Spring AI is now generally available, with its first stable release 1.0 ready for you to download on Maven Central. Let’s use it right away to build a complete AI application, using your favorite LLM and our favorite vector database. Or dive straight into the repository with the final application.
What’s Spring AI?
Spring AI 1.0, a comprehensive solution for AI engineering in Java, is now available after a significant development period influenced by rapid advancements in the AI field. The release includes numerous essential new features for AI engineers.
Java and Spring are in a prime spot to jump on this whole AI wave. Tons of companies are running their stuff on Spring Boot, which makes it super easy to plug AI into what they're already doing. You can basically link up your business logic and data right to those AI models without too much hassle.

Spring AI provides support for various AI models and technologies, such as:
- Image models: generate images given text prompts.
- Transcription models: take audio sources and convert them to text.
- Embedding models: convert arbitrary data into vectors, which are data types optimized for semantic similarity search.
- Chat models: these should be familiar! You’ve no doubt even had a brief conversation with one somewhere.
Chat models are where most of the fanfare seems to be in the AI space, and rightfully so, they're awesome! You can get them to help you correct a document or write a poem. (Just don’t ask them to tell a joke… yet.) They’re awesome, but they do have some issues.
Spring AI solutions to AI challenges

(The picture shown is used with permission from the Spring AI team lead Dr. Mark Pollack)
Let's go through some of these problems and their solutions in Spring AI.
| Problem | Solution | |
|---|---|---|
| Consistency | Chat Models are open-minded and prone to distraction | You can give them a system prompt to govern their overall shape and structure |
| Memory | AI models don’t have memory, so they can’t correlate one message from a given user to another | You can give them a memory system to store the relevant parts of the conversation |
| Isolation | AI models live in isolated little sandboxes, but they can do really amazing things if you give them access to tools - functions that they can invoke when they deem it necessary | Spring AI supports tool calling which lets you tell the AI model about tools in its environment, which it can then ask you to invoke. This multi-turn interaction is all handled transparently for you |
| Private data | AI models are smart, but they’re not omniscient! They don't know what's in your proprietary databases - nor we think would you want them to! | You need to inform their responses by stuffing the prompts - basically using the all mighty string concatenation operator to put text in the request before the model looks at the question being asked. Background information, if you like. How do you decide what should be sent and what shouldn’t? Use a vector store to select only the relevant data and send it in onward. This is called retrieval augmented generation, or RAG |
| Hallucination | AI chat models like to, well, chat! And sometimes they do so so confidently that they can make stuff up | You need to use evaluation - using one model to validate the output of another - to confirm reasonable results |
And, of course, no AI application is an island. Today modern AI systems and services work best when integrated with other systems and services. Model Context Protocol (MCP) makes it possible to connect your AI applications with other MCP-based services, regardless of what language they’re written in. You can assemble all of this in agentic workflows that drive towards a larger goal.
The best part? You can do all this while building on the familiar idioms and abstractions any Spring Boot developer will have come to expect: convenient starter dependencies for basically everything are available on the Spring Initializr.
Spring AI provides convenient Spring Boot autoconfigurations that give you the convention-over-configuration setup you’ve come to know and expect. And Spring AI supports observability with Spring Boot’s Actuator and the Micrometer project. It plays well with GraalVM and virtual threads, too, allowing you to build super fast and efficient AI applications that scale.
Why Elasticsearch
Elasticsearch is a full text search engine, you probably know that. So why are we using it for this project? Well, it’s also a vector store! And quite a good one at that, where data lives next to the full text. Other notable advantages:
- Super easy to set up
- Opensource
- Horizontally scalable
- Most of your organization’s free form data probably already lives in an Elasticsearch cluster
- Feature complete search engine capability
- Fully integrated in Spring AI!
Taking everything into consideration, Elasticsearch checks all the boxes for an excellent vector store, so let's set it up and start building our application!
Getting started with Elasticsearch
We’re going to need both Elasticsearch and Kibana, the UI console you’ll use to interact with the data hosted in the database.
You can try everything on your local machine thanks to the goodness of Docker images and the Elastic.co home page. Go there, scroll down to find the curl command, run it and pipe it right into your shell:
curl -fsSL https://elastic.co/start-local | sh
______ _ _ _
| ____| | | | (_)
