Have you ever wanted to search your photo album by meaning? Try queries like “show me my pictures where I’m wearing a blue jacket and sitting on a bench,” “show me pictures of Mount Everest,” or “sake and sushi.” Grab a cup of coffee (or your favorite drink) and continue reading. In this blog, we show you how to build a multimodal hybrid search application. Multimodal means the app can understand and search across different kinds of input—text, images, and audio—not just words. Hybrid means it combines techniques like keyword matching, kNN vector search, and geofencing to deliver sharper results.
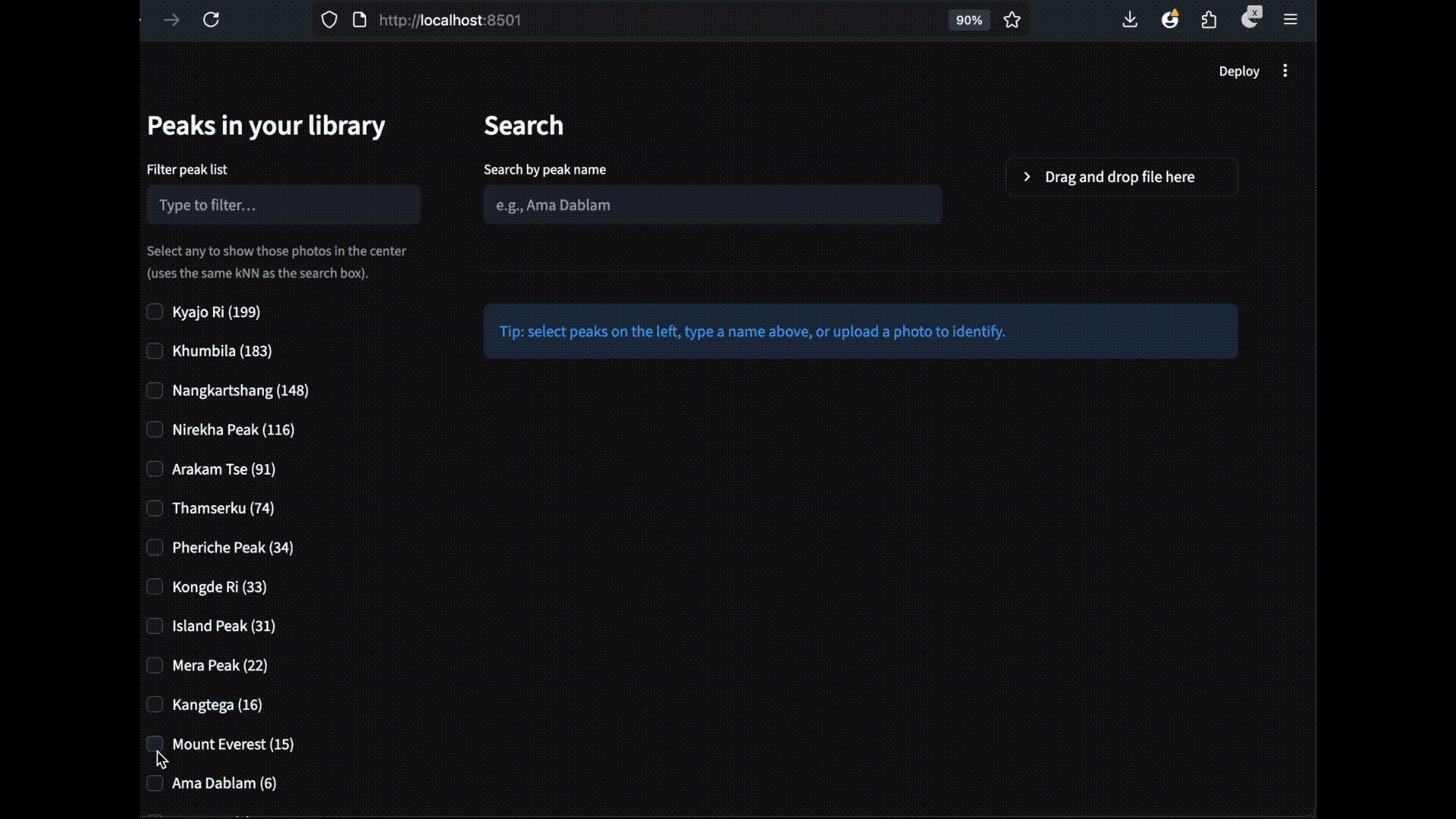
To achieve this, we use Google’s SigLIP-2 to generate vector embeddings for both images and text, and store them in the Elasticsearch vector database. At query time, we convert the search input, text or image, into embeddings and run fast kNN vector searches to retrieve results. This setup enables efficient text-to-image and image-to-image search. A Streamlit UI brings this project to life by providing us a frontend to not only do text-based search to find and view the matching photos from the album, but also allows us to identify the mountain peak from the uploaded image and view other photos of that mountain in the photo album.
We also cover the steps we took to improve search accuracy, along with practical tips and tricks. For further exploration, we provide a GitHub repository and a Colab notebook.
How it started
This blog post was inspired by a 10-year-old who asked me to show them all the pictures of Mount Ama Dablam from my Everest Base Camp trek. As we sifted through the photo album, I was also asked to identify several other mountain peaks, some of which I couldn't name.
That gave me an idea that this can be a fun computer vision project. What we wanted to achieve:
- find pictures of a mountain peak by name
- guess the mountain peak name from an image and also find similar peaks in the photo album
- get concept queries to work (person, river, prayer flags, etc)

Mount Ama Dablam
Assembling the dream team: SigLIP-2, Elasticsearch & Streamlit
It quickly became clear that for this to work, we’d need to turn both the text (“Ama Dablam”) and the images (photos from my album) into vectors that can be meaningfully compared, i.e., in the same vector space. Once we do that, search is just “finding the nearest neighbors”.

