Elastic connectors make it easy to index and combine data from different sources to run unified searches. With the addition of Playground you can set up a knowledge base that you can chat with and ask questions.
Connectors are a type of Elastic integration that are helpful for syncing data from different sources to an Elasticsearch index.
In this article, we'll see how to index a Confluence Wiki using the Elastic connector, configure an index to run semantic queries, and then use Playground to chat with your data.
Steps
Configure the connector
In our example, our Wiki works as a centralized repository for a hospital and contains info on:
- Doctors' profiles: speciality, availability, contact info.
- Patients' files: Medical records and other relevant data.
- Hospital guidelines: Policies, emergency protocols and instructions for staff.
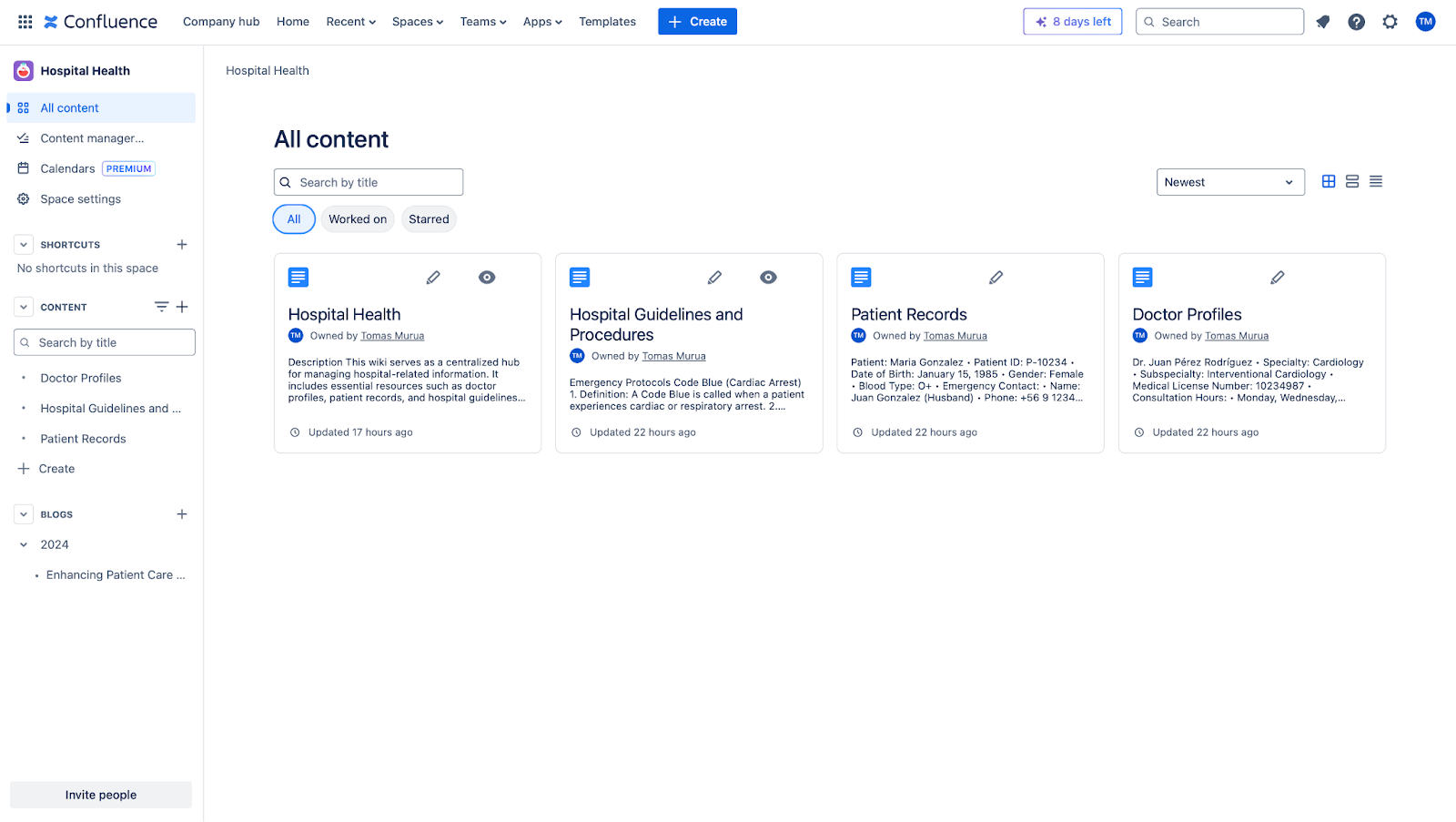
We'll index the content from our Wiki using the Elasticsearch-managed Confluence connector.
The first step is to get your Atlassian API Key:
Configuring the Confluence native connector
You can follow the steps here to guide you through the configuration:
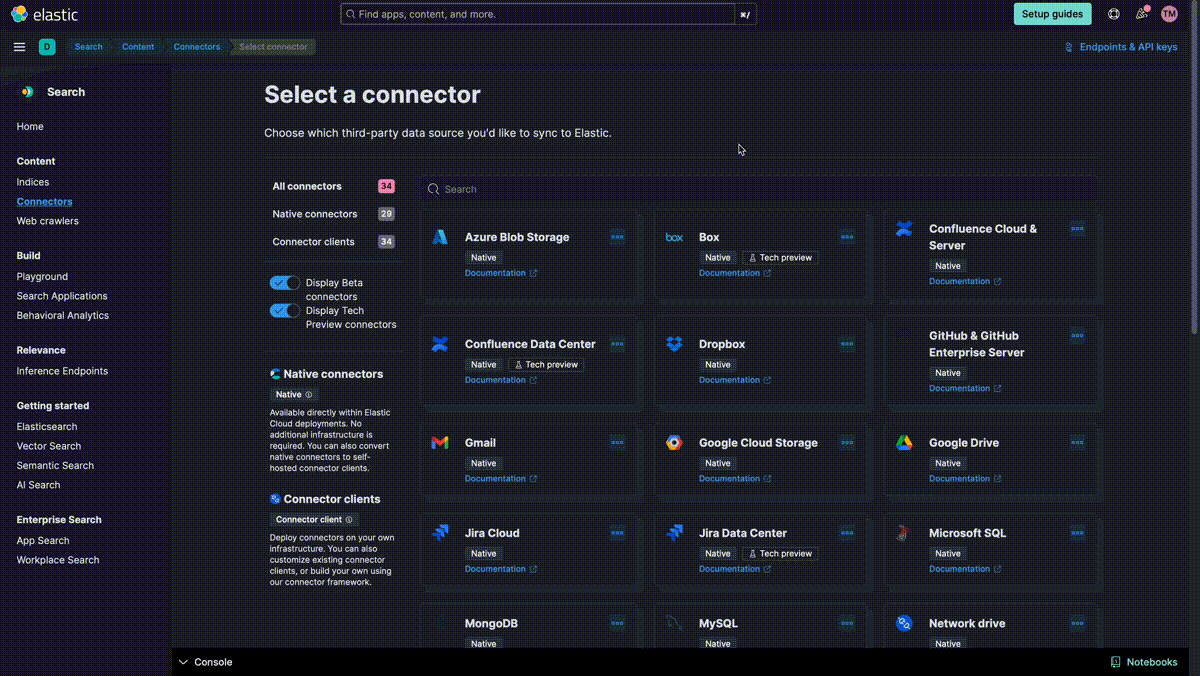
- Access your Kibana instance and go to Search > Connectors
- Click on add a connector and select Confluence from the list.