| |__ | | __ _ ___| |_ _ ___
| __| | |/ _` / __| __| |/ __|
| |____| | (_| \__ \ |_| | (__
|______|_|\__,_|___/\__|_|\___|
-------------------------------------------------
🚀 Run Elasticsearch and Kibana for local testing
-------------------------------------------------
ℹ️ Do not use this script in a production environment
⌛️ Setting up Elasticsearch and Kibana v9.0.0...
- Generated random passwords
- Created the elastic-start-local folder containing the files:
- .env, with settings
- docker-compose.yml, for Docker services
- start/stop/uninstall commands
- Running docker compose up --wait
[+] Running 25/26
✔ kibana_settings Pulled 16.7s
✔ kibana Pulled 26.8s
✔ elasticsearch Pulled 17.4s
[+] Running 6/6
✔ Network elastic-start-local_default Created 0.0s
✔ Volume "elastic-start-local_dev-elasticsearch" Created 0.0s
✔ Volume "elastic-start-local_dev-kibana" Created 0.0s
✔ Container es-local-dev Healthy 12.9s
✔ Container kibana_settings Exited 11.9s
✔ Container kibana-local-dev Healthy 21.8s
🎉 Congrats, Elasticsearch and Kibana are installed and running in Docker!
🌐 Open your browser at http://localhost:5601
Username: elastic
Password: w1GB15uQ
🔌 Elasticsearch API endpoint: http://localhost:9200
🔑 API key: SERqaGlKWUJLNVJDODc1UGxjLWE6WFdxSTNvMU5SbVc5NDlKMEhpMzJmZw==
Learn more at https://github.com/elastic/start-local
➜ ~This will simply pull and configure Docker images for Elasticsearch and Kibana, and after a few minutes you’ll have them up and running on your local machine, complete with connection credentials.
You’ve also got two different urls you can use to interact with your Elasticsearch instance. Do as the prompt says and point your browser to http://localhost:5601.
Note the username elastic and password printed on the console, too: you’ll need those to log in (in the example output above they’re respectively elastic and w1GB15uQ).
Pulling the app together
Go to the Spring Initializr page and generate a new Spring AI project with the following dependencies:
Elasticsearch Vector StoreSpring Boot ActuatorGraalVMOpenAIWeb
Make sure to choose the latest-and-greatest version of Java (ideally Java 24 - as of this writing - or later) and the build tool of your choice. We’re using Apache Maven in this example.
Click Generate and then unzip the project and import it into your IDE of choice. (We’re using IntelliJ IDEA.)
First things first: let’s specify your connection details for your Spring Boot application. In application.properties, write the following:
spring.elasticsearch.uris=http://localhost:9200
spring.elasticsearch.username=elastic
spring.elasticsearch.password=w1GB15uQWe’ll also Spring AI’s vector store capability to initialize whatever’s needed on the Elasticsearch side in terms of data structures, so specify:
spring.ai.vectorstore.elasticsearch.initialize-schema=trueWe’re going to use OpenAI in this demo, specifically the Embedding Model and Chat Model (feel free to use the service you prefer, as long as Spring AI supports it).
The Embedding Model is needed to create embeddings of the data before we stash it into Elasticsearch. For OpenAI to work, we need to specify the API key:
spring.ai.openai.api-key=...You can define it as an environment variable like SPRING_AI_OPENAI_API_KEY to avoid stashing the credential in your source code.
We’re going to upload files, so be sure to customize how much data can be uploaded to the servlet container:
spring.servlet.multipart.max-file-size=20MB
spring.servlet.multipart.max-request-size=20MBWe’re almost there! Before we dive into writing the code, let’s get a preview of how this is going to work.
On our machine, we downloaded the following file (a list of rules for a board game), renamed it to test.pdf and put it in ~/Downloads/test.pdf.
The file will be sent to the /rag/ingest endpoint (replace the path accordingly to your local setup):
http --form POST http://localhost:8080/rag/ingest path@/Users/jlong/Downloads/test.pdfThis might take a few seconds…
Behind the scenes, the data’s being sent to OpenAI, which is creating embeddings of the data; that data is then being written to Elasticsearch, both the vectors and the original text.
That data, along with all the embeddings therein, is where the magic happens. We can then query Elasticsearch using the VectorStore interface.
The full flow looks like this:
- The HTTP client uploads your PDF of choice to the Spring application.
- Spring AI takes care of the text extraction from our PDF and chunks each page into 800 character chunks.
- OpenAI generates the vector representation for each chunk.
- Both chunked text and the embedding are then stored in Elasticsearch.

Last, we’ll issue a query:
http :8080/rag/query question=="where do you place the reward card after obtaining it?"And we’ll get a relevant answer:
After obtaining a Reward card, you place it facedown under the Hero card of the hero who received it.
Found at page: 28 of the manualNice! How does this all work?
- The HTTP client submits the question to the Spring application.
- Spring AI gets the vector representation of the question from OpenAI.
- With that embedding it searches for similar documents in the stored Elasticsearch chunks and retrieves the most similar documents.
- Spring AI then sends the question and retrieved context to OpenAI for generating an LLM answer.
- Finally, it returns the generated answer and a reference to the retrieved context.

