LangExtract is an open-source Python library created by Google that helps transform unstructured text into structured information using multiple LLMs and custom instructions. Unlike using an LLM alone, LangExtract provides structured and traceable outputs, links each extraction back to the original text, and offers visual tools for validation, making it a practical solution for information extraction in different contexts.
LangExtract is useful when you want to transform unstructured data—such as contracts, invoices, books, etc—into a defined structure, making it searchable and filterable. For example, classify expenses of an invoice, extract the parties in a contract, or even detect the sentiments of the characters of a certain paragraph in a book.
LangExtract also offers features such as long context handling, remote file loading, multiple passes to improve recall, and multiple workers to parallelize the work.
Use case
To demonstrate how LangExtract and Elasticsearch work together, we will use a dataset of 10 contracts of different types. These contracts contain standard data such as costs, amounts, dates, duration, and contractor. We will use LangExtract to extract structured data from the contracts and store them as fields in Elasticsearch, allowing us to run queries and filters against them.
You can find the full notebook here.
Steps
- Installing dependencies and importing packages
- Setting up Elasticsearch
- Extracting data with LangExtract
- Querying data
Installing dependencies and importing packages
We need to install LangExtract to process the contracts and extract structured data from them, as well as the elasticsearch client to handle Elasticsearch requests.
%pip install langextract elasticsearch -qWith the dependencies installed, let’s import the following:
- json – which helps to handle JSON data.
- os – to access local environment variables.
- glob – used to search files in directories based on a pattern.
- google.colab – useful in Google Colab notebooks to load locally stored files.
- helpers – which provide extra Elasticsearch utilities, for example, to insert or update multiple documents in bulk.
- IPython.display.HTML – which allows you to render HTML content directly inside a notebook, making outputs more readable.
- getpass – used to securely input sensitive information, such as passwords or API keys, without displaying them on the screen.
import langextract as lx
import json
import os
import glob
from google.colab import files
from elasticsearch import Elasticsearch, helpers
from IPython.display import HTML
from getpass import getpassSetting up Elasticsearch
Setup keys
We now need to set some variables before developing the app. We will use Gemini AI as our model. Here you can learn how to obtain an API key from the Google AI Studio. Also, make sure you have an Elasticsearch API key available.
os.environ["ELASTICSEARCH_API_KEY"] = getpass("Enter your Elasticsearch API key: ")
os.environ["ELASTICSEARCH_URL"] = getpass("Enter your Elasticsearch URL: ")
os.environ["LANGEXTRACT_API_KEY"] = getpass("Enter your LangExtract API key: ")
INDEX_NAME = "contracts"Elasticsearch client
es_client = Elasticsearch(
os.environ["ELASTICSEARCH_URL"], api_key=os.environ["ELASTICSEARCH_API_KEY"]
)Index mappings
Let’s define the Elasticsearch mappings for the fields we are going to extract with LangExtract. Note that we use keyword for the fields we want to use exclusively for filters, and text + keyword for the ones we plan to search and filter on.
try:
mapping = {
"mappings": {
"properties": {
"contract_date": {"type": "date", "format": "MM/dd/yyyy"},
"end_contract_date": {"type": "date", "format": "MM/dd/yyyy"},
"service_provider": {
"type": "text",
"fields": {"keyword": {"type": "keyword"}},
},
"client": {"type": "text", "fields": {"keyword": {"type": "keyword"}}},
"service_type": {"type": "keyword"},
"payment_amount": {"type": "float"},
"delivery_time_days": {"type": "numeric"},
"governing_law": {"type": "keyword"},
"raw_contract": {"type": "text"},
}
}
}
es_client.indices.create(index=INDEX_NAME, body=mapping)
print(f"Index {INDEX_NAME} created successfully")
except Exception as e:
print(f"Error creating index: {e}")Extracting data with LangExtract
Providing examples
The LangExtract code defines a training example for LangExtract that shows how to extract specific information from contracts.
The contract_examples variable contains an ExampleData object that includes:
- Example text: A sample contract with typical information like dates, parties, services, payments, etc.
- Expected extractions: A list of extraction objects that map each piece of information from the text to a specific class (
extraction_class) and its normalized value (extraction_text). Theextraction_classwill be the field name, and the extraction_text will be the value of that field.