- Name the new connector "hospital".
- Then click on the create new Index button.
- Click on edit configurations and, for this example, we need to modify the data source for "confluence cloud". The required fields are:
- Confluence Cloud account email
- API Key
- Confluence URL label
- Save the configuration and go to the next step.
By default, the connector will index:
- Pages
- Spaces
- Blog Posts
- Attachments
To make sure to only index the wiki, you need to use an advanced filter rule to include only pages inside the space named "Hospital Health" identified as "HH".
[
{
"query": "type = 'page' AND space.key = 'HH'"
}
]You can check out additional examples here.
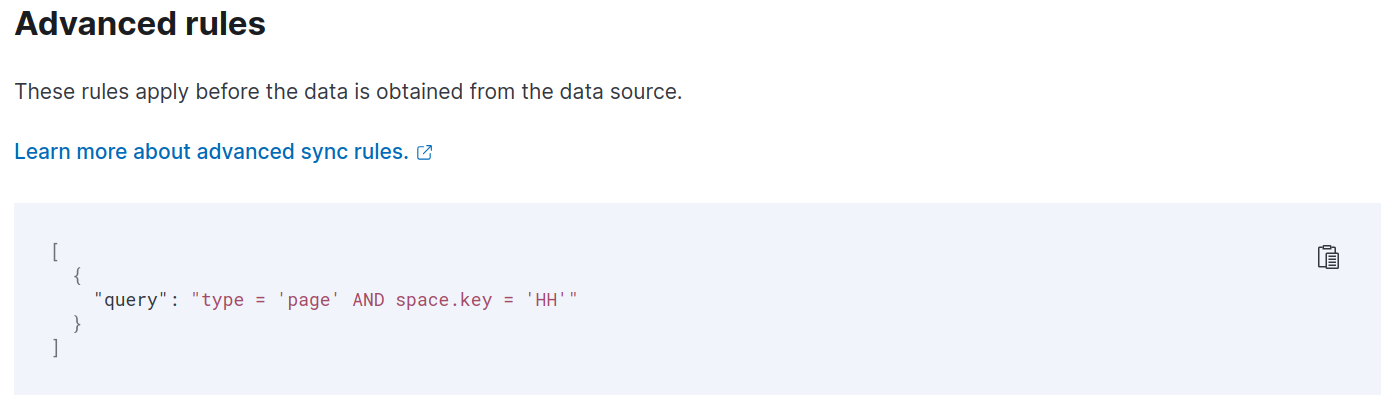
Now, let's run a Full Content Sync to index our wiki.
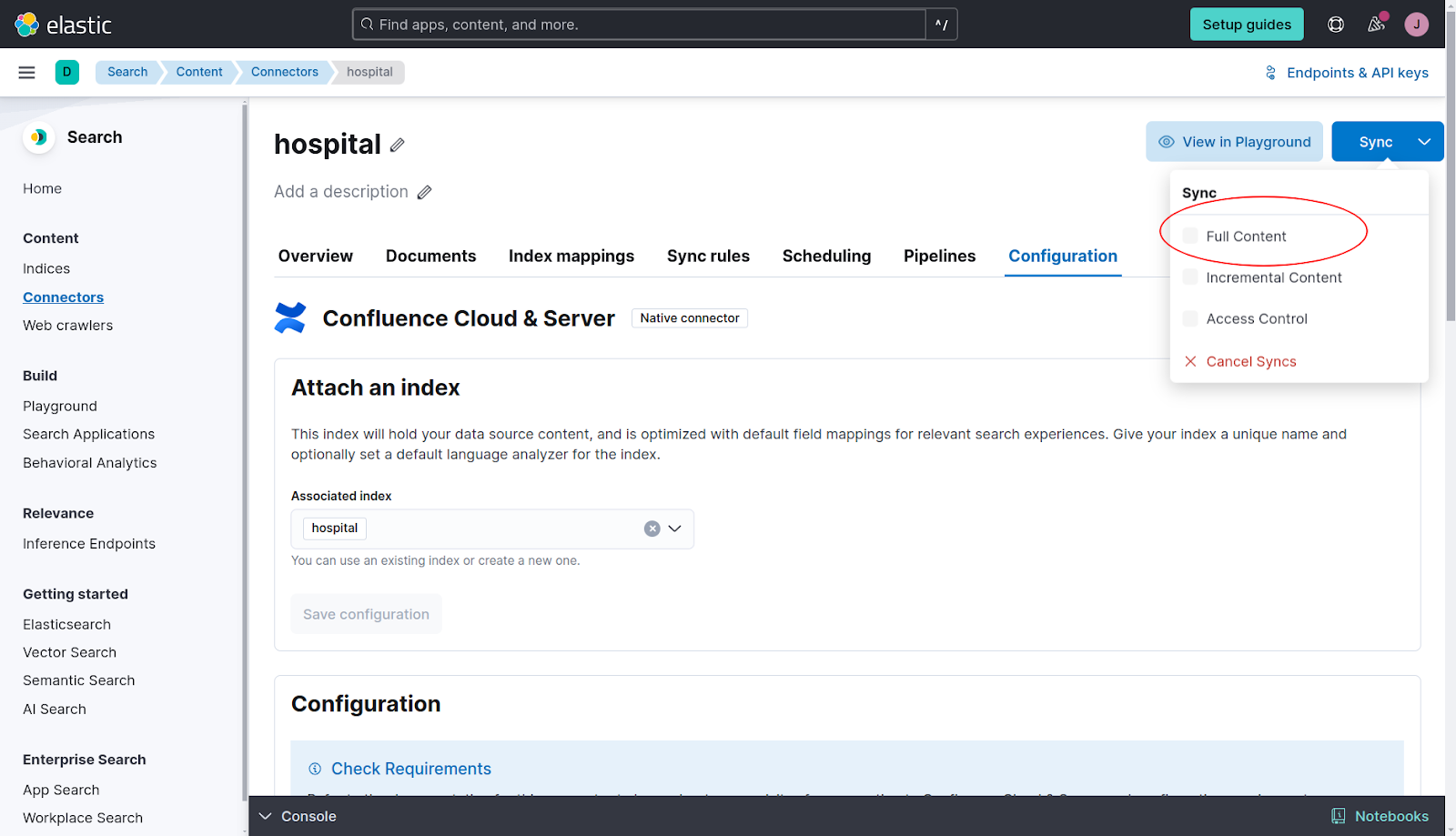
Once completed, we can check the indexed documents on the tab "Documents".
