Elasticsearch 9.1 incorporates a UI that makes it easier to handle synonym set creation, maintenance, and assigning synonyms to indices. It’s based on the Synonyms API, which was included in version 8.10.0.
In Elasticsearch, synonyms are rules that handle different terms as equivalent during document analysis and querying. They are useful for handling language variations such as acronyms (“AI” ↔ “artificial intelligence”), different spellings (Wi-Fi” ↔ “wifi”), or product names (“dress shirt” ↔ “formal shirt”), so users see results that include all variations of a query term.
In this blog, we’ll go over ways to configure synonyms in Elasticsearch, show how to create synonym sets using the Synonyms UI, and explain the difference between equivalent and explicit synonyms.
Index vs search-time synonyms
There are two ways to configure synonyms in Elasticsearch: at the time of indexing or when running a query. Each has different implications.
Let’s take a look at the main differences:
- Indexed synonyms: Here, synonyms are created while indexing documents, expanding the tokens and storing them in the inverted index. This method:
- Increases the index size.
- Impacts the token stats in the index, since these synonyms are also considered in the BM25 algorithm and affect the final document score.
- Search-time synonyms: These synonyms are calculated during query time, expanding the search tokens and comparing them with the index ones. This method:
- Does not impact the index.
- Slightly increases the query response time, since the synonyms are calculated each time you run the query.
If you want to learn more about these two methods, refer to The same, but different: Boosting the power of Elasticsearch with synonyms.
Generally speaking, the choice between these methods depends on the use case. However, in most cases, it is best to use search-time synonyms, so we’ll use that approach in this blog. In addition, synonym sets (i.e., groups of words that can be considered equivalent) can only be applied during the querying process.
Creating synonym sets with the Synonyms UI
Synonym sets are groups of words that act as logic containers, where you define the rules specifying which terms should be treated as synonyms. Within each set, you can add lists of words and related expressions, in one or two directions. The best part is that you can then easily add them to any index with just a couple of clicks.
Now, let’s create a synonym set for documents relating to AI using the Synonyms UI. You can access this tool from Kibana´s side menu, under: Elasticsearch > Relevance > Synonyms.
As soon as you click on Synonyms, you’ll get a Get Started screen. Click on create:
Let’s name the set ai-synonyms. On the next screen, we’ll define the rules:
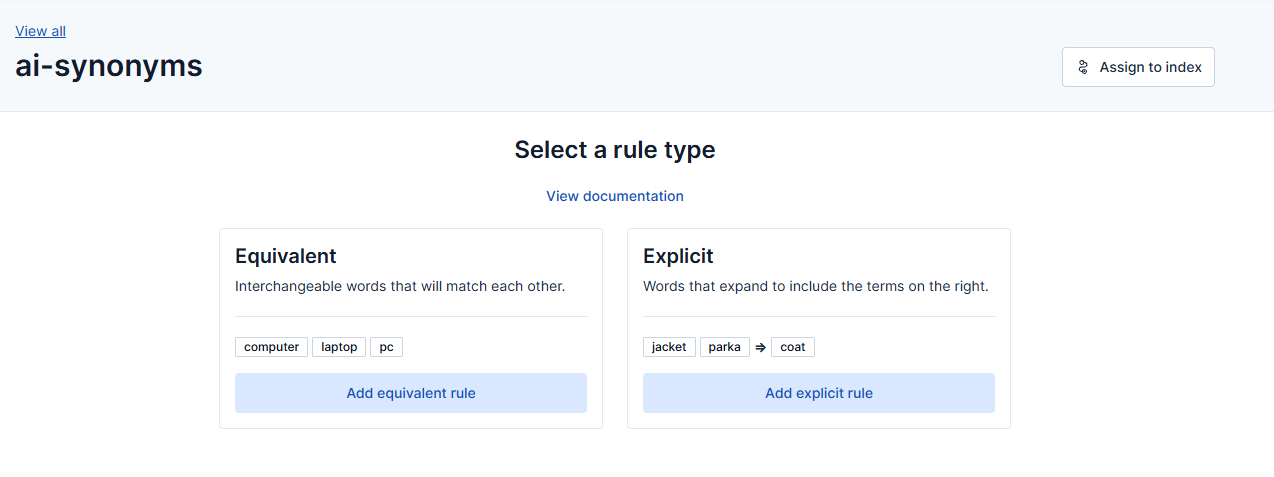
Rules can be equivalent (two-directional) or explicit (one-directional). We’ll learn more about these rules in the next section.