To generate image embeddings, we use a multilingual vision–language encoder, so a photo of a mountain and a phrase like “Ama Dablam” land in the same vector space.
SigLIP-2, recently released by Google, fits well here. It can generate embeddings without task-specific training (a zero-shot setting) and works nicely for our use case: unlabeled photos and peaks with different names and languages. Because it’s trained for text ↔ image matching, a mountain picture from the trek and a short text prompt end up close as embeddings, even when the query language or spelling varies.
SigLIP-2 offers a strong quality-to-speed balance, supports multiple input resolutions, and runs on both CPU and GPU. SigLIP-2 is designed to be more robust to outdoor photos compared to previous models like the original CLIP. During our tests, SigLIP-2 consistently generated reliable results. It is also very well supported, making it the obvious choice for this project.
Next, we need a vector database to store the embeddings and power search. It should support not only cosine kNN search over image embeddings, but also apply geo-fence and text filters in a single query. Elasticsearch fits well here: it handles vectors (HNSW kNN on dense_vector fields) very well, supports hybrid search that combines text, vectors, and geo queries, and offers filtering and sorting out of the box. It also scales horizontally, making it easy to grow from a handful of photos to thousands. The official Elasticsearch Python Client keeps plumbing simple, and it integrates cleanly with the project.Lastly, we need a lightweight frontend where we can enter search queries and view results. For a quick, Python-based demo, Streamlit is a great fit. It provides the primitives we need—file upload, a responsive image grid, and drop-down menus for sorting and geofencing. It’s easy to clone and run locally, and it also works in a Colab notebook.
Implementation
Elasticsearch indexing design and indexing strategy
We’ll be using two indices for this project: peaks_catalog and photos.
Peaks_catalog index
This index serves as a compact catalog of prominent mountain peaks that are visible during the Everest Base Camp Trek. Each document in this index corresponds to a single mountain peak, like Mount Everest. For each mountain peak document, we store names/aliases, optional latitude-longitude coordinates, and a single prototype vector built by blending SigLIP-2 text prompts (+ optional reference images).
Index mapping:
| Field | Type | Example | Purpose/Notes | Vector/Indexing |
|---|---|---|---|---|
| id | keyword | ama-dablam | Stable slug/id | — |
| names | text + keyword subfield | ["Ama Dablam","Amadablam"] | Aliases / multilingual names; names.raw for exact filters | — |
| latlon | geo_point | {"lat":27.8617,"lon":86.8614} | Peak GPS coordinates as a latitude/ longitude combination (optional) | — |
| elev_m | integer | 6812 | Elevation (optional) | — |
| text_embed | dense_vector | 768 | Blended prototype (prompts and optionally 1–3 reference images) for this peak | index:true, similarity:"cosine", index_options:{type:"hnsw", m:16, ef_construction:128} |
This index is primarily used for image-to-image searches, such as identifying mountain peaks from images. We also use this index to enhance text-to-image search results.
In summary, the peaks_catalog transforms the question "What mountain is this?" into a focused nearest-neighbor problem, effectively separating conceptual understanding from the complexities of image data.
Indexing strategy for peaks_catalog index: We start by creating a list of the most prominent peaks visible during the EBC trek. For each peak, we store its geo location, name, synonyms, and elevation in a yaml file. The next step is to generate the embedding for each peak and store it in text_embed field. In order to generate a robust embeddings, we use the following technique:
- Create a text prototype using:
- names of the peaks
- prompt ensemble (using multiple different prompts to try to answer the same question), for example:
- “a natural photo of the mountain peak {name} in the Himalayas, Nepal”
- “{name} landmark peak in the Khumbu region, alpine landscape”
- “{name} mountain summit, snow, rocky ridgeline”
- optional anti-concept (telling SigLIP-2 what not to match on): subtract a small vector for “painting, illustration, poster, map, logo” so we bias toward real photos.
- Optionally create an image prototype if reference images of the peak are provided.
We then blend the text and image prototype to generate the final embedding. Finally, the document is indexed with all the required fields:
def l2norm(v: np.ndarray) -> np.ndarray:
return v / (np.linalg.norm(v) + 1e-12)
def compute_blended_peak_vec(
emb: Siglip2,
names: List[str],
peak_id: str,
peaks_images_root: str,
alpha_text: float = 0.5,
max_images: int = 3,
) -> Tuple[np.ndarray, int, int, List[str]]:
"""
Build blended vector for a single peak.
