When you search for "pants" in an e-commerce catalog, do you really want to see 10 variations of the same black capris? Probably not. You'd likely prefer a diverse selection showing different styles, colors, and types of pants. This is where Maximum Marginal Relevance (MMR) comes in — a powerful technique for balancing relevance with diversity in search results.
In this blog, we'll explore how to implement MMR with Elasticsearch to create more diverse and useful search results, using a fashion product catalog as our example.
The problem: When relevance isn't enough
Traditional search systems optimize for one thing: relevance. They find items that best match your query and rank them by similarity scores. This works well for many use cases, but it can lead to redundant results.
Consider searching for "pants" in a fashion catalog. A pure relevance-based search might return:
- Black capris (score: 0.682)
- Black capris from another brand (score: 0.681)
- More black capris (score: 0.680)
- Even more black capris (score: 0.680)
- ...you get the idea
While these are all highly relevant to "pants", they're not particularly helpful for a user trying to explore different options. What we need is a way to maintain relevance while promoting diversity.
Enter Maximum Marginal Relevance
MMR is an algorithm that elegantly solves this problem by balancing two competing objectives:
- Relevance: How well items match the query
- Diversity: How different items are from each other
The algorithm works iteratively, selecting items that are relevant to the query but different from already selected items. This ensures that each additional result adds new information rather than redundancy.
How MMR works
The MMR algorithm follows a simple but effective process:
- Start by selecting the most relevant item (highest score)
- For each remaining item, calculate an MMR score that combines: Its relevance to the query and its dissimilarity to already selected items
- Select the item with the highest MMR score
- Repeat until you have enough results
The key insight is the MMR scoring formula:
MMR Score = λ × relevance - (1 - λ) × max_similarity_to_selectedThe λ parameter controls the trade-off, where λ = 1.0 is pure relevance (no diversity) and λ = 0.0: pure diversity (ignore relevance).
MMR doesn’t dictate how you score relevance — it just needs a number. That could come from BM-25, a learned ranker, or any custom metric you like. Because BM-25 relies on per-term statistics stored in postings lists that aren’t available on the client, we’ll use vector similarity as our relevance function for this blog. This lets us compute relevance elegantly by taking the dot product.
Implementing MMR
