Like everyone else these days, here at Elastic, we are going all-in on Chat, Agents, and RAG. In the Search department, we’ve recently been working on an Agent Builder and Tool Registry, all with the intent of making it trivial to “chat” with your data in Elasticsearch.
Read the Building AI Agentic Workflows with Elasticsearch blog for more on the “big picture” of that effort, or Your First Elastic Agent: From a Single Query to an AI-Powered Chat for a more practical primer.
In this blog, though, we’re going to zoom in a bit to look at one of the first things that happens when you start to chat, and to walk you through some of the recent improvements we’ve made.
What’s happening here?

When you chat with your Elasticsearch data, our default AI Agent walks through this standard flow:
- Inspect the prompt.
- Identify which index is likely to contain the answers to that prompt.
- Generate a query for that index, based on the prompt.
- Search that index with that query.
- Synthesize the results.
- Can the results address the prompt? If yes, respond. If not, repeat, but try something different.
This shouldn’t look too novel - it’s just Retrieval Augmented Generation (RAG). And as you’d expect, the quality of your responses depends heavily on the relevance of your initial search results. So as we’ve been working on improving our response quality, we’ve been paying very close attention to the queries we were generating in step 3 and running in step 4. And we noticed an interesting pattern.
Often, when our first responses were “bad”, it wasn’t because we’d run a bad query. It was because we’d picked the wrong index to query. Steps 3 and 4 weren’t usually our issue - it was step 2.
What were we doing?
Our initial implementation was simple. We had built a tool (called index_explorer) that would effectively do a _cat/indices to list all the indices available to us, then ask the LLM to identify which of these indices was the best match for the user’s message/question/prompt. You can see this original implementation here.
You are an AI assistant for the Elasticsearch company.
based on a natural language query from the user, your task is to select up to ${limit} most relevant indices from a list of indices.
