Elasticsearch 8.16 has a new functionality that allows you to upload PDF files directly into Kibana and analyze them using Playground. In this article, we'll see how to use this functionality by uploading a resume in PDF format and then using Playground to interact with it.
Playground is a low-code platform hosted in Kibana that allows you to create a RAG application and chat with your content. You can read more about it in this article and even test it using this link.
Steps:
- Configure the Elasticsearch Inference Service Endpoint
- Upload PDFs to Kibana
- Interact with the data in Playground
Configure the Elasticsearch Inference Service Endpoint
To run semantic searches, we must first configure an inference endpoint. In this example, we'll use the Elasticsearch Inference Endpoint. This endpoint offers:
- rerank
- sparse embedding
- text embedding
For this example, let's select sparse embedding:
PUT _inference/sparse_embedding/my-elser-model
{
"service": "elasticsearch",
"service_settings": {
"adaptive_allocations": {
"enabled": true,
"min_number_of_allocations": 1,
"max_number_of_allocations": 10
},
"num_threads": 1,
"model_id": ".elser_model_2"
}
}Once configured, confirm that the model was correctly loaded into Kibana by checking Search > Relevance > Inference Endpoint in the Kibana UI.
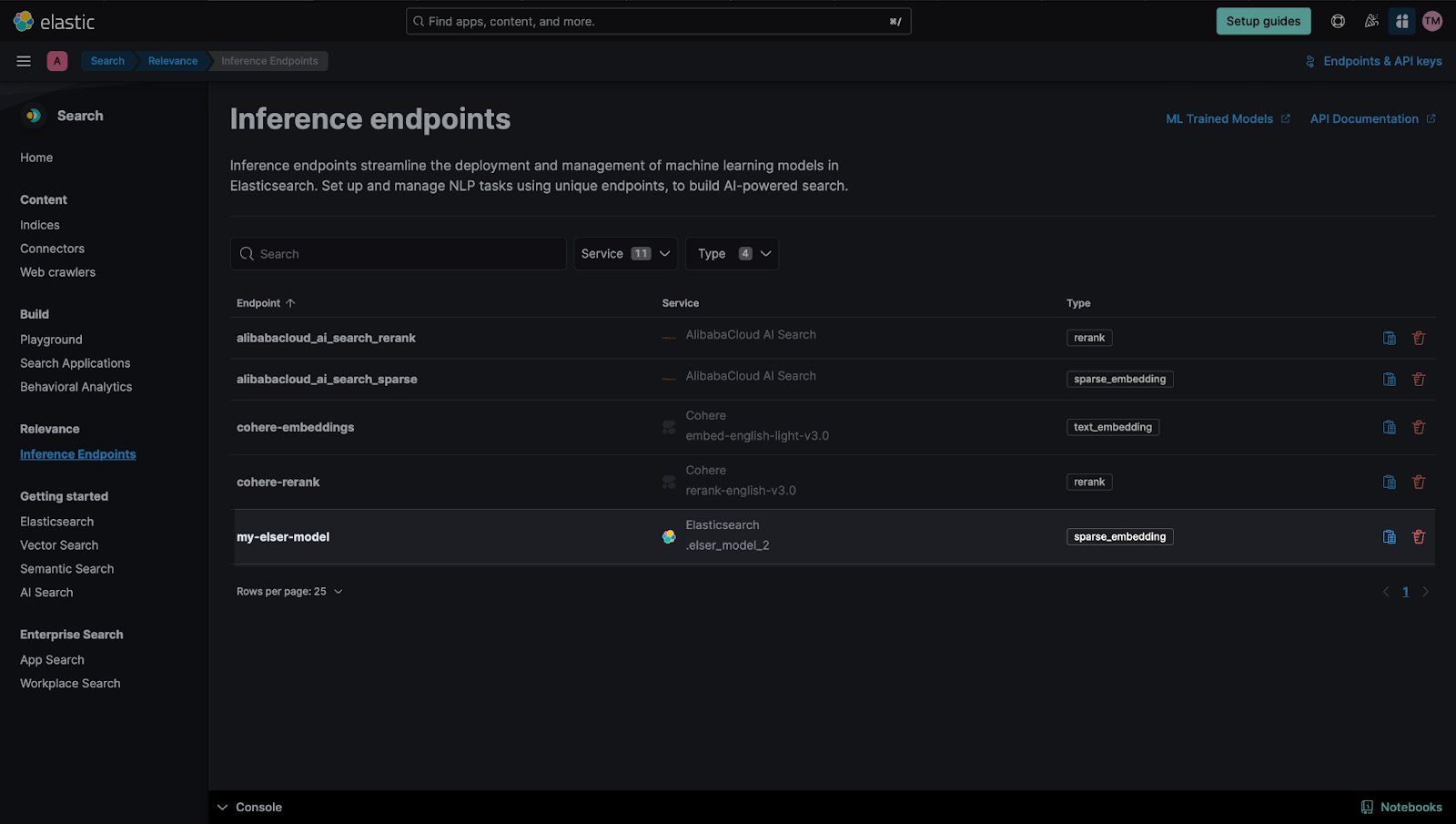
Upload PDFs to Kibana
We'll upload the resume of a junior developer to learn how to use the Kibana upload files functionality.