Let’s dive into the Java code to see how it really works.
First of all, the Main class: it’s a stock standard main class for any ol’ Spring Boot application.
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}Nothing to see there. Moving on…
Up next, a basic HTTP controller:
@RestController
class RagController {
private final RagService rag;
RagController(RagService rag) {
this.rag = rag;
}
@PostMapping("/rag/ingest")
ResponseEntity<?> ingestPDF(@RequestBody MultipartFile path) {
rag.ingest(path.getResource());
return ResponseEntity.ok().body("Done!");
}
@GetMapping("/rag/query")
ResponseEntity<?> query(@RequestParam String question) {
String response = rag.directRag(question);
return ResponseEntity.ok().body(response);
}
}The controller is simply calling a service we’ve built to handle ingesting files and writing them to the Elasticsearch vector store, and then facilitating queries against that same vector store.
Let’s look at the service:
@Service
class RagService {
private final ElasticsearchVectorStore vectorStore;
private final ChatClient ai;
RagService(ElasticsearchVectorStore vectorStore, ChatClient.Builder clientBuilder) {
this.vectorStore = vectorStore;
this.ai = clientBuilder.build();
}
void ingest(Resource path) {
PagePdfDocumentReader pdfReader = new PagePdfDocumentReader(path);
List<Document> batch = new TokenTextSplitter().apply(pdfReader.read());
vectorStore.add(batch);
}
// TBD
}This code handles all the ingest: given a Spring Framework Resource, which is a container around bytes, we read the PDF data (presumed to be a .PDF file - make sure that you validate as much before accepting arbitrary inputs!) using Spring AI’s PagePdfDocumentReader and then tokenize it using Spring AI’s TokenTextSplitter, finally adding the resulting List<Document>s to the VectorStore implementation, ElasticsearchVectorStore.
You can confirm as much using Kibana: after sending a file to the /rag/ingest endpoint, open up your browser to localhost:5601 and in the side menu on the left navigate to Dev Tools. There you can issue queries to interact with the data in the Elasticsearch instance.

Issue a query like this:

Now for the fun stuff: how do we get that data back out again in response to user queries?
Here’s a first cut at an implementation of the query, in a method called directRag.
String directRag(String question) {
// Query the vector store for documents related to the question
List<Document> vectorStoreResult =
vectorStore.doSimilaritySearch(SearchRequest.builder().query(question).topK(5)
.similarityThreshold(0.7).build());
// Merging the documents into a single string
String documents = vectorStoreResult.stream()
.map(Document::getText)
.collect(Collectors.joining(System.lineSeparator()));
// Exit if the vector search didn't find any results
if (documents.isEmpty()) {
return "No relevant context found. Please change your question.";
}
// Setting the prompt with the context
String prompt = """
You're assisting with providing the rules of the tabletop game Runewars.
Use the information from the DOCUMENTS section to provide accurate answers to the
question in the QUESTION section.
If unsure, simply state that you don't know.
DOCUMENTS:
""" + documents
+ """
QUESTION:
""" + question;
// Calling the chat model with the question
String response = ai
.prompt()
.user(prompt)
.call()
.content();
return response +
System.lineSeparator() +
"Found at page: " +
// Retrieving the first ranked page number from the document metadata
vectorStoreResult.getFirst().getMetadata().get(PagePdfDocumentReader.METADATA_START_PAGE_NUMBER) +
" of the manual";
}The code’s fairly straightforward, but let’s break it down into multiple steps:
- Use the
VectorStoreto perform a similarity search. - Given all the results, get the underlying Spring AI
Documents and extract their text, concatenating them all into one result. - Send the results from the
VectorStoreto the model, along with a prompt instructing the model what to do with them and the question from the user. Wait for the response and return it.
This is RAG - retrieval augmented generation. It’s the idea that we’re using data from a vector store to inform the processing and analysis done by the model. Now that you know how to do it, let’s hope you never have to! Not like this anyway: Spring AI’s Advisors are here to simplify this process even more.
Advisors allows you to pre- and post-process a request to a given model, other than providing an abstraction layer between your application and the vector store. Add the following dependency to your build:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>Add another method called advisedRag(String question) to the class:
String advisedRag(String question) {
return this.ai
.prompt()
.user(question)
.advisors(new QuestionAnswerAdvisor(vectorStore))
.call()
.content();
}All the RAG-pattern logic is encapsulated in the QuestionAnswerAdvisor. Everything else is just as any request to a ChatModel would be! Nice!
And you can get the complete code from GitHub.
Conclusion
In this demo, we used Docker images and did everything on our local machine, but the goal here is to build production-worthy AI systems and services. There are several things you could do to make that a reality.
First of all, you can add Spring Boot Actuator to monitor the consumption of tokens. Tokens are a proxy for the complexity (and sometimes the dollars-and-cents) cost of a given request to the model.
You’ve already got the Spring Boot Actuator on the classpath, so just specify the following properties to show all the metrics (captured by the magnificent Micrometer.io project):
management.endpoints.web.exposure.include=*Restart your application. Make a query, and then go to: http://localhost:8080/actuator/metrics. Search for “token” and you’ll see information about the tokens being used by the application. Make sure you keep an eye on this. You can of course use Micrometer’s integration for Elasticsearch to push those metrics and have Elasticsearch act as your time series database of choice, too!
You should then consider that every time we make a request to a datastore like Elasticsearch, or to OpenAI, or to other network services, we’re doing IO and - often - that IO blocks the threads on which it executes. Java 21 and later ship with non-blocking virtual threads that dramatically improve scalability. Enable it with:
spring.threads.virtual.enabled=trueAnd, finally, you’ll want to host your application and your data in a place where it can thrive and scale. We're sure you’ve probably already thought about where to run your application, but where will you host your data? May we recommend the Elastic Cloud? It’s secure, private, scalable, and full of features. Our favorite part? If you want, you can get the Serverless edition where Elastic wears the pager, not you!
Ready to try this out on your own? Start a free trial.
Elasticsearch has integrations for tools from LangChain, Cohere and more. Join our advanced semantic search webinar to build your next GenAI app!
Related content
September 18, 2025
Elasticsearch open inference API adds support for Google’s Gemini models
Learn how to use the Elasticsearch open inference API with Google’s Gemini models for content generation, question answering, and summarization.