*The natural language query is:* ${nlQuery}
*List of indices:*
${indices.map((index) => `- ${index.index}`).join('\n')}
Based on those information, please return most relevant indices with your reasoning.
Remember, you should select at maximum ${limit} indices.How well was this working? We weren’t sure! We had clear examples where it wasn’t working well, but our real first challenge was to quantify our current state.
Establishing a baseline
It starts with data
What we needed was a Golden Data Set for measuring a tool’s effectiveness at selecting the right index given a user prompt and a preexisting set of indices. And we didn’t have such a dataset at hand.So we generated one.
Acknowledgement: This isn’t “best practice”, we know. But sometimes, it’s better to move forward than to bikeshed. Progress, SIMPLE Perfection.
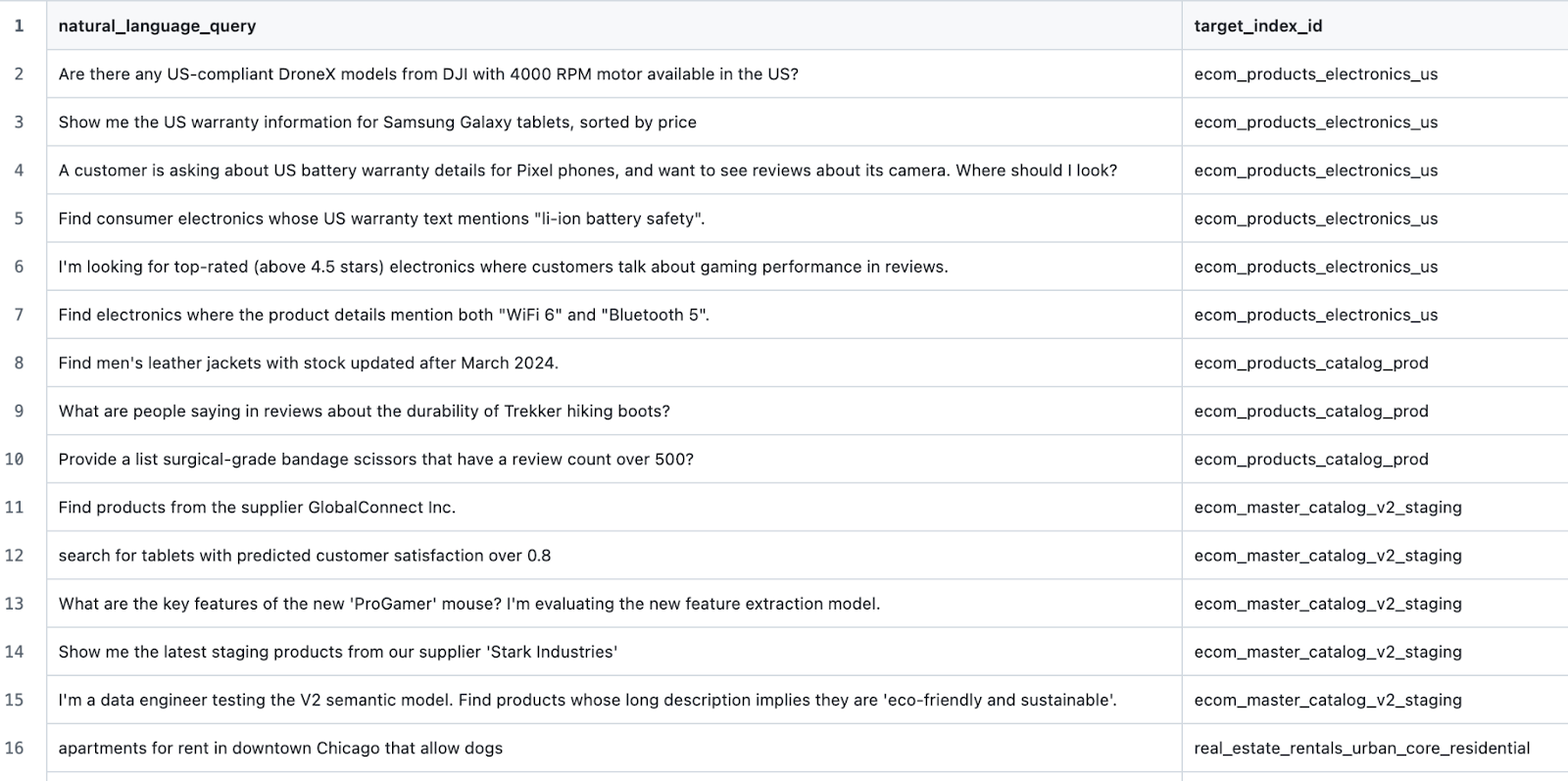
We generated seed indices for several different domains using this prompt. Then, for each generated domain, we generated a few more indices using this prompt (the goal here being to sow confusion for the LLM with hard negatives and difficult-to-classify examples). Next, we manually edited each generated index and its descriptions. Finally, we generated test queries using this prompt.This left us with sample data like:

and test cases like:
Crafting a test harness
The process from here was very simple. Script up a tool that could:
- Establish a clean slate with a target Elasticsearch cluster.
- Create all the indices defined in the target dataset.
- For each test scenario, execute the i
ndex_explorertool (handily, we have an Execute Tool API). - Compare the result index with the expected index, and capture the result.
- After finishing all test scenarios, tabulate the results.
Survey says…
The initial results were unsurprisingly mediocre.
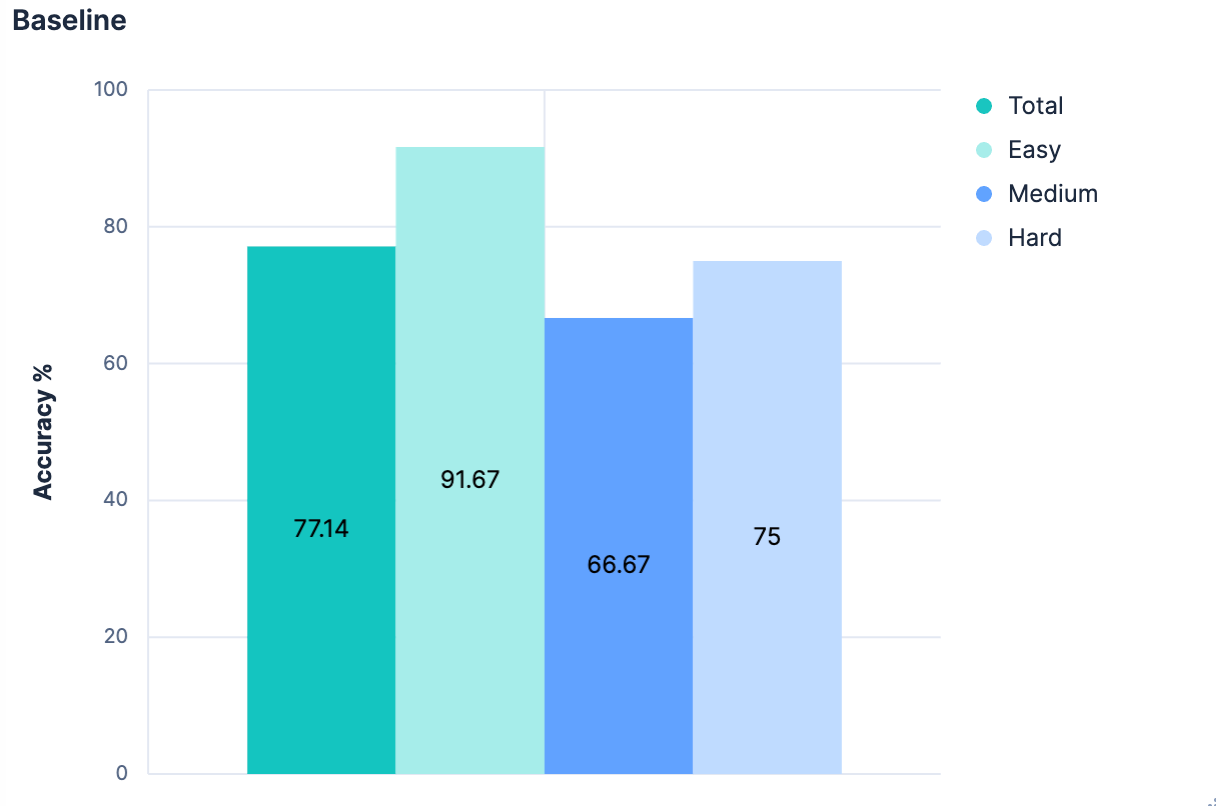
Overall, 77.14% accurate in identifying the right index. And this was in a “best case” scenario, where all indices have good, semantically-meaningful names. Anyone who’s ever done a `PUT test2/_doc/foo {...}` knows that your indices don’t always have meaningful names.