Returns:
vec : np.ndarray (L2-normalized)
found_count : number of reference images discovered
used_count : number of references used (<= max_images)
used_filenames: list of filenames used (for logging)
"""
# 1) TEXT vector
tv = embed_text_blend(emb, names)
# 2) IMAGE refs: prefer folder by id; fallback to slug of the primary name
root = Path(peaks_images_root)
candidates = [root / peak_id]
if names:
candidates.append(root / slugify(names[0]))
all_refs: List[Path] = []
for c in candidates:
if c.exists() and c.is_dir():
all_refs = list_ref_images(c)
if all_refs:
break
found = len(all_refs)
used_list = all_refs[:max_images] if (max_images and found > max_images) else all_refs
used = len(used_list)
img_v = embed_image_mean(emb, used_list) if used_list else None
# 3) Blend TEXT and IMAGE vectors, clamp alpha to [0,1]
a = max(0.0, min(1.0, float(alpha_text)))
vec = l2norm(tv if img_v is None else (a * tv + (1.0 - a) * img_v)).astype("float32")
return vec, found, used, [p.name for p in used_list]Sample document from peaks_catalog index:
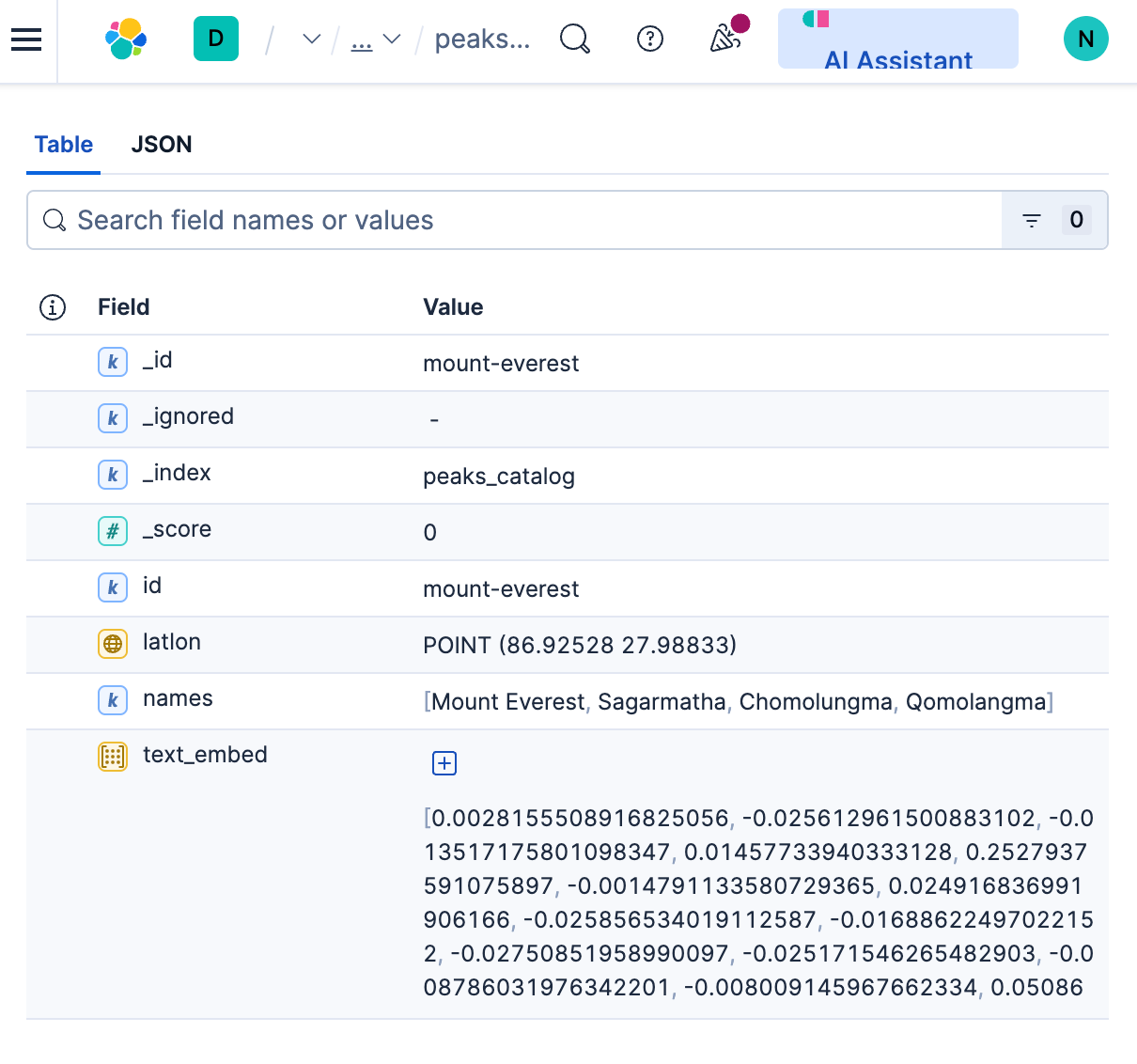
Photos index
This primary index stores detailed information about all photos in the album. Each document represents a single photo, containing the following information:
- Relative path to the photo in the photo album. This can be used to view the matching image or load the image in the search UI.
- GPS and time information of the picture.
- Dense vector for image encoding generated by SigLIP-2.
predicted_peaksthat lets us filter by peak name.
Index mapping
| Field | Type | Example | Purpose/Notes | Vector / Indexing |
|---|---|---|---|---|
| path | keyword | data/images/IMG_1234.HEIC | How UI opens thumbnail/full image | — |
| clip_image | dense_vector | 768 | SigLIP-2 image embedding | index:true, similarity:"cosine", index_options:{type:"hnsw", m:16, ef_construction:128} |
| predicted_peaks | keyword | ["ama-dablam","pumori"] | Top-K guesses at index time (cheap UX filter / facet) | — |
| gps | geo_point | {"lat":27.96,"lon":86.83} | enables geo filters | — |
| shot_time | date | 2023-10-18T09:41:00Z | capture time: sort/filter | — |
Indexing strategy for photos index: For each photo in the album, we do the following:
Extract image shot_time and gps information from image metadata.
- SigLIP-2 image embedding: pass the image through the model and L2-normalize the vector. Store the embedding in
clip_imagefield. - Predict the peaks and store them in the
predicted_peaksfield. To do this, we first take the photo’s image vector generated in the previous step, then run a quick kNN search against the text_embed field in thepeaks_catalogindex. We keep the top 3-4 peaks and ignore the rest. - We calculate the
_idfield by doing a hash on the image name and path. This makes sure that we do not end up with duplicates after multiple runs.
