In this article, we will implement a search engine for FAQs using LlamaIndex to index the data. Elasticsearch will serve as our vector database, enabling vector search, while RAG (Retrieval-Augmented Generation) will enrich the context, providing more accurate responses.
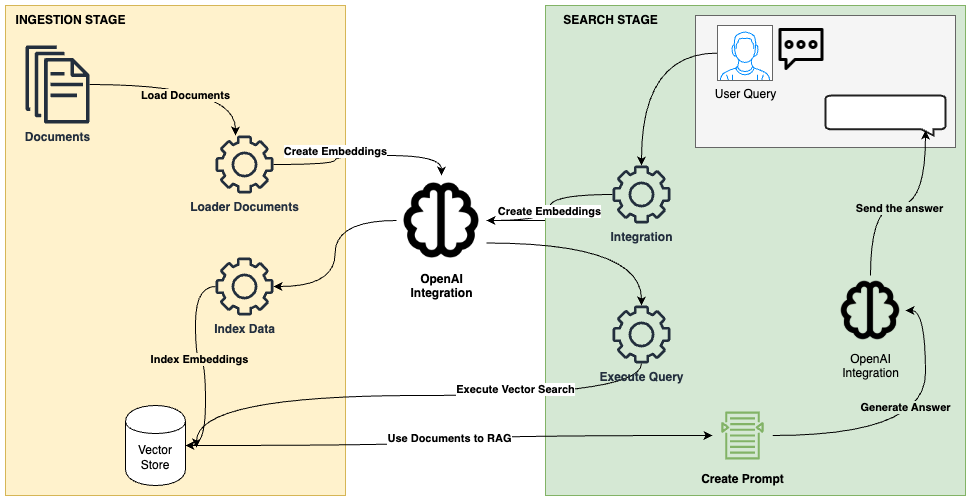
What is LlamaIndex?
LlamaIndex is a framework that facilitates the creation of agents and workflows powered by Large Language Models (LLMs) to interact with specific or private data. It allows the integration of data from various sources (APIs, PDFs, databases) with LLMs, enabling tasks such as research, information extraction, and generation of contextualized responses.
Key concepts:
- Agents: Intelligent assistants that use LLMs to perform tasks, ranging from simple responses to complex actions.
- Workflows: Multi-step processes that combine agents, data connectors, and tools for advanced tasks.
- Context augmentation: A technique that enriches the LLM with external data, overcoming its training limitations.
LlamaIndex integration with Elasticsearch:
Elasticsearch can be used in various ways with LlamaIndex:
- Data source: Use the Elasticsearch Reader to extract documents.
- Embeddings model: Encode data into vectors for semantic searches.
- Vector storage: Use Elasticsearch as a repository for searching vectorized documents.
- Advanced storage: Configure structures such as document summaries or knowledge graphs.
Using LlamaIndex and Elasticsearch to build an FAQ search
Data preparation
We will use the Elasticsearch Service FAQ as an example. Each question was extracted from the website and saved in an individual text file. You can use any approach to organize the data; in this example, we chose to save the files locally.
Example file:
File Name: what-is-elasticsearch-service.txt
Content: Elasticsearch Service is hosted and managed Elasticsearch and Kibana brought to you by the creators of Elasticsearch. Elasticsearch Service is part of Elastic Cloud and ships with features that you can only get from the company behind Elasticsearch, Kibana, Beats, and Logstash. Elasticsearch is a full text search engine that suits a range of uses, from search on websites to big data analytics and more.After saving all the questions, the directory will look like this:

Installation of dependencies
We will implement the ingestion and search using the Python language, the version I used was 3.9. As a prerequisite, it will be necessary to install the following dependencies:
llama-index-vector-stores-elasticsearch
llama-index
openaiElasticsearch and Kibana will be created with Docker, configured via docker-compose.yml to run version 8.16.2. This makes it easier to create the local environment.
version: '3.8'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:8.16.2
container_name: elasticsearch-8.16.2
environment:
- node.name=elasticsearch
- xpack.security.enabled=false
- discovery.type=single-node
- "ES_JAVA_OPTS=-Xms1024m -Xmx1024m"
ports:
- 9200:9200
networks:
- shared_network
kibana:
image: docker.elastic.co/kibana/kibana:8.16.2
container_name: kibana-8.16.2
restart: always
environment:
- ELASTICSEARCH_URL=http://elasticsearch:9200
ports:
- 5601:5601
depends_on:
- elasticsearch
networks:
- shared_network
networks:
shared_network:Document ingestion using LlamaIndex
The documents will be indexed into Elasticsearch using LlamaIndex. First, we load the files with SimpleDirectoryReader, which allows loading files from a local directory. After loading the documents, we will index them using the VectorStoreIndex.
