The creation of judgement lists is a crucial step in optimizing search result quality, but it can be a complicated and difficult task. A judgement list is a curated set of search queries paired with relevance ratings for their corresponding results, also known as a test collection. Metrics computed using this list act as a benchmark for measuring how well a search engine performs. To help streamline the process of creating judgement lists, the OpenSource Connections team developed Quepid. Judgement can either be explicit or based on implicit feedback from users. This blog will guide you through setting up a collaborative environment in Quepid to effectively enable human raters to do explicit judgements, which is the foundation of every judgement list.
Quepid supports search teams in the search quality evaluation process:
- Build query sets
- Create judgement lists
- Calculate search quality metrics
- Compare different search algorithms/rankers based on calculated search quality metrics
For our blog, let's assume that we are running a movie rental store and have the goal of improving our search result quality.
Prerequisites
This blog uses the data and the mappings from the es-tmdb repository. The data is from The Movie Database. To follow along, set up an index called tmdb with the mappings and index the data. It doesn’t matter if you set up a local instance or use an Elastic Cloud deployment for this - either works fine. We assume an Elastic Cloud deployment for this blog. You can find information about how to index the data in the README of the es-tmdb repository.
Do a simple match query on the title field for rocky to confirm you have data to search in:
GET tmdb/_search
{
"query": {
"match": {
"title": "rocky"
}
}
}You should see 8 results.
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 8,
"relation": "eq"
}
…
}Log into Quepid
Quepid is a tool that enables users to measure search result quality and run offline experiments to improve it.
You can use Quepid in two ways: either use the free, publicly available hosted version at https://app.quepid.com, or set up Quepid on a machine you have access to. This post assumes you are using the free hosted version. If you want to set up a Quepid instance in your environment, follow the Installation Guide.
Whichever setup you choose, you’ll need to create an account if you don’t already have one.
Set up a Quepid Case
Quepid is organized around "Cases." A Case stores queries together with relevance tuning settings and how to establish a connection to your search engine.
- For first-time users, select Create Your First Relevancy Case.
- Returning users can select Relevancy Cases from the top-level menu and click + Create a case.
Name your case descriptively, e.g., "Movie Search Baseline," as we want to start measuring and improving our baseline search.
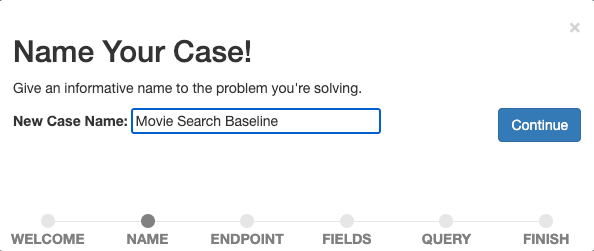
Confirm the name by selecting Continue.
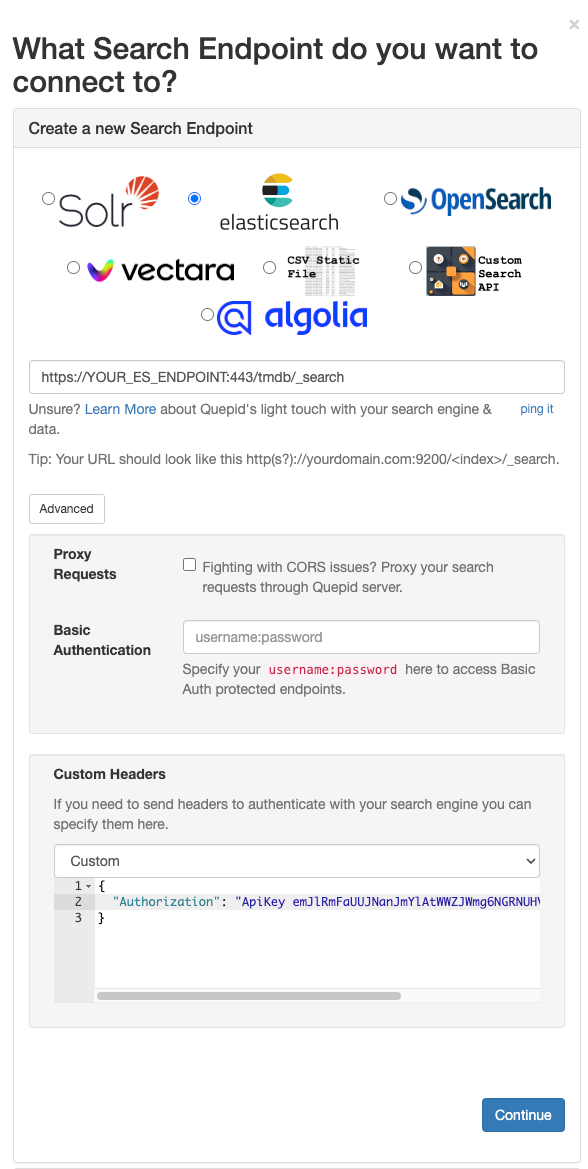
Next, we establish a connection from Quepid to the search engine. Quepid can connect to a variety of search engines, including Elasticsearch.
