In Elasticsearch 9.0, we introduced kNN vector rescoring for searches over fields using quantized vectors. While rescoring significantly improves recall, it can substantially increase latency in some situations. To understand why, we’ll examine what rescoring does and how Lucene and the operating system manage data on disk. We’ll also explain how enabling direct IO affects latency.
How vector rescoring works
An HNSW quantized vector index stores:
- The HNSW graph used to navigate the vector space
- The quantized vector data as bits
- The original raw vector data as 32-bit floats
When an approximate kNN search is performed, the HNSW graph is navigated to find the k-nearest vectors to the search vector, using the quantized vector data. If rescoring is enabled, the graph is oversampled by a factor of 3 by default, meaning that 3*k quantized vectors are searched for in the graph. The rescoring step then filters those 3*k oversampled quantized vectors down to the k nearest vectors using the unquantized raw vector data.
For each oversampled quantized vector, the original raw vector is retrieved and compared against the search vector to find the k nearest actual vectors, which are then returned from the query. This operation requires a random-access read into the raw vector data for every oversampled vector. And the raw vector data can be very large—often taking up 90-95% of the whole index, which can be many, many gigabytes or terabytes.
Why the page cache becomes a bottleneck
When the operating system reads data from disk—whether SSD, NVMe, or spinning disk—it caches a copy of the data read into RAM in case the data or data around it is needed again. This is usually done in 4KB pages; hence, it’s called the page cache. The OS uses any spare RAM in the system for the page cache:
$ free -m
total used free shared buff/cache available
Mem: 31536 14623 6771 1425 12021 1691In this example, the system has 32GB of RAM. 15GB is being used by running programs, and 12GB is being used by the page cache and other buffers.
So, in order to read data from disk, the OS first copies the relevant pages being requested from disk into memory. Then, that data is made available to the running program to access. If there is not enough free RAM to store the just-read page, an existing page is evicted from the page cache, and the new page replaces it.
But which page should be evicted? This is the age-old software engineering problem of cache invalidation. Modern OSs have gotten pretty good at deciding which pages are unlikely to be needed in the future, but they can’t (yet) predict the future. And the random-access pattern of vector rescoring is completely unpredictable, leaving the OS to essentially guess which page should be evicted.
This is a problem. The raw vector data for the oversampled vectors could be located anywhere in the index, and there could be a lot of pages to read depending on k. This might mean the OS needs to evict many pages during rescoring—including those which have the HNSW graph on them.
$ sar -B 1
pgpgin/s pgpgout/s fault/s majflt/s
112099.20 16493.60 11562.00 10761.60That’s a lot of page faults.
See, the OS doesn’t know what the pages are used for, or what’s on them. It also doesn’t know that the HNSW graph is used at the start of every vector query on that index. To the OS, these are just bytes on disk, along with information on previous access times. If the HNSW graph’s pages are evicted, then some or all of it needs to be reloaded for the next vector query. And disk access times are long, at least compared to memory access times. Tens of microseconds for NVMe, hundreds for SSDs, and many milliseconds for HDDs.