September 4, 2025
Transforming data interaction: Deploying Elastic’s MCP server on Amazon Bedrock AgentCore Runtime for crafting agentic AI applications
Transform complex database queries into simple conversations by deploying Elastic's search capabilities on Amazon Bedrock AgentCore Runtime platform.

June 16, 2025
Elasticsearch open inference API adds support for IBM watsonx.ai rerank models
Exploring how to use IBM watsonx™ reranking when building search experiences in the Elasticsearch vector database.
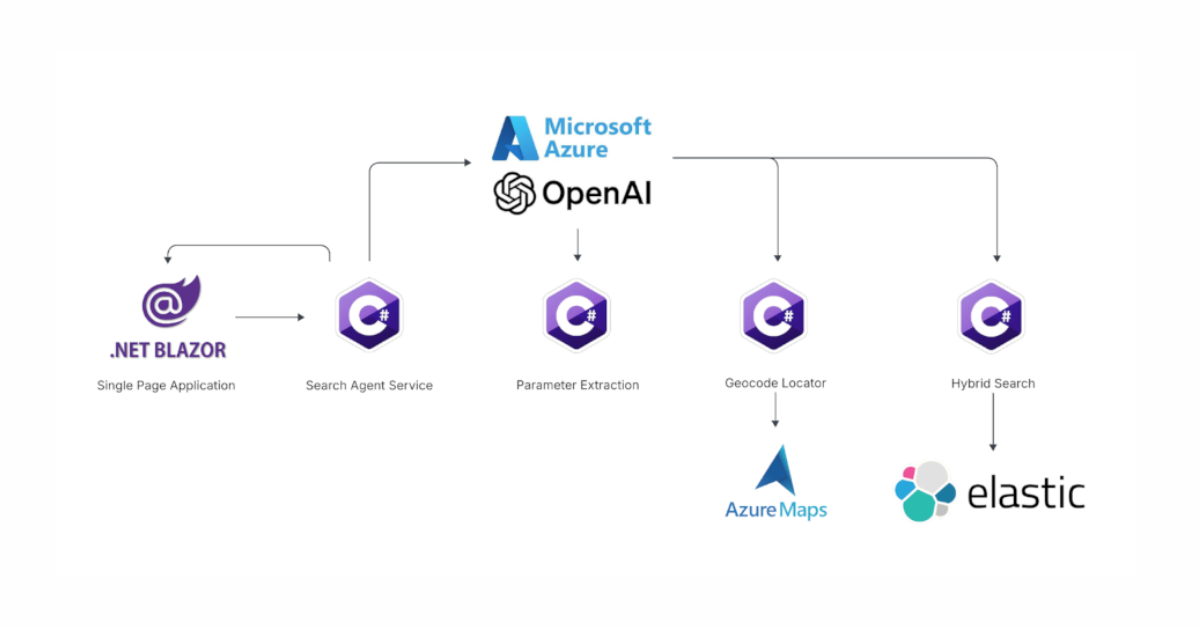
June 13, 2025
Using Azure LLM Functions with Elasticsearch for smarter query experiences
Try out the example real estate search app that uses Azure Gen AI LLM Functions with Elasticsearch to provide flexible hybrid search results. See step-by-step how to configure and run the example app in GitHub Codespaces.
June 17, 2025
Improving Copilot capabilities using Elasticsearch
Discover how to use Elasticsearch with Microsoft 365 Copilot Chat and Copilot in Microsoft Teams.