Go to the Kibana UI and follow these steps:
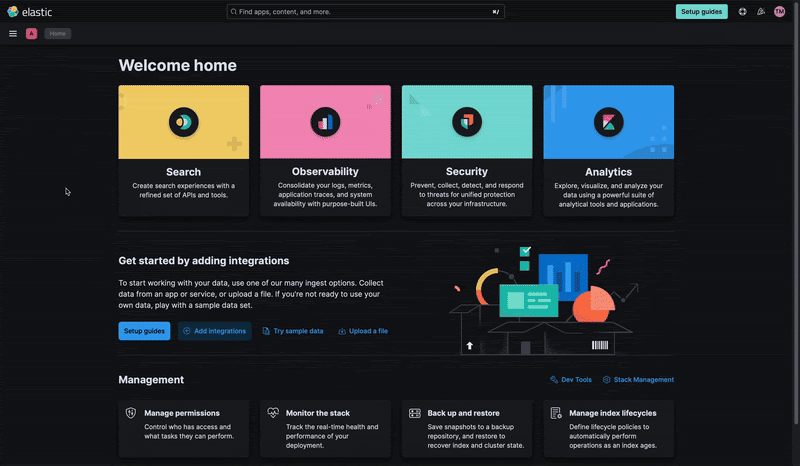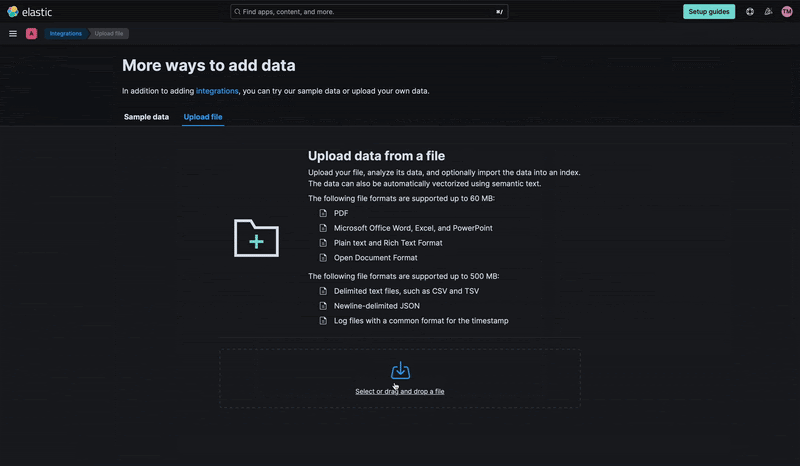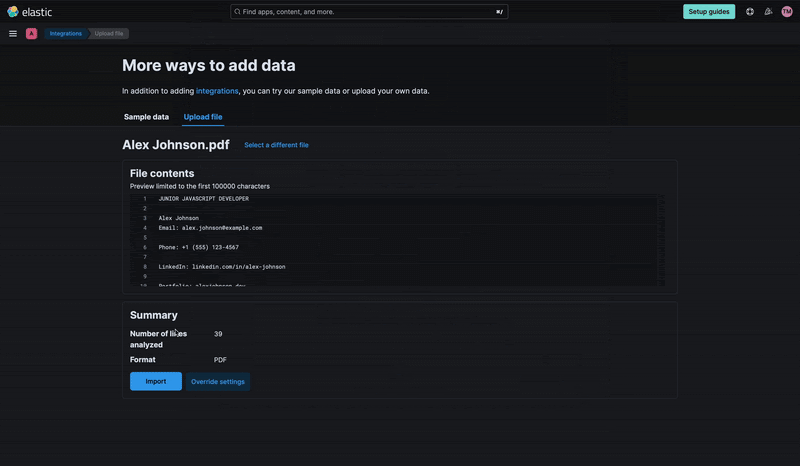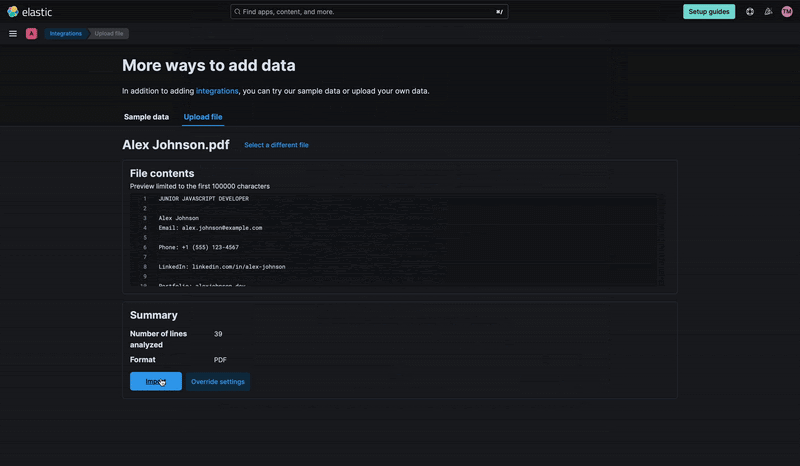
Next, for Import Data, we have two options:
Simple: This is the default option and it allows