This is the second part of our Elasticsearch in JavaScript series. In the first part, we learned how to set up our environment correctly, configure the Node.js client, index data and search. In this second part, we will learn how to implement production best practices and run the Elasticsearch Node.js client in Serverless environments.
We will review:
You can check the source code with the examples here.
Production best practices
Error handling
A useful feature of the Elasticsearch client in Node.js is that it exposes objects for the possible errors in Elasticsearch so you can validate and handle them in different ways.
To see them all, run this:
const { errors } = require('@elastic/elasticsearch')
console.log(errors)Let’s go back to the search example and handle some of the possible errors:
app.get("/search/lexic", async (req, res) => {
....
} catch (error) {
if (error instanceof errors.ResponseError) {
let errorMessage =
"Response error!, query malformed or server down, contact the administrator!";
if (error.body.error.type === "parsing_exception") {
errorMessage = "Query malformed, make sure mappings are set correctly";
}
res.status(error.meta.statusCode).json({
erroStatus: error.meta.statusCode,
success: false,
results: null,
error: errorMessage,
});
}
res.status(500).json({
success: false,
results: null,
error: error.message,
});
}
});ResponseError in particular, will occur when the answer is 4xx or 5xx, meaning the request is incorrect or the server is not available.
We can test this type of error by generating wrong queries, like trying to do a term query on a text-type field:
Default error:
{
"success": false,
"results": null,
"error": "parsing_exception\n\tRoot causes:\n\t\tparsing_exception: [terms] query does not support [visit_details]"
}Customized error:
{
"erroStatus": 400,
"success": false,
"results": null,
"error": "Response error!, query malformed or server down; contact the administrator!"
}We can also capture and handle each type of error in a certain way. For example, we can add retry logic in a TimeoutError.
app.get("/search/semantic", async (req, res) => {
try {
...
} catch (error) {
if (error instanceof errors.TimeoutError) {
// Retry logic...
res.status(error.meta.statusCode).json({
erroStatus: error.meta.statusCode,
success: false,
results: null,
error:
"The request took more than 10s after 3 retries. Try again later.",
});
}
}
});Testing
Tests are key in guaranteeing the app's stability. To test the code in a way that is isolated from Elasticsearch, we can use the library elasticsearch-js-mock when creating our cluster.
This library allows us to instantiate a client that is very similar to the real one but that will answer to our configuration by only replacing the client’s HTTP layer with a mock one while keeping the rest the same as the original.
We’ll install the mocks library and AVA for automated tests.
npm install @elastic/elasticsearch-mock
npm install --save-dev ava
We’ll configure the package.json file to run the tests. Make sure it looks this way:
"type": "module",
"scripts": {
"test": "ava"
},
"devDependencies": {
"ava": "^5.0.0"
}Let’s now create a test.js file and install our mock client:
const { Client } = require('@elastic/elasticsearch')
const Mock = require('@elastic/elasticsearch-mock')
const mock = new Mock()
const client = new Client({
node: 'http://localhost:9200',
Connection: mock.getConnection()
})Now, add a mock for semantic search:
function createSemanticSearchMock(query, indexName) {
mock.add(
{
method: "POST",
path: `/${indexName}/_search`,
body: {
query: {
semantic: {
field: "semantic_field",
query: query,
},
},
},
},
() => {
return {
hits: {
total: { value: 2, relation: "eq" },
hits: [
{
_id: "1",
_score: 0.9,
_source: {
owner_name: "Alice Johnson",
pet_name: "Buddy",
species: "Dog",
breed: "Golden Retriever",
vaccination_history: ["Rabies", "Parvovirus", "Distemper"],
visit_details:
"Annual check-up and nail trimming. Healthy and active.",
},
},
{
_id: "2",
_score: 0.7,
_source: {
owner_name: "Daniel Kim",
pet_name: "Mochi",
species: "Rabbit",
breed: "Mixed",
vaccination_history: [],
visit_details:
"Nail trimming and general health check. No issues.",
},
},
],
},
};
}
);
}We can now create a test for our code, making sure that the Elasticsearch part will always return the same results:
import test from 'ava';
test("performSemanticSearch must return formatted results correctly", async (t) => {
const indexName = "vet-visits";
const query = "Which pets had nail trimming?";
createSemanticSearchMock(query, indexName);
async function performSemanticSearch(esClient, q, indexName = "vet-visits") {
try {
const result = await esClient.search({
index: indexName,
body: {
query: {
semantic: {
field: "semantic_field",
query: q,
},
},
},
});
return {
success: true,
results: result.hits.hits,
};
} catch (error) {
if (error instanceof errors.TimeoutError) {
return {
success: false,
results: null,
error: error.body.error.reason,
};
}
return {
success: false,
results: null,
error: error.message,
};
}
}
const result = await performSemanticSearch(esClient, query, indexName);
t.true(result.success, "The search must be successful");
t.true(Array.isArray(result.results), "The results must be an array");
if (result.results.length > 0) {
t.true(
"_source" in result.results[0],
"Each result must have a _source property"
);
t.true(
"pet_name" in result.results[0]._source,
"Results must include the pet_name field"
);
t.true(
"visit_details" in result.results[0]._source,
"Results must include the visit_details field"
);
}
});Let’s run the tests.