For example, the date "March 10, 2024" from the text is extracted as class contract_date (field name) with normalized value "03/10/2024" (field value). The model learns from these patterns to extract similar information from new contracts.
The contract_prompt_description provides additional context about what to extract and in what order, complementing what the examples alone cannot express.
contract_prompt_description = "Extract contract information including dates, parties (contractor and contractee), purpose/services, payment amounts, timelines, and governing law in the order they appear in the text."
# Define contract-specific example data to help the model understand what to extract
contract_examples = [
lx.data.ExampleData(
text="Service Agreement dated March 10, 2024, between ABC Corp (Service Provider) and John Doe (Client) for consulting services. Payment: $5,000. Delivery: 30 days. Contract ends June 10, 2024. Governed by California law.",
extractions=[
lx.data.Extraction(
extraction_class="contract_date", extraction_text="03/10/2024"
),
lx.data.Extraction(
extraction_class="end_contract_date", extraction_text="06/10/2024"
),
lx.data.Extraction(
extraction_class="service_provider", extraction_text="ABC Corp"
),
lx.data.Extraction(extraction_class="client", extraction_text="John Doe"),
lx.data.Extraction(
extraction_class="service_type", extraction_text="consulting services"
),
lx.data.Extraction(
extraction_class="payment_amount", extraction_text="5000"
),
lx.data.Extraction(
extraction_class="delivery_time_days", extraction_text="30"
),
lx.data.Extraction(
extraction_class="governing_law", extraction_text="California"
),
],
)
]Dataset
You can find the entire dataset here. Below is an example of what the contracts look like:
This Contract Agreement ("Agreement") is made and entered into on February 2, 2025, by and between:
* Contractor: GreenLeaf Landscaping Co.
* Contractee: Robert Jenkins
Purpose: Garden maintenance and landscaping for private residence.
Terms and Conditions:
1. The Contractor agrees to pay the Contractee the sum of $3,200 for the services.
2. The Contractee agrees to provide landscaping and maintenance services for a period of 3 months.
3. This Agreement shall terminate on May 2, 2025.
4. This Agreement shall be governed by the laws of California.
5. Both parties accept the conditions stated herein.
Signed:
GreenLeaf Landscaping Co.
Robert JenkinsSome data is explicitly written in the document, but other values can be inferred and converted by the model. For example, dates will be formatted as dd/MM/yyyy, and duration in months will be converted to days.
Running extraction
In a Colab notebook, you can load the files with:
files.upload()LangExtract extracts fields and values with the lx.extract function. It must be called for each contract, passing the content, prompt, example, and model ID.
contract_files = glob.glob("*.txt")
print(f"Found {len(contract_files)} contract files:")
for i, file_path in enumerate(contract_files, 1):
filename = os.path.basename(file_path)
print(f"\t{i}. {filename}")
results = []
for file_path in contract_files:
filename = os.path.basename(file_path)
with open(file_path, "r", encoding="utf-8") as file:
content = file.read()
# Run the extraction
contract_result = lx.extract(
text_or_documents=content,
prompt_description=contract_prompt_description,
examples=contract_examples,
model_id="gemini-2.5-flash",
)
results.append(contract_result)To better understand the extraction process, we can save the extraction results as an NDJSON file:
NDJSON_FILE = "extraction_results.ndjson"
# Save the results to a JSONL file
lx.io.save_annotated_documents(results, output_name=NDJSON_FILE, output_dir=".")
# Generate the visualization from the file
html_content = lx.visualize(NDJSON_FILE)
HTML(html_content.data)The line lx.visualize(NDJSON_FILE) generates an HTML visualization with the references from a single document, where you can see the specific lines where the data was extracted.