So, we have a baseline, and it shows plenty of room for improvement. It was now time for some science! 🧪
Experimentation
Hypothesis 1: Mappings will help
The goal here is to identify an index that will contain data relevant to the original prompt. And the part of an index that best describes the data that it contains is the index’s mappings. Even without grabbing any samples of the index contents, knowing that the index has a price field of type double implies that the data represents something to be sold. An author field of type text implies some unstructured language data. The two together might imply that the data is books/stories/poems. There are a lot of semantic clues we can derive just from knowing an index’s properties. So in a local branch, I adjusted our `.index_explorer` tool to send the full mappings of an index (along with its name) to the LLM to make its decision.
The result (from Kibana logs):
[2025-09-05T11:01:21.552-05:00][ERROR][plugins.onechat] Error: Error calling connector: event: error
data: {"error":{"code":"request_entity_too_large","message":"Received a content too large status code for request from inference entity id [.rainbow-sprinkles-elastic] status [413]","type":"error"}}
at createInferenceProviderError (errors.ts:90:10)
at convertUpstreamError (convert_upstream_error.ts:39:38)
at handle_connector_response.ts:26:33
at Observable.init [as _subscribe] (/Users/seanstory/Desktop/Dev/kibana/node_modules/rxjs/src/internal/observable/throwError.ts:123:68)...The tool’s initial authors had anticipated this. While an index’s mapping is a gold mine for information, it’s also a pretty verbose block of JSON. And in a realistic scenario where you’re comparing numerous indices (our evaluation dataset defines 20), these JSON blobs add up. So we want to give the LLM more context for its decision than just index names for all the options, but not so much as the full mappings of each.