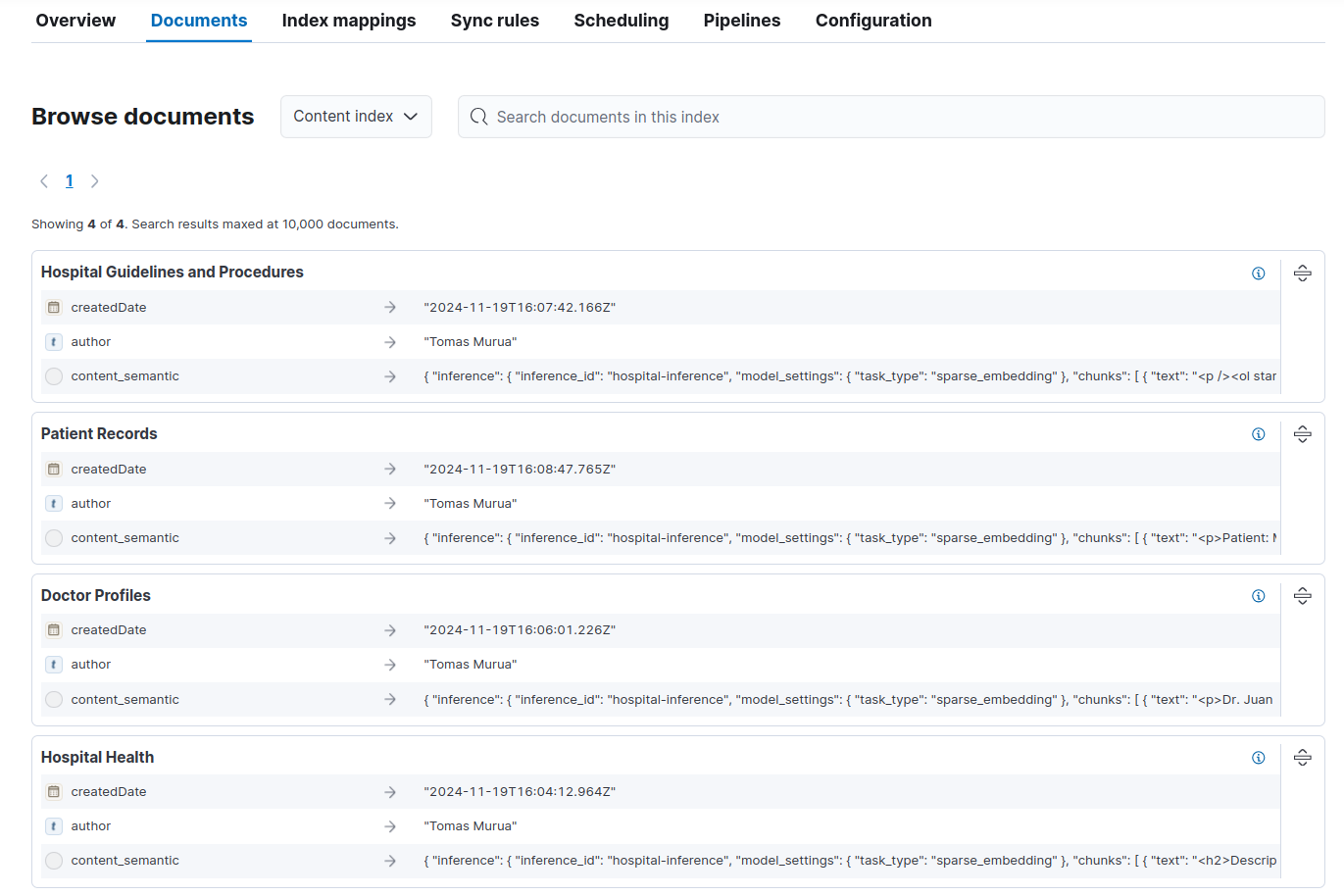
Preparing the index
With what we have so far, we could run full text queries on our content. Since we want to make questions instead of looking for keywords, we now need to have semantic search.
For this purpose we will use Elasticsearch ELSER model as the embeddings provider.
To configure this, use the Elasticsearch's inference API.