npm run test
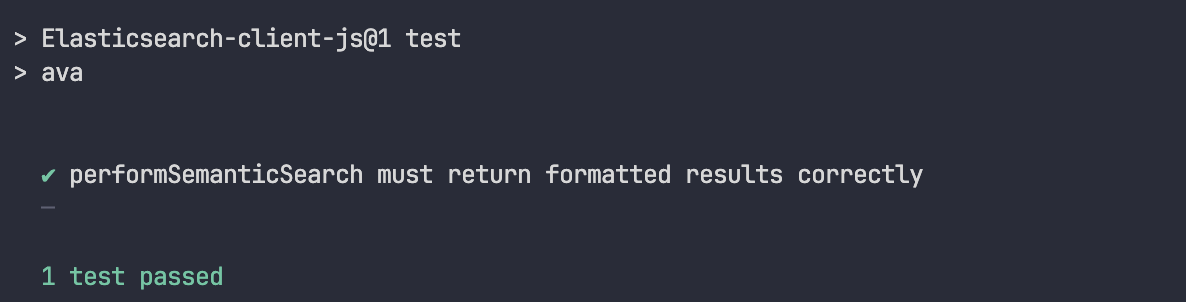
Done! From now on, we can test our app focusing 100 % on the code and not on external factors.
Serverless environments
Running the client on Elastic Serverless
We covered running Elasticsearch on Cloud or on-prem; however, the Node.js client also supports connections to Elastic Cloud Serverless.
Elastic Cloud Serverless allows you to create a project where you don’t need to worry about infrastructure since Elastic handles that internally, and you only need to worry about the data you want to index and how long you want to have access to it.
From a usage perspective, Serverless decouples compute from storage, providing autoscaling features for both search and indexing. This allows you to only grow the resources you actually need.
The client makes the following adaptations to connect to Serverless:
- Turns off sniffing and ignores any sniffing-related options
- Ignores all nodes passed in config except the first one, and ignores any node filtering and selecting options
- Enables compression and `TLSv1_2_method` (same as when configured for Elastic Cloud)
- Adds an `elastic-api-version` HTTP header to all requests
- Uses `CloudConnectionPool` by default instead of `WeightedConnectionPool`
- Turns off vendored `content-type` and `accept` headers in favor of standard MIME types
To connect your serverless project, you need to use the parameter serverMode: serverless.
const { Client } = require('@elastic/elasticsearch')
const client = new Client({
node: 'ELASTICSEARCH_ENDPOINT',
auth: { apiKey: 'ELASTICSEARCH_API_KEY' },
serverMode: "serverless",
});Running the client on function-as-a-service environment
In the example, we used a Node.js server, but you can also connect using a function-as-a-service environment with functions like AWS lambda, GCP Run, etc.
'use strict'
const { Client } = require('@elastic/elasticsearch')
const client = new Client({
// client initialisation
})
exports.handler = async function (event, context) {
// use the client
}Another example is to connect to services like Vercel, which is also serverless. You can check this complete example of how to do this, but the most relevant part of the search endpoint looks like this:
const response = await client.search(
{
index: INDEX,
// You could directly send from the browser
// the Elasticsearch's query DSL, but it will
// expose you to the risk that a malicious user
// could overload your cluster by crafting
// expensive queries.
query: {
match: { field: req.body.text },
},
},
{
headers: {
Authorization: `ApiKey ${token}`,
},
}
);This endpoint lives in the folder /api and is run from the server’s side so that the client only has control over the “text” parameter that corresponds to the search term.
The implication of using function-as-a-service is that, unlike a server running 24/7, functions only bring up the machine that runs the function, and once it is finished, the machine goes into rest mode to consume fewer resources.
This configuration can be convenient if the application does not get too many requests; otherwise, the costs can be high. You also need to consider the lifecycle of functions and the run times (which could only be seconds in some cases).
Conclusion
In this article, we learned how to handle errors, which is crucial in production environments. We also covered testing our application while mocking the Elasticsearch service, which provides reliable tests regardless of the cluster’s state and lets us focus on our code.
Finally, we demonstrated how to spin up a fully serverless stack by provisioning both Elastic Cloud Serverless and a Vercel application.
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content
July 1, 2025
Building an agentic RAG assistant with JavaScript, Mastra and Elasticsearch
Learn how to build AI agents in the JavaScript ecosystem

May 15, 2025
Elasticsearch in JavaScript the proper way, part I
Explaining how to create a production-ready Elasticsearch backend in JavaScript.
October 30, 2024
Export your Kibana Dev Console requests to Python and JavaScript Code
The Kibana Dev Console now offers the option to export requests to Python and JavaScript code that is ready to be integrated into your application.
October 16, 2024
Convert your Kibana Dev Console requests to Python and JavaScript Code
The Kibana Dev Console now offers the option to export requests to Python and JavaScript code that is ready to be integrated into your application.

June 4, 2024
Automatically updating your Elasticsearch index using Node.js and an Azure Function App
Learn how to update your Elasticsearch index automatically using Node.js and an Azure Function App. Follow these steps to ensure your index stays current.