Hypothesis 2: “Flattened” mappings (field lists) as a compromise
We started with the assumption that index creators will use semantically meaningful index names. What if we extend that assumption to field names as well? Our previous experiment failed because mapping JSON includes a LOT of crufty metadata and boilerplate.
"description_text": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
},
"copy_to": [
"description_semantic"
]
},The above block, for instance, is 236 characters, and defines just a single field in an Elasticsearch mapping. Whereas the string “description_text” is only 16 characters. That’s nearly a 15x increase in character count, without a meaningful semantic improvement in describing what that field implies about the available data. What if we were to fetch mappings for all indices, but before sending them to the LLM, “flatten” them just to a list of their field names?
We gave it a try.
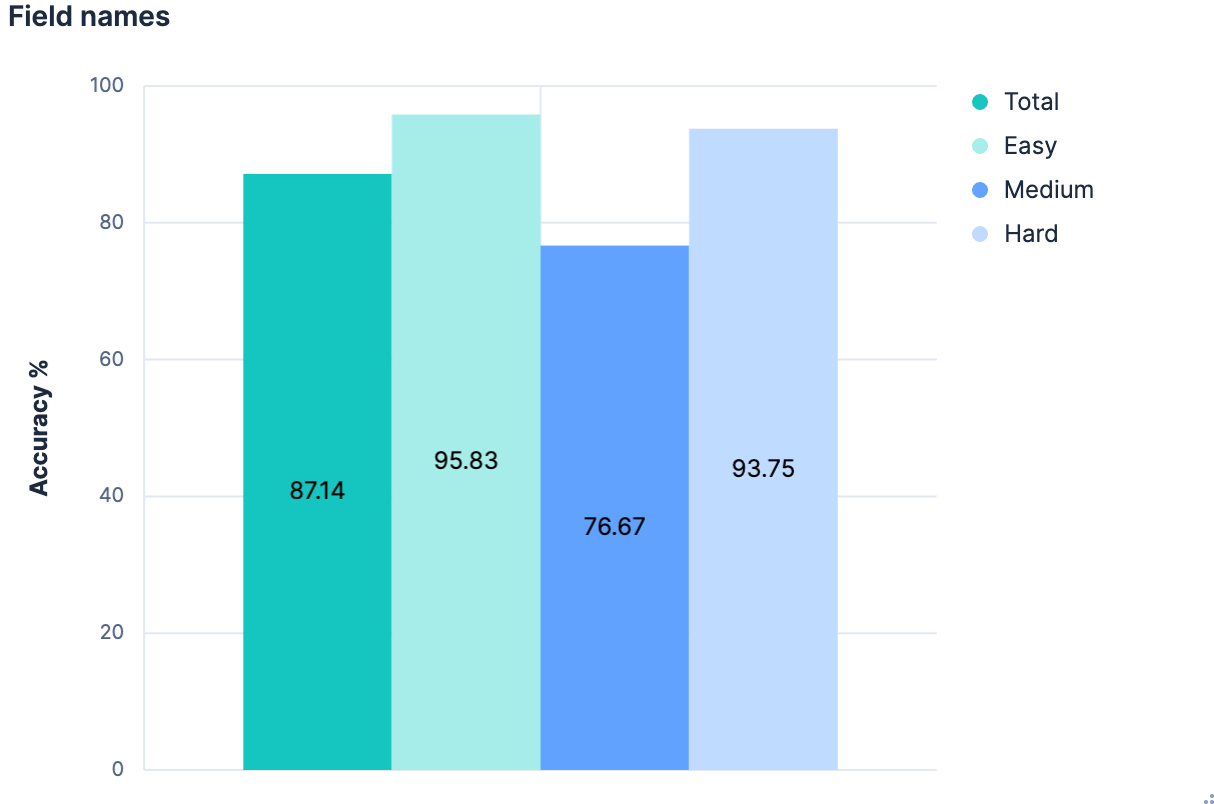
This is great! Improvements across the board. But could we do better?
Hypothesis 3: Descriptions in the mapping _meta
If just field names with no additional context caused that much of a jump, presumably adding substantial context would be even better! It’s not necessarily conventional for every index to have a description attached, but it is possible to add index-level metadata of any kind to the mapping’s _meta object. We went back to our generated indices, and added descriptions for every index in our dataset. As long as descriptions aren’t crazy long, they should use fewer tokens than the full mapping, and provide significantly better insights as to what data is included in the index. Our experiment validated this hypothesis.
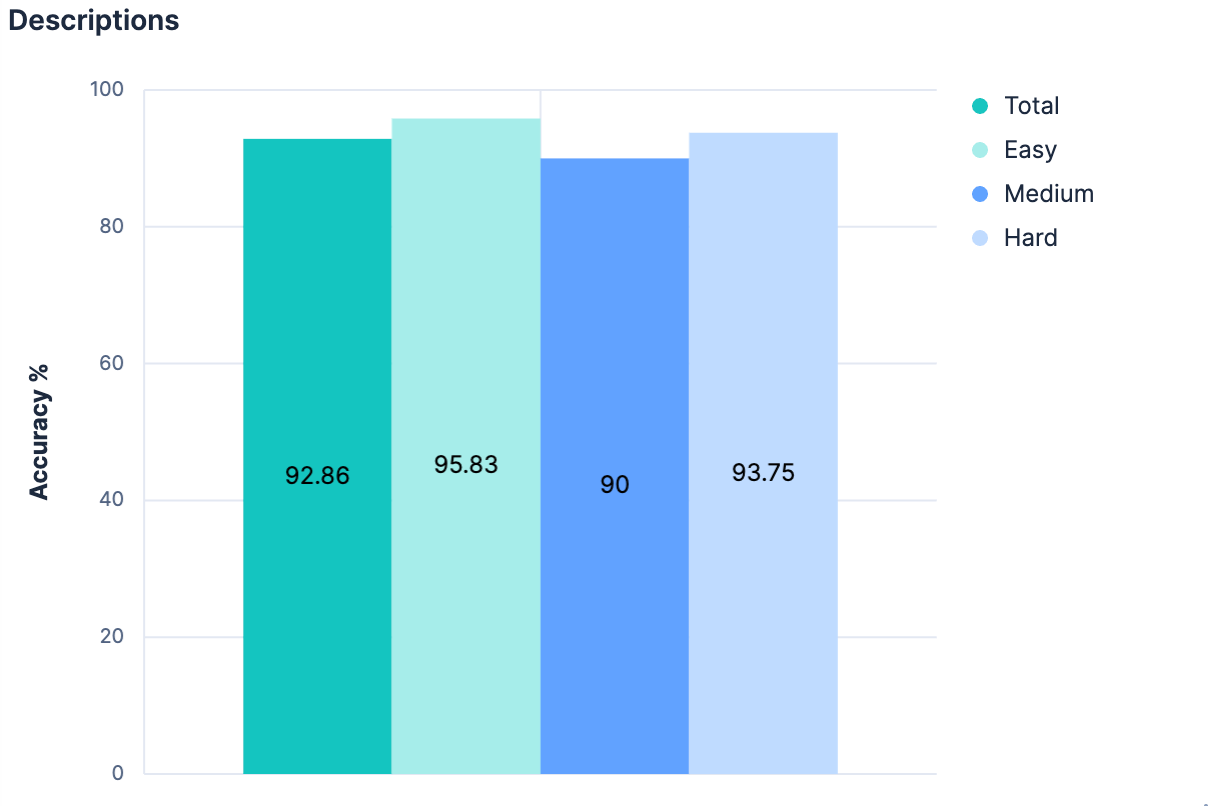
A modest improvement, and we’re now >90% accurate across the board.