Go to Kibana Dev Tools and copy this code to start the endpoint:
PUT _inference/sparse_embedding/hospital-inference
{
"service": "elser",
"service_settings": {
"num_allocations": 1,
"num_threads": 1
}
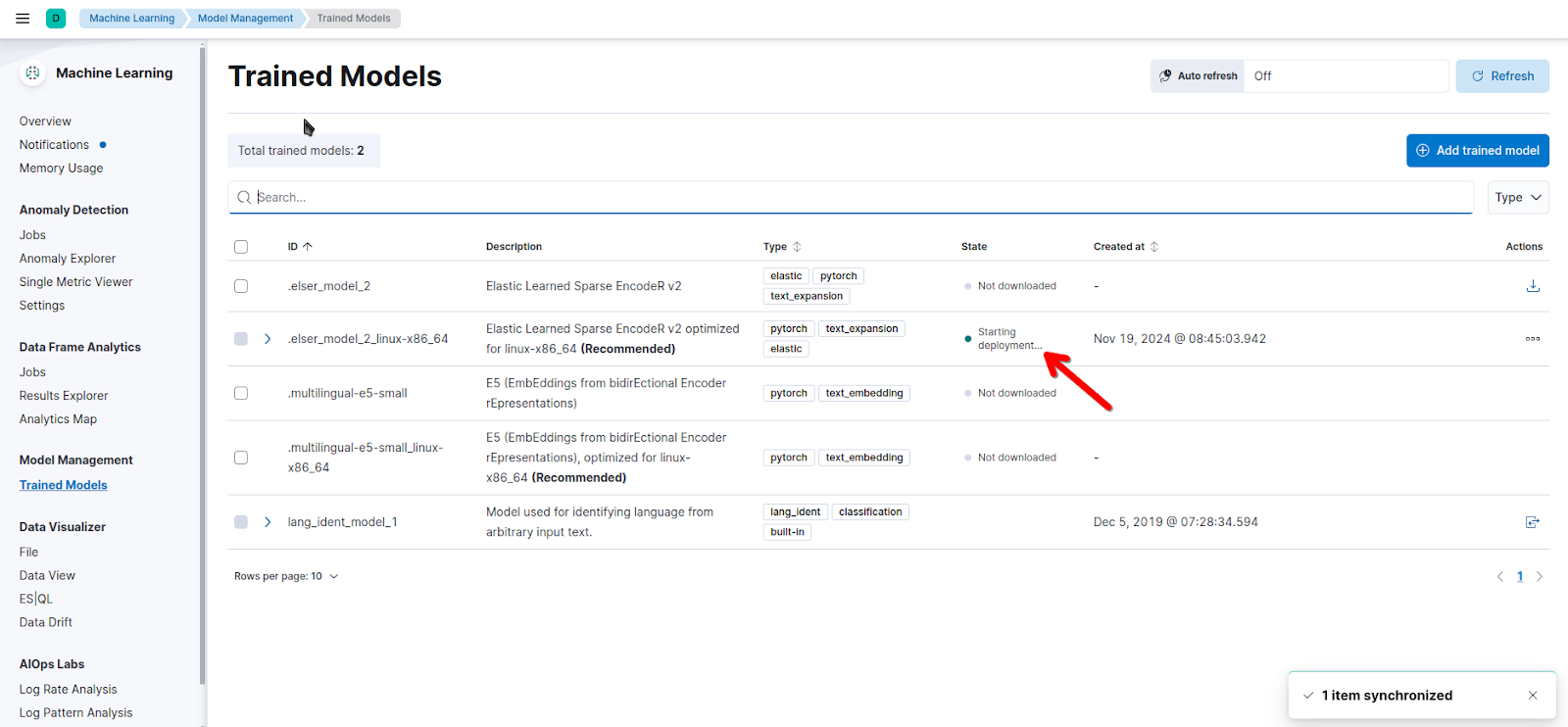
}Now the model is loading in the background. You might get a 502 Bad Gateway error if you haven't used the ELSER model before. To make sure the model is loading, check Machine Learning > Trained Models:
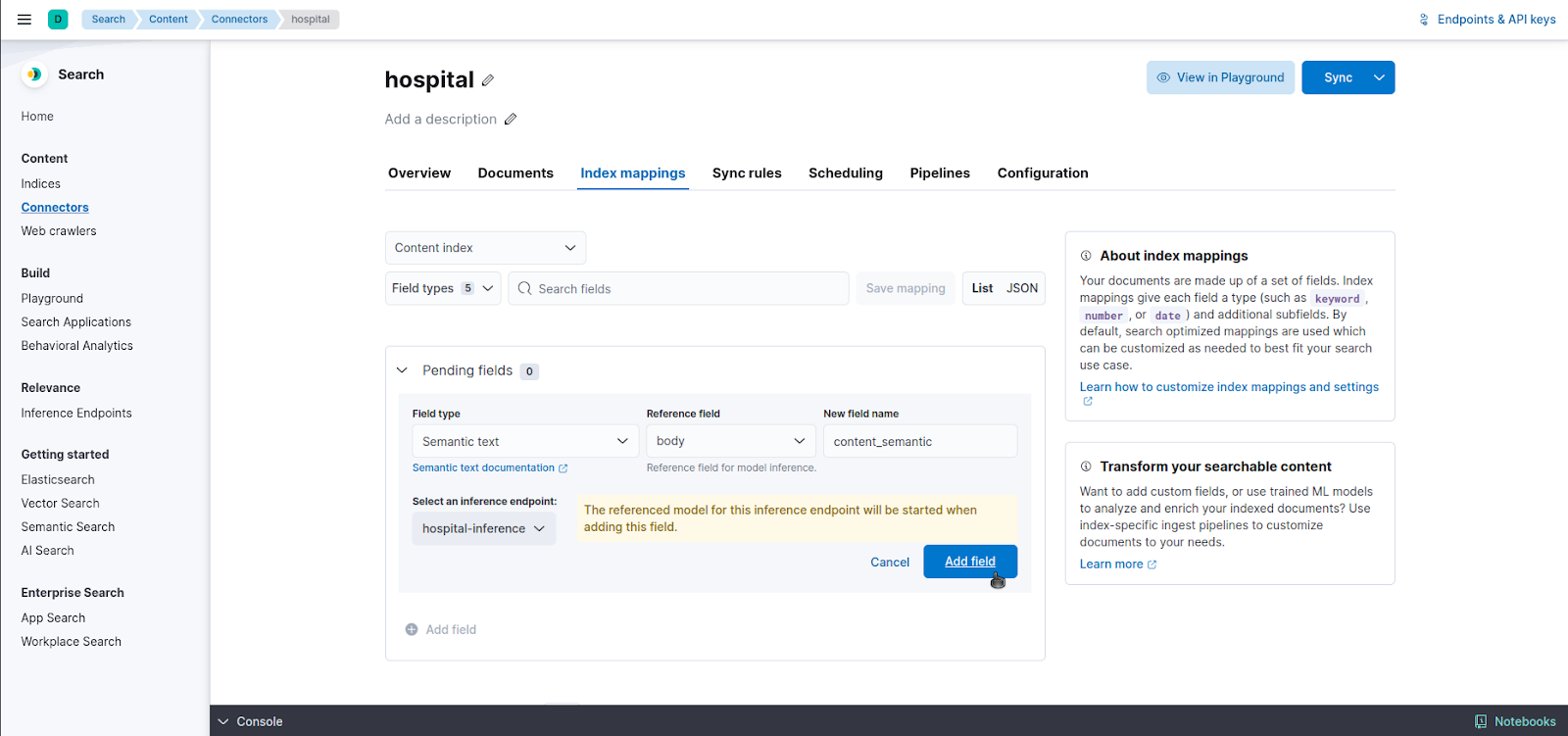
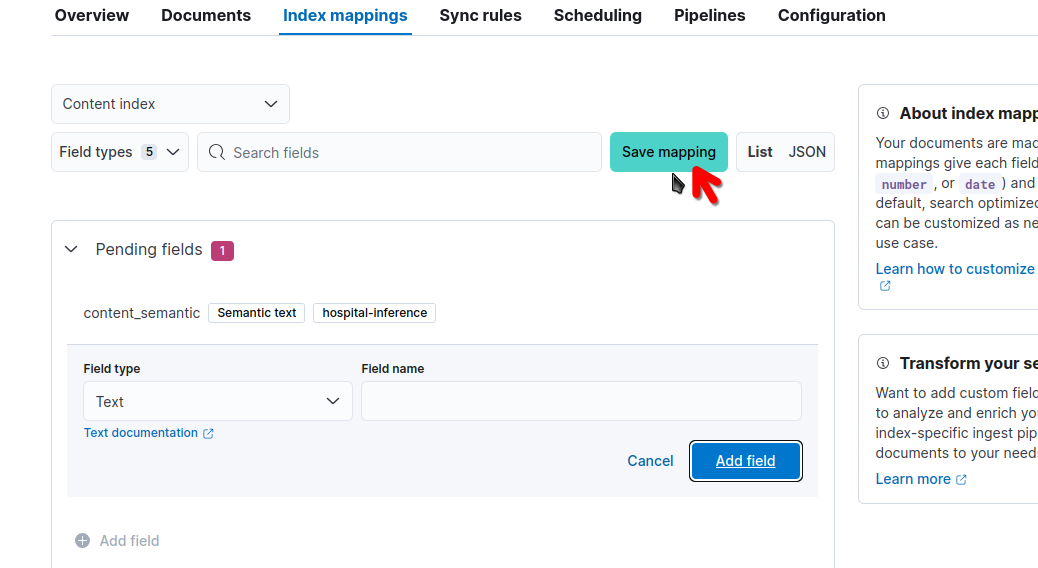
Let's add a semantic_text field using the UI. Go to the connector's page, select Index mappings, and click on Add Field.
Select "Semantic text" as field type. For this example, the reference field will be "body" and the field name content_semantic. Finally, select the inference endpoint we've just configured.
Before clicking on "Add field", check that your configuration looks similar to this:
Now click on "Save mapping":
One you've ran the Full Content Sync from the UI, let's check it's ok by running a semantic query:
GET hospital/_search
{
"size": 1,
"_source": {
"excludes": [
"*embeddings",
"*chunks"
]
},
"query": {
"semantic": {
"field": "content_semantic",
"query": "doctors information"
}
}
}The response should look something like this:
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 6.8836327,
"hits": [
{
"_index": "hospital",
"_id": "7602523",
"_score": 6.8836327,
"_ignored": [
"body.enum"
],
"_source": {
"author": "your-confluence-name",
"content_semantic": {
"inference": {
"inference_id": "hospital-inference",
"model_settings": {
"task_type": "sparse_embedding"
}
}
},
"type": "page",
"title": "Patient Records",
"body": """<p>Patient: Maria Gonzalez</p><ac:structured-macro ac:name="code" ac:schema-version="1" ac:macro-id="94a4309e-f9c2-4d5c-b7e3-fd26f6500555"><ac:plain-text-body><![CDATA[• Patient ID: P-10234 • Date of Birth: January 15, 1985 • Gender: Female • Blood Type: O+ • Emergency Contact: • Name: Juan Gonzalez (Husband) • Phone: +56 9 1234 5678 • Allergies: Penicillin • Chronic Conditions: Type 2 Diabetes • Current Medications: • Metformin 500 mg (twice daily) • Lisinopril 10 mg (once daily) • Recent Visits: 1. October 5, 2024: • Reason: Regular diabetes check-up. • Findings: Stable HbA1c levels (6.8%). • Treatment: Continue current medication. 2. November 2, 2024: • Reason: Minor injury (ankle sprain). • Treatment: Bandage, physical therapy recommended. • Primary Physician: Dr. Juan Pérez Rodríguez (Cardiology) • Notes: • Patient shows good compliance with diabetes management plan. • Follow-up appointment scheduled for January 10, 2025.]]