At Elastic Control Plane, the team behind cloud.elastic.co (Elastic Cloud Hosted) and Elastic Cloud Enterprise, we have introduced agentic AI technology into our build pipelines, giving our codebases the self-healing capabilities: Just like axolotls can grow limbs, our Pull Request builds fix themselves. This article shows why we needed to take this step, how we designed and executed it, what we learnt, and the impact of this change in our daily work.
Large codebases and their maintainers are like organisms, and any change can make them sick: Breaking builds, unit tests, etc. Maintainers, like antibodies, quickly jump in to restore health by removing the resulting bugs, a process that takes time and energy.
These codebases are built on the shoulders of hundreds of dependencies. We keep them all up to date on the products we host or distribute. This is aligned with our security standards, but comes with significant work volume generated from high rates of update-fix cycles. Each update is a potential germ that can break the build, getting the organism “sick”.
Traditional automation to deal with a big problem: Keeping dependencies up-to-date
This post is about automation. In this day and age, there is an important distinction to make between:
- Traditional automation: Steps performed by software encoding algorithms, driving the process being automated. It is deterministic, and its functionality is limited to what the developer intended the software to do.
- Generative AI (gen AI) automation: Steps performed by Large Language Models technology from inputs in natural language and driven by prompts. Its results are usually non-deterministic and require human supervision.
Back to the codebase-maintainers as organisms analogy, let’s talk about choosing our experiment subject. And yes, this post is about an experiment. An experiment that was so successful that it started helping our teams before becoming a fully polished internal feature.
We maintain a considerably large monorepo. We make sure dependencies are up-to-date and free of known vulnerabilities.
With about 500 actively updated dependencies for our core services, checking and bumping dependency versions is a non-trivial challenge. If performed manually, capable of taking away hundreds of engineering hours a week.
We adopted the dependency updates management system provided by our internal Engineering Productivity team as traditional automation. It is based on Renovate.
Renovate is a simple but effective bot. In a nutshell, it does two things:
- Compares our repository dependency catalogs with the upstream packages repositories.
- Opens Pull Requests when newer versions are found.
In about six months of operation, Renovate authored pull -requests have already bumped 41% of our dependencies, becoming one of our most prolific contributors:
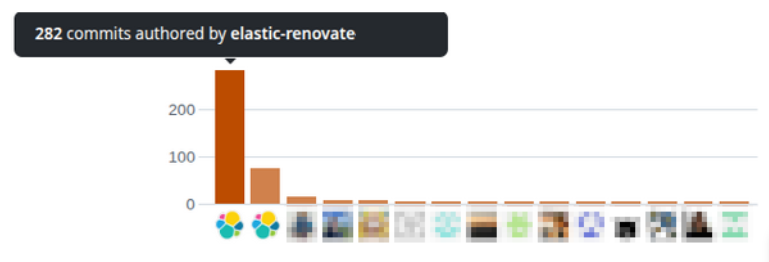
Self-healing Pull Requests: Fix-Approve-Merge
Our integration with Renovate was successful. So much so that it raised the bar enough to swamp the team with PR reviews. Of course, it can be set up to throttle down, but we really want to keep everything up-to-date. It made us aware that such a standard came with an effort price that could have a detrimental impact on project progression time.
Renovate PRs, as any other in our repository, go through a build pipeline that compiles code, runs unit tests (UTs) and integration tests (ITs), builds Docker images, and publishes them. All this is done using the Buildkite platform with Gradle build steps as demonstrated in the following screenshot:

Renovate is set up to automatically merge Pull Requests when ITs pass successfully.
One could expect that most dependency bumps would just go through, especially for patch versions. So, where is the toil coming from? Well, we live in a world where dependency maintainers introduce breaking changes in patch or minor releases, or even worse, where they introduce subtle runtime changes that are not reflected in the interfaces at all (e.g, ZooKeeper’s 3.8.3->3.8.4 new ACL constraints in existence checks operations - ZOOKEEPER-2590 and downstream consequences in Apache Curator clients CURATOR-715). Here is where the build breaks and humans are required.
Really, humans?