Equivalent synonyms (bidirectional)
In Elasticsearch, a bidirectional or equivalent synonym rule implies that the list of terms is interchangeable within a set of documents, for example, iphone/smart phone in an e-commerce website.
Let’s create an equivalent synonym set with four rules:
- chatbot ↔ artificial intelligence
- self-driving car ↔ autonomous vehicle
- llm ↔ large language model
- ai ↔ artificial intelligence
You can start adding words and using comma, enter, or shift to insert the word into the list:
The final set should look like this:

Now, let’s create the index where we’ll use the set. Go to Dev Tools and run the script below. This will create an index with two fields: title and title.synonyms, so we can easily see the difference between searching with and without synonyms.
PUT ai_articles
{
"settings": {
"analysis": {
"filter": {
"ecom_syns": {
"type": "synonym",
"synonyms_set": "ai-synonyms",
"updateable": true
}
},
"analyzer": {
"my_search_analyzer": {
"tokenizer": "standard",
"filter": ["lowercase", "ecom_syns"]
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "standard",
"fields": {
"synonyms": {
"type": "text",
"search_analyzer": "my_search_analyzer"
}
}
}
}
}
}Then, you need to index these documents:
POST _bulk
{ "index": { "_index": "ai_articles", "_id": "1" } }
{ "title": "Artificial Intelligence in Healthcare" }
{ "index": { "_index": "ai_articles", "_id": "2" } }
{ "title": "Chatbot for Customer Support" }
{ "index": { "_index": "ai_articles", "_id": "3" } }
{ "title": "Self-Driving Car Safety Guide" }
{ "index": { "_index": "ai_articles", "_id": "4" } }
{ "title": "Autonomous Vehicle Safety Guide" }
{ "index": { "_index": "ai_articles", "_id": "5" } }
{ "title": "Large Language Model Training Basics" }
{ "index": { "_index": "ai_articles", "_id": "6" } }
{ "title": "LLM Inference Optimization" }
{ "index": { "_index": "ai_articles", "_id": "7" } }
{ "title": "AI: Appreciative Inquiry in Organizational Change" }And finally, run this query:
GET ai_articles/_search
{
"query": {
"match": {
"title": "llm"
}
}
}You can see that we’re only getting the result with an exact match, leaving behind the article titled Large Language Model Training Basics.
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.7397224,
"hits": [
{
"_index": "ai_articles",
"_id": "6",
"_score": 1.7397224,
"_source": {
"title": "LLM Inference Optimization"
}
}
]
}
}Now, let’s run the query using the synonym field:
GET ai_articles/_search
{
"query": {
"match": {
"title.synonyms": "llm"
}
}
}Now we get the document with LLM and large language model:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 2.8478816,
"hits": [
{
"_index": "ai_articles",
"_id": "5",
"_score": 2.8478816,
"_source": {
"title": "Large Language Model Training Basics"
}
},
{
"_index": "ai_articles",
"_id": "6",
"_score": 1.7397224,
"_source": {
"title": "LLM Inference Optimization"
}
}
]
}
}Since this is an equivalent or two-direction rule, we’ll get the same results if we now search for “large language model”:
GET ai_articles/_search
{
"query": {
"match": {
"title.synonyms": "large language model"
}
}
}Check out the results:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 4.271822,
"hits": [
{
"_index": "ai_articles",
"_id": "5",
"_score": 4.271822,
"_source": {
"title": "Large Language Model Training Basics"
}
},
{
"_index": "ai_articles",
"_id": "6",
"_score": 1.7397224,
"_source": {
"title": "LLM Inference Optimization"
}
}
]
}
}Explicit synonyms (one-direction)
Unlike equivalent synonyms, explicit synonyms only go one way: from a source term to another one, but not the other way around.
Right now, since all our rules are equivalent, when we run the search below:
GET ai_articles/_search
{
"query": {
"match": {
"title.synonyms": "artificial intelligence"
}
}
}We get article #7, even though it has nothing to do with “Artificial Intelligence”, since both terms (AI and Artificial Intelligence) are deemed equivalent.
