Elastic announced Elastic Rerank in December 2024, which brings powerful semantic search capabilities with no required reindexing—delivering high relevance, top performance, and efficiency. The core set of capabilities powered by Elastic is now even more flexible, allowing developers to bring their own models from Cohere, Vertex AI, Hugging Face, Jina AI and now IBM watsonx.ai. With our open Inference API, you get the control and choice to integrate, test, and optimize reranking for your needs.
Along with support for IBM watsonx™ Slate embedding models, Elasticsearch vector database powers watsonx Assistant for Conversational Search—now with semantic reranking for even better answer quality.
Reranking refines LLM responses by prioritizing the most relevant documents using advanced scoring methods, ensuring accurate responses in multi-stage retrieval, and making it broadly applicable even for datasets that you don’t want to reindex or remap.
IBM watsonx offers high-quality reranker models that accurately score and prioritize passages based on query relevance, helping refine search results for better precision. These models enhance tasks like semantic search and document comparison, making them essential for delivering highly relevant answers in AI-driven retrieval systems.
In this blog, we’ll explore how to use IBM watsonx™ reranking when building search experiences in the Elasticsearch vector database to reorder search results by meaning, giving you sharper, more context-aware answers without altering your existing index.
How reranking can create powerful search experiences
Semantic reranking is crucial because users expect the best answers at the top, and GenAI models require accurate results to avoid generating incorrect information. Semantic reranking provides consistent scoring, ensuring the most relevant documents are used by AI models and enabling effective cutoff points to prevent hallucinations.
Prerequisites & Creation of an Inference Endpoint
Create an Elasticsearch Serverless Project.
Elasticsearch Cloud Serverless offers fast query execution and seamless integration with the open Inference API, making it ideal for deploying reranking without infrastructure overhead.
Generate an API key in IBM Cloud
- Go to IBM watsonx.ai Cloud and log in using your credentials. You will land on the welcome page.
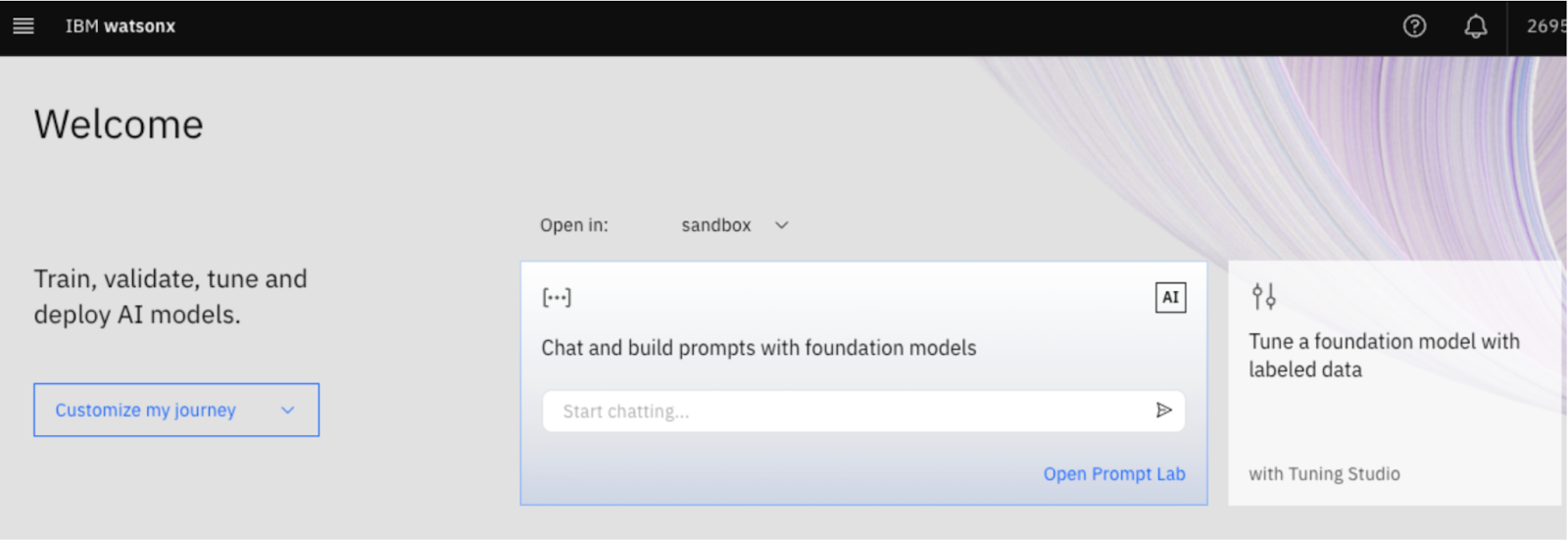
- Go to the API keys page.