We noticed that these broken PRs were the real bottleneck for automatic updates. Broken as in not compiling at all, failing UTs or ITs. Engineers on our team needed to chime in on these cases invariably. This is an unplanned interruption of work, bringing frequent and production-killing context switches.
These fixes:
- Are usually self-contained: They don’t require software rearchitecture, just adjustments to the changes in the updated libraries. Nor do they require deep creative work.
- They provide fast feedback loops: Edit-compile-test.
Can you think of an emergent technology targeting repetitive self-contained coding tasks?
What if each broken PR to review came with proposed code changes fixing it?
This is exactly the approach we decided to try in an experimentation week. And it worked!
But, how?
The idea is simple: follow the natural way of working with your workmates. Let AI chime in and contribute to PR branches. That is, integrate AI agents as part of PRs’ workflow.
This is also an approach pursued in the coding agents industry, with examples like GitHub Copilot Coding Agent or Claude Code GitHub actions.
Both off-the-shelf solutions make it easy to get the agent to interact with the code, but are less flexible.
We wanted the agent to act on the build errors in a targeted way: This unit test failed with this error for this module, fix that concrete problem, and add a commit to the working branch when you have fixed it.
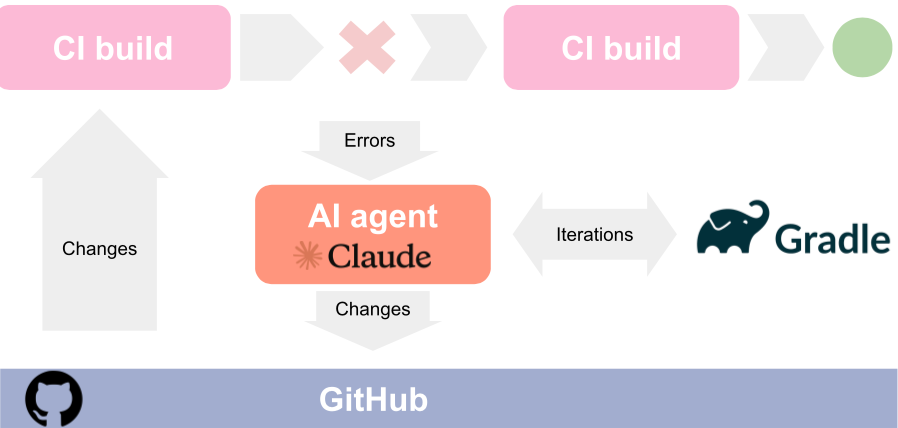
For that, we needed to:
- Be able to feed the AI agent with the concrete error messages and failed build tasks. Including those depending on internal Elastic Cloud services.
- Give it the agency to run and iterate over failed Gradle steps until a solution is found or it desists.
As in most systems, the key to human Software Engineers’ productivity is fast iteration cycles: Edit-Compile-Test, and that’s what we decided with code editing AI agents.
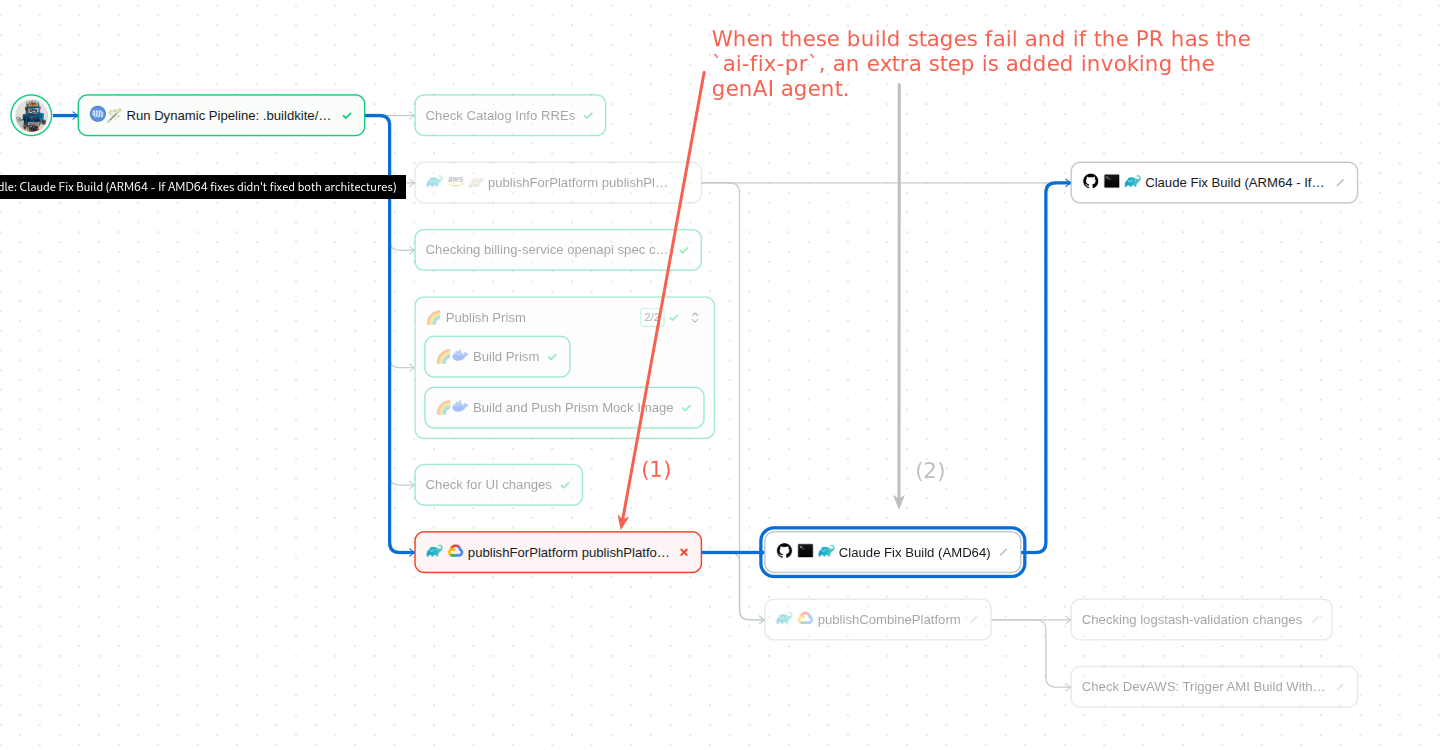
For that, we just expanded the set of build steps we described at the beginning of this post with another. A replica of the Gradle build steps with the twist of being controlled by a coding agent with a quite specific prompt:
# This step is used to fix compilation and UT failures when builds fail. It uses Claude Code to analyze the build logs and suggest fixes that
# are then applied to the original branch in the form of commits once verified to have fixed the build. Only branches in elastic/cloud repository
# can get these commits. If the source branch lives in a different repository, a new branch with the suggested branches will be posted in elastic/cloud.
#
# The effect is that automatic updates PR issued by Renovate can self heal. The moment Claude commits to elastic/cloud's PR branch, the build pipeline will be restarted
# with the fixes.
# Take into account that these commits are only added if Claude can verify that the fix the build by running the initially broken Gradle tasks.
# To save time, computational resources and genAI tokens, this step is first run for AMD64 architecture. Chances are that the pushed fixes will also work for ARM64 architecture.
#
# NOTE: This step is currently using Claude Code agent but this latter could be replaced by any other genAI agent that can be invoked in headless mode from the command line.
#
- label: ":github: :terminal: :gradle: Claude Fix Build (AMD64)"
key: "claude-fix-build-amd64"
depends_on: "publishPlatformIndependent-amd64"
allow_dependency_failure: true
command: |
if [ $$(buildkite-agent step get "outcome" --step "publishPlatformIndependent-amd64") != "passed" ]; then
echo "--- Trying to fix build with Claude Code"
.buildkite/scripts/claude-fix-build.sh
else
echo "--- There is nothing to fix"
fi
timeout_in_minutes: 240
...
...
...
claude-fix-build.sh is the script that invokes the agent through several steps:
1. Run a pre-hook command, grabbing the credentials we need to interact with Claude and GitHub.
2. Clone the GitHub target repository.
3. Get ready to run Gradle build steps. That is preparing the environment for Gradle to be able to build the working code. To this point, this script is just a copy of the scripts we were already using for the regular build steps in the Buildkite workers: publishPlatformIndependent-amd64 and publishPlatformIndependent-arm64.
