In today’s digital age, search engines are the backbone of how we access information. Whether it’s a web search engine, an e-commerce site, an internal enterprise search tool, or a Retrieval Augmented Generation (RAG) system, the quality of search results directly impacts user satisfaction and engagement. But what ensures that search results meet user expectations? Enter the judgment list, a tool to evaluate and refine search result quality. At OpenSource Connections, our experts regularly help clients create and use judgment lists to improve their user search experience. In this post, we’ll explore why a judgment list is essential, the different types of judgments, and the key factors that define search quality.
Why do you need a judgment list?
Judgment lists play a crucial role in the continuous cycle of search result quality improvement. They provide a reliable benchmark for evaluating search relevance by offering a curated set of assessments on whether search results truly meet user needs. Without high-quality judgment lists, search teams would struggle to interpret feedback from users and automated signals, making it difficult to validate hypotheses about improving search. For example, if a team hypothesizes that hybrid search will increase relevance and expects a 2% increase in click-through rate (CTR), they need judgment lists to compare before-and-after performance meaningfully.
These lists help ground experimentation results in objective measures, ensuring that changes positively impact business outcomes before they are rolled out broadly. By maintaining robust judgment lists, search teams can iterate with confidence, refining the search experience in a structured, data-driven way.
A judgment list is a curated set of search queries paired with relevance ratings for their corresponding results, also known as a test collection. Metrics computed using this list act as a benchmark for measuring how well a search engine performs. Here’s why it’s indispensable:
- Evaluating search algorithms: It helps determine whether a search algorithm is returning the most relevant results for a given query.
- Measuring improvements or regressions: When you make changes to your search engine, a judgment list can quantify the impact of those changes on result quality.
- Providing insights into user satisfaction: By simulating expected outcomes, a judgment list aligns system performance with user needs.
- Helping product development: By making product requirements explicit, a judgment list supports search engineers implementing them.
For example, if a user searches for “best smartphones under $500,” your judgment list can indicate whether the results not only list relevant products but also cater to the query intent of affordability and quality.
Judgment lists are used in offline testing. Offline testing enables rapid, cost-effective iterations before committing to time-consuming live experiments like A/B testing. Ideally, combining both online and offline testing maximizes experimentation efficiency and ensures robust search improvements.
What is a judgment?
At its core, a judgment is a rating of how relevant a search result is for a specific query. Judgments can be categorized into two main types: binary judgments and graded judgments.
Binary judgments
- Results are labeled as either relevant (1) or not relevant (0).
- Example: A product page returned for the query “wireless headphones” either matches the query intent or it doesn’t.
- Use case: Binary judgments are simple and useful for queries with clear-cut answers.
Graded judgments
- Results are assigned a relevance score on a scale (e.g., 0 to 3), with each value representing a different level of relevance:
- 0: Definitely irrelevant
- 1: Probably irrelevant
- 2: Probably relevant
- 3: Definitely relevant
- Example: A search result for “best laptops for gaming” might score:
- 3 for a page listing laptops specifically designed for gaming,
- 2 for a page featuring laptops that could be suitable for gaming,
- 1 for gaming-related accessories, and
- 0 for items unrelated to gaming laptops.
- Scales can also be categorical rather than numeric, for example:
- Exact
- Substitute
- Complement
- Irrelevant
- Use case: Graded judgments are ideal for queries requiring a nuanced evaluation of relevance, beyond a simple binary determination of “relevant” or “not relevant.” This approach accommodates scenarios where multiple factors influence relevance.
Some evaluation metrics explicitly require more than a binary judgment. We use graded judgments when we want to model specific information-seeking behaviors and expectations in our evaluation metric. For example, the gain based metrics, Discounted Cumulative Gain (DCG), normalized Discounted Cumulative Gain (nDCG), and Expected Reciprocal Rank (ERR), model a user whose degree of satisfaction with a result can be greater or lesser, while still being relevant. This is useful for those who are researching and gathering information to make a decision.
Example of a judgment list
Let’s consider an example of a judgment list for an e-commerce search engine:
| Query | Result URL | Relevance |
|---|---|---|
| wireless headphones | /products/wireless-headphones-123 | 3 |
| wireless headphones | /products/noise-cancelling-456 | 3 |
| best laptops for gaming | /products/gaming-laptops-789 | 3 |
| best laptops for gaming | /products/ultrabook-321 | 2 |
In this list:
- The query “wireless headphones” evaluates the relevance of two product pages, with scores indicating how well the result satisfies the user’s intent.
- A score of 3 represents high relevance, a very good match, while lower scores suggest the result is less ideal.
This structured approach allows search teams to objectively assess and refine their search algorithms.