The configuration will differ depending on your Elasticsearch and Quepid setup. To connect Quepid to an Elastic Cloud deployment, we need to enable and configure CORS for our Elastic Cloud deployment and have an API key ready. Detailed instructions are in the corresponding how-to on the Quepid docs.
Enter your Elasticsearch endpoint information (https://YOUR_ES_HOST:PORT/tmdb/_search) and any additional information necessary to connect (the API key in case of an Elastic Cloud deployment in the Advanced configuration options), test the connection by clicking on ping it and select Continue to move to the next step.
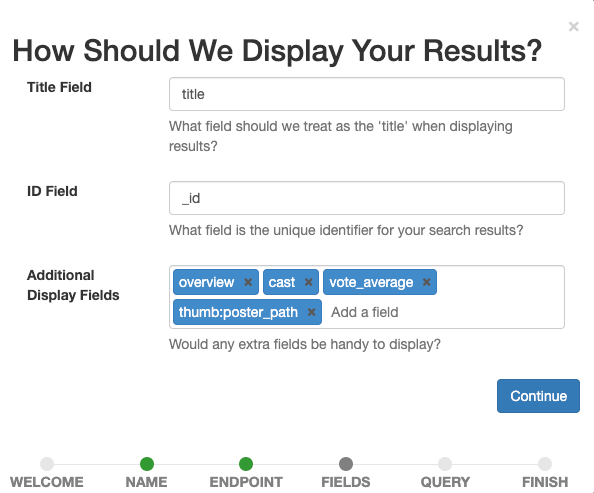
Now we define which fields we want to see displayed in the case. Select all that help our human raters later assess the relevance of a document for a given query.
Set title as the Title Field, leave _id as the ID Field, and add overview, tagline, cast, vote_average, thumb:poster_path as Additional Display Fields. The last entry displays small thumbnail images for the movies in our results to visually guide us and the human raters.
Confirm the display settings by selecting the Continue button.
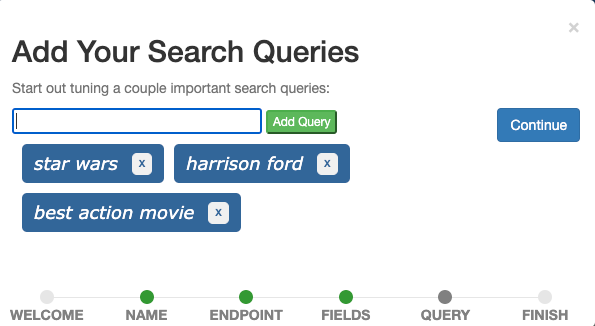
The last step is adding search queries to the case. Add the three queries star wars, harrison ford, and best action movie one by one via the input field and Continue.
Ideally, a case contains queries that represent real user queries and illustrate different types of queries. For now, we can imagine star wars being a query representing all queries for movie titles, harrison ford a query representing all queries for cast members, and best action movie a query representing all queries that search for movies in a specific genre. This is typically called a query set.
In a production scenario, we would sample queries from event tracking data by applying statistical techniques like Probability-Proportional-to-Size sampling and import these sampled queries into Quepid to include queries from the head (frequent queries) and tail (infrequent queries) relative to their frequency, which means we bias towards more frequent queries without excluding rare ones.
Finally, select Finish and you will be forwarded to the case interface where you see the three defined queries.
Queries and Information Needs
To arrive at our overarching goal of a judgement list, human raters will need to judge a search result (typically a document) for a given query. This is called a query/document pair.
Sometimes, it seems easy to know what a user wanted when looking at the query. The intention behind the query harrison ford is to find movies starring Harrison Ford, the actor. What about the query action? I know I’d be tempted to say the user’s intention is to find movies belonging to the action genre. But which ones? The most recent ones, the most popular ones, the best ones according to user ratings? Or does the user maybe want to find all movies that are called “Action”? There are at least 12 (!) movies called “Action” in The Movie Database and their names mainly differ in the number of exclamation marks in the title.
Two human raters may differ in interpreting a query where the intention is unclear. Enter the Information Need: An Information Need is a conscious or unconscious desire for information. Defining an information need helps human raters judge documents for a query, so they play an important role in the process of building judgement lists. Expert users or subject matter experts are good candidates for specifying information needs. It is good practice to define information needs from the perspective of the user, as it's their need the search results should fulfill.
Information needs for the queries of our “Movies Search Baseline” case:
- star wars: The user wants to find movies or shows from the Star Wars franchise. Potentially relevant are documentaries about Star Wars.
- harrison ford: The user wants to find movies starring the actor Harrison Ford. Potentially relevant are movies where Harrison Ford has a different role, like narrator.
- best action movie: The user wants to find action movies, preferably the ones with high average user votes.