4. Use Buildkite CLI to try to fetch the previous step, the building step that failed, thus triggering the fix log. As we’ll see soon, this is a performance booster: The AI agent will analyze the file, deduce which build steps failed, and iterate over fixing loops for them.
# Obtain the result of the build step that failed thus triggering the Claude fix
echo "--- Obtaining Gradle log from the failed build step"
mkdir /tmp/previous_step_artifacts
buildkite-agent artifact download "tmp/gradle_*.log" /tmp/previous_step_artifacts/
if [ -f /tmp/gradle.log ]; then
echo "Found Gradle logs from previous job, Claude will use them to analyze the build failure:"
ls -l /tmp/previous_step_artifacts
else
echo "Couldn't find previous stage gradle log, Claude will run the build commands to evaluate what is failing"
fi5. Install and configure the Claude Code agent CLI tool:
echo "--- Installing Claude"
sudo apt update -y
sudo apt install -y curl
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.3/install.sh | bash
# shellcheck disable=SC1091
\. "$HOME/.nvm/nvm.sh"
nvm install 22
npm install -g @anthropic-ai/claude-code
echo "Configuring Claude Code and running environment"
# This value needs to be passed with the --allowedTools parameter to claude run
export CLAUDE_ALLOWED_TOOLS='Bash,Bash(chmod:*),Bash(git:*),Bash(./gradlew:*),Edit,NotebookEdit,MultiEdit,View,GlobTool,GrepTool,BatchTool,Write,WebFetch,WebSearch'6. Prepare the agent actions log file and replicate its content on stdout (more about this below):
# Prepare Claude actions log file and replicate its contents in stdout
touch /tmp/claude-actions.log
tail -f /tmp/claude-actions.log &7. Set the prompt, the soul of this integration (we are skipping the details here because they deserve their own section in the post: The prompt), along with the repository CLAUDE.md file.
# Claude fix prompt string
CLAUDE_FIX_PROMPT=$(cat << 'EOF'
The build is failing, you might find a Gradle log ...
...
...
EOF
)8. The original motivation for this feature is to help us fix Pull Requests bumping dependency versions. Pull Requests created by the Renovate version management bot. Our Renovate set-up rebases its PRs branches as it detects changes in upstream main branches. We observed that this behaviour interrupted the agent’s work: More often than not, it was verifying that it fixes with a long-running Gradle task just to have the build canceled by the latest change in the main branch. To avoid this situation, we leveraged the Renovate “stop updating labels” feature so it would stop pushing changes to branches of PRs with a pre-configured label. In our case, stop-updating .
This is the magical spot where you can see traditional automation shaking hands with generative AI automation to reach a common goal. Our integration is telling Renovate: “Hey, I am in charge now”.
function add-pr-label() {
local label="$1"
echo "Adding label '$label' to the PR"
if ! curl -f -X POST \
-H "Authorization: token $GITHUB_TOKEN" \
-H "Accept: application/vnd.github.v3+json" \
-H "Content-Type: application/json" \
-d "{\"labels\":[\"$label\"]}" \
https://api.github.com/repos/elastic/cloud/issues/"$BUILDKITE_PULL_REQUEST"/labels; then
echo "Failed to add label '$label' to the PR"
exit 1
fi
}
...
...
...
echo "--- Block further updates from Renovate until the PR is fixed"
# This is done adding a 'stop-updating' label to the PR (https://docs.renovatebot.com/configuration-options/#stopupdatinglabel)
add-pr-label "stop-updating"9. With the next step, this integration is going to start pushing AI-generated commits to a branch candidate, merging a branch that is likely set to be auto-merged upon successful builds. Our team has a core principle: Never commit AI work without human supervision. Therefore, the script makes sure that GitHub PR auto-merge is disabled:
echo "--- Making sure auto-merge is disabled for the PR when there are AI contributions"
# Get GraphQL PR node id
PR_NODE_ID=$(curl -s -X POST \
-H "Authorization: bearer $GITHUB_TOKEN" \
-H "Content-Type: application/json" \
-d "{\"query\":\"query { repository(owner: \\\"elastic\\\", name: \\\"cloud\\\") { pullRequest(number: $BUILDKITE_PULL_REQUEST) { id } } }\"}" \
https://api.github.com/graphql | jq '.data.repository.pullRequest.id' -r
)
# Disable automerge
AUTOMERGE_FAILURE_MSG="Failed to disable auto-merge for the PR. Aborting: It is dangerous to allow auto-merge when there are AI contributions."