documents = SimpleDirectoryReader("./faq").load_data()
storage_context = StorageContext.from_defaults(vector_store=es)
index = VectorStoreIndex(documents, storage_context=storage_context, embed_model=embed_model)Vector Stores in LlamaIndex are responsible for storing and managing document embeddings. LlamaIndex supports different types of Vector Stores, and in this case, we will use Elasticsearch. In the StorageContext, we configure the Elasticsearch instance. Since the context is local, no additional parameters were required. For configurations in other environments, refer to the documentation to check the necessary parameters: ElasticsearchStore Configuration.
By default, LlamaIndex uses the OpenAI text-embedding-ada-002 model to generate embeddings. However, in this example, we will use the text-embedding-3-small model. It is important to note that an OpenAI API key will be required to use the model.
Below is the complete code for document ingestion.
import openai
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, StorageContext
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.vector_stores.elasticsearch import ElasticsearchStore
openai.api_key = os.environ["OPENAI_API_KEY"]
es = ElasticsearchStore(
index_name="faq",
es_url="http://localhost:9200"
)
def format_title(filename):
filename_without_ext = filename.replace('.txt', '')
text_with_spaces = filename_without_ext.replace('-', ' ')
formatted_text = text_with_spaces.title()
return formatted_text
embed_model = OpenAIEmbedding(model="text-embedding-3-small")
documents = SimpleDirectoryReader("./faq").load_data()
for doc in documents:
doc.metadata['title'] = format_title(doc.metadata['file_name'])
storage_context = StorageContext.from_defaults(vector_store=es)
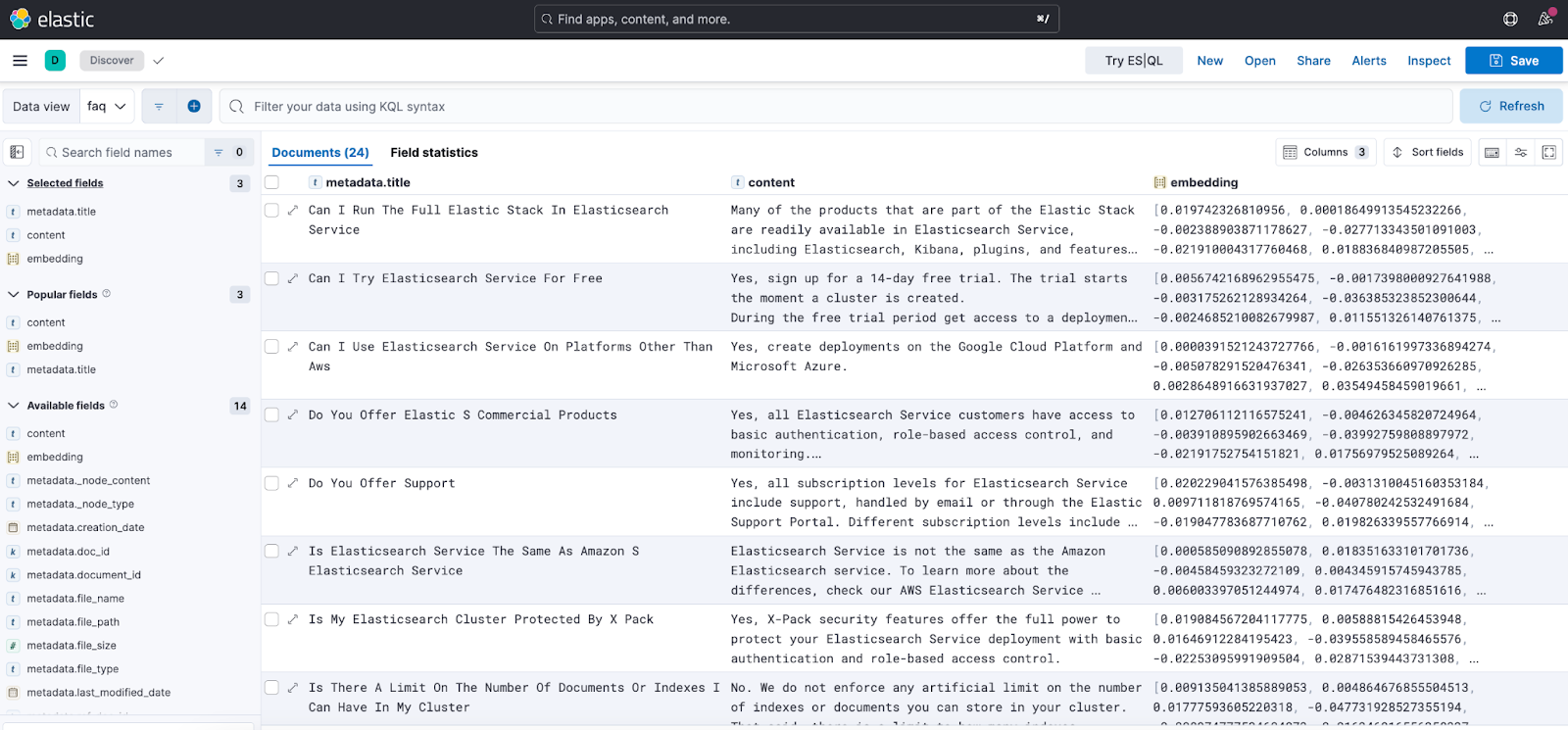
index = VectorStoreIndex(documents, storage_context=storage_context, embed_model=embed_model)After execution, the documents will be indexed in the faq index as shown below:
Search with RAG
To perform searches, we configure the ElasticsearchStore client, setting the index_name and es_url fields with the Elasticsearch URL. In retrieval_strategy, we defined the AsyncDenseVectorStrategy for vector searches. Other strategies, such as AsyncBM25Strategy (keyword search) and AsyncSparseVectorStrategy (sparse vectors), are also available. More details can be found in the official documentation.
es = ElasticsearchStore(
index_name="faq",
es_url="http://localhost:9200",
retrieval_strategy=AsyncDenseVectorStrategy(
)
)Next, a VectorStoreIndex object will be created, where we configure the vector_store using the ElasticsearchStore object. With the as_retriever method, we perform the search for the most relevant documents for a query, setting the number of results returned to 5 through the similarity_top_k parameter.
index = VectorStoreIndex.from_vector_store(vector_store=es)
retriever = index.as_retriever(similarity_top_k=5)