></ac:plain-text-body></ac:structured-macro><p>Patient: Carlos Lopez</p><ac:structured-macro ac:name="code" ac:schema-version="1" ac:macro-id="f99cbaf8-28ee-41aa-9489-22dcaba756eb"><ac:plain-text-body><![CDATA[• Patient ID: P-10987 • Date of Birth: March 23, 1970 • Gender: Male • Blood Type: A- • Emergency Contact: • Name: Sofia Lopez (Daughter) • Phone: +56 9 2345 6789 • Allergies: None reported • Chronic Conditions: Hypertension • Current Medications: • Losartan 50 mg (once daily) • Atorvastatin 20 mg (once daily) • Recent Visits: 1. September 10, 2024: • Reason: Chest pain. • Findings: No evidence of cardiac issues; diagnosed as acid reflux. • Treatment: Prescribed omeprazole. 2. October 20, 2024: • Reason: Blood pressure follow-up. • Findings: BP controlled at 130/85 mmHg. 3. November 15, 2024: • Reason: Flu symptoms. • Treatment: Prescribed antiviral medication. • Primary Physician: Dr. Maria Fernanda López (Pediatrics/General Medicine) • Notes: • Needs annual cardiovascular evaluation. • Recommended diet and exercise modifications.]]></ac:plain-text-body></ac:structured-macro><p>Patient: Ana Torres</p><ac:structured-macro ac:name="code" ac:schema-version="1" ac:macro-id="b68d2005-2b16-4775-afb7-730a729a3753"><ac:plain-text-body><![CDATA[• Patient ID: P-12345 • Date of Birth: July 12, 1992 • Gender: Female • Blood Type: AB+ • Emergency Contact: • Name: Luis Torres (Brother) • Phone: +56 9 3456 7890 • Allergies: None reported • Chronic Conditions: None reported • Current Medications: None • Recent Visits: 1. June 18, 2024: • Reason: Routine physical exam. • Findings: All tests normal. 2. October 5, 2024: • Reason: Severe headache. • Findings: Diagnosed with tension headache. • Treatment: Prescribed ibuprofen and stress management techniques. • Primary Physician: Dr. Carolina Martínez Torres (Dermatology) • Notes: • Advised to monitor hydration and sleep patterns. • Referred to counseling for stress management.]]></ac:plain-text-body></ac:structured-macro><p>Patient: Roberto Castillo</p><ac:structured-macro ac:name="code" ac:schema-version="1" ac:macro-id="3c9e75e2-d412-430c-8427-78a71040dbfd"><ac:plain-text-body><![CDATA[• Patient ID: P-15432 • Date of Birth: August 5, 1965 • Gender: Male • Blood Type: B+ • Emergency Contact: • Name: Elena Castillo (Wife) • Phone: +56 9 4567 8901 • Allergies: Sulfa drugs • Chronic Conditions: Chronic Obstructive Pulmonary Disease (COPD) • Current Medications: • Tiotropium inhaler (once daily) • Salbutamol (as needed) • Recent Visits: 1. August 20, 2024: • Reason: Difficulty breathing. • Findings: COPD exacerbation due to respiratory infection. • Treatment: Prescribed antibiotics and corticosteroids. 2. November 10, 2024: • Reason: Routine COPD management. • Findings: Improved lung function post-treatment. • Primary Physician: Dr. Esteban González Martínez (Orthopedics/General Care) • Notes: • Patient advised to avoid smoking and cold weather. • Pulmonary rehabilitation program recommended.]]