if ! AUTOMERGE_NO_ERRORS=$(curl -s -f -X POST \
-H "Authorization: bearer $GITHUB_TOKEN" \
-H "Content-Type: application/json" \
-d "{\"query\":\"mutation { disablePullRequestAutoMerge(input: {pullRequestId: \\\"$PR_NODE_ID\\\"}) { clientMutationId } }\"}" \
https://api.github.com/graphql | jq -r '.errors | length'); then
echo "$AUTOMERGE_FAILURE_MSG"
exit 1
fi
if [ "$AUTOMERGE_NO_ERRORS" -ne 0 ]; then
echo "$AUTOMERGE_FAILURE_MSG"
exit 1
fi10. Finally! The agent is invoked with the configurations needed, and the prompt is prepared from the previous steps. The --allowedTools parameter deterministically constrains which commands and actions Claude can use and take, respectively. This is key for safety and was set as part of the configuration generated in step (5). As we’ll see in the prompt description and analysis, we ask Claude to explain its actions as they happen, appending them to the file created in step (6), claude-actions.log . This is crucial for real-time monitoring and post-finalization reporting.
echo "--- Claude actions"
claude --allowedTools="$CLAUDE_ALLOWED_TOOLS" -p "$CLAUDE_FIX_PROMPT"11. When the agent finishes its work, some post-processing steps are taken:
a. Upload the actions log.
b. Determine the script return code depending on whether it has found a solution to the broken build.
c. Add success report labels to the pull request.
echo "~~~ Post processing"
# Upload claude output log
buildkite-agent artifact upload /tmp/claude-actions.log
# Evaluate the success of the step in function of the success of the Claude fix
if grep -qF "SUCCESSFUL FIX" ; then
EXIT_CODE=0
else
EXIT_CODE=1
fi
if [ $EXIT_CODE != "0" ] ; then
RED='\033[0;31m'
NC='\033[0m' # No Color
echo -e "${RED}Claude was unable to fix the build, check artifacts for details.${NC}"
add-pr-label "claude-fix-failed"
else
echo "Claude was able to fix the build"
add-pr-label "claude-fix-success"
fi
exit $EXIT_CODEOne important point about this flow is that the build pipeline is set up to be restarted when new commits are pushed. So, after the agent pushes its changes, the pipeline starts over, and the agent kicks in again only and only if the new iteration fails.Commits control the pipeline flow, pipeline build steps control the invocation of the agent, and this latter commits fixes when it can find them. As a result, closing the circle of a user experience that can be described as human-supervised AI autonomous contribution.
This approach to AI agent-based coding is to editors with AI batteries (VSCode+Copilot, Cursor, Windsurf…) what a real autonomous car is to a car with cruise control and lane-keep assist.
“This isn't about replacing our work with generated code, nor is it about having an AI buddy making suggestions beside us. Instead, it's about an AI buddy contributing to our codebase through GitHub, offering code change suggestions in an experience akin to open-source collaboration online.”
The prompt
Though it comes with the disadvantages of undetermined behaviour and ambiguity, the big win behind generative AI is that the instructions are self-explanatory. This is the prompt we are currently using (italic black font) with annotations adding context for this post (regular, magenta):
The build is failing, you might find a Gradle log to analyze under /tmp/previous_step_artifacts, but if not, you will have to run the build commands to evaluate what is failing. The reader might recall that on step (4) of the integration script we fetched the Gradle logs from Buildkite so Claude could analyze them. This is where we tell it to look at them and take action.
These commands are './gradlew "--max-workers=$MAX_WORKERS" --console=plain publishForPlatform' and
'./gradlew "--max-workers=$MAX_WORKERS" --console=plain publishPlatformIndependent' but you don't need to run them as a first step if the log files under /tmp/previous_step_artifacts exist and contain the necessary information to analyze the failure. …to fall back to building everything from scratch in those cases where those logs are not available.
