Vector search provides the foundation when implementing semantic search for text or similarity search for images, videos, or audio. With vector search, the vectors are mathematical representations of data that can be huge and sometimes sluggish. Better Binary Quantization (hereafter referred to as BBQ) works as a compression method for vectors. It allows you to find the right matches while shrinking the vectors to make them faster to search and process. This article will cover BBQ and rescore_vector, a field only available for quantized indices that automatically rescores vectors.
All complete queries and outputs mentioned in this article can be found in our Elasticsearch Labs code repository.
Why would you implement this in your use case?
Note: for an in-depth understanding of how the mathematics behind BBQ works, please check out the “Further learning” section below. For the purposes of this blog, the focus is on the implementation.
While the mathematics is intriguing and it is crucial if you want to fully grasp why your vector searches remain precise. Ultimately, this is all about compression since it turns out that with the current vector search algorithms you are limited by the read speed of data. Therefore if you can fit all of that data into memory, you get a significant speed boost when compared to reading from storage (memory is approximately 200x faster than SSDs).
There are a few things to keep in mind:
- Graph-based indices like HNSW (Hierarchical Navigable Small World) are the fastest for vector retrieval.
- HNSW: An approximate nearest neighbor search algorithm that builds a multi-layer graph structure to enable efficient high-dimensional similarity searches.
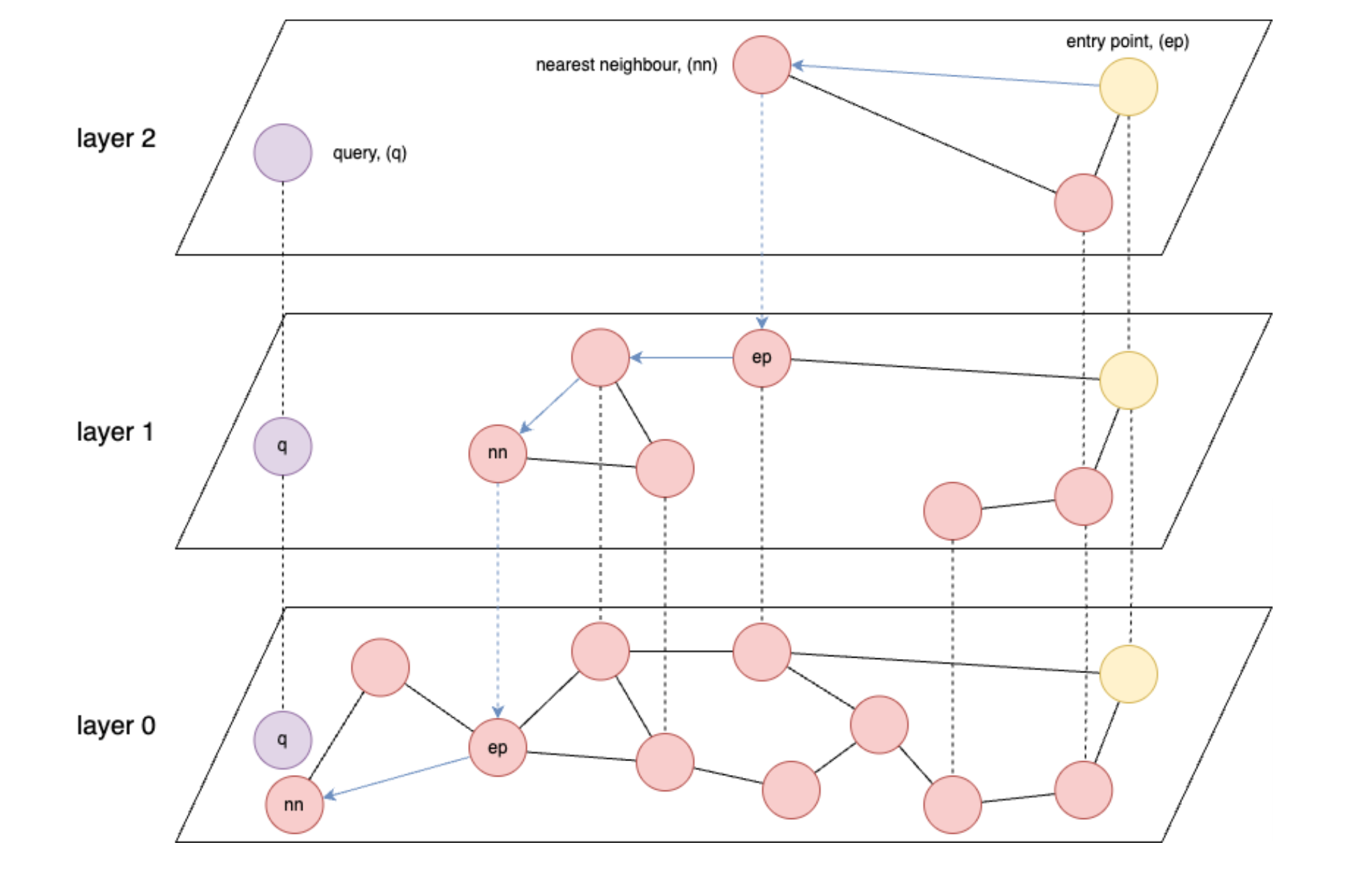
- HNSW is fundamentally limited in speed by data read speed from memory, or in the worst case, from storage.