Define Information Needs in Quepid
To define an information need in Quepid, access the case interface:
1. Open a query (for example star wars) and select Toggle Notes.
2. Enter the Information Need in the first field and any additional notes in the second field:
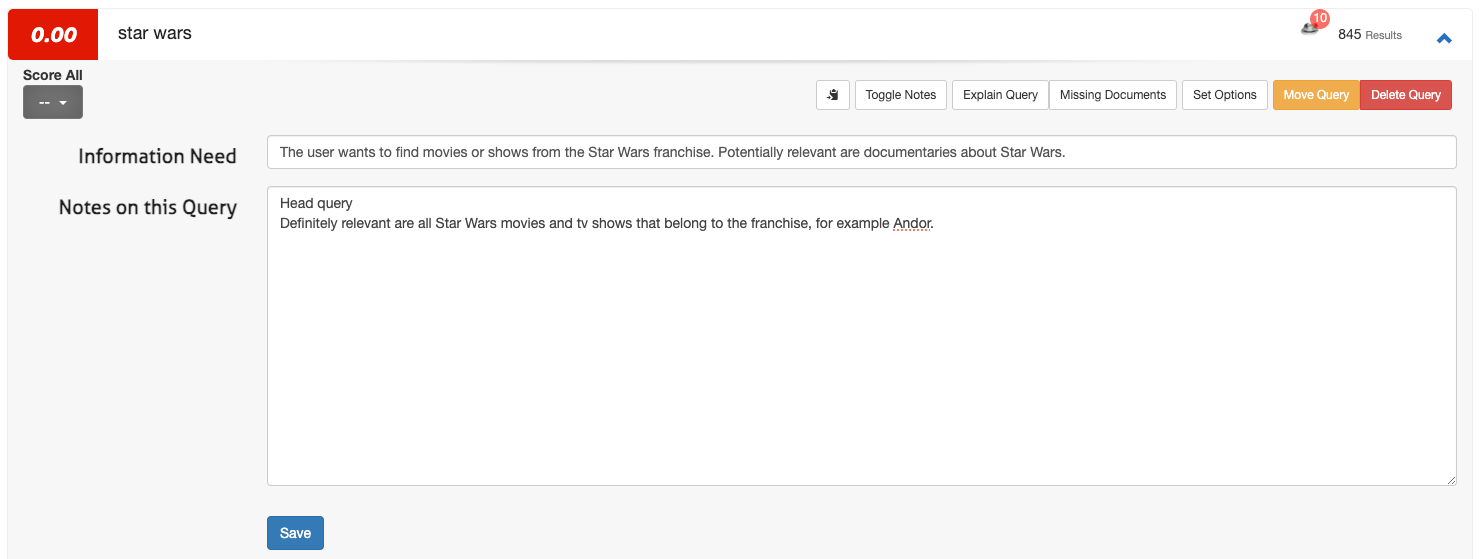
3. Click Save.
For a handful of queries, this process is fine. However, when you expand your case from three to 100 queries (Quepid cases are often in the range of 50 to 100 queries) you may want to define information needs outside of Quepid (for example, in a spreadsheet) and then upload them via Import and select Information Needs.
Create a Team in Quepid and Share your Case
Collaborative judgements enhance the quality of relevance assessments. To set up a team:
1. Navigate to Teams in the top-level menu.

2. Click + Add New, enter a team name (for example, "Search Relevance Raters"), and click Create.
3. Add members by typing their email addresses and clicking Add User.
4. In the case interface, select Share Case.
5. Choose the appropriate team and confirm.
Create a Book of Judgements
A Book in Quepid allows multiple raters to evaluate query/document pairs systematically. To create one:
1. Go to Judgements in the case interface and click + Create a Book.
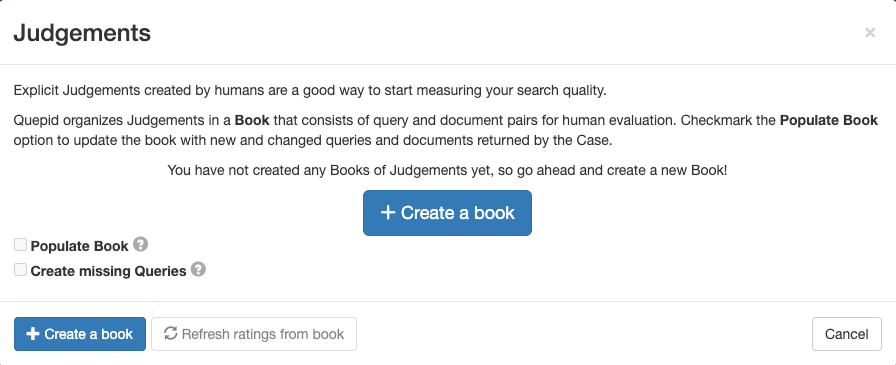
2. Configure the book with a descriptive name, assign it to your team, select a scoring method (for example, DCG@10), and set the selection strategy (single or multiple raters). Use the following settings for the Book:
- Name: “Movies Search 0-3 Scale”
- Teams to Share this Book With: Check the box with the Team you created
- Scorer: DCG@10
3. Click Create Book.
The name is descriptive and contains information about what is searched in (“Movies”) and also the scale of the judgements (“0-3”). The selected Scorer DCG@10 defines the way the search metric will be calculated. “DCG” is short for Discounted Cumulative Gain and“@10” is the number of results from the top taken into consideration when the metric is calculated.