results = retriever.retrieve(query)The next step is RAG. The results of the vector search are incorporated into a formatted prompt for the LLM, enabling a contextualized response based on the retrieved information.
In the PromptTemplate, we define the prompt format, which includes:
- Context ({context_str}): documents retrieved by the retriever.
- Query ({query_str}): the user's question.
- Instructions: guidelines for the model to respond based on the context, without relying on external knowledge.
qa_prompt = PromptTemplate(
"You are a helpful and knowledgeable assistant."
"Your task is to answer the user's query based solely on the context provided below."
"Do not use any prior knowledge or external information.\n"
"---------------------\n"
"Context:\n"
"{context_str}\n"
"---------------------\n"
"Query: {query_str}\n"
"Instructions:\n"
"1. Carefully read and understand the context provided.\n"
"2. If the context contains enough information to answer the query, provide a clear and concise answer.\n"
"3. Do not make up or guess any information.\n"
"Answer: "
)Finally, the LLM processes the prompt and returns a precise and contextual response.
llm = OpenAI(model="gpt-4o")
context_str = "\n\n".join([n.node.get_content() for n in results])
response = llm.complete(
qa_prompt.format(context_str=context_str, query_str=query)
)
print("Answer:")
print(response)The complete code is below:
es = ElasticsearchStore(
index_name="faq",
es_url="http://localhost:9200",
retrieval_strategy=AsyncDenseVectorStrategy(
)
)
def print_results(results):
for rank, result in enumerate(results, start=1):
title = result.metadata.get("title")
score = result.get_score()
text = result.get_text()
print(f"{rank}. title={title} \nscore={score} \ncontent={text}")
def search(query: str):
index = VectorStoreIndex.from_vector_store(vector_store=es)
retriever = index.as_retriever(similarity_top_k=10)
results = retriever.retrieve(QueryBundle(query_str=query))
print_results(results)
qa_prompt = PromptTemplate(
"You are a helpful and knowledgeable assistant."
"Your task is to answer the user's query based solely on the context provided below."
"Do not use any prior knowledge or external information.\n"
"---------------------\n"
"Context:\n"
"{context_str}\n"
"---------------------\n"
"Query: {query_str}\n"
"Instructions:\n"
"1. Carefully read and understand the context provided.\n"
"2. If the context contains enough information to answer the query, provide a clear and concise answer.\n"
"3. Do not make up or guess any information.\n"
"Answer: "
)
llm = OpenAI(model="gpt-4o")
context_str = "\n\n".join([n.node.get_content() for n in results])
response = llm.complete(
qa_prompt.format(context_str=context_str, query_str=query)
)
print("Answer:")
print(response)
question = "Elastic services are free?"
print(f"Question: {question}")
search(question)Now we can perform our search, for example, "Elastic services are free?" and get a contextualized response based on the FAQ data itself.