us to quickly upload our PDF into the index and automatically creates a data view with the indexed info.
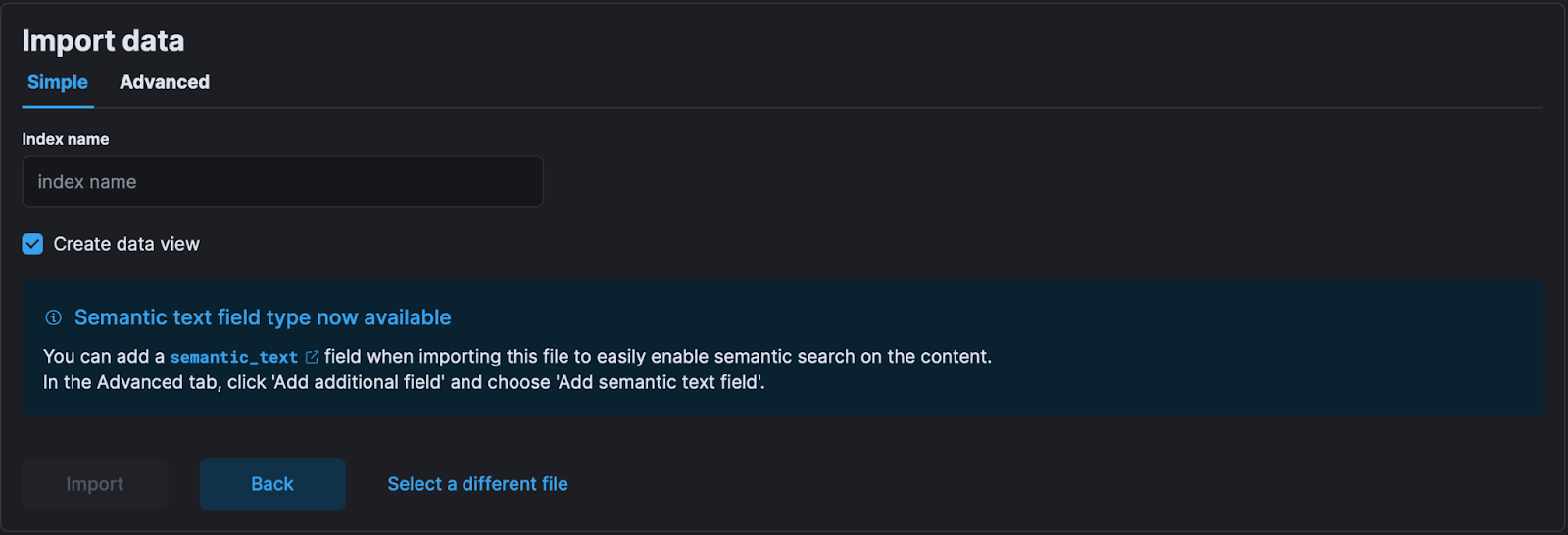
Advanced: This option allows us to customize mappings or add ingest pipelines. Within these settings you can:
- Add a semantic text type of field.