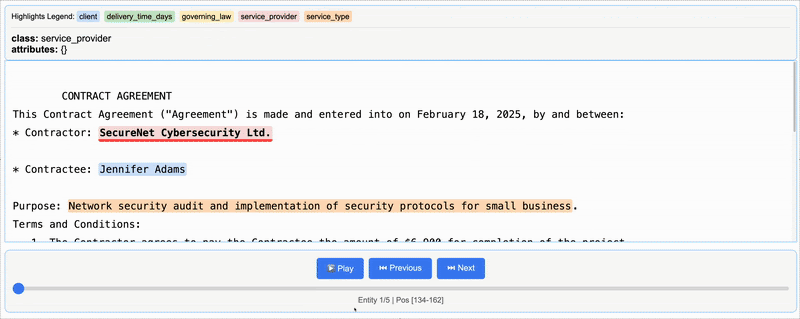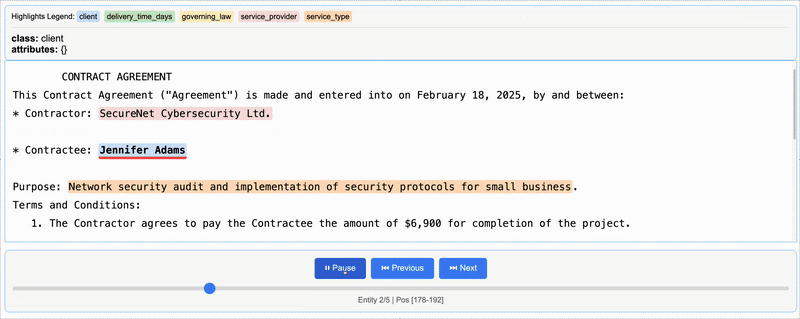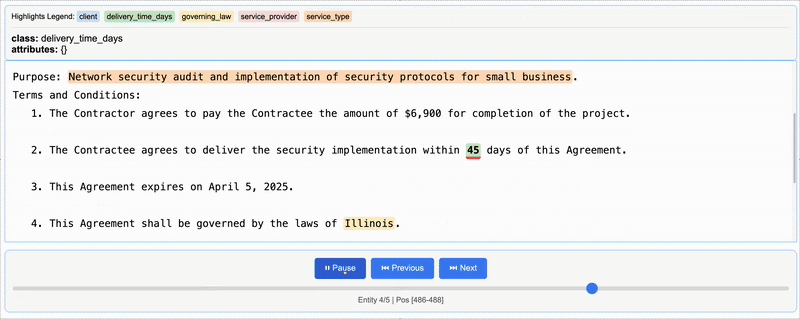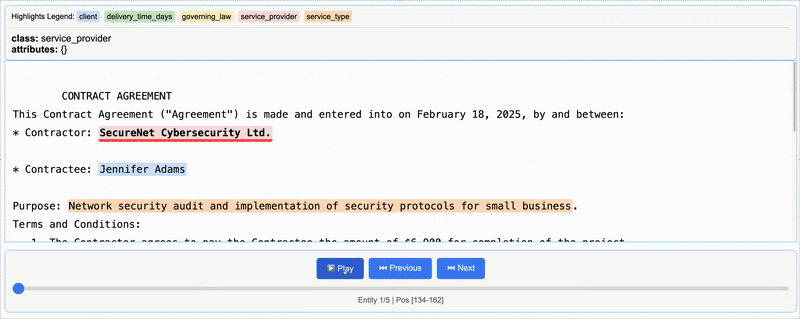
The extracted data from one contract will look like this:
{
"extractions": [
{
"extraction_class": "contract_date",
"extraction_text": "02/02/2025",
"char_interval": null,
"alignment_status": null,
"extraction_index": 1,
"group_index": 0,
"description": null,
"attributes": {}
},
{
"extraction_class": "service_provider",
"extraction_text": "GreenLeaf Landscaping Co.",
...
},
{
"extraction_class": "client",
"extraction_text": "Robert Jenkins",
...
},
{
"extraction_class": "service_type",
"extraction_text": "Garden maintenance and landscaping for private residence",
...
},
{
"extraction_class": "payment_amount",
"extraction_text": "3200",
...
},
{
"extraction_class": "delivery_time_days",
"extraction_text": "90",
...
},
{
"extraction_class": "end_contract_date",
"extraction_text": "05/02/2025",
...
},
{
"extraction_class": "governing_law",
"extraction_text": "California",
...
}
],
"text": "This Contract Agreement (\"Agreement\") is made and entered into on February 2, 2025, by and between:\n* Contractor: GreenLeaf Landscaping Co.\n\n* Contractee: Robert Jenkins\n\nPurpose: Garden maintenance and landscaping for private residence.\nTerms and Conditions:\n 1. The Contractor agrees to pay the Contractee the sum of $3,200 for the services.\n\n 2. The Contractee agrees to provide landscaping and maintenance services for a period of 3 months.\n\n 3. This Agreement shall terminate on May 2, 2025.\n\n 4. This Agreement shall be governed by the laws of California.\n\n 5. Both parties accept the conditions stated herein.\n\nSigned:\nGreenLeaf Landscaping Co.\nRobert Jenkins",
"document_id": "doc_5a65d010"
}Based on this result, we will index the data into Elasticsearch and query it.