Question: Elastic services are free?
Answer:
Elastic services are not entirely free. However, there is a 14-day free trial available for exploring Elastic solutions. After the trial, access to features and services depends on the subscription level.To generate this response, the following documents were used:
1. title=Can I Try Elasticsearch Service For Free
score=1.0
content=Yes, sign up for a 14-day free trial. The trial starts the moment a cluster is created.
During the free trial period get access to a deployment to explore Elastic solutions for Enterprise Search, Observability, Security, or the latest version of the Elastic Stack.
2. title=Do You Offer Elastic S Commercial Products
score=0.9941274512218439
content=Yes, all Elasticsearch Service customers have access to basic authentication, role-based access control, and monitoring.
Elasticsearch Service Gold, Platinum and Enterprise customers get complete access to all the capabilities in X-Pack: Security, Alerting, Monitoring, Reporting, Graph Analysis & Visualization. Contact us to learn more.
3. title=What Is Elasticsearch Service
score=0.9896776845746571
content=Elasticsearch Service is hosted and managed Elasticsearch and Kibana brought to you by the creators of Elasticsearch. Elasticsearch Service is part of Elastic Cloud and ships with features that you can only get from the company behind Elasticsearch, Kibana, Beats, and Logstash. Elasticsearch is a full text search engine that suits a range of uses, from search on websites to big data analytics and more.
4. title=Can I Run The Full Elastic Stack In Elasticsearch Service
score=0.9880631561979476
content=Many of the products that are part of the Elastic Stack are readily available in Elasticsearch Service, including Elasticsearch, Kibana, plugins, and features such as monitoring and security. Use other Elastic Stack products directly with Elasticsearch Service. For example, both Logstash and Beats can send their data to Elasticsearch Service. What is run is determined by the subscription level.
5. title=What Is The Difference Between Elasticsearch Service And The Amazon Elasticsearch Service
score=0.9835054890793161
content=Elasticsearch Service is the only hosted and managed Elasticsearch service built, managed, and supported by the company behind Elasticsearch, Kibana, Beats, and Logstash. With Elasticsearch Service, you always get the latest versions of the software. Our service is built on best practices and years of experience hosting and managing thousands of Elasticsearch clusters in the Cloud and on premise. For more information, check the following Amazon and Elastic Elasticsearch Service comparison page.
Please note that there is no formal partnership between Elastic and Amazon Web Services (AWS), and Elastic does not provide any support on the AWS Elasticsearch Service.Conclusion
Using LlamaIndex, we demonstrated how to create an efficient FAQ search system with support for Elasticsearch as a vector database. Documents are ingested and indexed using embeddings, enabling vector searches. Through a PromptTemplate, the search results are incorporated into the context and sent to the LLM, which generates precise and contextualized responses based on the retrieved documents.
This workflow integrates information retrieval with contextualized response generation to deliver accurate and relevant results.
References
https://www.elastic.co/guide/en/cloud/current/ec-faq-getting-started.html
https://docs.llamaindex.ai/en/stable/api_reference/readers/elasticsearch/
https://docs.llamaindex.ai/en/stable/module_guides/indexing/vector_store_index/
https://docs.llamaindex.ai/en/stable/examples/query_engine/custom_query_engine/
https://www.elastic.co/search-labs/integrations/llama-index
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content

September 22, 2025
Elastic Open Web Crawler as a code
Learn how to use GitHub Actions to manage Elastic Open Crawler configurations, so every time we push changes to the repository, the changes are automatically applied to the deployed instance of the crawler.

August 6, 2025
How to display fields of an Elasticsearch index
Learn how to display fields of an Elasticsearch index using the _mapping and _search APIs, sub-fields, synthetic _source, and runtime fields.

July 14, 2025
Run Elastic Open Crawler in Windows with Docker
Learn how to use Docker to get Open Crawler working in a Windows environment.

June 24, 2025
Ruby scripting in Logstash
Learn about the Logstash Ruby filter plugin for advanced data transformation in your Logstash pipeline.

June 4, 2025
3 ingestion tips to change your search game forever
Get your Elasticsearch ingestion game to the next level by following these tips: data pre-processing, data enrichment and picking the right field types.