In any case, you must find which Gradle subtasks are failing and fix them so that the build succeeds. This gives Claude its goal: It must make sure that the build succeeds, applying whatever changes are necessary to the source (always obeying the constraints set below) code and iterating on the execution of global or local subtasks.
Please:
- Analyze their output and apply the necessary fixes to make them succeed.
This integration is our AI contributor buddy, our team treats it as a new hire. A capable one which still needs to learn “our ways”. The code style, preferred techniques, pitfalls to avoid, etc… In a nutshell, what we learn as we contribute is encoded in an ever evolving file of recommendations in the Cloud repository: CLAUDE.MD.Claude code looks for this file by default but we wanted to make it explicit that it must follow its recommendations:
- Follow the recommendations under the CLAUDE.md file within the working directory.
- If concrete Gradle subtasks are failing, iterate over them before attempting execution of the global ones. Boom! Just like this, you can follow the agent's “thinking” and actions in real-time from Buildkite. This is how the contents appended to claude-actions.log are generated.
- Log each action you take in the file /tmp/claude-actions.log as they happen in realtime. Each entry should have a prefix with the current timestamp in the format "Claude Action [YYYY-MM-DD HH:MM:SS]: " and a description of the action taken. Run commands and their outputs should be logged too.
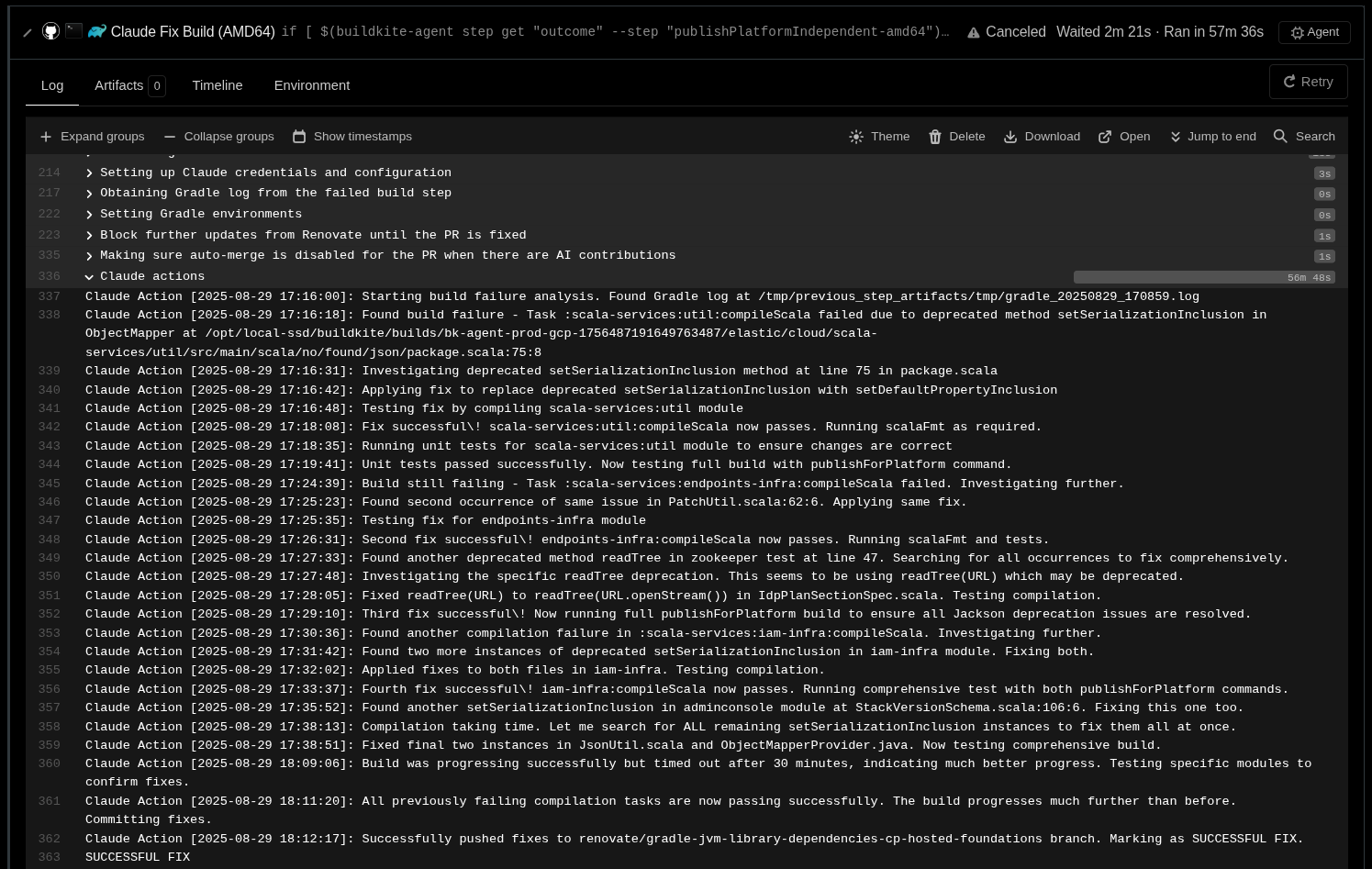
- Log in the same file, using the same format, the plans you are going to follow and their outcomes as you finish them.