Let's see how to implement MMR for an image search system using Elasticsearch and multimodal embeddings. To showcase the effects of MMR we will be using the paramaggarwal/fashion-product-images-dataset dataset.
In this blog post we will only focus on the retrieval and reranking, but you can find a full end-to-end example in our search-labs GitHub repository.
First, we need to search for similar items using vector similarity:
def search_similar_images(es, index_name, query_vector, k=10):
"""Search for similar images using vector similarity"""
query = {
"knn": {
"field": "image_vector",
"query_vector": query_vector,
"k": k
},
"_source": ["id", "image_url"],
"size": k
}
response = es.search(index=index_name, body=query)
return extract_results(response)This gives us our initial relevance-ranked results. Now, let's apply MMR to rerank them for diversity:
def maximal_marginal_relevance(
query_embedding: List[float],
embedding_list: List[List[float]],
lambda_mult: float = 0.5, # value between 0.0 and 1.0
k: int = 4,
) -> List[int]:
query_embedding_arr = np.array(query_embedding)
if min(k, len(embedding_list)) <= 0:
return []
if query_embedding_arr.ndim == 1:
query_embedding_arr = np.expand_dims(query_embedding_arr, axis=0)
# calcuate the similarity to the query for all reranking candidates
similarity_to_query = _cosine_similarity(query_embedding_arr, embedding_list)[0]
# start with the most similar item to the query
most_similar = int(np.argmax(similarity_to_query))
idxs = [most_similar]
selected = np.array([embedding_list[most_similar]])
# Iteratively select documents that maximize MMR score
while len(idxs) < min(k, len(embedding_list)):
best_score = -np.inf
idx_to_add = -1
# calulate the similarity between all candidate items and all selected items
similarity_to_selected = _cosine_similarity(embedding_list, selected)
# look at all candidates
for i, query_score in enumerate(similarity_to_query):
if i in idxs:
continue
# Find the highest similarity of this item to already selected items
redundant_score = max(similarity_to_selected[i])
# Calculate MMR score
equation_score = (lambda_mult * query_score - (1 - lambda_mult) * redundant_score)
# select this item if it has the highest MMR score for this run
if equation_score > best_score:
best_score = equation_score
idx_to_add = i
# append the item with the highest MMR score for this run to our list
idxs.append(idx_to_add)
selected = np.append(selected, [embedding_list[idx_to_add]], axis=0)
return idxsThe impact: Before and after MMR
Let's look at how MMR transforms search results for the query "pants":
Before MMR (pure relevance):
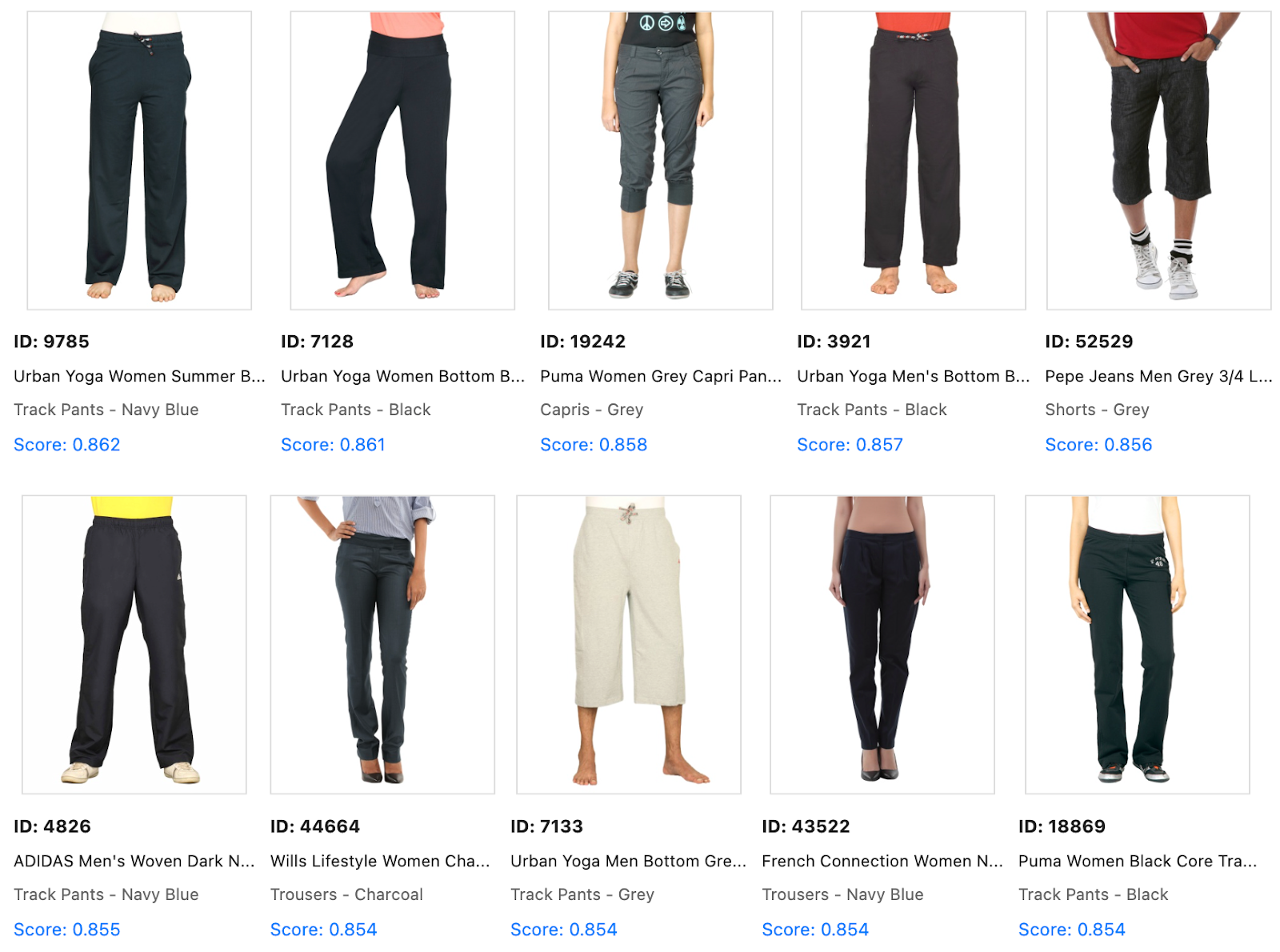
Notice the repetition? We see that most products are a dark shade with a straight cut.