In this case, we are using a metric that measures the information gain and combines it with positional weighting. There may be other search metrics that are more suitable for your use case and choosing the right one is a challenge in itself.
Populate the Book with Query/Document Pairs
In order to add query/document pairs for relevance assessment, follow these steps:
1. In the case interface, navigate to "Judgements."
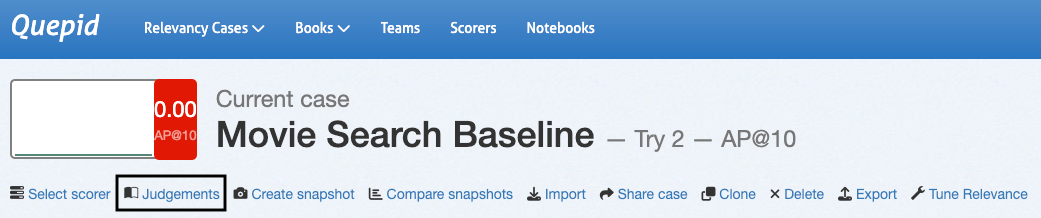
2. Select your created book.
3. Click "Populate Book" and confirm by selecting "Refresh Query/Doc Pairs for Book."
This action generates pairs based on the top search results for each query, ready for evaluation by your team.
Let your Team of Human Raters Judge
So far, the completed steps were fairly technical and administrative. Now that this necessary preparation is done, we can let our team of judges do their work. In essence, the judge’s job is to rate the relevance of one particular document for a given query. The result of this process is the judgement list that contains all relevance labels for the judged query document pairs. Next, this process and the interface for it are explained in further detail.
Overview of the Human Rating Interface
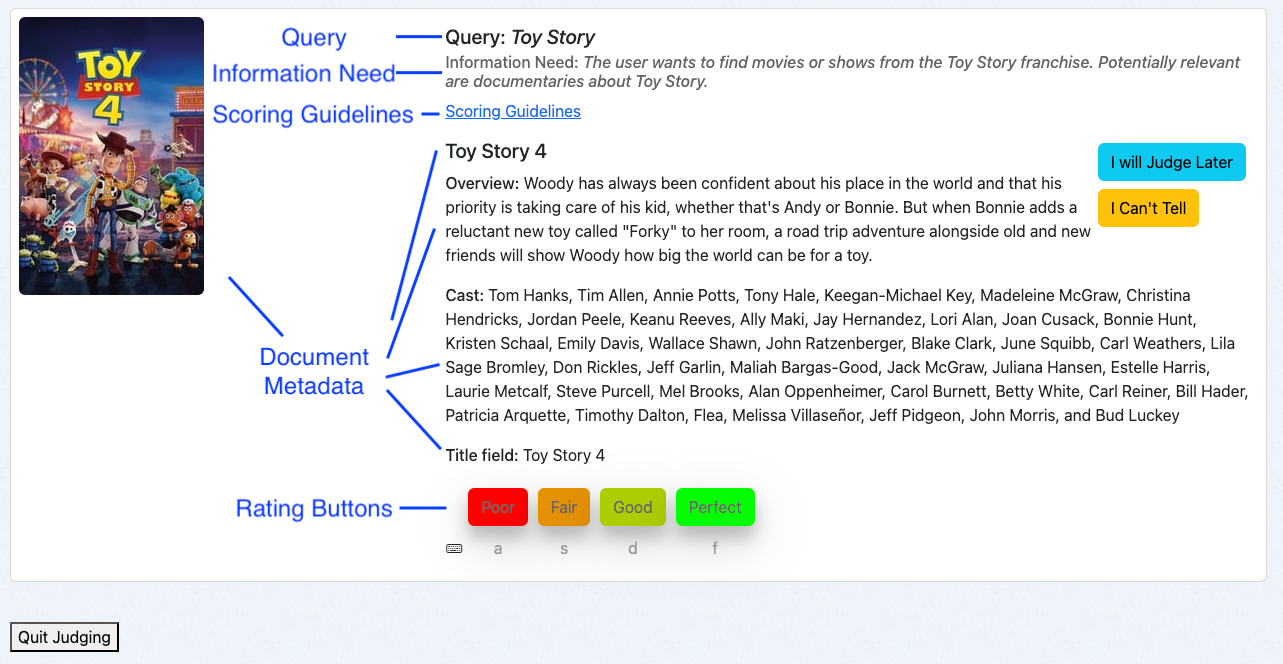
Quepid's Human Rating Interface is designed for efficient assessments:
- Query: Displays the search term.
- Information Need: Shows the user's intent.
- Scoring Guidelines: Provides instructions for consistent evaluations.
- Document Metadata: Presents relevant details about the document.
- Rating Buttons: Allows raters to assign judgements with corresponding keyboard shortcuts.
Using the Human Rating Interface
As a human rater, I access the interface via the book overview:
1. Navigate to the case interface and click Judgements.
2. Click on More Judgements are Needed!.
The system will present a query/document pair that has not been rated yet and that requires additional judgements. This is determined by the Book’s selection strategy:
- Single Rater: A single judgement per query/doc pair.