- Index Settings: If you want to configure things like shards or analyzers.
- Index Mappings: If you want to change a field type or how you define your data.
- Ingest Pipeline: If you want to make changes to your data before indexing it.
Go to "Advanced" and select "Add additional field":
Select the field attachment.content; in “copy to field” type "content" and make sure that the inference endpoint is my-elser-model:
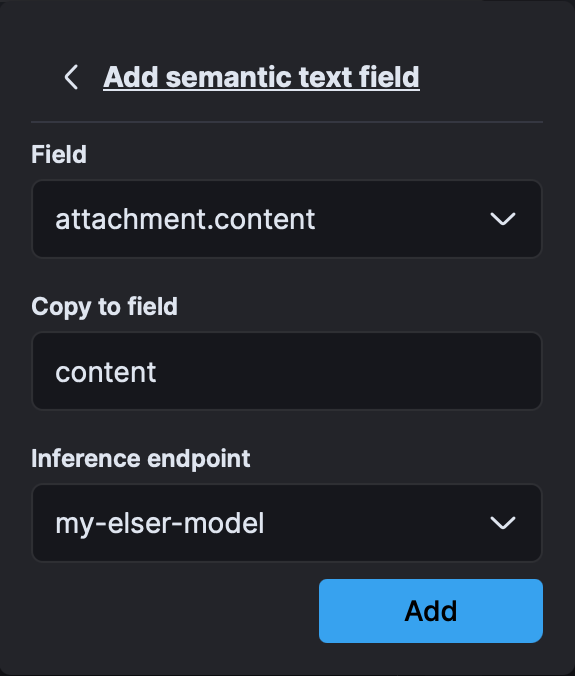
The field Copy to is used to copy the content from attachment.content to a new semantic_text field of (content), which automatically generates vector embeddings using the underlying Inference endpoint (Elastic’s ELSER in this case). This makes both the semantic and text fields available so you can run full-text, semantic, or hybrid searches.
Once everything is configured, click on "Import":

Now that the index is created, we can explore it using Playground.
Interact with the data in Playground
Connect to Playground
After configuring the index and uploading the resumes, we now need to connect the index to Playground. Click Connect to an LLM and select one of the options.