></ac:plain-text-body></ac:structured-macro><p>Patient: Lucia Rivera</p><ac:structured-macro ac:name="code" ac:schema-version="1" ac:macro-id="b49bf9e7-c26d-45ed-8fc5-1ac23b89a049"><ac:plain-text-body><![CDATA[• Patient ID: P-17654 • Date of Birth: May 19, 2000 • Gender: Female • Blood Type: O- • Emergency Contact: • Name: Pedro Rivera (Father) • Phone: +56 9 5678 9012 • Allergies: Latex • Chronic Conditions: Asthma • Current Medications: • Fluticasone inhaler (daily) • Albuterol (as needed for acute symptoms) • Recent Visits: 1. July 15, 2024: • Reason: Asthma exacerbation. • Findings: Trigger identified as seasonal pollen. • Treatment: Adjusted inhaler dosage. 2. October 25, 2024: • Reason: Follow-up visit. • Findings: Asthma under control; no acute symptoms reported. • Primary Physician: Dr. Maria Fernanda López (Pediatrics) • Notes: • Recommended allergy testing for better management. • Advised to carry rescue inhaler at all times.]]></ac:plain-text-body></ac:structured-macro>""",
"space": "Hospital Health",
"url": "https://tomasmurua.atlassian.net/wiki/spaces/HH/pages/7602523/Patient+Records",
"labels": [],
"createdDate": "2024-11-19T16:08:47.765Z",
"id": "7602523",
"ancestors": [
{
"title": "Hospital Health"
}
],
"_timestamp": "2024-11-19T16:09:33.434Z",
"_allow_access_control": [
"account_id:712020:88983800-6c97-469a-9451-79c2dd3732b5",
"group_id:5c41d427-6ce5-4936-9e07-dada287179e8",
"group_id:26497e10-fe1b-4510-87e4-356c8f60fe49",
"group_id:bbdc180e-eec3-4723-9647-867efb4491be",
"group_id:55332682-d081-46e4-bd8c-9e3a37d03b14"
]
}
}
]
}Chat with your data using Playground
What is Playground?
Playground is a low code platform hosted in Kibana that allows you to easily create a RAG application and ask questions to your indices, regardless if they have embeddings.
Playground not only provides a UI chat with citations and provides full control over the queries, but also handles different LLMs to synthesize the answers.
You can read this article for a deeper insight and test the online demo to familiarize yourself with it.
Configure Playground
To begin, you only need the credentials for any of the compatible models:
- OpenAI (or any local model compatible with OpenAI API)
- Amazon Bedrock
- Google Gemini
When you open Playground, you have the option to configure the LLM provider and select the index with the documents you want to use as knowledge base.
For this example, we'll use OpenAI. You can check this link to learn how to get an API key.
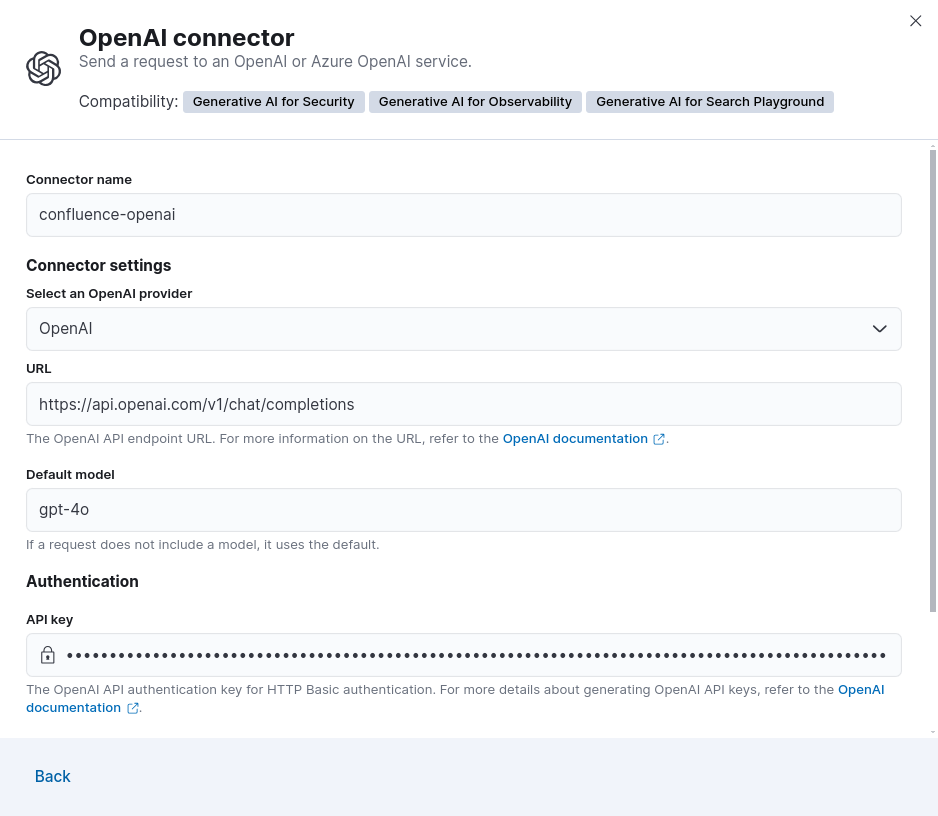
Let's create our OpenAI connector by clicking Connect to an LLM > OpenAI and let's fill in the fields as in the image below:
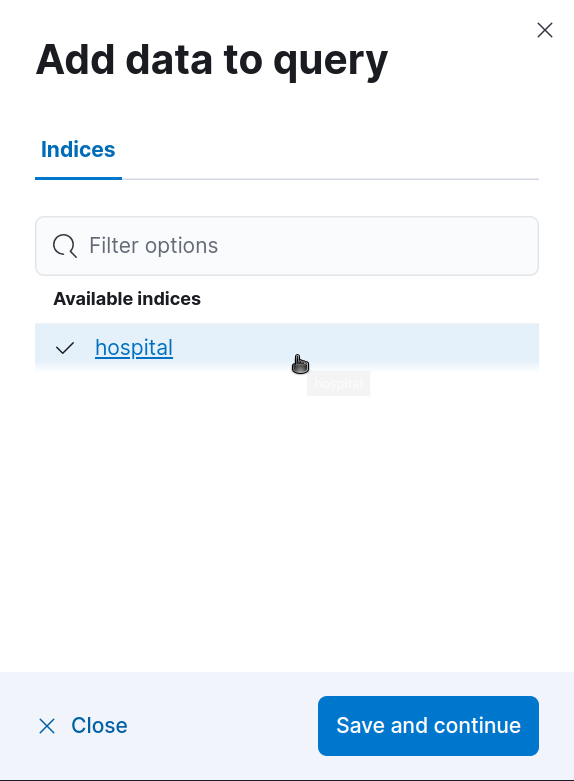
To select the index we created using the Confluence connector, click on "Add data sources" and click on the index.