Once we have determined all the fields for the photo, the photo documents are indexed in batches using bulk indexing:
def bulk_index_photos(
es: Elasticsearch,
images_root: str,
photos_index: str = "photos",
peaks_index: str = "peaks_catalog",
topk_predicted: int = 5,
batch_size: int = 200,
refresh: str = "false",
) -> None:
"""Walk a folder of images, embed + enrich, and bulk index to Elasticsearch."""
root = Path(images_root)
if not root.exists():
raise SystemExit(f"Images root not found: {images_root}")
emb = Siglip2()
batch: List[Dict[str, Any]] = []
n_indexed = 0
for p in iter_images(root):
rel = relpath_within(root, p)
_id = id_for_path(rel)
# 1) Image embedding (and reuse it for predicted_peaks)
try:
with Image.open(p) as im:
ivec = emb.image_vec(im.convert("RGB")).astype("float32")
except (UnidentifiedImageError, OSError) as e:
print(f"[skip] {rel} — cannot embed: {e}")
continue
# 2) Predict top-k peak names
try:
top_names = predict_peaks(es, ivec.tolist(), peaks_index=peaks_index, k=topk_predicted)
except Exception as e:
print(f"[warn] predict_peaks failed for {rel}: {e}")
top_names = []
# 3) EXIF enrichment (safe)
gps = get_gps_decimal(str(p))
shot = get_shot_time(str(p))
# 4) Build doc and stage for bulk
doc = {"path": rel, "clip_image": ivec.tolist(), "predicted_peaks": top_names}
if gps:
doc["gps"] = gps
if shot:
doc["shot_time"] = shot
batch.append(
{"_op_type": "index", "_index": photos_index, "_id": _id, "_source": doc}
)
# 5) Periodic flush
if len(batch) >= batch_size:
helpers.bulk(es, batch, refresh=refresh)
n_indexed += len(batch)
print(f"[photos] indexed {n_indexed} (last: {rel})")
batch.clear()
# Final flush
if batch:
helpers.bulk(es, batch, refresh=refresh)
n_indexed += len(batch)
print(f"[photos] indexed {n_indexed} total.")
print("[done] photos indexing")Sample document from the photos index:
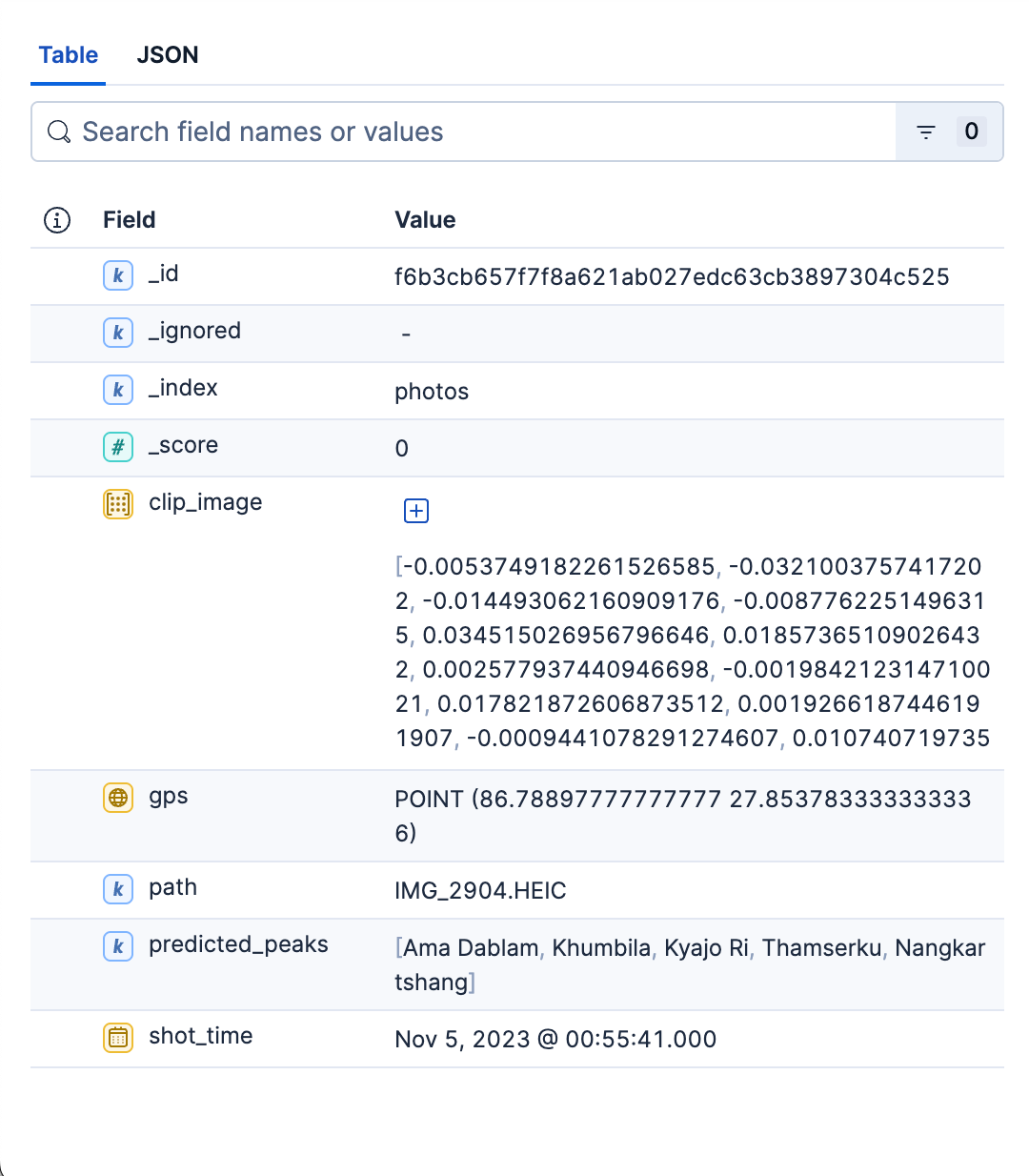
In summary, the photos’ index is the fast, filterable, kNN-ready store of all the photos in the album. Its mapping is minimal on purpose—just enough structure to retrieve quickly, display cleanly, and slice results by space and time. This index serves both search use cases. Python script to create both indices can be found here.