Configure the chatbot
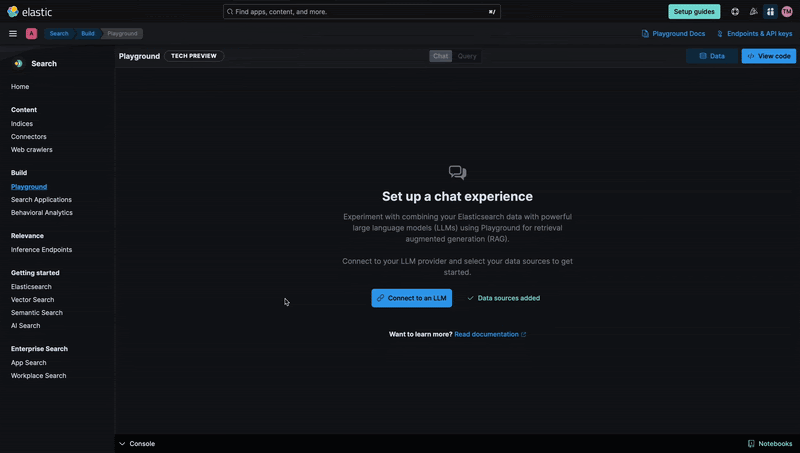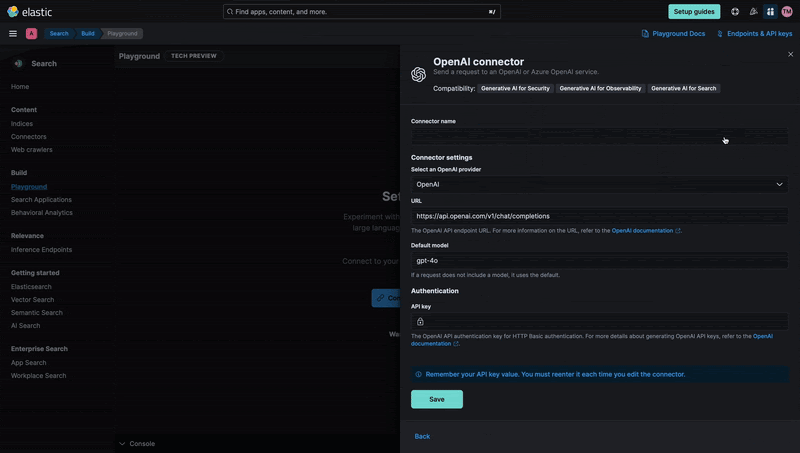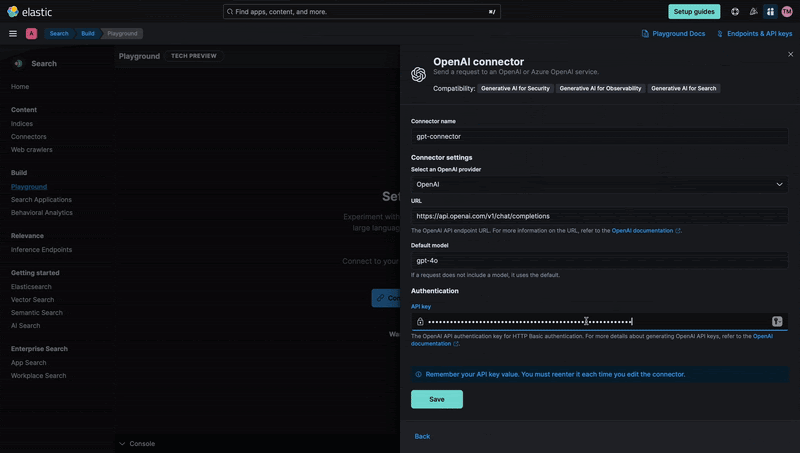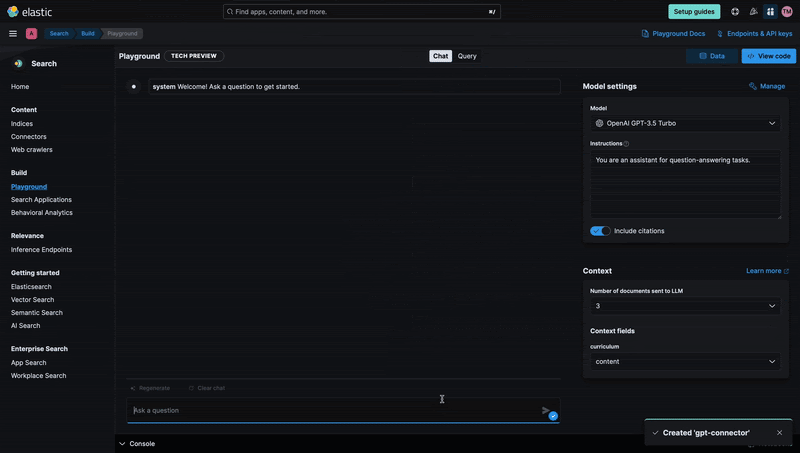
Once Playground has been configured and we have indexed Alex Johnson's resume, we can interact with the data. Using semantic search and LLMs we can ask questions using natural language and get answers even if the documents don't