Different kinds of judgments
To create a judgment list, you need to evaluate the relevance of search results, and this evaluation can come from different sources. Each type has its strengths and limitations:
1. Explicit judgments
These are made by human evaluators who assess search results based on predefined guidelines. Typically, Subject Matter Experts (SMEs) are preferred as human evaluators for their knowledge. Explicit judgments offer high accuracy and nuanced insights but also pose unique challenges. Explicit judgments are very good in capturing the actual relevance of a document for a given query.
- Strengths: High accuracy, nuanced understanding of intent, and the ability to interpret complex queries.
- Limitations: Time-consuming, costly for large datasets, and prone to certain challenges.
Challenges:
- Variation: Different judges might assess the same result differently, introducing inconsistency.
- Position bias: Results higher up in the ranking are often judged as more relevant regardless of actual quality.
- Expertise: Not all judges possess the same level of subject matter or technical expertise, leading to potential inaccuracies.
- Interpretation: User intent or the information need behind a query can be ambiguous or difficult to interpret.
- Multitasking: Judges often handle multiple tasks simultaneously, which may reduce focus.
- Fatigue: Judging can be mentally taxing, impacting judgment quality over time.
- Actual vs. perceived relevance: Some results may appear relevant at first glance (e.g., by a misleading product image) but fail closer scrutiny.
- Scaling: As the dataset grows, efficiently gathering enough judgments becomes a logistical challenge.
Best practices:
To overcome these challenges, follow these guidelines:
- Define information needs and tasks clearly to reduce variation in how judges assign grades.
- Train judges thoroughly and provide detailed guidance.
- Avoid judging results in a list view to minimize position bias.
- Correlate judgments from different groups (e.g., subject matter experts versus general judges) to identify discrepancies.
- Use crowdsourcing or specialized agencies to scale the evaluation process efficiently.
2. Implicit judgments
Implicit judgments are inferred from user behavior data such as click-through rates, dwell time, and bounce rates. While they offer significant advantages, they also present unique challenges. In addition to relevance, implicit judgments capture search result quality aspects that match user taste or preference (for example, cost, and delivery time) as well as factors that fulfill the user in a certain way or the attractiveness of a product to a user (for example, sustainability features of the product).
- Strengths: Scalable and based on real-world usage, making it possible to gather massive amounts of data without manual intervention.
- Limitations: Susceptible to biases and other challenges that affect the reliability of the judgments.
Challenges:
- Clicks are noisy: Users might click on results due to missing or unclear information on the search results page, not because the result is truly relevant.
- Biases:
- Position bias: Users are more likely to click on higher-ranked results, regardless of their actual relevance.
- Presentation bias: Users cannot click on what is not shown, resulting in missing interactions for potentially relevant results.
- Conceptual biases: For example, in a grid view result presentation users tend to interact more often with results at the grid margins.
- Sparsity issues: Metrics like CTR can be skewed in scenarios with limited data (e.g., CTR = 1.0 if there’s only 1 click out of 1 view).
- No natural extension points: Basic models like CTR lack built-in mechanisms for handling nuanced user behavior or feedback.
Best practices:
To mitigate these challenges and maximize the value of implicit judgments:
- Avoid over-reliance on position bias-prone metrics: Combine implicit signals with other data points to create a more holistic evaluation.
- Correlate implicit judgments with explicit feedback: Compare user behavior data with manually graded relevance scores to identify alignment and discrepancies.
- Train your models thoughtfully: Ensure they account for biases and limitations inherent in user behavior data by using a model that incorporates countermeasures for biases and provides options to combine different signals (for example clicks and purchases).
3. AI-generated judgments
AI-generated judgments leverage large language models (LLMs) like OpenAI’s GPT-4o to judge query-document pairs. These judgments are gaining traction due to their scalability and cost-effectiveness. LLMs as judges capture the actual relevance of a document for a given query well.
- Strengths: Cost-efficient, scalable, and consistent across large datasets, enabling quick evaluations of vast numbers of results.
- Limitations: AI-generated judgments may lack context-specific understanding, introduce biases from training data, and fail to handle edge cases effectively.
Challenges:
- Training data bias: The AI model’s outputs are only as good as the data it’s trained on, potentially inheriting or amplifying biases.
- Context-specific nuances: AI may struggle with subjective or ambiguous queries that require human-like understanding.
- Interpretability: Understanding why a model assigns a specific judgment can be difficult, reducing trust in the system.
- Scalability trade-offs: While AI can scale easily, ensuring quality across all evaluations requires significant computational resources and potentially fine-tuning.
- Cost: While LLM judgments scale well, they are not free. Monitor your expenses closely.