Hypothesis 4: The sum is greater than its parts
Field names increased our results. Descriptions increased our results. So, utilizing both descriptions AND field names should show even better results, right?
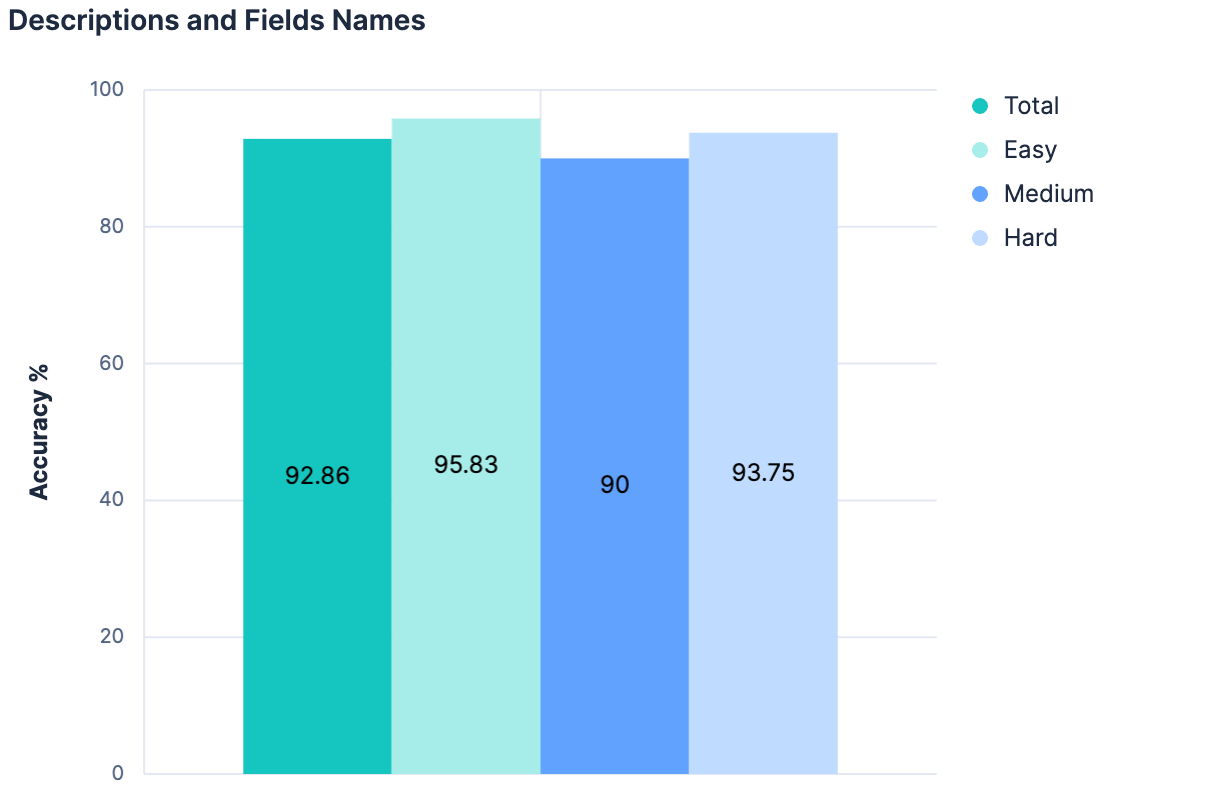
The data said “no” (no change from the previous experiment). The leading theory here was that since the descriptions were generated from the index fields/mappings to start with, there’s not enough different information between these two pieces of context to help add anything “new” when combining them. In addition, the payload we’re sending for our 20 test indices is getting quite large. The train of thought we’ve followed thus far is not scalable. In fact, there’s good reason to believe that none of our experiments thus far would work on Elasticsearch clusters where there are hundreds or thousands of indices to choose from. Any approach that linearly increases the message size sent to the LLM as the total number of indices increases is probably not going to be a generalizable strategy.
What we really need is an approach that helps us whittle down a large number of candidates to just the most relevant options…
What we have here is a search problem.
Hypothesis 5: Selection via semantic search
If an index’s name has semantic meaning, then it can be stored as a vector and searched semantically.