- Ideally, you want to be able to load all of your stored vectors into memory.
- Embedding models generally produce vectors with float32 precision, 4 bytes per floating point number.
- And finally, depending on how many vectors and/or dimensions you have, you can very quickly run out of memory to keep all of your vectors in.
Taking this for granted, you see that a problem arises quickly once you start ingesting millions or even billions of vectors, each with potentially hundreds or even thousands of dimensions. The section entitled “Approximate numbers on the compression ratios” provides some rough numbers.
What do you need to get started?
To get started, you will need the following:
- If you are using Elastic Cloud or on-prem, you will need a version of Elasticsearch higher than 8.18. While BBQ was introduced in 8.16, in this article, you will use
vector_rescore, which was introduced in 8.18. - Additionally, you will also need to ensure there is a machine learning (ML) node in your cluster. (Note: an ML node with a minimum of 4GB is needed to load the model, but you will likely need much larger nodes for full production workloads.)
- If you are using Serverless, you will need to select an instance that is optimized for vectors.
- You will also need a base level of knowledge regarding vector databases. If you aren’t already familiar with vector search concepts in Elastic, you may want to first check out the following resources:
Implementation
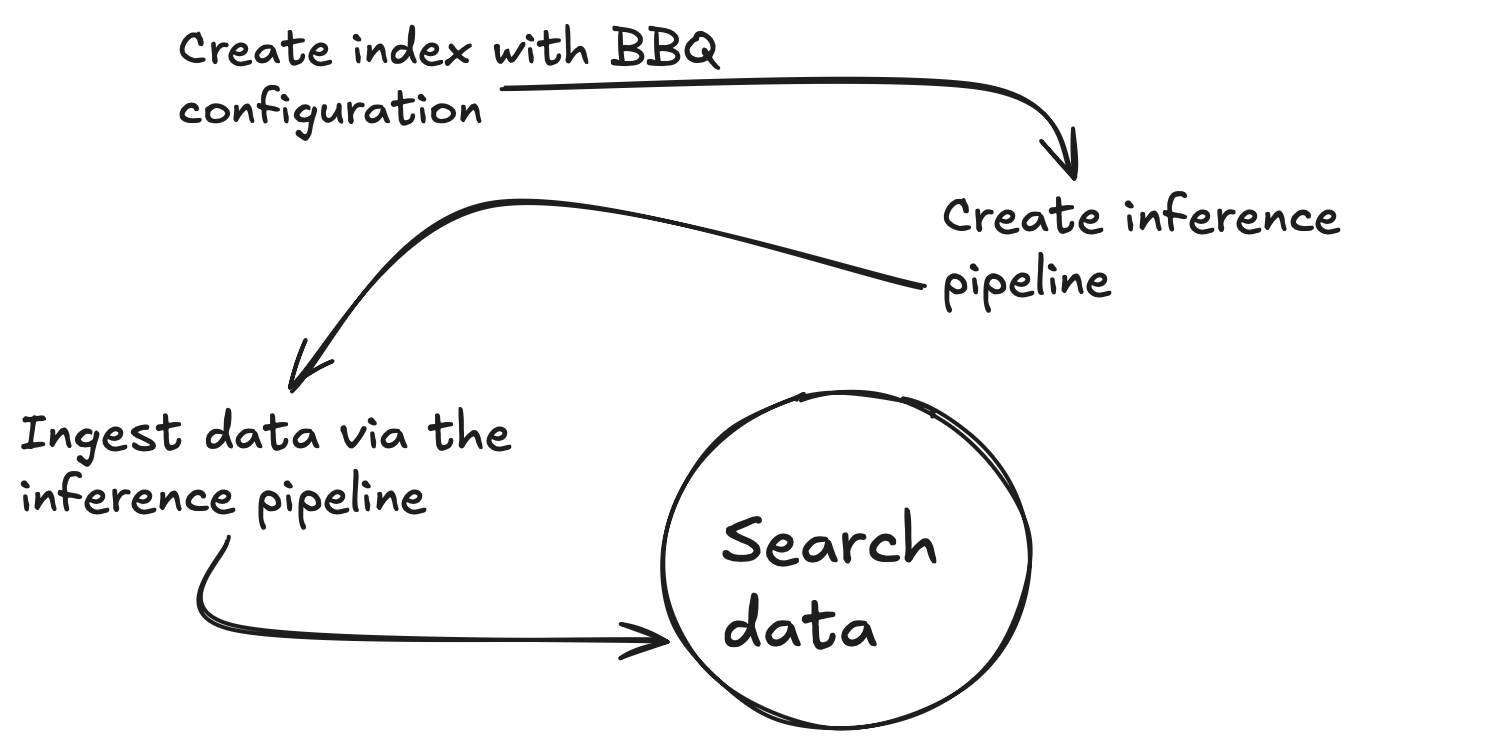
To keep this blog simple, you will use built-in functions when they are available. In this case, you have the .multilingual-e5-small vector embedding model that will run directly inside Elasticsearch on a machine learning node. Note that you can replace the text_embedding model with the embedder of your choosing (OpenAI, Google AI Studio, Cohere and plenty more. If your preferred model is not yet integrated, you can also bring your own dense vector embeddings.)
First, you will need to create an inference endpoint to generate vectors for a given piece of text. You will run all of these commands from the Kibana Dev Tools Console. This command will download the .multilingual-e5-small. If it does not already exist, then it will set up your endpoint; this may take a minute to run. You can see the expected output in the file 01-create-an-inference-endpoint-output.json in the Outputs folder.