- Create an API key.
Steps in Elasticsearch
Using DevTools in Kibana, create an inference endpoint using the watsonxai service for reranking. This example uses the MS Marco MiniLM L-12 v2 model which is supported by IBM, for ensuring high relevance in passage retrieval.
PUT _inference/rerank/ibm_watsonx_rerank
{
"service": "watsonxai",
"service_settings": {
"api_key": "<api_key>",
"url": "xxx.ml.cloud.ibm.com",
"model_id": "cross-encoder/ms-marco-minilm-l-12-v2",
"project_id": "<project_id>",
"api_version": "2024-05-02"
}
}You will receive the following response on the successful creation of the inference endpoint:
{
"inference_id": "ibm_watsonx_rerank",
"task_type": "rerank",
"service": "watsonxai",
"service_settings": {
"url": "xxx.ml.cloud.ibm.com",
"api_version": "2024-05-02",
"model_id": "cross-encoder/ms-marco-minilm-l-12-v2",
"project_id": "<project_id>",
"rate_limit": {
"requests_per_minute": 120
}
}
}Let us now create an index.
PUT quotes-index
{
"mappings": {
"properties": {
"movie_title": {
"type": "text"
},
"quotes": {
"type": "text"
}
}
}
}Next, insert data into the created index.
PUT quotes-index/_doc/1
{
"movie_title": "The Big Lebowski",
"quotes": [
"That rug really tied the room together",
"Yeah, well, you know, that's just like, uh, your opinion, man"
]
}
PUT quotes-index/_doc/2
{
"movie_title": "Star Wars",
"quotes": [
"These are not the droids you're looking for",
"I have a bad feeling about this",
"Do. Or do not. There is no try."
]
}
PUT quotes-index/_doc/3
{
"movie_title": "The Avengers",
"quotes": [
"What's the matter, scared of a little lightning?",
"Superheroes? In New York? Give me a break!"
]
}Next, let’s search using a text_similarity_reranker retriever, which enhances search results by reranking documents based on semantic similarity to a specified inference text, using an ML model.
The retriever helps you configure both the retrieval and reranking of search results in a single API call.
POST quotes-index/_search
{
"retriever": {
"text_similarity_reranker": {
"retriever": {
"standard": {
"query": {
"match": {
"quotes": "feeling lightning"
}
}
}
},
"field": "quotes",
"inference_id": "ibm_watsonx_rerank",
"inference_text": "feeling lightning",
"rank_window_size": 50
}
},
"size": 50
}Next, let’s verify the returned result.
{
"took": 718,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.003072956,
"hits": [
{
"_index": "quotes-index",
"_id": "3",
"_score": 0.003072956,
"_source": {
"movie_title": "The Avengers",
"quotes": [
"What's the matter, scared of a little lightning?",
"Superheroes? In New York? Give me a break!"
]
}
},
{
"_index": "quotes-index",
"_id": "2",
"_score": 0.000024473073,
"_source": {
"movie_title": "Star Wars",
"quotes": [
"These are not the droids you're looking for",
"I have a bad feeling about this",
"Do. Or do not. There is no try."
]
}
}
]
}
}The passages are now reordered to show the passages with the highest scores first. In this example, lexical retrieval initially selected The Avengers (_id: 3) and Star Wars (_id: 2) based on word matches—“lightning” in one and “feeling” in the other. This approach considers surface-level overlaps and keywords.
IBM watsonx.ai rerank then re-evaluated the results based on context, ranking The Avengers higher because “lightning” directly aligned with the query "feeling lightning." This demonstrates that by prioritizing meaning over simple keyword matches, reranking ensures more relevant search results.