The effect of this is that when vector data gets large enough to no longer fit entirely in the page cache, the OS starts swapping out pages for every single query—causing query performance to plummet dramatically, as it constantly switches between the HNSW graph and the raw vectors. An extra few gigabytes of vector data can cause query latency to increase by 100x, and sometimes even more.
Direct IO to the rescue
So what’s to be done? The page cache is controlled by the OS, not Elasticsearch—so can we actually do anything about that? Fortunately, we can. Besides providing various hints to the OS about the purpose of the data read from disk (which the OS can use or not as it sees fit), we can also tell the OS to bypass the page cache completely, and just read directly from disk for every access. This is called ‘direct IO’.
Obviously, this is much slower than reading from an already-cached page in RAM, but it stops existing pages from being evicted from the page cache to store the new page. Importantly, this allows the OS to leave the HNSW graph in memory, where it belongs.
The effect of direct IO on search latency in low-memory scenarios is dramatic (note the logarithmic scale):
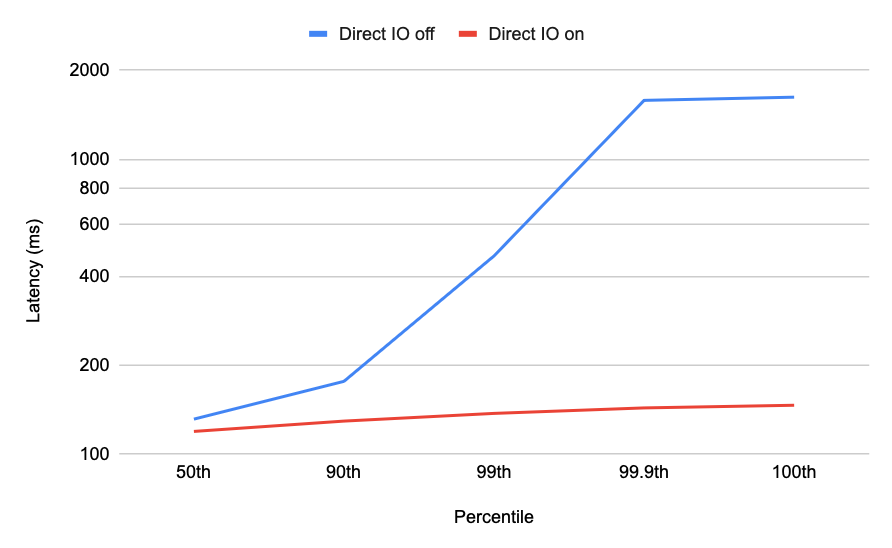
However, it does come at a cost. Because direct IO forces the page cache to be bypassed, turning on direct IO when there is enough memory to store all the vector data causes a huge slowdown:
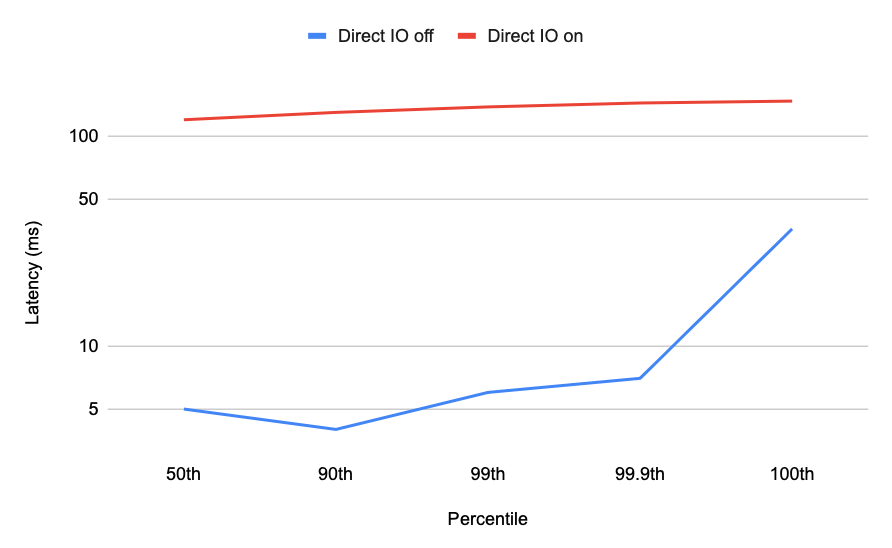
Ideally, we would detect when vector data is being swapped in and out of the page cache, but that’s tricky with the tools available within the JVM. We’re working on it, but we’re not there yet.
When (and when not) to enable direct IO?
As you can see, turning on direct IO when your vector data is too large for RAM dramatically reduces the high latencies of kNN vector searches in such situations. But, turning on direct IO when you do have enough memory causes a large slowdown.
Starting in Elasticsearch 9.1, you can use direct IO for vector rescoring on bbq_hnsw indices. For now, it’s turned off by default, since it can cause a performance drop when enough memory is available. But if you are seeing very large latencies in your vector searches, try adding the JVM option -Dvector.rescoring.directio=true to enable direct IO for all rescoring on bbq_hnsw indices.
We’re looking into different ways to expose that option in the future, and to evaluate the various performance differentials for future Elasticsearch versions. Nonetheless, if you find that it improves your vector search performance, do let us know!
Note that there is a known issue for Elasticsearch 9.1.0 where direct IO is turned on by default. This will be fixed in Elasticsearch 9.1.1. We’re continuing to evaluate the uses of direct IO and how this access method might be used in the future.
Ready to try this out on your own? Start a free trial.
Elasticsearch has integrations for tools from LangChain, Cohere and more. Join our advanced semantic search webinar to build your next GenAI app!
Related content

October 23, 2025
Low-memory benchmarking in DiskBBQ and HNSW BBQ
Benchmarking Elasticsearch latency, indexing speed, and memory usage for DiskBBQ and HNSW BBQ in low-memory environments.

October 22, 2025
Deploying a multilingual embedding model in Elasticsearch
Learn how to deploy an e5 multilingual embedding model for vector search and cross-lingual retrieval in Elasticsearch.

October 23, 2025
Introducing a new vector storage format: DiskBBQ
Introducing DiskBBQ, an alternative to HNSW, and exploring when and why to use it.
September 19, 2025
Using TwelveLabs’ Marengo video embedding model with Amazon Bedrock and Elasticsearch
Creating a small app to search video embeddings from TwelveLabs' Marengo model.

September 15, 2025
Balancing the scales: Making reciprocal rank fusion (RRF) smarter with weights
Exploring weighted reciprocal rank fusion (RRF) in Elasticsearch and how it works through practical examples.