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 3.4859602,
"hits": [
{
"_index": "ai_articles",
"_id": "1",
"_score": 3.4859602,
"_source": {
"title": "Artificial Intelligence in Healthcare"
}
},
{
"_index": "ai_articles",
"_id": "2",
"_score": 1.7429801,
"_source": {
"title": "Chatbot for Customer Support"
}
},
{
"_index": "ai_articles",
"_id": "7",
"_score": 1.4617822,
"_source": {
"title": "AI: Appreciative Inquiry in Organizational Change"
}
}
]
}
}If we create a directional rule ai => artificial intelligence, when we search for “ai”, Elasticsearch would replace “ai” with “artificial intelligence”, so this search:
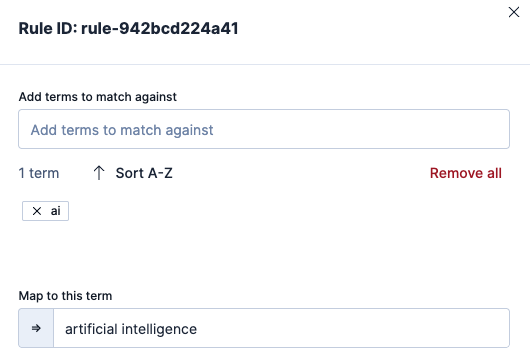
Note that a ruleset can have explicit, and equivalent synonym rules in it.
GET ai_articles/_search
{
"query": {
"match": {
"title.synonyms": "ai"
}
}
}Will only return results with “artificial intelligence”, even if there are other documents that say “ai”.
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 3.4859602,
"hits": [
{
"_index": "ai_articles",
"_id": "1",
"_score": 3.4859602,
"_source": {
"title": "Artificial Intelligence in Healthcare"
}
}
]
}
}You can see how this works using API _analyze:
POST ai_articles/_analyze
{
"analyzer": "my_search_analyzer",
"text": "AI"
}You can clearly see that we’re only getting two tokens, and no results with just “ai”:
{
"tokens": [
{
"token": "artificial",
"start_offset": 0,
"end_offset": 2,
"type": "SYNONYM",
"position": 0
},
{
"token": "intelligence",
"start_offset": 0,
"end_offset": 2,
"type": "SYNONYM",
"position": 1
}
]
}To avoid losing documents that also include “ai”, we can adjust the configuration so that the term is not only replaced, but expanded:
We only need to define the rule like this in the Synonyms UI: ai => artificial intelligence, ai.

Elasticsearch will show this change in the index immediately, so that the same query with “ai” will now yield more results:
GET ai_articles/_search
{
"query": {
"match": {
"title.synonyms": "ai"
}
}
}Response:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 3.4859602,
"hits": [
{
"_index": "ai_articles",
"_id": "1",
"_score": 3.4859602,
"_source": {
"title": "Artificial Intelligence in Healthcare"
}
},
{
"_index": "ai_articles",
"_id": "7",
"_score": 1.4617822,
"_source": {
"title": "AI: Appreciative Inquiry in Organizational Change"
}
}
]
}
}Conclusion
Synonyms are essential in search because they cover variations of the same word that users may use. Elasticsearch supports both equivalent and explicit synonyms to better capture user intent. Equivalent synonyms establish equivalences between words, while explicit synonyms define one word as a synonym for another, but not vice versa.
Using the Synonym UI in Kibana, we can perform maintenance tasks that, until now, could only be done using the synonym API.
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content

October 8, 2025
How to reduce the number of shards in an Elasticsearch Cluster
Learn how Elasticsearch shards affect cluster performance in this comprehensive guide, including how to get the shard count, change it from default, and reduce it if needed.
October 3, 2025
How to deploy Elasticsearch on AWS Marketplace
Learn how to set up and run Elasticsearch using Elastic Cloud Service on AWS Marketplace in this step-by-step guide.

September 29, 2025
HNSW graph: How to improve Elasticsearch performance
Learn how to use the HNSW graph M and ef_construction parameters to improve search performance.
September 26, 2025
Elasticsearch plugin for UBI: Analyze user data in Kibana
Discover how to capture user behavior data using the Elasticsearch plugin for UBI and build a custom dashboard in Kibana to analyze it.
September 23, 2025
How to set up and deploy Elasticsearch via Azure Marketplace
Learn how to set up and deploy Elasticsearch using Azure Native ISV Service.