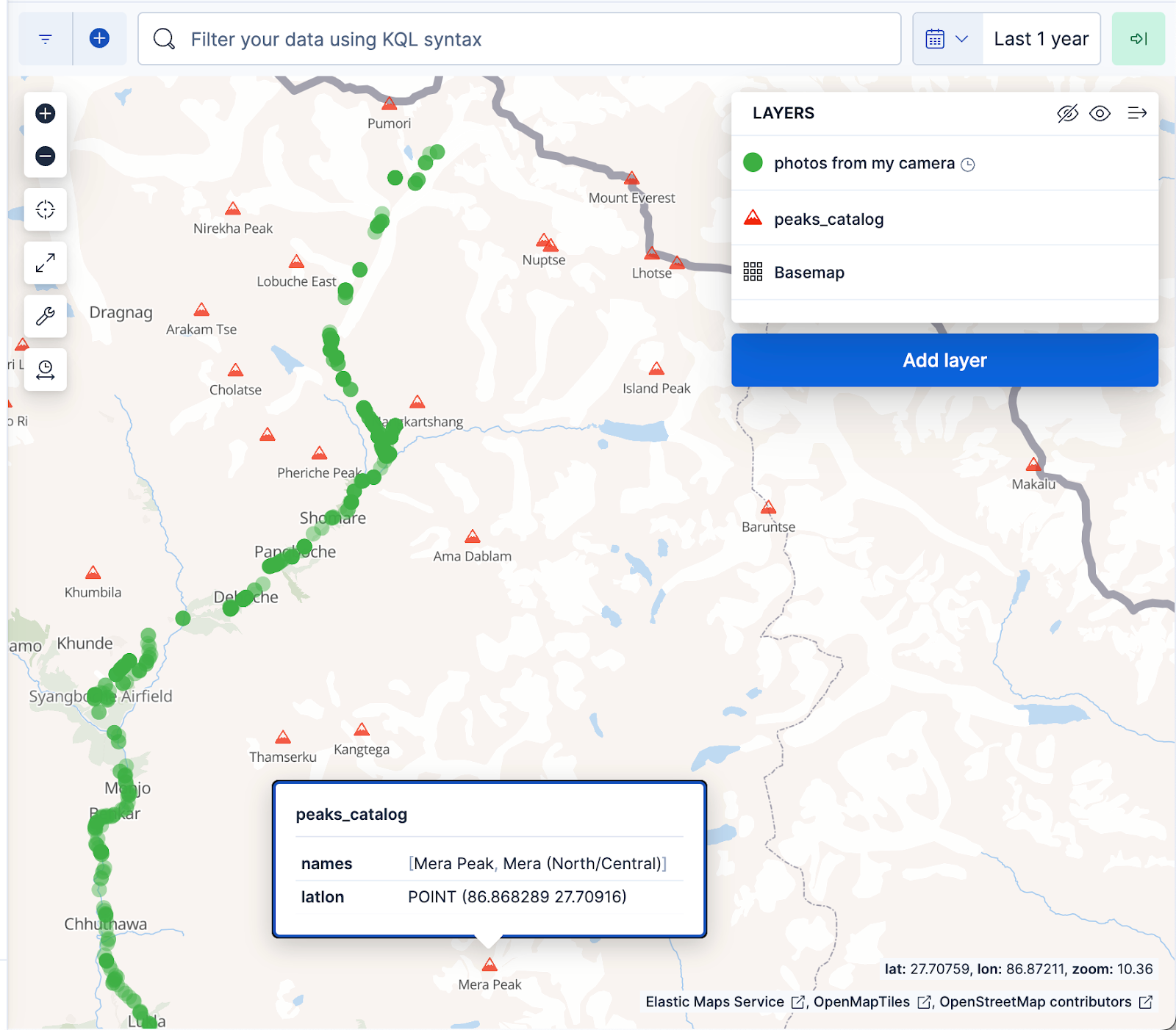
The Kibana maps visualization below displays documents from the photo album as green dots and mountain peaks from the peaks_catalog index as red triangles, with the green dots aligning well with the Everest Base Camp trek trail.
Search use cases
Search by name (text-to-image): This feature enables users to locate photos of mountain peaks (and even abstract concepts like “prayer flags”) using text queries. To achieve this, the text input is converted into a text vector using SigLIP-2. For robust text vector generation, we employ the same strategy used for creating text embeddings in the peaks_catalog index: combining text input with a small prompt ensemble, subtracting a minor anti-concept vector, and applying L2-normalization to produce the final query vector. A kNN query is then executed on the photos.clip_image field to retrieve the top matching peaks, based on cosine similarity to find the closest images. Optionally, search results can be made more relevant by applying geo and date filters, and/or a photos.predicted_peaks term filter as part of the query (see query examples below). This helps exclude look-alike peaks that aren’t actually in view on the trek.