Querying data
Indexing data to Elasticsearch
We use the _bulk API to ingest the data into the contracts index. We are going to store each of the extraction_class results as new fields, and the extraction_text as the values of those fields.
def build_data(ndjson_file, index_name):
with open(ndjson_file, "r") as f:
for line in f:
doc = json.loads(line)
contract_doc = {}
for extraction in doc["extractions"]:
extraction_class = extraction["extraction_class"]
extraction_text = extraction["extraction_text"]
contract_doc[extraction_class] = extraction_text
contract_doc["raw_contract"] = doc["text"]
yield {"_index": index_name, "_source": contract_doc}
try:
success, errors = helpers.bulk(es_client, build_data(NDJSON_FILE, INDEX_NAME))
print(f"{success} documents indexed successfully")
if errors:
print("Errors during indexing:", errors)
except Exception as e:
print(f"Error: {str(e)}")With that, we are ready to start writing queries:
10 documents indexed successfullyQuerying data
Now, let’s query contracts that have expired and have a payment amount greater than or equal to 15,000.
try:
response = es_client.search(
index=INDEX_NAME,
source_excludes=["raw_contract"],
body={
"query": {
"bool": {
"filter": [
{"range": {"payment_amount": {"gte": 15000}}},
{"range": {"end_contract_date": {"lte": "now"}}},
]
}
}
},
)
print(f"\nTotal hits: {response['hits']['total']['value']}")
for hit in response["hits"]["hits"]:
doc = hit["_source"]
print(json.dumps(doc, indent=4))
except Exception as e:
print(f"Error searching index: {str(e)}")And here are the results:
{
"contract_date": "01/08/2025",
"service_provider": "MobileDev Innovations",
"client": "Christopher Lee",
"service_type": "Mobile application development for fitness tracking and personal training",
"payment_amount": "18200",
"delivery_time_days": "100",
"end_contract_date": "04/18/2025",
"governing_law": "Colorado"
},
{
"contract_date": "01/22/2025",
"service_provider": "BlueWave Marketing Agency",
"client": "David Thompson",
"service_type": "Social media marketing campaign and brand development for startup company",
"payment_amount": "15600",
"delivery_time_days": "120",
"end_contract_date": "05/22/2025",
"governing_law": "Florida"
},
{
"contract_date": "02/28/2025",
"service_provider": "CloudTech Solutions Inc.",
"client": "Amanda Foster",
"service_type": "Cloud infrastructure migration and setup for e-commerce platform",
"payment_amount": "22400",
"delivery_time_days": "75",
"end_contract_date": "05/15/2025",
"governing_law": "Washington"
}Conclusion
LangExtract makes it easier to extract structured information from unstructured documents, with clear mappings and traceability back to the source text. Combined with Elasticsearch, this data can be indexed and queried, enabling filters and searches over contract fields like dates, payment amounts, and parties.
In our example, we kept the dataset simple, but the same flow can scale to larger collections of documents or different domains such as legal, financial, or medical text. You can also experiment with more extraction examples, custom prompts, or additional post-processing to refine the results for your specific use case.
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content

October 15, 2025
Training LTR models in Elasticsearch with judgement lists based on user behavior data
Learn how to use UBI data to create judgment lists to automate the training of your Learning to Rank (LTR) models in Elasticsearch.
September 19, 2025
Using TwelveLabs’ Marengo video embedding model with Amazon Bedrock and Elasticsearch
Creating a small app to search video embeddings from TwelveLabs' Marengo model.

Introducing the ES|QL query builder for the Python Elasticsearch Client
Learn how to use the ES|QL query builder, a new Python Elasticsearch client feature that makes it easier to construct ES|QL queries using a familiar Python syntax.
Evaluating your Elasticsearch LLM applications with Ragas
Assessing the quality of a RAG solution using Ragas metrics and Elasticsearch.
August 18, 2025
Using FastAPI’s WebSockets and Elasticsearch to build a real-time app
Learn how to build a real-time application using FastAPI WebSockets and Elasticsearch.