Best practices:
To address these challenges and make the most of AI-generated judgments:
- Incorporate human oversight: Periodically compare AI-generated judgments with explicit human evaluations to catch errors and edge cases and use this information to improve your prompt.
- Enhance interpretability: Use explainable AI techniques to improve understanding and trust in the LLM’s decisions. Make the LLM explain its decision as part of your prompt.
- Optimize computational resources: Invest in infrastructure that balances scalability with cost-effectiveness.
- Combine AI with other judgment types: Use AI-generated judgments alongside explicit and/or implicit judgments to create a holistic evaluation framework.
- Prompt engineering: Invest time in your prompt. Even small changes can make a huge difference in judgment quality.
Different factors of search quality
Different kinds of judgments incorporate different aspects or factors of search quality. We can divide search result quality factors into three groups:
- Search relevance: This measures how well a document matches the information need expressed in the query. For instance:
- Binary judgments: Does the document fulfill the query (relevant or not)?
- Graded judgments: How well does the document fulfill the query on a nuanced scale?
Explicit judgments and AI-generated judgments work well to capture search relevance.
- Relevance factors: These address whether the document aligns with specific user preferences. Examples include:
- Price: Is the result affordable or within a specified range?
- Brand: Does it belong to a brand the user prefers?
- Availability: Is the item in stock or ready for immediate use
Implicit judgments capture relevance factors well.
- Fulfillment aspects: These go beyond relevance and preferences to consider how the document resonates with broader user values or goals. Examples include:
- Sustainability: Does the product or service promote environmental responsibility?
- Ethical practices: Is the company or provider known for fair trade or ethical standards?
Fulfillment aspects are the most difficult to measure and quantify. Understanding your users is key and implicit feedback is the best way to move in that direction. Be aware of biases in implicit feedback and apply techniques to counter these as well as possible, for example when modeling the judgments based on implicit feedback.
By addressing these factors systematically, search systems can ensure a holistic approach to evaluating and enhancing result quality.
Where do judgment lists fit in the search quality improvement cycle?
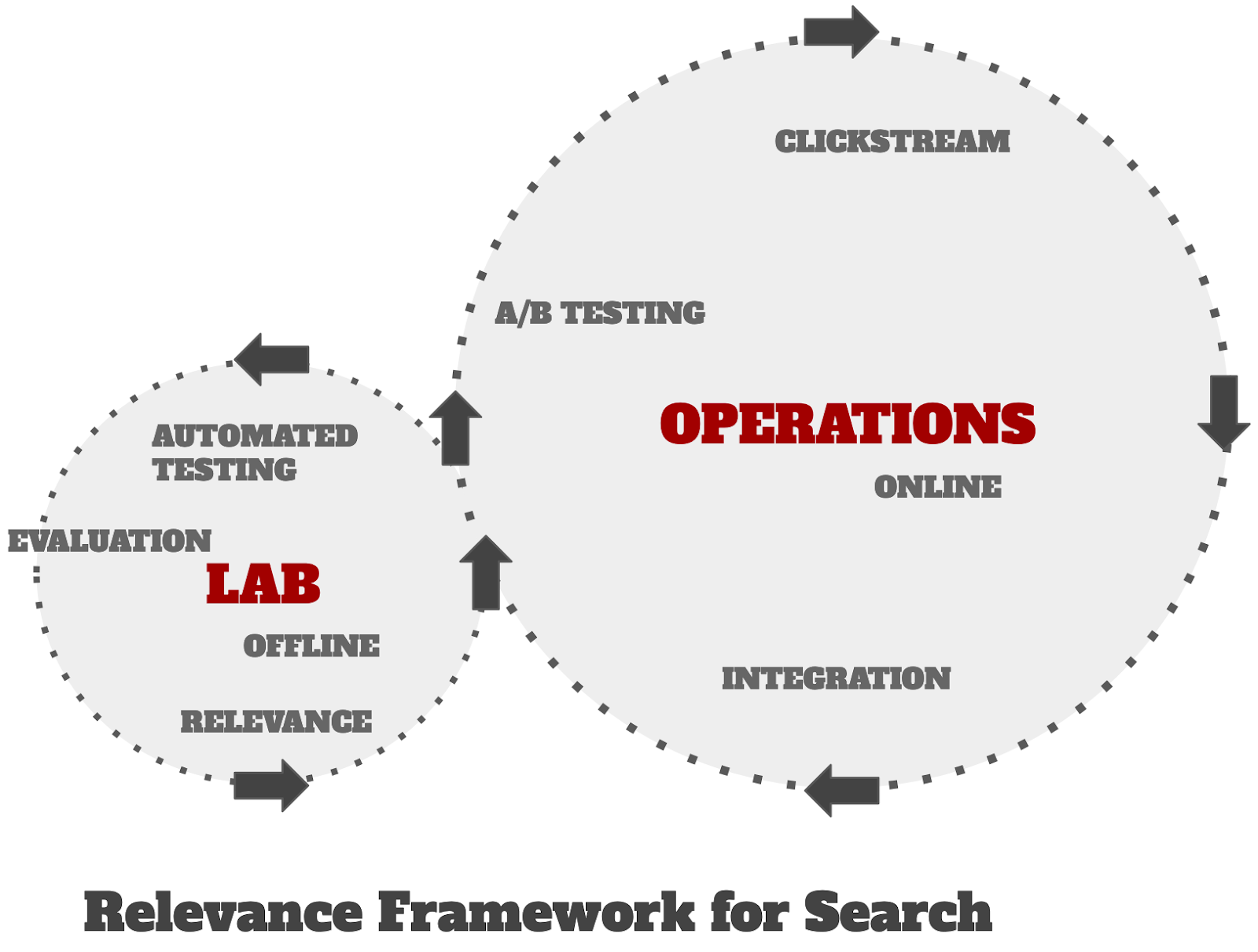
Search quality improvement is an iterative process that involves evaluating and refining search algorithms to better meet user needs. Judgment lists play a central role in offline experimentation (the smaller, left cycle in the image below), where search results are tested against predefined relevance scores without involving live users. This allows teams to benchmark performance, identify weaknesses, and make adjustments before deploying changes. This makes offline experimentation a fast and low-risk way of exploring potential improvements before trialing them in an online experiment.
Online experimentation (the larger, right cycle) uses live user interactions, such as A/B testing, to gather real-world feedback on system updates. While offline experimentation with judgment lists ensures foundational quality, online experimentation captures dynamic, real-world nuances and user preferences. Both approaches complement each other, forming a comprehensive framework for search quality improvement.