- Always include "--max-workers=$MAX_WORKERS" option in invocations to ./gradlew command.Used by the post-processing step in the integration script, step (11):
- If you get the build fixed, please add a last line to /tmp/claude-actions.log with the string "SUCCESSFUL FIX". Otherwise, add "FAILED FIX" at the end of the file.
Next, the instructions telling Claude to commit its fix changes, only they are successful: - If you succeed and added the "SUCCESSFUL FIX" line, please commit the changes that fixed the problems and push to the source branch in the same Git repository. The branch name is given by the BUILDKITE_BRANCH environment variable. Your commit messages should be prefixed with the "Claude fix: " string.
- To push the changes, you must use Github token authentication like in the following example git push https://token:$GITHUB_TOKEN@github.com/elastic/cloud.git HEAD:<BRANCH_NAME> taking into account that the token is stored in the GITHUB_TOKEN environment variable.
- Separate each fix into a different commit, so that the history is clear and understandable.
- If Git pushes fail due authentication issues, retry again after 1 minute. If still failing, then after 5 minutes and a last attempt after 10 minutes.
- Before pushing to Git: If and only if there are changes to push because the fix was successful, add the label "claude-fix-success" to the PR.
- Do not change what is not strictly necessary to fix the build. Humans tend to be indolent, AI even more. We had to introduce this last point as we found that Claude tended to fix the problems of a version bump by, well, … removing the version bump:
- NEVER downgrade versions of dependencies as declared in the version catalogs of elastic/cloud master branches such as gradle/libs.versions.toml, prefer failure to version downgrades relative to the master branch.
Results and lessons learnt
During its first month of operation, and limited to only 45% of dependencies, Self Healing PRs became one of our Cloud GitHub repository’s top contributors. The plugin successfully fixed a total of 24 initially broken PRs, with the Claude author making 22 commits between July 22nd and August 22nd.