- Multiple Raters: Up to three judgements per query/doc pair.
Rating Query/Doc Pairs
Let’s walk through a couple of examples. When you are following this guide, you will most likely be presented with different movies. However, the rating principles stay the same.
Our first example is the movie “Heroes” for the query harrison ford:
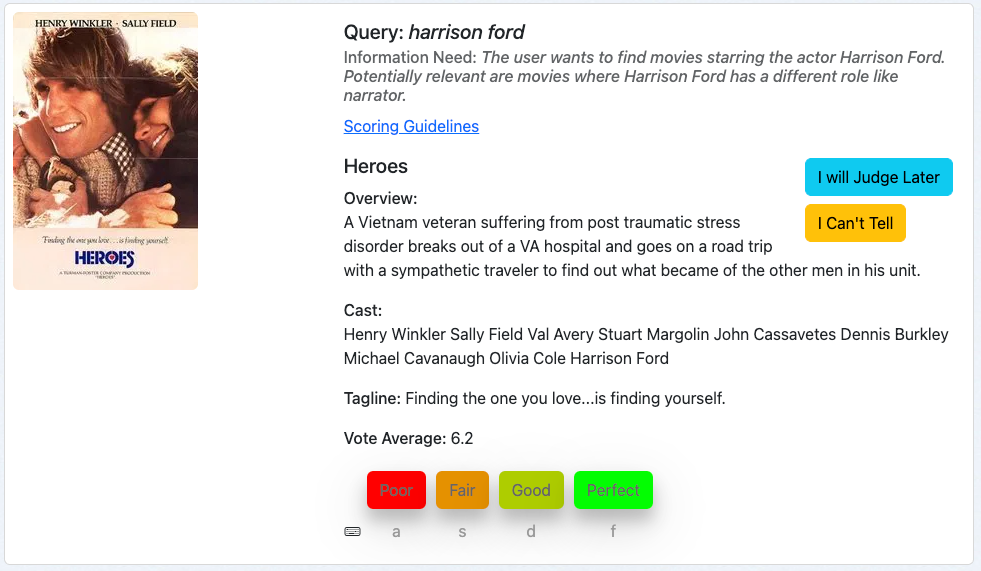
We first look at the query, followed by the information need and then judge the movie based on the metadata given.
This movie is a relevant result for our query, since Harridson Ford is in its cast. We may regard more recent movies as more relevant subjectively but this is not part of our information need. So we rate this document with “Perfect” which is a 3 in our graded scale.
Our next example is the movie “Ford v Ferrari” for the query harrison ford:
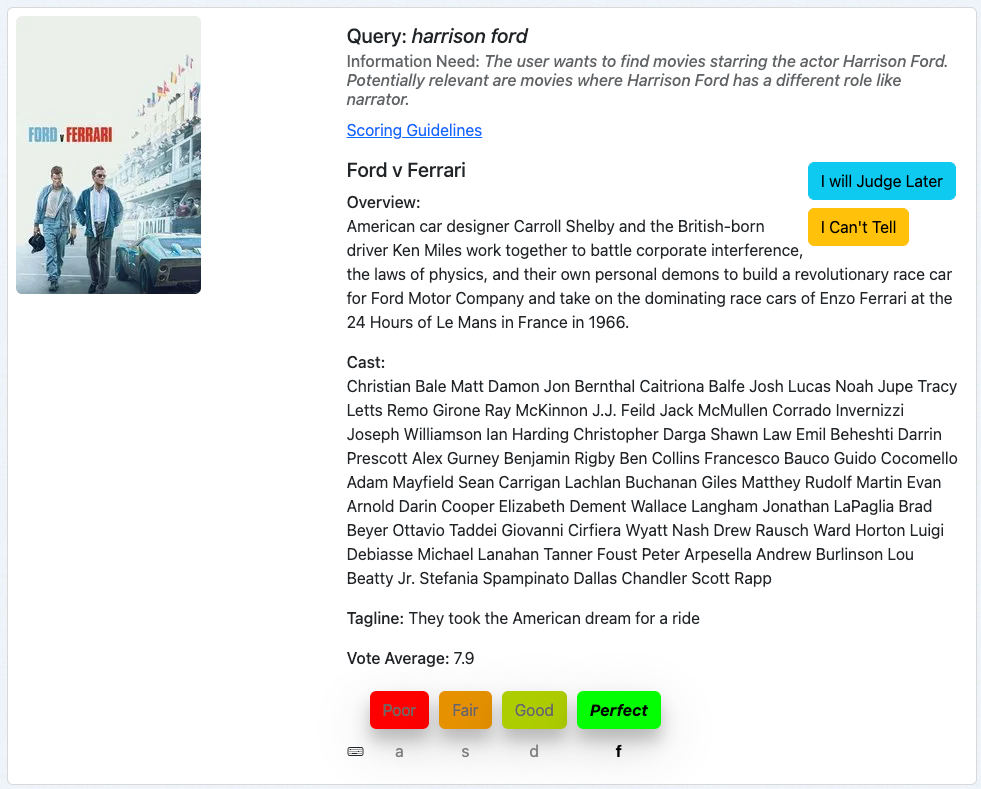
Following the same practice, we judge this query/doc by looking at the query, the information need and then how well the document’s metadata matches the information need.