If an index’s field names have semantic meaning, then they can be stored as vectors, and searched semantically.
If an index has a description with semantic meaning, it, too, can be stored as a vector, and searched semantically.
Today, Elasticsearch indices don’t make any of this information searchable (maybe we should!) but it was pretty trivial to hack together something that could work around that gap. Using Elastic’s connector framework, I built a connector that would output a document for every index in a cluster. The output documents would be something like:
doc = {
"_id": index_name,
"index_name": index_name,
"meta_description”: description,
"field_descriptions" = field_descriptions,
"mapping": json.dumps(mapping),
"source_cluster": self.es_client.configured_host,
}I sent these documents to a new index where I’d manually defined the mapping to be:
{
"mappings": {
"properties": {
"semantic_content": {
"type": "semantic_text"
},
"index_name": {
"type": "text",
"copy_to": "semantic_content"
},
"mapping": {
"type": "keyword",
"copy_to": "semantic_content"
},
"source_cluster": {
"type": "keyword"
},
"meta_description": {
"type": "text",
"copy_to": "semantic_content"
},
"field_descriptions": {
"type": "text",
"copy_to": "semantic_content"
}
}
}
}This creates a single semantic_content field, where every other field with semantic meaning gets chunked up and indexed. Searching this index becomes trivial, with merely:
GET indexed-indices/_search
{
"query": {
"semantic": {
"field": "semantic_content",
"query": "$query"
}
}
}The modified index_explorer tool is now much faster, as it does not need to make a request to an LLM, but instead can request a single embedding for the given query and perform an efficient vector search operation. Taking the top hit as our selected index, we got results of:
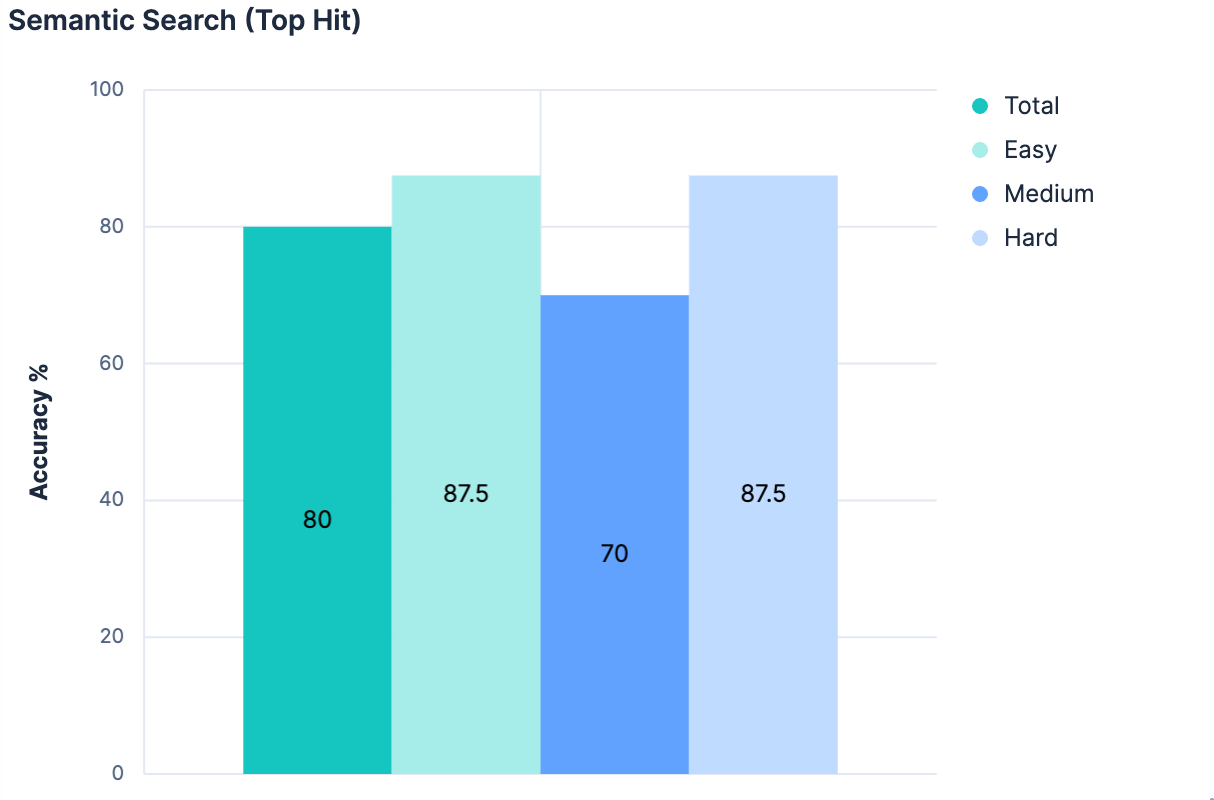
This approach is scalable. This approach is efficient. But this approach is barely better than our baseline. This is unsurprising though; the search approach here is incredibly naive. There’s no nuance. No recognition that an index’s name and description should carry more weight than an arbitrary field name that the index contains. No affordance to weight exact lexical matches over synonymous matches. However, building a highly nuanced query would need to assume a LOT about the data at hand. Thus far, we’ve already made some large assumptions about index and field names having semantic meaning, but we’d need to go a step further and start assuming how much meaning they have and how they relate to one another. Without doing so, we probably can’t reliably identify the best match as our top result, but can more likely say that the best match is somewhere in the top N results. We need something that can consume semantic information in the context in which it exists, comparing against another entity that may represent itself in a semantically distinct way, and judge between them. Like an LLM.