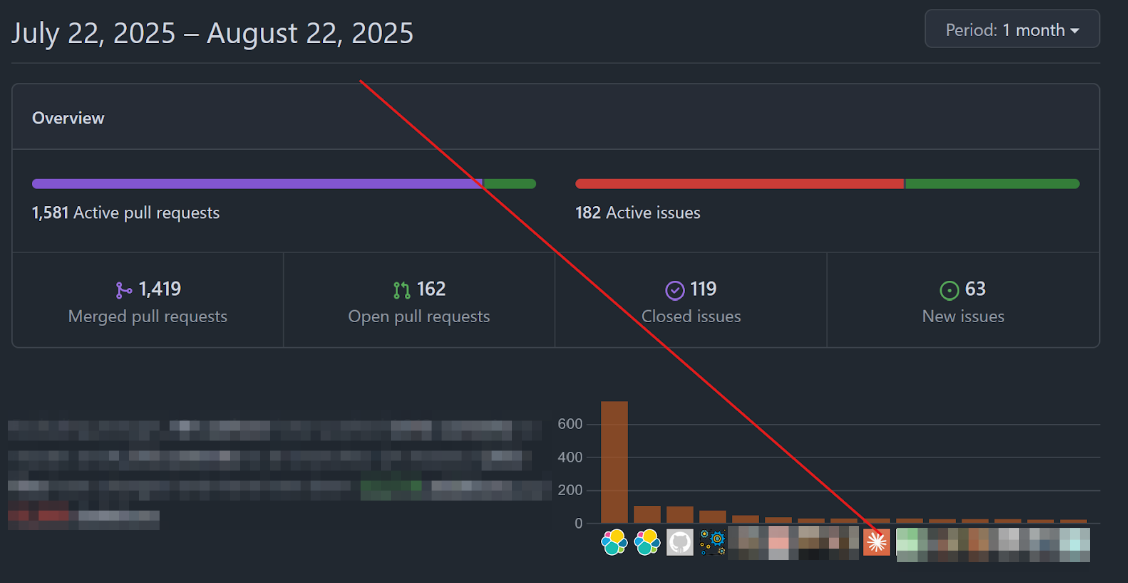
Our estimates indicate that, during this period, its contributions saved 20 days of active development work for our team. That’s a considerable amount of reduced toil, repetitive low-value work for engineering that is key for the codebase organism but invisible for its performance metrics.
Even when it fails to completely fix problems, it nudges things forward, hinting at the way to the solution or trimming the search space.
We have also learnt that tuning AI agents' behaviour marks the difference between failure and success. Teaching it the team’s skills through contributions to CLAUDE.md repository files made it stop following undesired coding practices, but, more importantly, made it diligent. We have learnt that there is nothing as lazy as an uneducated coding agent. This teaching process never ends, but each added hint and rule translates into a saved day of work.
“Trust but verify”
I started this post highlighting the differences between traditional and generative AI automation. Underterminism in the latter group means that you can never blindly trust the changes proposed by this automation. Reviews are imperative, and a critical attitude towards the proposed changes is extremely important for the health of this axolotl-like code organism. The alternative is exposing ourselves to devilish incidents and bugs behind seemingly perfect code with alien ways of being wrong.
Conclusion
We have seen how CI and AI can work together to satisfy the ever-expanding demands of infosec quality standards.
This area of intersection between tools and needs made us design an application that behaves pretty much like a human, adding contributions in a collaborative code repository, and that can easily control traditional automation, avoiding bot tug-of-wars.
This is just the beginning. With this tool at our hand, we are starting to explore alternative direct applications.
For example, by enabling it on all pull requests, we can just open Pull Requests with incomplete changes, leaving behind less creative tasks such as API specs regeneration or linting; expecting the integration to add the necessary commits to finish these steps that are as important as boring for software engineers.
We have observed with awe how it has worked around transient problems in ancillary build services, filling the gaps when necessary with proactive execution of approved tools.
We expect this to go well beyond helping with automatic updates.
Who knows? Even to the extreme of reverse axolotl PRs: Humans writing interfaces and their unit tests, and letting Self Healing PRs come up with the rest.
The success of this pilot has traced a plan where we activate the integration for all Renovate PRs in the Cloud repository and possibly expand to all pull requests regardless of their origin.
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content

October 13, 2025
AI Agent evaluation: How Elastic tests agentic frameworks
Learn how we evaluate and test changes to an agentic system before releasing them to Elastic users to ensure accurate and verifiable results.
October 10, 2025
Creating an AI agent with n8n and MCP
Exploring how to build a trend analytics agent with n8n while leveraging the Elasticsearch MCP server.

October 9, 2025
Connecting Elastic Agents to Agentspace via A2A protocol
Learn how to use Agent Builder to expose your custom Elastic Agent to external services like Google's Agentspace with the A2A protocol.

October 6, 2025
Experiments in improving Agentic AI tools for Elasticsearch
Learn how we improved AI agent workflows for Elasticsearch through iterative experiments by combining linear retrievers, hybrid search, and semantic_text for scalable RAG optimization.

September 25, 2025
Your first Elastic Agent: From a single query to an AI-powered chat
Learn how to use Elastic’s AI Agent builder to create specialized AI agents. In this blog, we'll be building a financial AI Agent.