PUT _inference/text_embedding/my_e5_model
{
"service": "elasticsearch",
"service_settings": {
"num_threads": 1,
"model_id": ".multilingual-e5-small",
"adaptive_allocations": {
"enabled": true,
"min_number_of_allocations": 1
}
}
}Once this has returned, your model will be set up and you can test that the model works as expected with the following command. You can see the expected output in the file 02-embed-text-output.json in the Outputs folder.
POST _inference/text_embedding/my_e5_model
{
"input": "my awesome piece of text"
}If you run into issues around your trained model not being allocated to any nodes, you may need to start your model manually.
POST _ml/trained_models/.multilingual-e5-small/deployment/_startNow let's create a new mapping with 2 properties, a standard text field (my_field) and a dense vector field (my_vector) with 384 dimensions to match the output from the embedding model. You will also override the index_options.type to bbq_hnsw. You can see the expected output in the file 03-create-byte-qauntized-index-output.json in the Outputs folder.
PUT bbq-my-byte-quantized-index
{
"mappings": {
"properties": {
"my_field": {
"type": "text"
},
"my_vector": {
"type": "dense_vector",
"dims": 384,
"index_options": {
"type": "bbq_hnsw"
}
}
}
}
}To ensure Elasticsearch generates your vectors, you can make use of an Ingest Pipeline. This pipeline will require 3 things: the endpoint, (model_id), the input_field that you want to create vectors for and the output_field to store those vectors in. The first command below will create an inference ingest pipeline, which uses the inference service under the hood, and the second will test that the pipeline is working correctly. You can see the expected output in the file 04-create-and-simulate-ingest-pipeline-output.json in the Outputs folder.
PUT _ingest/pipeline/my_inference_pipeline
{
"processors": [
{
"inference": {
"model_id": "my_e5_model",
"input_output": [
{
"input_field": "my_field",
"output_field": "my_vector"
}
]
}
}
]
}
POST _ingest/pipeline/my_inference_pipeline/_simulate
{
"docs": [
{
"_source": {
"my_field": "my awesome text field"
}
}
]
}You are now ready to add some documents with the first 2 commands below and to test that your searches work with the 3rd command. You can check out the expected output in the file 05-bbq-index-output.json in the Outputs folder.