This is a poor result. We probably see this result as one of our query terms, “ford”, matches in the title. But Harrison Ford plays no role in this movie, nor any other role. So we rate this document “Poor” which is a 0 in our graded scale.
Our third example is the movie “Action Jackson” for the query best action movie:
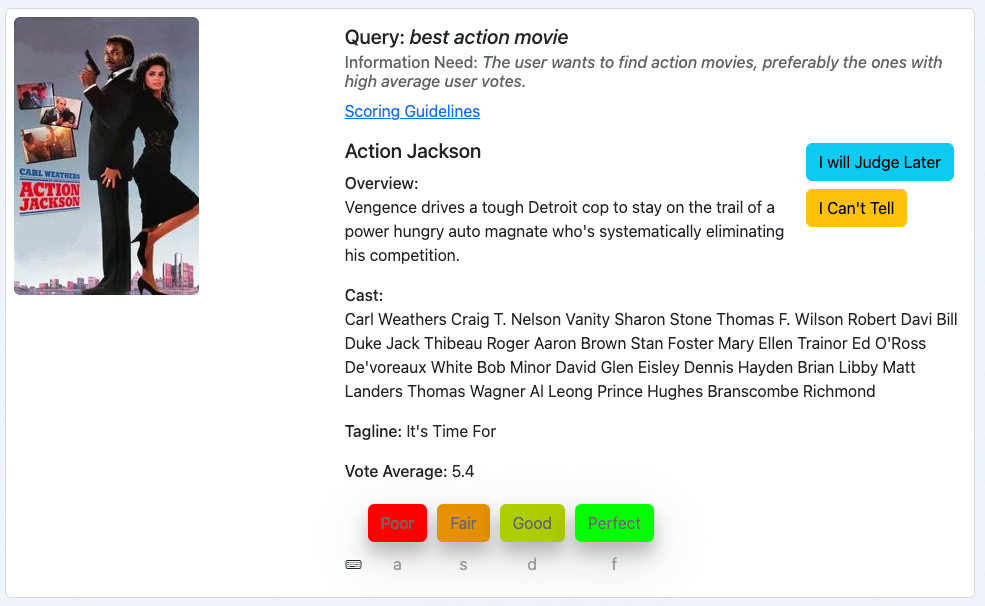
This looks like an action movie, so the information need is at least partially met. However, the vote average is 5.4 out of 10. And that makes this movie probably not the best action movie in our collection. This would lead me as a judge to rate this document “Fair,” which is a 1 in our graded scale.
These examples illustrate the process of rating query/doc pairs with Quepid in particular, on a high level and also in general.
Best Practices Human Raters
The shown examples might make it seem straightforward to get to explicit judgements. But setting up a reliable human rating program is no easy feat. It’s a process filled with challenges that can easily compromise the quality of your data:
- Human raters can become fatigued from repetitive tasks.
- Personal preferences may skew judgements.
- Levels of domain expertise vary from judge to judge.
- Raters often juggle multiple responsibilities.
- The perceived relevance of a document may not match its true relevance to a query.
These factors can result in inconsistent, low-quality judgements. But don’t worry - there are proven best practices that can help you minimize these issues and build a more robust and reliable evaluation process:
- Consistent Evaluation: Review the query, information need, and document metadata in order.
- Refer to Guidelines: Use scoring guidelines to maintain consistency. Scoring guidelines can contain examples of when to apply which grade which illustrates the process of judging. Having a check in with human raters after the first batch of judgements proved to be a good practice to learn about challenging edge cases and where additional support is needed.
- Utilize Options: If uncertain, use "I Will Judge Later" or "I Can’t Tell," providing explanations when necessary.
- Take Breaks: Regular breaks help maintain judgement quality. Quepid helps with regular breaks by popping confetti whenever a human rater finishes a batch of judgements.
By following these steps, you establish a structured and collaborative approach to creating judgement lists in Quepid, enhancing the effectiveness of your search relevance optimization efforts.
Next Steps
Where to go from here? Judgement lists are but one foundational step towards improving search result quality. Here are the next steps:
Calculate Metrics and Start Experimenting
Once judgement lists are available, leveraging the judgements and calculating search quality metrics is a natural progression. Quepid automatically calculates the configured metric for the current case when judgements are available. Metrics are implemented as “Scorers” and you can provide your own when the supported ones do not include your favorite!
Go to the case interface, navigate to Select Scorer, choose DCG@10 and confirm by clicking on Select Scorer. Quepid will now calculate DCG@10 per query and also average overall queries to quantify the search result quality for your case.