Hypothesis 6: Candidate set reduction
There were quite a few more experiments I’m going to gloss over, but the key breakthrough was letting go of the desire to pick the best match purely off of a semantic search, and instead leveraging semantic search as a filter to weed out irrelevant indices from the LLM’s consideration. We combined Linear Retrievers, Hybrid Search with RRF, and semantic_text for our search, limiting the results to the top 5 matching indices.
Then, for each match, we added the index’s name, description, and field names to a message for the LLM. The results were fantastic:
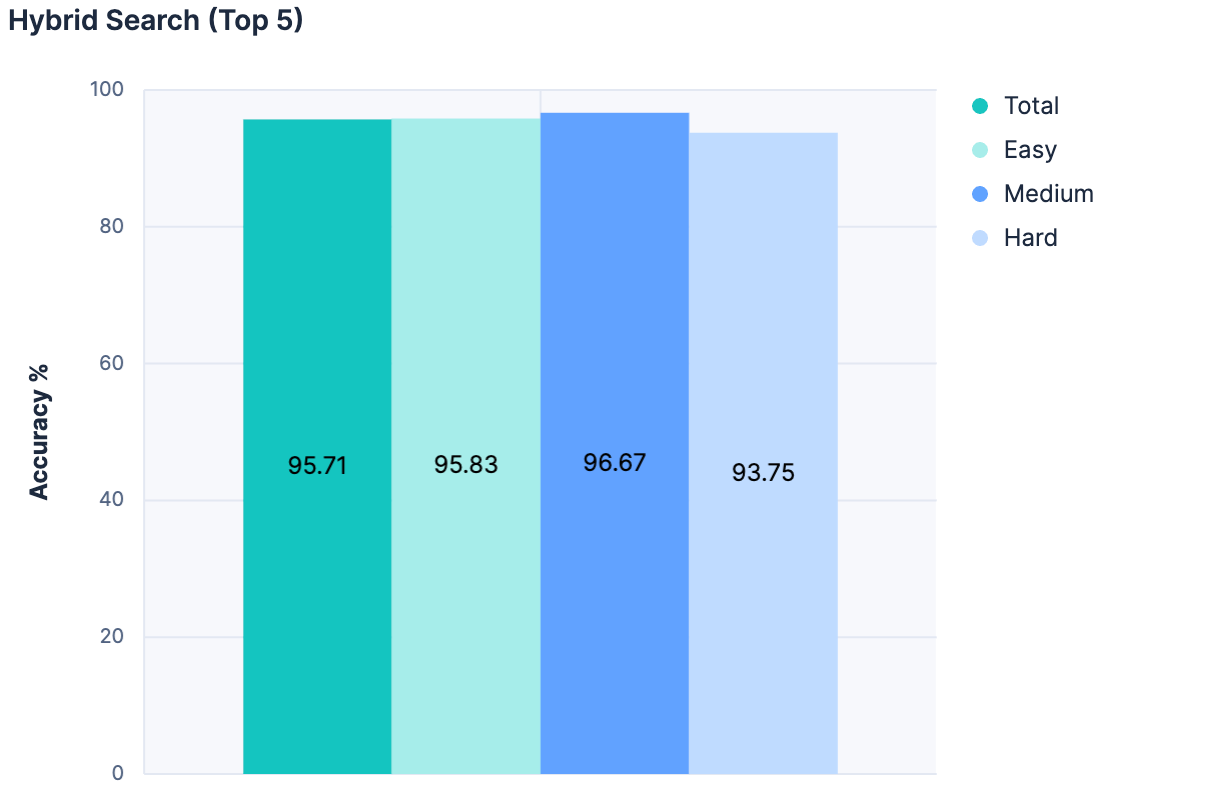
The highest accuracy of any experiment yet! And because this approach doesn’t increase the message size proportional to the total number of indices, this approach is far more scalable.