After MMR (λ=0.5):
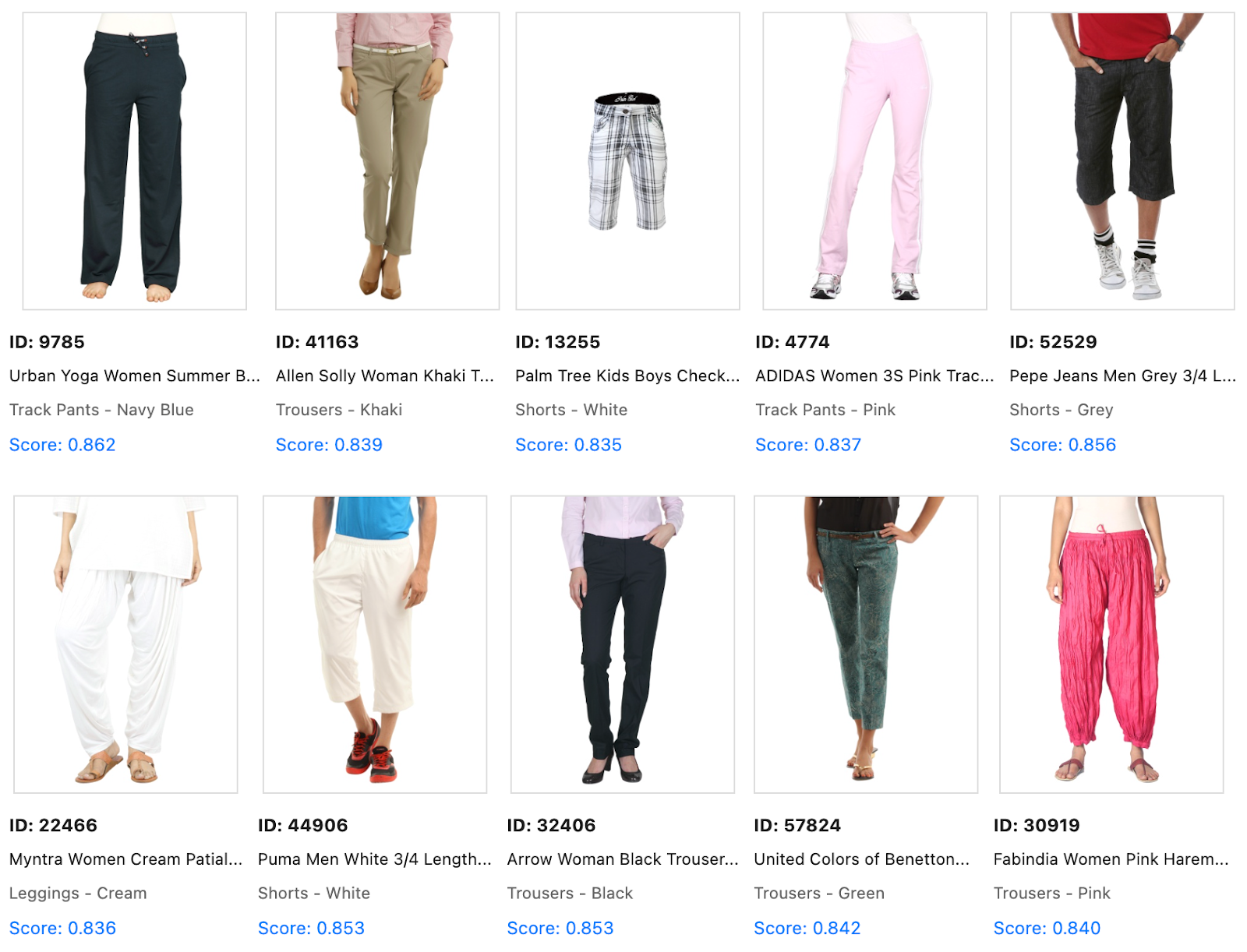
The reranked results showcase diversity in many features such as colors, brands, target demographics, style and more. Each result adds new information, making the exploration experience more valuable.