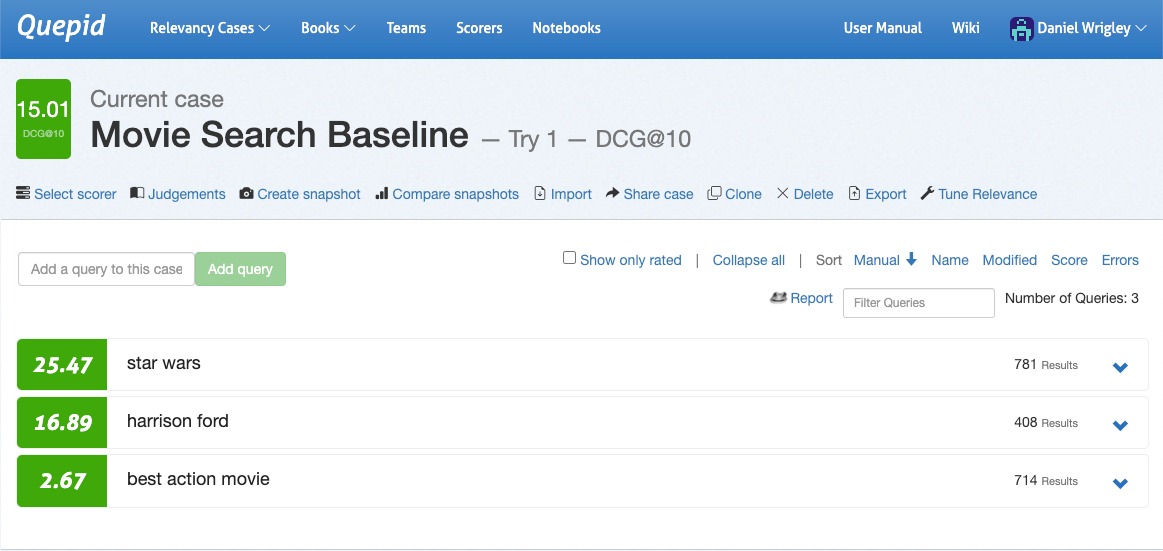
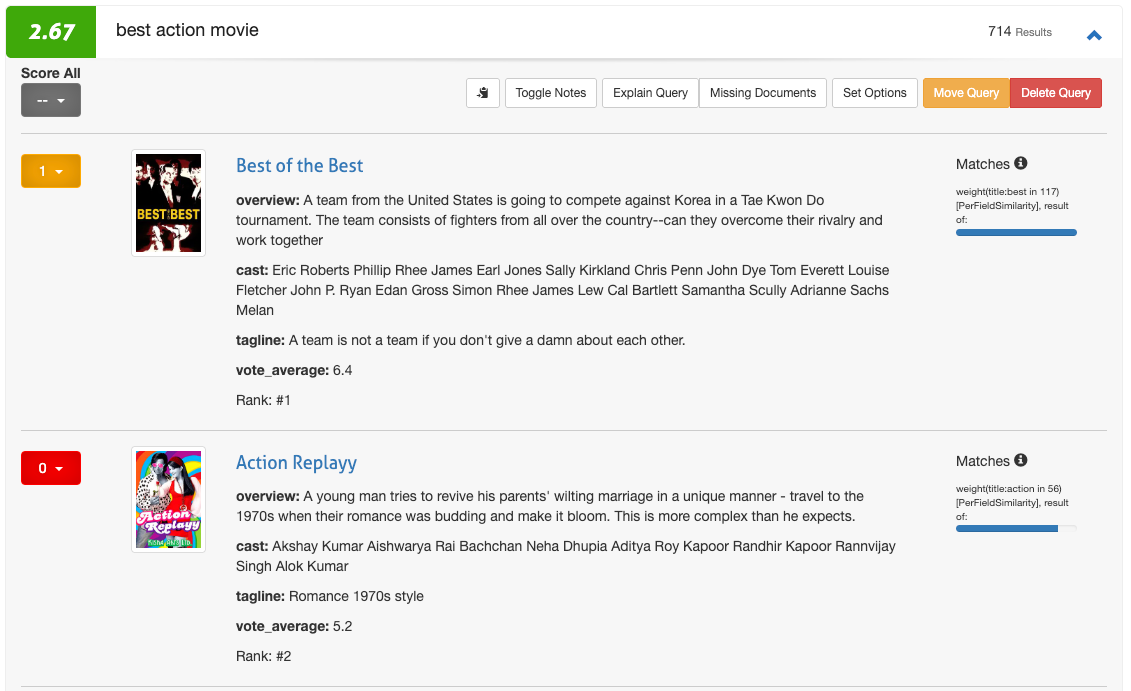
Now that your search result quality is quantified, you can run first experiments. Experimentation starts with generating hypotheses. Looking at the three queries in the screenshot after doing some rating makes it obvious that the three queries perform very differently in terms of their search quality metric: star wars performs pretty well, harrison ford looks alright but the greatest potential lies in best action movie.
