t know why a document matched. Late interaction models are different: we know how well each document vector matches our query vectors; therefore, we can determine where and why a document matches.
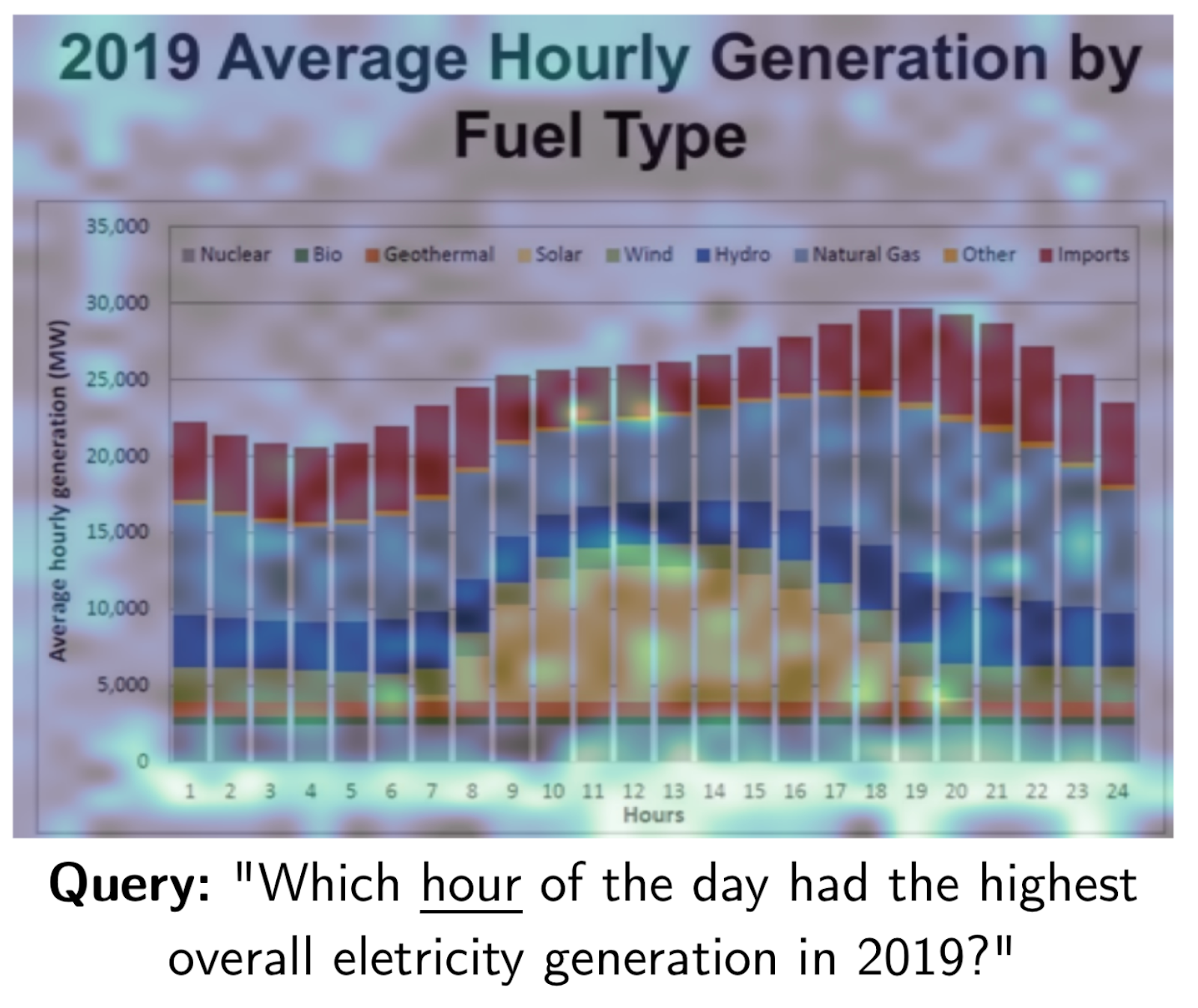
A heatmap of where the word “hour” matches in this document. Source: https://arxiv.org/pdf/2407.01449
Searching with ColPali in Elasticsearch
We will be taking a subset of the ViDoRe test set to take a look at how to index documents with ColPali in Elasticsearch. The full code examples can be found on GitHub.
To index the document vectors, we will be defining a mapping with the new rank_vectors field.
mappings = {
"mappings": {
"properties": {
"col_pali_vectors": {
"type": "rank_vectors"
}
}
}
}
INDEX_NAME = "searchlabs-colpali"
es = Elasticsearch(<ELASTIC_HOST>, api_key=<ELASTIC_API_KEY>)
es.indices.create(index=INDEX_NAME, body=mappings)
for image_path in tqdm(images, desc="Index documents"):
vectors = create_col_pali_image_vectors(image_path)
es_client.index(index=INDEX_NAME, id=image_path, document={"col_pali_vectors": vectors})We now have an index ready to be searched full of ColPali vectors. To score our documents, we can use the new maxSimDotProduct function.
query = "What do companies use for recruiting?"
es_query = {
"_source": False,
"query": {
"script_score": {
"query": {
"match_all": {}
},
"script": {
"source": "maxSimDotProduct(params.query_vector, 'col_pali_vectors')",
"params": {
"query_vector": create_col_pali_query_vectors(query)
}
}
}
},
"size": 5
}
results = es.search(index=INDEX_NAME, body=es_query)
image_ids = [hit["_id"] for hit in results["hits"]["hits"]]
html = "<div style='display: flex; flex-wrap: wrap; align-items: flex-start;'>"
for image_id in image_ids:
image_path = os.path.join(DOCUMENT_DIR, image_id)
html += f'<img src="{image_path}" alt="{image_id}" style="max-width:300px; height:auto; margin:10px;">'
html += "</div>"
display(HTML(html))
Key takeaways on ColPali in Elasticsearch
ColPali is a powerful new model that can be used to search complex documents with high accuracy. Elasticsearch makes it easy to use as it provides a fast and scalable search solution. Since the initial release, other powerful iterations such as ColQwen have been released. We encourage you to try these models for your own search applications and see how they can improve your results.
Before implementing what we covered here in production environments, we highly recommend that you check out part 2 of this article. Part 2 explores advanced techniques, such as bit vectors and token pooling, which can optimize resource utilization and enable effective scaling of this solution.
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content

September 15, 2025
Balancing the scales: Making reciprocal rank fusion (RRF) smarter with weights
Exploring weighted reciprocal rank fusion (RRF) in Elasticsearch and how it works through practical examples.

September 8, 2025
MCP for intelligent search
Building an intelligent search system by integrating Elastic's intelligent query layer with MCP to enhance the generative efficacy of LLMs.

Building intelligent duplicate detection with Elasticsearch and AI
Explore how organizations can leverage Elasticsearch to detect and handle duplicates in loan or insurance applications.

July 10, 2025
Diversifying search results with Maximum Marginal Relevance
Implementing the Maximum Marginal Relevance (MMR) algorithm with Elasticsearch and Python. This blog includes code examples for vector search reranking.

July 9, 2025
Semantic text is all that and a bag of (BBQ) chips! With configurable chunking settings and index options
Semantic text search is now customizable, with support for customizable chunking settings and index options to customize vector quantization, making semantic_text more powerful for expert use cases.