have the keywords we used in the query, like in the example below:
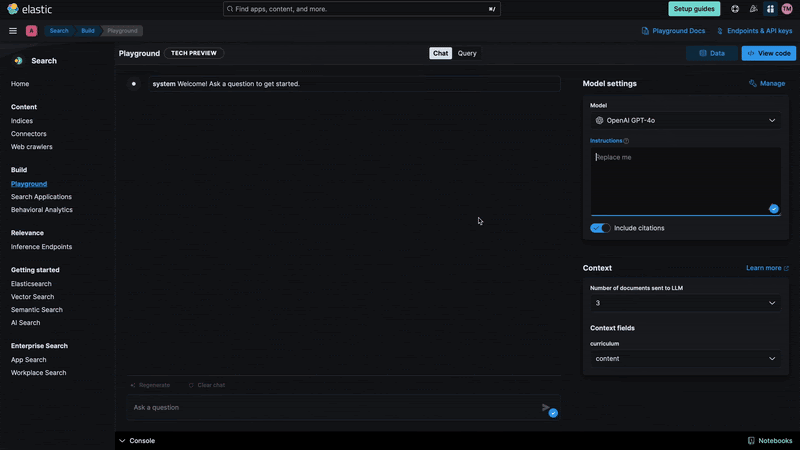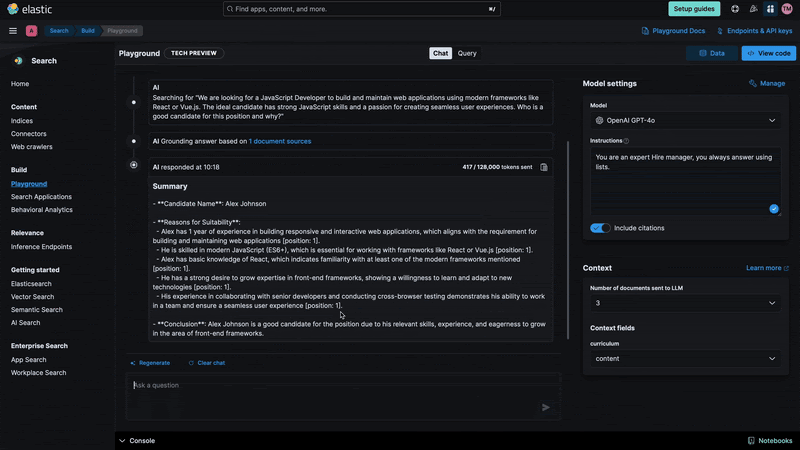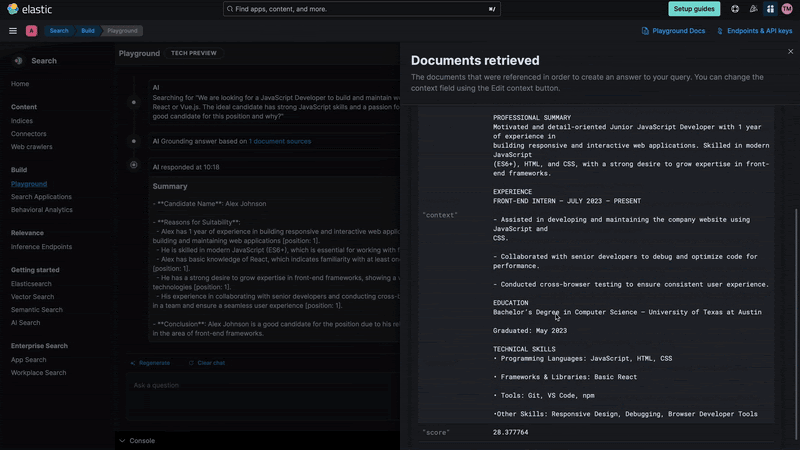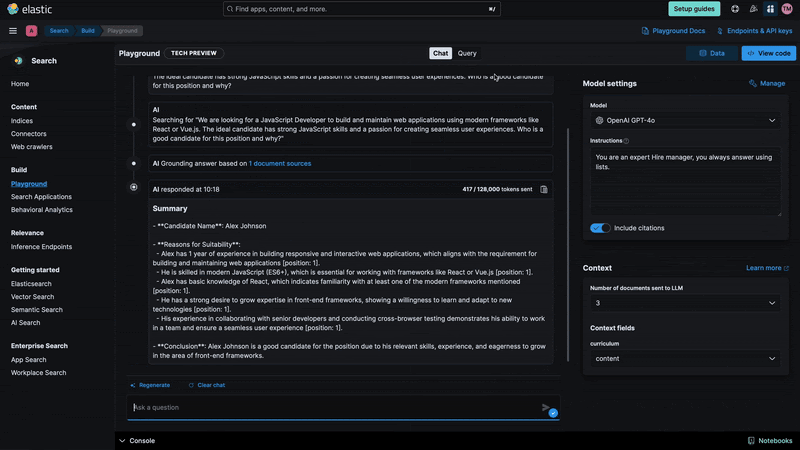
Using the instructions menu, we can control the chatbot behavior and define features like the response format. It can also include citations, to make sure the answer is properly grounded.