Tuning MMR for your use case
The beauty of MMR lies in its tunability. By adjusting the λ parameter, you can adapt the algorithm to different scenarios:
- Product Discovery (λ=0.3-0.5): Emphasize diversity to help users explore options
- Precision Search (λ=0.7-0.9): Prioritize relevance when users know what they want
- Research Applications (λ=0.5-0.7): Balance for comprehensive coverage
You can even make λ dynamic based on:
- Query type (broad vs. specific)
- User behavior (browsing vs. purchasing)
- Result set characteristics (high vs. low similarity)
Performance considerations
While MMR provides significant value, it does come with computational costs. The algorithm computes similarities between candidates and selected items. For production systems, consider limiting the reranking depth to a top k for results for the best tradeoff between impact and performance. Also, consider that retrieving the vectors will impact your performance, as it requires serialization of large amounts of data.
Beyond e-commerce: Other applications
While we've focused on fashion products and traditional search bars with result lists, MMR has broad applications. When using Retrieval Augmented Generation (RAG) applications, a request for "great vacation spots" could, without result diversification, yield results solely focused on Greek beaches. MMR, however, would diversify the output to include a range of vacation types, from relaxing beach holidays in Greece to adventurous hikes up an Icelandic volcano. Other use-cases could include:
- News aggregation: Show articles from different sources and perspectives
- Document search: Surface documents covering different aspects of a topic
- Recommendation: Suggest diverse movies, music, or content
- Academic search: Find papers from different research groups and methodologies
- And countless more
Conclusion
Maximum Marginal Relevance transforms search from a pure relevance race into a balanced information retrieval system. By implementing MMR with Elasticsearch, you can deliver search results that are not just relevant but also informative and diverse.
The key is finding the right balance for your use case. Start with λ=0.7 for a relevance-leaning approach, then adjust based on user feedback and behavior. Your users will appreciate seeing a variety of relevant options rather than slight variations of the same thing.
Sometimes the second-best match that's different is more valuable than another perfect match that's redundant. That's the power of diversity in search.
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content

September 15, 2025
Balancing the scales: Making reciprocal rank fusion (RRF) smarter with weights
Exploring weighted reciprocal rank fusion (RRF) in Elasticsearch and how it works through practical examples.

September 8, 2025
MCP for intelligent search
Building an intelligent search system by integrating Elastic's intelligent query layer with MCP to enhance the generative efficacy of LLMs.

Building intelligent duplicate detection with Elasticsearch and AI
Explore how organizations can leverage Elasticsearch to detect and handle duplicates in loan or insurance applications.

July 9, 2025
Semantic text is all that and a bag of (BBQ) chips! With configurable chunking settings and index options
Semantic text search is now customizable, with support for customizable chunking settings and index options to customize vector quantization, making semantic_text more powerful for expert use cases.

May 28, 2025
Hybrid search revisited: introducing the linear retriever!
Discover how the linear retriever enhances hybrid search by leveraging weighted scores and MinMax normalization for more precise and consistent rankings. Learn how to configure this new tool for optimized search pipelines and improve your results today.