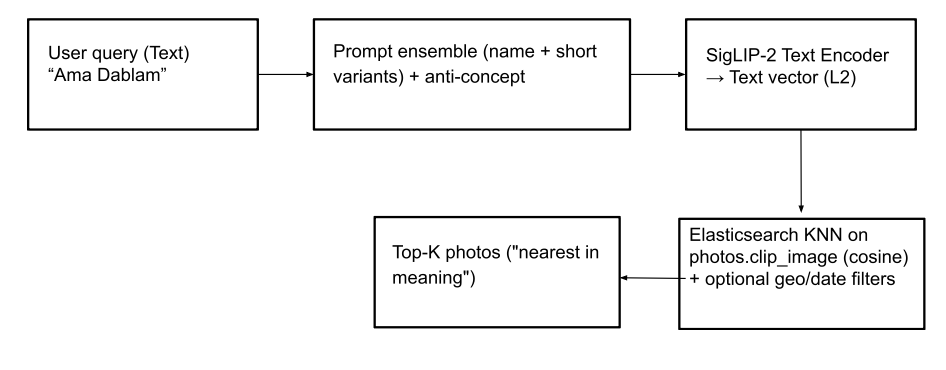
Elasticsearch query with geo filter:
POST photos/_search
{
"knn": {
"field": "clip_image",
"query_vector": [ ... ],
"k": 60,
"num_candidates": 2000
},
"query": {
"bool": {
"filter": [
{ "geo_bounding_box": { "gps": { "top_left": "...", "bottom_right": "..." } } }
]
}
},
"_source": ["path","predicted_peaks","gps","shot_time"]
}
Response (first two documents):
{
"hits": {
"total": {
"value": 56,
"relation": "eq"
},
"max_score": 0.5779596,
"hits": [
{
"_index": "photos",
"_id": "d01da3a1141981486c3493f6053c79e92a788463",
"_score": 0.5779596,
"_source": {
"path": "IMG_2738.HEIC",
"predicted_peaks": [
"Pumori",
"Kyajo Ri",
"Khumbila",
"Nangkartshang",
"Kongde Ri"
],
"gps": {
"lat": 27.97116388888889,
"lon": 86.82331111111111
},
"shot_time": "2023-11-03T08:07:13"
}
},
{
"_index": "photos",
"_id": "c79d251f07adc5efaedc53561110a7fd78e23914",
"_score": 0.5766071,
"_source": {
"path": "IMG_2761.HEIC",
"predicted_peaks": [
"Kyajo Ri",
"Makalu",
"Baruntse",
"Cho Oyu",
"Khumbila"
],
"gps": {
"lat": 27.975558333333332,
"lon": 86.82515
},
"shot_time": "2023-11-03T08:51:08"
}
}
}Search by image (image-to-image): This feature allows us to identify a mountain in a picture and find other images of that same mountain within the photo album. When an image is uploaded, it's processed by the SigLIP-2 image encoder to generate an image vector. A kNN search is then performed on the peaks_catalog.text_embed field to identify the best-matching peak names. Subsequently, a text vector is generated from these matching peak names, and another kNN search is conducted on the photos index to locate corresponding pictures.
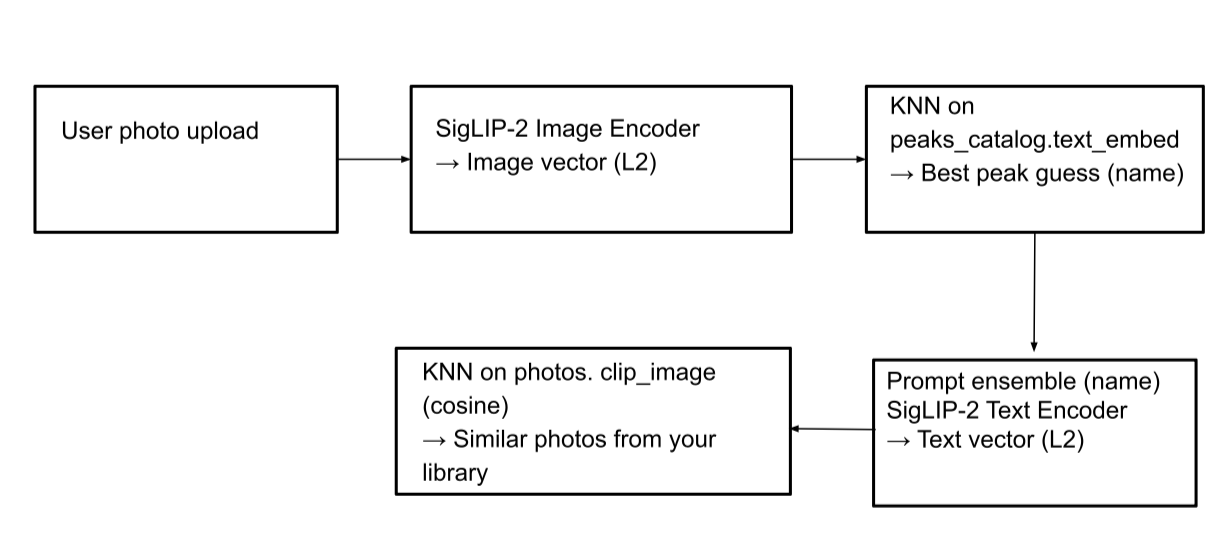
Elasticsearch query:
Step 1: Find the matching peak names
GET peaks_catalog/_search
{
"knn": {
"field": "text_embed",
"query_vector": [...image-vector... ],
"k": 3,
"num_candidates": 500
},
"_source": [
"id",
"names",
"latlon",
"text_embed"
]
}
Response (first two documents):
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 0.58039916,
"hits": [
{
"_index": "peaks_catalog",
"_id": "pumori",
"_score": 0.58039916,
"_source": {
"id": "pumori",
"names": [
"Pumori",
"Pumo Ri"
],
"latlon": {
"lat": 28.01472,
"lon": 86.82806
},
"text_embed": [
... embeddings...
]
}
},
{
"_index": "peaks_catalog",
"_id": "kyajo-ri",
"_score": 0.57942784,
"_source": {
"id": "kyajo-ri",
"names": [
"Kyajo Ri",
"Kyazo Ri"
],
"latlon": {
"lat": 27.909167,
"lon": 86.673611
},
"text_embed": [
... embeddings...