PUT bbq-my-byte-quantized-index/_doc/1?pipeline=my_inference_pipeline
{
"my_field": "my awesome text field"
}
PUT bbq-my-byte-quantized-index/_doc/2?pipeline=my_inference_pipeline
{
"my_field": "some other sentence"
}
GET bbq-my-byte-quantized-index/_search
{
"query": {
"bool": {
"must": [
{
"knn": {
"field": "my_vector",
"query_vector_builder": {
"text_embedding": {
"model_id": "my_e5_model",
"model_text": "my awesome search field"
}
},
"k": 10,
"num_candidates": 100
}
}
]
}
},
"_source": [
"my_field"
]
}As recommended in this post, rescoring and oversampling are advised when you scale to non-trivial amounts of data because they help maintain high recall accuracy while benefiting from the compression advantages. From Elasticsearch version 8.18, you can do it this way using rescore_vector. The expected output is in the file 06-bbq-search-8-18-output.json in the Outputs folder.
GET bbq-my-byte-quantized-index/_search
{
"query": {
"bool": {
"must": [
{
"knn": {
"field": "my_vector",
"query_vector_builder": {
"text_embedding": {
"model_id": "my_e5_model",
"model_text": "my awesome search field"
}
},
"rescore_vector": {
"oversample": 3
},
"k": 10,
"num_candidates": 100
}
}
]
}
},
"_source": [
"my_field"
]
}How do these scores compare to those you would get for raw data? If you do everything above again but with index_options.type: hnsw, you will see that the scores are very comparable. You can see the expected output in the file 07-raw-vector-output.json in the Outputs folder.
PUT my-raw-vector-index
{
"mappings": {
"properties": {
"my_field": {
"type": "text"
},
"my_vector": {
"type": "dense_vector",
"dims": 384,
"index_options": {
"type": "hnsw"
}
}
}
}
}
PUT my-raw-vector-index/_doc/1?pipeline=my_inference_pipeline
{
"my_field": "my awesome text field"
}
PUT my-raw-vector-index/_doc/2?pipeline=my_inference_pipeline
{
"my_field": "some other sentence"
}
GET my-raw-vector-index/_search
{
"query": {
"bool": {
"must": [
{
"knn": {
"field": "my_vector",
"query_vector_builder": {
"text_embedding": {
"model_id": "my_e5_model",
"model_text": "my awesome search field"
}
},
"k": 10,
"num_candidates": 100
}
}
]
}
},
"_source": [
"my_field"
]
}Approximate numbers on the compression ratios
Storage and memory requirements can quickly become a significant challenge when working with vector search. The following breakdown illustrates how different quantization techniques dramatically reduce the memory footprint of vector data.
| Vectors (V) | Dimensions (D) | raw (V x D x 4) | int8 (V x (D x 1 + 4)) | int4 (V x (D x 0.5 + 4)) | bbq (V x (D x 0.125 + 4)) |
|---|---|---|---|---|---|
| 10,000,000 | 384 | 14.31GB | 3.61GB | 1.83GB | 0.58GB |
| 50,000,000 | 384 | 71.53GB | 18.07GB | 9.13GB | 2.89GB |
| 100,000,000 | 384 | 143.05GB | 36.14GB | 18.25GB | 5.77GB |
Conclusion
BBQ is an optimization you can apply to your vector data for compression without sacrificing accuracy. It works by converting vectors into bits, allowing you to search the data effectively and empowering you to scale your AI workflows to accelerate searches and optimize data storage.
Further learning
If you are interested in learning more about BBQ, be sure to check out the following resources:
- Binary Quantization (BBQ) in Lucene and Elasticsearch
- Better Binary Quantization (BBQ) vs. Product Quantization
- Optimized Scalar Quantization: Even Better Binary Quantization
- Better Binary Quantization (BBQ): From Bytes to BBQ, The Secret to Better Vector Search by Ben Trent
Ready to try this out on your own? Start a free trial.
Elasticsearch has integrations for tools from LangChain, Cohere and more. Join our advanced semantic search webinar to build your next GenAI app!
Related content

October 22, 2025
Deploying a multilingual embedding model in Elasticsearch
Learn how to deploy an e5 multilingual embedding model for vector search and cross-lingual retrieval in Elasticsearch.

October 2, 2025
Introducing a new vector storage format: DiskBBQ
Introducing DiskBBQ, an alternative to HNSW, and exploring when and why to use it.
September 19, 2025
Using TwelveLabs’ Marengo video embedding model with Amazon Bedrock and Elasticsearch
Creating a small app to search video embeddings from TwelveLabs' Marengo model.

September 15, 2025
Balancing the scales: Making reciprocal rank fusion (RRF) smarter with weights
Exploring weighted reciprocal rank fusion (RRF) in Elasticsearch and how it works through practical examples.

September 8, 2025
MCP for intelligent search
Building an intelligent search system by integrating Elastic's intelligent query layer with MCP to enhance the generative efficacy of LLMs.