Try semantic reranking with watsonx and Elasticsearch today
With the integration of IBM watsonx™ rerank models, the Elasticsearch Open Inference API continues to empower developers with enhanced capabilities for building powerful and flexible AI-powered search experiences. Explore more supported encoder foundation models available with watsonx.ai.
Additionally, use IBM watsonx Assistant’s new Conversational Search feature and IBM watsonx Discovery today. Visit IBM watsonx Discovery to learn more about this new capability using Elasticsearch. You can follow these steps for setup and integration with IBM watsonx Assistants.
Ready to try this out on your own? Start a free trial.
Elasticsearch has integrations for tools from LangChain, Cohere and more. Join our advanced semantic search webinar to build your next GenAI app!
Related content
September 18, 2025
Elasticsearch open inference API adds support for Google’s Gemini models
Learn how to use the Elasticsearch open inference API with Google’s Gemini models for content generation, question answering, and summarization.

September 4, 2025
Transforming data interaction: Deploying Elastic’s MCP server on Amazon Bedrock AgentCore Runtime for crafting agentic AI applications
Transform complex database queries into simple conversations by deploying Elastic's search capabilities on Amazon Bedrock AgentCore Runtime platform.
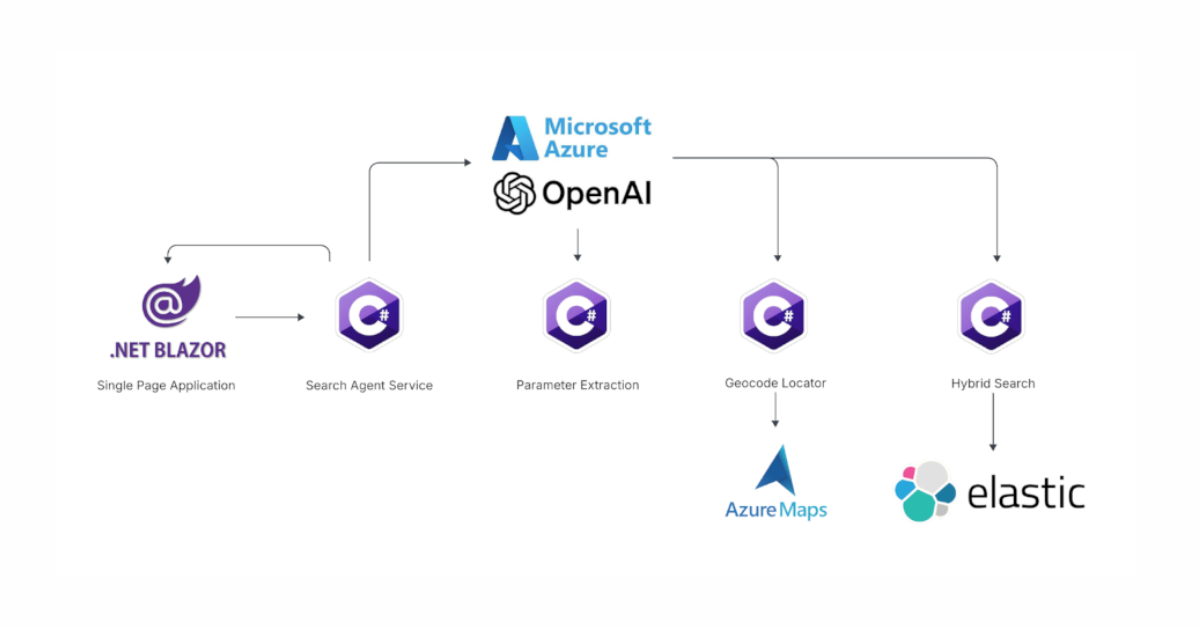
June 13, 2025
Using Azure LLM Functions with Elasticsearch for smarter query experiences
Try out the example real estate search app that uses Azure Gen AI LLM Functions with Elasticsearch to provide flexible hybrid search results. See step-by-step how to configure and run the example app in GitHub Codespaces.
June 17, 2025
Improving Copilot capabilities using Elasticsearch
Discover how to use Elasticsearch with Microsoft 365 Copilot Chat and Copilot in Microsoft Teams.
June 5, 2025
Making sense of unstructured documents: Using Reducto parsing with Elasticsearch
Demonstrating how Reducto's document processing can be integrated with Elasticsearch for semantic search.