]
}
}
]
}
}Step 2: Perform a search on the photos index to find the matching pictures (same query as shown in text-to-image search use case):
POST photos/_search
{
"knn": {
"field": "clip_image",
"query_vector": [ ...image-vector... ],
"k": 30,
"num_candidates": 2000
},
"_source": [
"path",
"gps",
"shot_time",
"predicted_peaks",
"clip_image"
],
"query": {
"bool": {
"filter": [
{
"term": {
"predicted_peaks": "Pumori"
}
}
]
}
}
}
Response (first two documents):
{
"hits": {
"total": {
"value": 56,
"relation": "eq"
},
"max_score": 0.5779596,
"hits": [
{
"_index": "photos",
"_id": "d01da3a1141981486c3493f6053c79e92a788463",
"_score": 0.5779596,
"_source": {
"path": "IMG_2738.HEIC",
"predicted_peaks": [
"Pumori",
"Kyajo Ri",
"Khumbila",
"Nangkartshang",
"Kongde Ri"
],
"gps": {
"lat": 27.97116388888889,
"lon": 86.82331111111111
},
"shot_time": "2023-11-03T08:07:13"
}
},
{
"_index": "photos",
"_id": "c79d251f07adc5efaedc53561110a7fd78e23914",
"_score": 0.5766071,
"_source": {
"path": "IMG_2761.HEIC",
"predicted_peaks": [
"Kyajo Ri",
"Makalu",
"Baruntse",
"Cho Oyu",
"Khumbila"
],
"gps": {
"lat": 27.975558333333332,
"lon": 86.82515
},
"shot_time": "2023-11-03T08:51:08"
}
}
}Streamlit UI
To bring everything together, we created a simple Streamlit UI that allows us to perform both search use cases. The left rail displays a scrollable list of peaks (aggregated from photos.predicted_peaks) with checkboxes and a mini-map/geo filter. At the top, there is a search by name box and an identify from photo upload button. The center pane features a responsive thumbnail grid showing kNN scores, predicted-peak badges, and capture times. Each image includes a view image button for full-resolution previews.
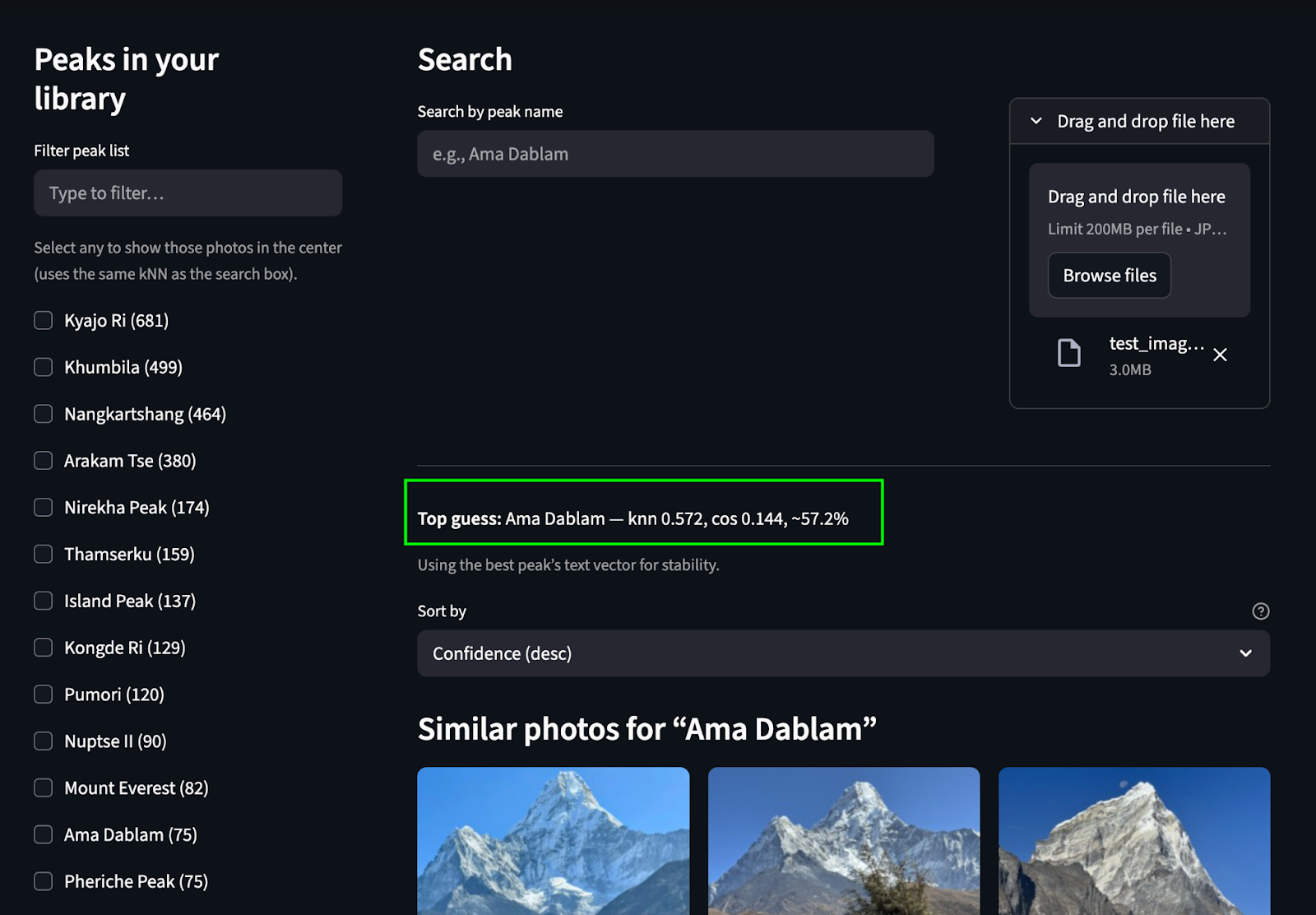
Search by uploading an image: We predict the peak and find matching peaks from the photo album.