Tools to create judgment lists
At its core, creating judgment lists is a labeling task where ultimately we are seeking to add a relevance label to a query-document pair. Some of the services that exist are:
- Quepid: An open source solution that supports the whole offline experimentation lifecycle from creating query sets to measuring search result quality with judgment lists created in Quepid.
- Label Studio: A data labeling platform that is predominantly used for generating training data or validating AI models.
- Amazon SageMaker Ground Truth: A cloud service offering data labeling to apply human feedback across the machine learning lifecycle.
- Prodigy: A complete data development experience with an annotation capability to label data.
Looking ahead: Creating judgment lists with Quepid
This post is the first in a series on search quality evaluation. In our next post, we will dive into the step-by-step process of creating explicit judgments using a specific tool called Quepid. Quepid simplifies the process of building, managing, and refining judgment lists, enabling teams to collaboratively improve search quality. Stay tuned for practical insights and tips on leveraging this tool to enhance the quality of your search results.
Conclusion
A judgment list is a cornerstone of search quality evaluation, providing a reliable benchmark for measuring performance and guiding improvements. By leveraging explicit, implicit, and AI-generated judgments, organizations can address the multifaceted nature of search quality—from relevance and accuracy to personalization and diversity. Combining these approaches ensures a comprehensive and robust evaluation strategy.
Investing in a well-rounded strategy for search quality not only enhances user satisfaction but also positions your search system as a trusted and reliable tool. Whether you’re managing a search engine or fine-tuning an internal search feature, a thoughtful approach to judgments and search quality factors is essential for success.
Partner with Open Source Connections to transform your search capabilities and empower your team to continuously evolve them. Our proven track record spans the globe, with clients consistently achieving dramatic improvements in search quality, team capability, and business performance. Contact us today to learn more.
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content

September 15, 2025
Balancing the scales: Making reciprocal rank fusion (RRF) smarter with weights
Exploring weighted reciprocal rank fusion (RRF) in Elasticsearch and how it works through practical examples.

September 8, 2025
MCP for intelligent search
Building an intelligent search system by integrating Elastic's intelligent query layer with MCP to enhance the generative efficacy of LLMs.

Building intelligent duplicate detection with Elasticsearch and AI
Explore how organizations can leverage Elasticsearch to detect and handle duplicates in loan or insurance applications.

July 10, 2025
Diversifying search results with Maximum Marginal Relevance
Implementing the Maximum Marginal Relevance (MMR) algorithm with Elasticsearch and Python. This blog includes code examples for vector search reranking.

July 9, 2025
Semantic text is all that and a bag of (BBQ) chips! With configurable chunking settings and index options
Semantic text search is now customizable, with support for customizable chunking settings and index options to customize vector quantization, making semantic_text more powerful for expert use cases.