Outcomes
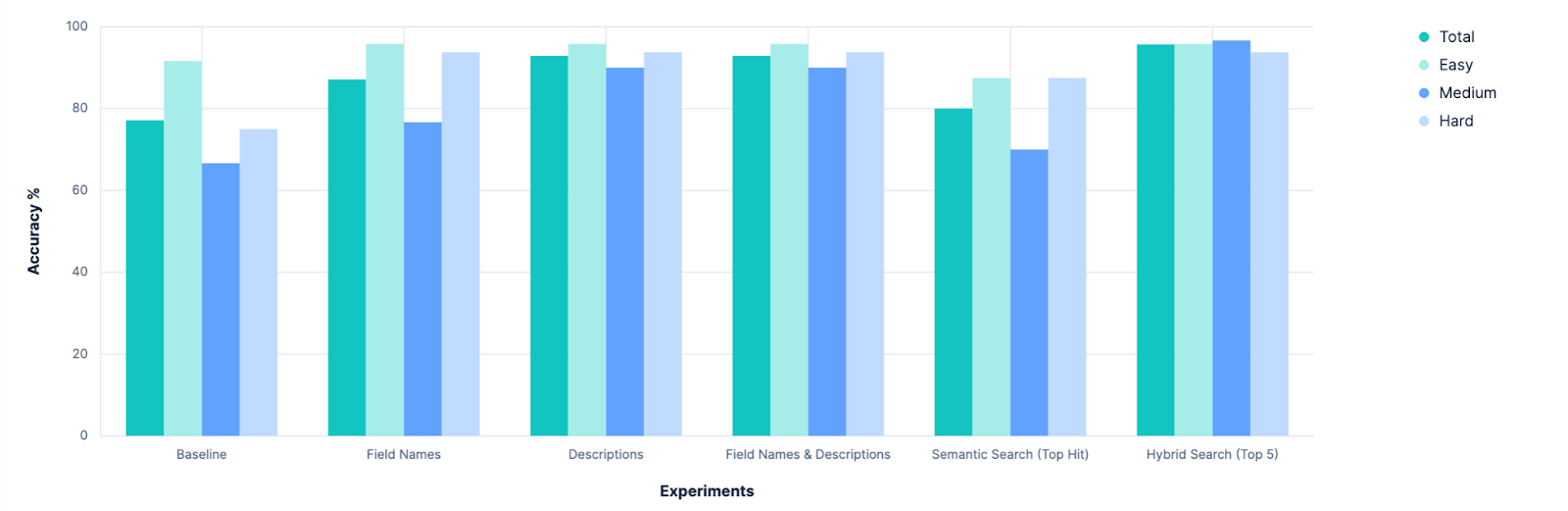
The first clear outcome was that our baseline can be improved upon. This seems obvious in retrospect, but before experimentation began, there was some serious discussion on whether we should abandon our index_explorer tool altogether and rely on explicit configuration from the user to limit the search space. While that’s still a viable and valid option, this research shows that there are promising paths forward towards automating index selection when such user inputs are unavailable.
The next clear outcome was that just throwing more description characters at the problem has diminishing returns. Before this research, we had been debating if we should invest in expanding Elasticsearch’s capability to store field-level metadata. Today, these meta values are capped at 50 characters, and there was an assumption that we’d need to increase this value in order to be able to derive semantic understanding of our fields. This is clearly not the case, and the LLM seems to do fairly well with just field names. We may investigate this further later, but it no longer feels pressing.
Conversely, this has given clear evidence for the importance of having “searchable” index metadata. For these experiments, we hacked an index-of-indices. But this is something we could investigate building directly into Elasticsearch, building APIs to manage, or at least establishing a convention around. We’ll be weighing our options and discussing internally, so stay tuned.
Finally, this effort has confirmed the value in us taking our time to experiment and make data-driven decisions. In fact, it’s helped us re-affirm that our Agent Builder product is going to need some robust, in-product evaluation capabilities. If we need to build a whole test harness just for a tool that picks indices, our customers will absolutely need ways to qualitatively evaluate their custom tools as they make iterative adjustments.
I’m excited to see what we’ll build, and I hope you are too!
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content

October 13, 2025
AI Agent evaluation: How Elastic tests agentic frameworks
Learn how we evaluate and test changes to an agentic system before releasing them to Elastic users to ensure accurate and verifiable results.
October 10, 2025
Creating an AI agent with n8n and MCP
Exploring how to build a trend analytics agent with n8n while leveraging the Elasticsearch MCP server.

October 9, 2025
Connecting Elastic Agents to Agentspace via A2A protocol
Learn how to use Agent Builder to expose your custom Elastic Agent to external services like Google's Agentspace with the A2A protocol.

September 30, 2025
CI/CD pipelines with agentic AI: How to create self-correcting monorepos
How our team introduced GenAI into CI pipelines to create self-correcting pull requests, automizing the update of hundreds of dependencies in large monorepos

September 25, 2025
Your first Elastic Agent: From a single query to an AI-powered chat
Learn how to use Elastic’s AI Agent builder to create specialized AI agents. In this blog, we'll be building a financial AI Agent.