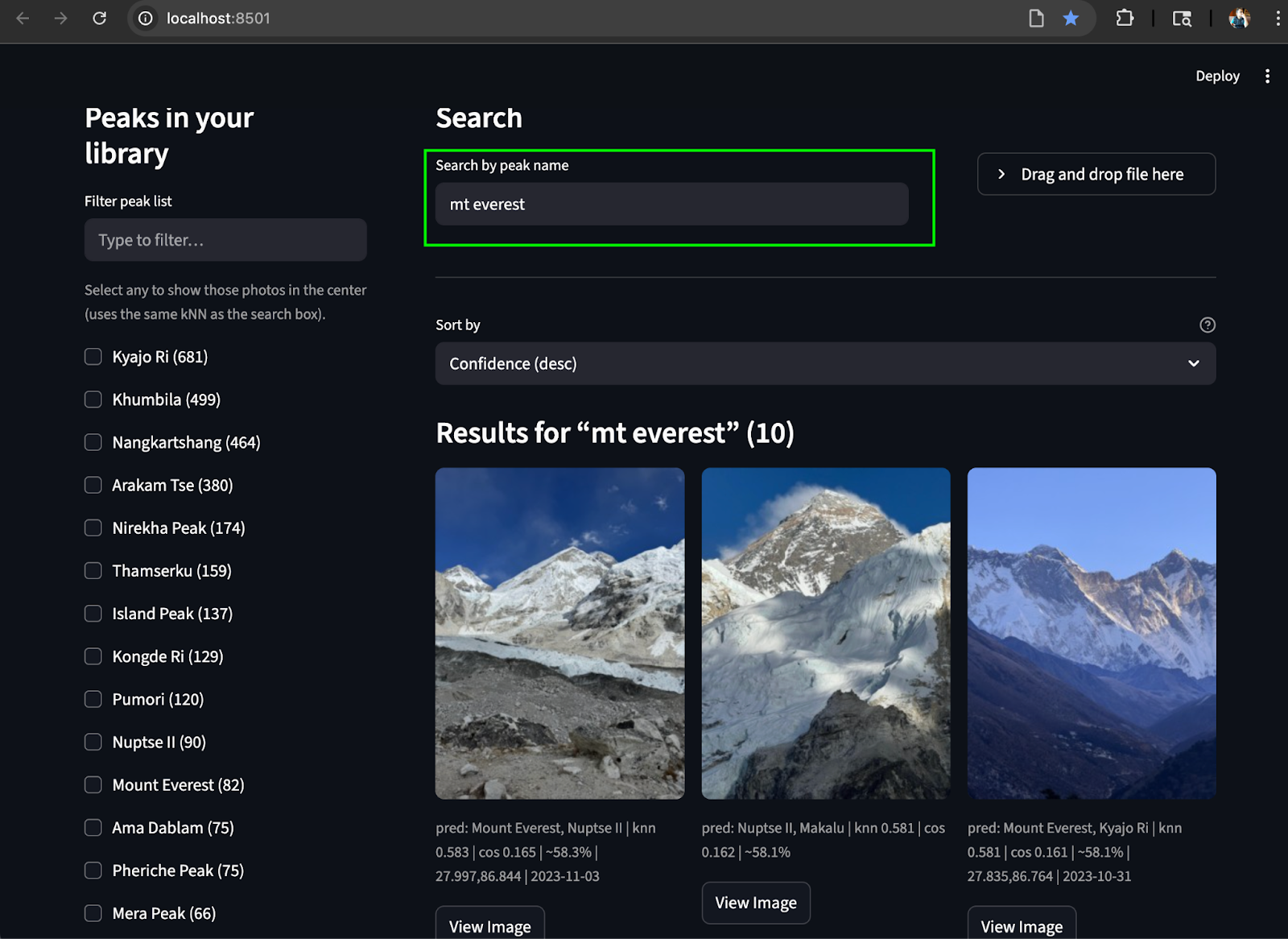
Search by text: Find the matching peaks in the album from text
Conclusion
What started as can we just see the Ama Dablam pictures? turned into a small, working multimodal search system. We took raw trek photos, turned them into SigLIP-2 embeddings, and used Elasticsearch to do fast kNN over vectors, plus simple geo/time filters to surface the right images by meaning. Along the way, we separated concerns with two indices: a tiny peaks_catalog of blended prototypes (for identification) and a scalable photos index of image vectors and EXIF (for retrieval). It’s practical, reproducible, and easy to extend.
If you want to tune it, there are a few settings to play with:
- Query time settings:
k(how many neighbors you want back) andnum_candidates(how wide to search before final scoring). These settings are discussed in the blog here. - Index time settings:
m(graph connectivity) andef_construction(build-time accuracy vs. memory). For queries, experiment withef_searchtoo—higher usually means better recall with some latency tradeoff. Refer to this blog for more details about these settings.
Looking ahead, native models/rerankers for multimodal and multilingual search are soon landing in the Elastic ecosystem, which should make image/text retrieval and hybrid ranking even stronger out of the box. ir.elastic.co+1
If you’d like to try this yourself:
- GitHub repo: https://github.com/navneet83/multimodal-mountain-peak-search
- Colab quickstart: https://colab.research.google.com/github/navneet83/multimodal-mountain-peak-search/blob/main/notebooks/multimodal_mountain_peak_search.ipynb
With this, our journey has come to an end, and it's time to fly back. Hope this was helpful and if you break it (or improve it), I’d love to hear what you changed.

Ready to try this out on your own? Start a free trial.
Elasticsearch has integrations for tools from LangChain, Cohere and more. Join our advanced semantic search webinar to build your next GenAI app!
Related content

November 3, 2025
Improving multilingual embedding model relevancy with hybrid search reranking
Learn how to improve the relevancy of E5 multilingual embedding model search results using Cohere's reranker and hybrid search in Elasticsearch.

October 23, 2025
Low-memory benchmarking in DiskBBQ and HNSW BBQ
Benchmarking Elasticsearch latency, indexing speed, and memory usage for DiskBBQ and HNSW BBQ in low-memory environments.

October 22, 2025
Deploying a multilingual embedding model in Elasticsearch
Learn how to deploy an e5 multilingual embedding model for vector search and cross-lingual retrieval in Elasticsearch.

October 23, 2025
Introducing a new vector storage format: DiskBBQ
Introducing DiskBBQ, an alternative to HNSW, and exploring when and why to use it.
September 19, 2025
Using TwelveLabs’ Marengo video embedding model with Amazon Bedrock and Elasticsearch
Creating a small app to search video embeddings from TwelveLabs' Marengo model.