Expanding this query we see its results and can dive into the nitty gritty details and explore why documents matched and what influences their scores:
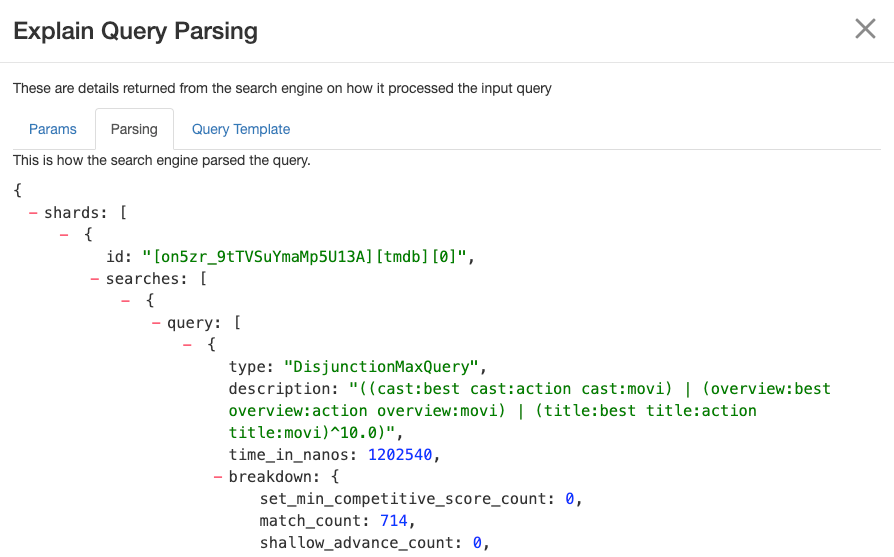
By clicking on “Explain Query” and entering the “Parsing” tab we see that the query is a DisjunctionMaxxQuery searching across three fields: cast, overview and title:
Typically, as search engineers we know some domain-specifics about our search platform. In this case, we may know that we have a genres field. Let’s add that to the query and see if search quality is improved.
We use the Query Sandbox that opens when selecting Tune Relevance in the case interface. Go ahead and explore this by adding the genres field you search in:
{
"query": {
"multi_match": {
"query": "#$query##",
"type": "best_fields",
"fields": [
"title^10",
"overview",
"cast",
"genres"
]
}
}
}Click Rerun My Searches! And view the results. Have they changed? Unfortunately not. We now have a lot of options to explore, basically all query options Elasticsearch offers:
- We could increase the field weight on the genres field.
- We could add a function that boosts documents by their vote average.
- We could create a more complex query that only boosts documents by their vote average if there is a strong genres match.
- …
The best thing about having all these options and exploring them in Quepid is that we have a way of quantifying the effects not only on the one query we try to improve but all queries we have in our case. That prevents us from improving one underperforming query by sacrificing search result quality for others. We can iterate fast and cheap and validate the value of our hypothesis without any risk, making offline experimentation a fundamental capability of all search teams.
Measure Inter-Rater Reliability
Even with task descriptions, information needs, and a human rater interface like the one Quepid provides, human raters can disagree.
Disagreement per se is no bad thing, quite the contrary: measuring disagreement can surface issues that you may want to tackle. Relevance can be subjective, queries can be ambiguous, and data can be incomplete or incorrect. Fleiss’ Kappa is a statistical measure for the agreement among raters and there is an example notebook in Quepid you can use. To find it, select Notebooks in the top-level navigation and select the notebook Fleiss Kappa.ipynb in the examples folder.

Conclusion
Quepid empowers you to tackle even the most complex search relevance challenges and continues to evolve: as of version 8 Quepid supports AI-generated judgements, which is particularly useful for teams who want to scale their judgement generation process.
Quepid workflows enable you to efficiently create judgement lists that are scalable–which ultimately results in search results that truly meet user needs. With judgement lists established, you have a robust foundation for measuring search relevance, iterating on improvements, and driving better user experiences.
As you move forward, remember that relevancy tuning is an ongoing process. Judgement lists allow you to systematically evaluate your progress, but they are most powerful when paired with experimentation, metric analysis, and iterative improvements.
Further Reading
- Quepid docs:
- Quepid Github repository
- Meet Pete, a blog series on improving e-commerce search
- Relevance Slack: join the #quepid channel
Partner with Open Source Connections to transform your search and AI capabilities and empower your team to continuously evolve them. Our proven track record spans the globe, with clients consistently achieving dramatic improvements in search quality, team capability, and business performance. Contact us today to learn more.
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content

September 15, 2025
Balancing the scales: Making reciprocal rank fusion (RRF) smarter with weights
Exploring weighted reciprocal rank fusion (RRF) in Elasticsearch and how it works through practical examples.

September 8, 2025
MCP for intelligent search
Building an intelligent search system by integrating Elastic's intelligent query layer with MCP to enhance the generative efficacy of LLMs.

Building intelligent duplicate detection with Elasticsearch and AI
Explore how organizations can leverage Elasticsearch to detect and handle duplicates in loan or insurance applications.

July 10, 2025
Diversifying search results with Maximum Marginal Relevance
Implementing the Maximum Marginal Relevance (MMR) algorithm with Elasticsearch and Python. This blog includes code examples for vector search reranking.

July 9, 2025
Semantic text is all that and a bag of (BBQ) chips! With configurable chunking settings and index options
Semantic text search is now customizable, with support for customizable chunking settings and index options to customize vector quantization, making semantic_text more powerful for expert use cases.