NOTE: You can select more than one index, if you want.
Now that we're done configuring, we can start making questions to the model.
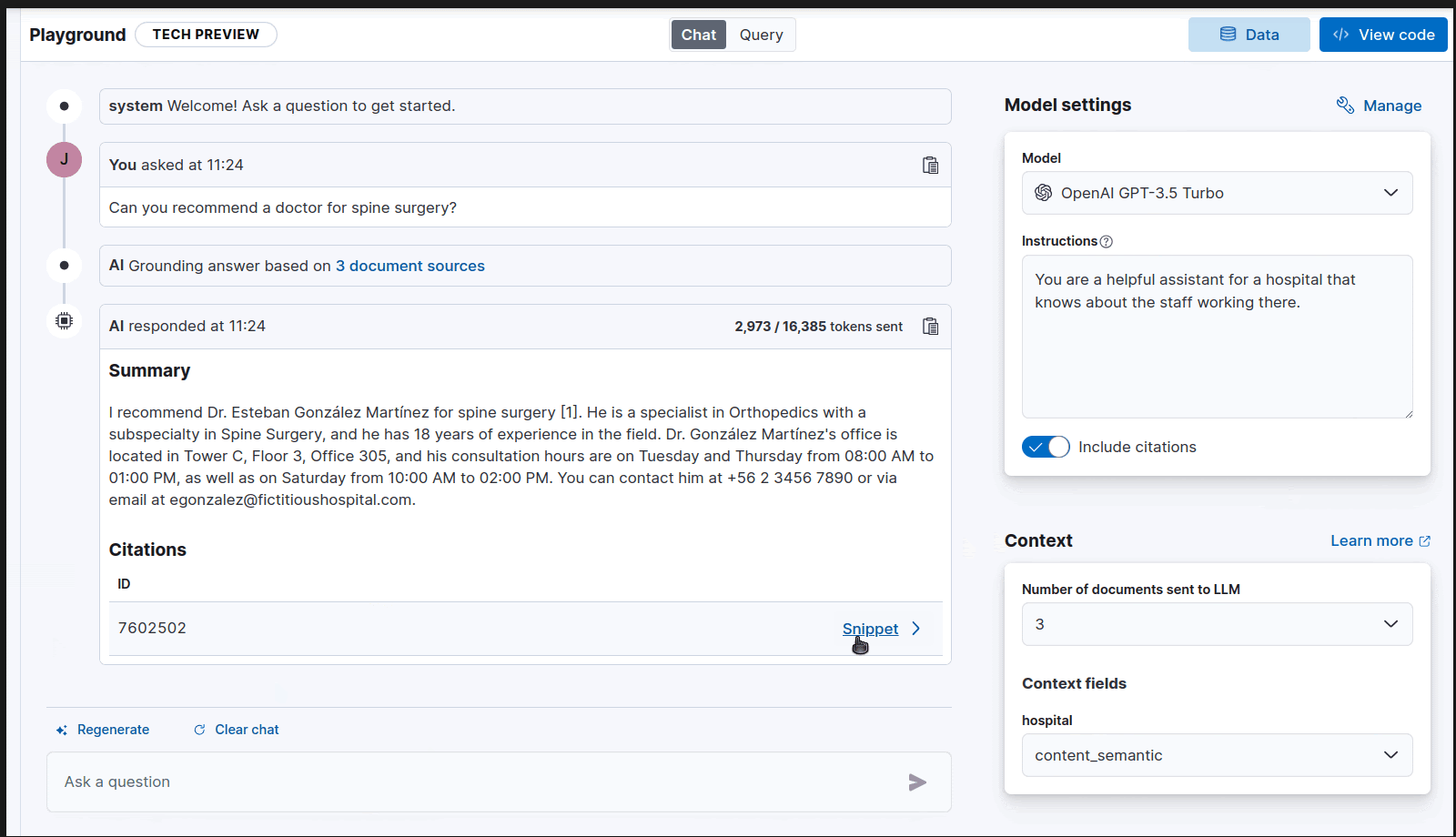
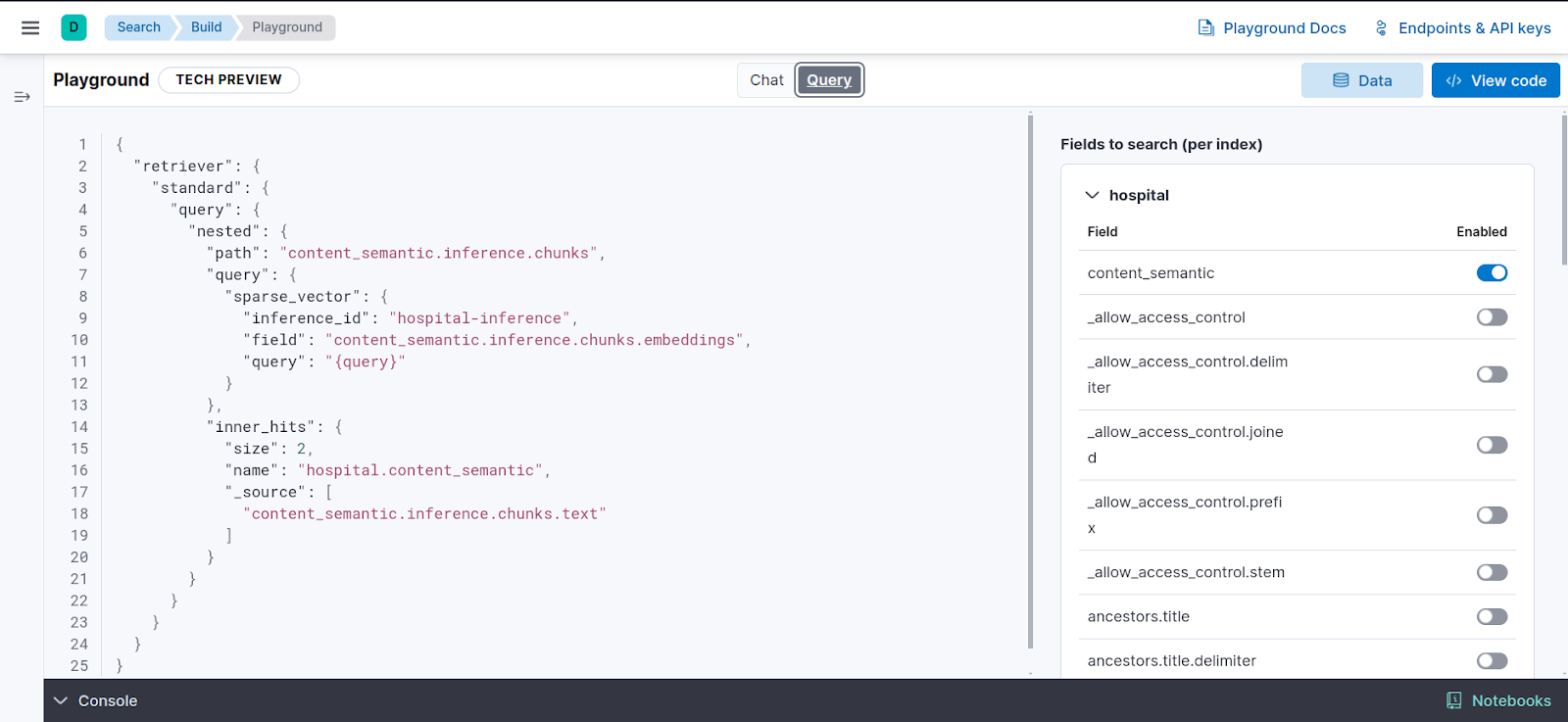
Aside from choosing to include citations with the source document in your answers, you can also control which fields to send to the LLM to use in search.
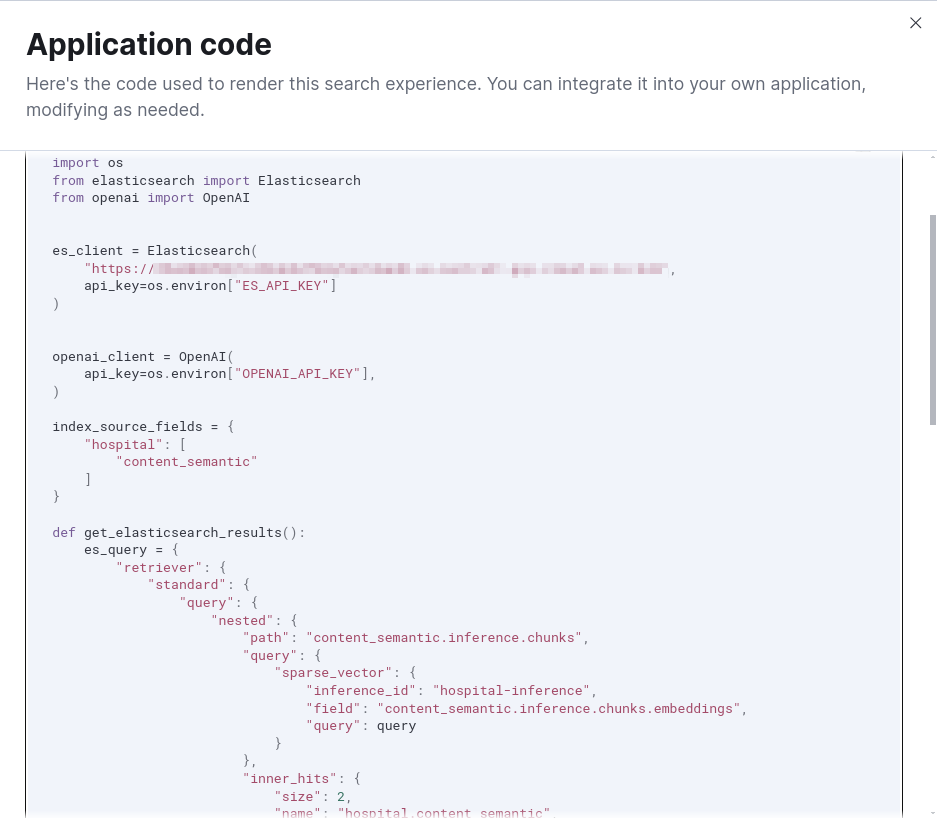
The View Code window provides the python code you need to integrate this into your apps.
Conclusion
In this article, we learned that we can use connectors both to search for information in different sources as well as a knowledge base using Playground. We also learned to easily deploy a RAG application to chat with your data without leaving the Elastic environment.
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content

September 22, 2025
Elastic Open Web Crawler as a code
Learn how to use GitHub Actions to manage Elastic Open Crawler configurations, so every time we push changes to the repository, the changes are automatically applied to the deployed instance of the crawler.

August 6, 2025
How to display fields of an Elasticsearch index
Learn how to display fields of an Elasticsearch index using the _mapping and _search APIs, sub-fields, synthetic _source, and runtime fields.

July 14, 2025
Run Elastic Open Crawler in Windows with Docker
Learn how to use Docker to get Open Crawler working in a Windows environment.

June 24, 2025
Ruby scripting in Logstash
Learn about the Logstash Ruby filter plugin for advanced data transformation in your Logstash pipeline.

June 4, 2025
3 ingestion tips to change your search game forever
Get your Elasticsearch ingestion game to the next level by following these tips: data pre-processing, data enrichment and picking the right field types.