If we go to the "Query" tab, we can see the query generated by Playground and we add both a text and a semantic_text fields, Playground will automatically generate a hybrid query to normalize the score between different types of different types of queries.
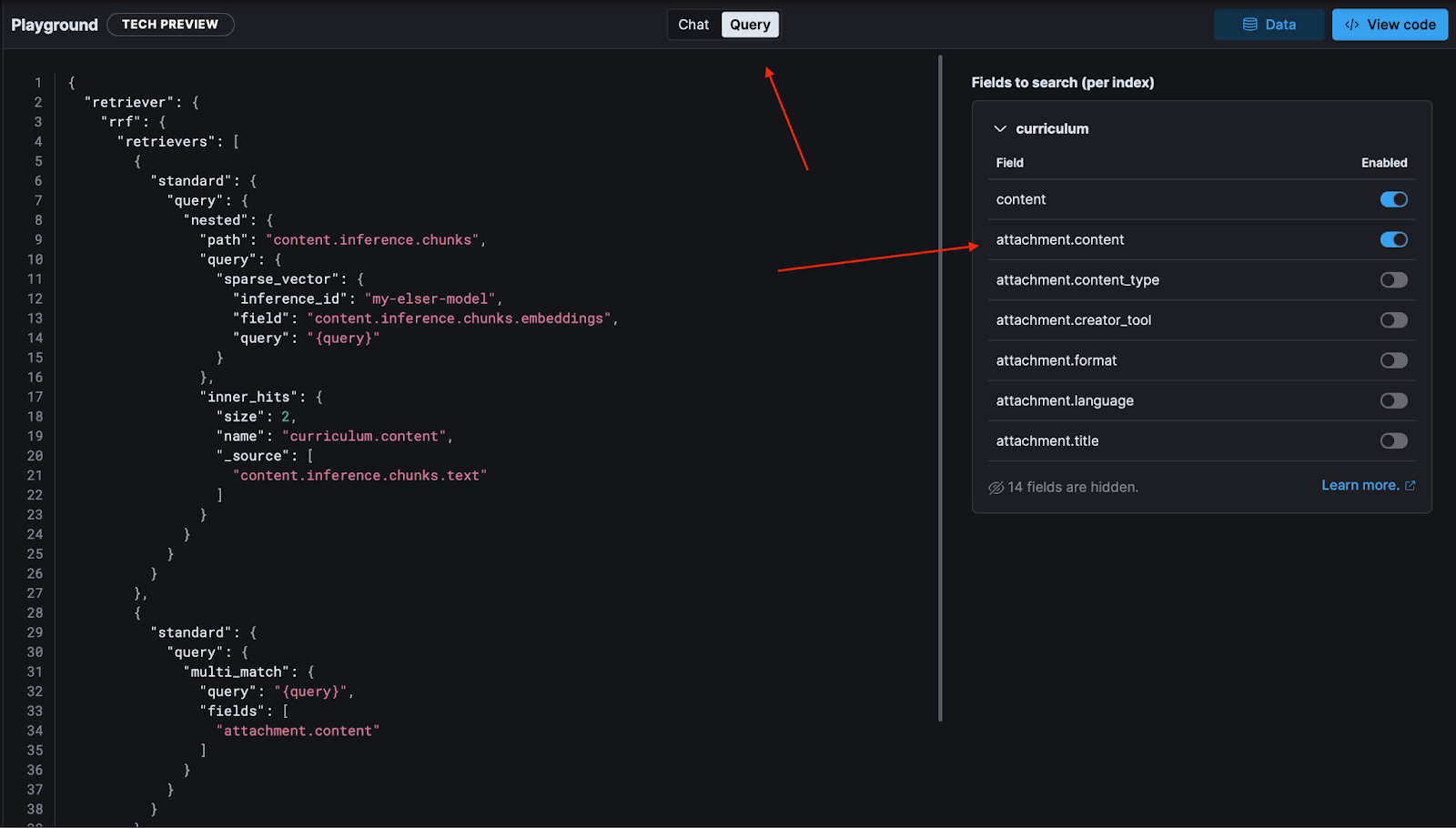
Playground not only answers questions but also helps us understand the internal components of a RAG system, like querying, retrieval phase, context and prompt instructions.
Give it a try and chat with your PDFs!
With the Elasticsearch 8.16 update, we can easily upload PDF/Word/Powerpoint files using the Kibana UI. It can automatically create an index in the simple mode, and you can use the advanced mode to customize your index and tailor it to your needs.
Once your files are uploaded, you can access Playground and quickly and easily chat with them since Playground will handle the LLM interactions and provide the best query based on the type of fields you want to search.
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content

November 4, 2025
Multimodal search for mountain peaks with Elasticsearch and SigLIP-2
Learn how to implement text-to-image and image-to-image multimodal search using SigLIP-2 embeddings and Elasticsearch kNN vector search. Project focus: finding Mount Ama Dablam peak photos from an Everest trek.

October 30, 2025
Context engineering using Mistral Chat completions in Elasticsearch
Learn how to utilize context engineering with Mistral Chat completions in Elasticsearch to ground LLM responses in domain-specific knowledge for accurate outputs.
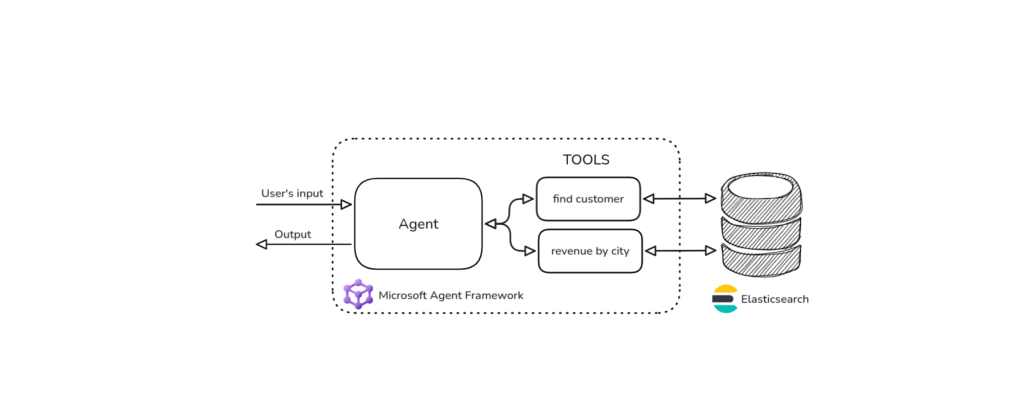
October 27, 2025
Building agentic applications with Elasticsearch and Microsoft’s Agent Framework
Learn how to use Microsoft Agent Framework with Elasticsearch to build an agentic application that extracts ecommerce data from Elasticsearch client libraries using ES|QL.
October 21, 2025
Introducing Elastic’s Agent Builder
Introducing Elastic Agent Builder, a framework to easily build reliable, context-driven AI agents in Elasticsearch with your data.

October 20, 2025
Elastic MCP server: Expose Agent Builder tools to any AI agent
Discover how to use the built-in Elastic MCP server in Agent Builder to securely extend any AI agent with access to your private data and custom tools.