Red Hat validated pattern frameworks use GitOps for seamless provisioning of all operators and applications on Red Hat OpenShift. The Elasticsearch vector database is now officially supported by The ‘AI Generation with LLM and RAG’ Validated Pattern. This allows developers to jumpstart their app development using Elastic's vector database for retrieval-augmented generation (RAG) applications on OpenShift, combining the benefits of Red Hat's container platform with Elastic's vector search capabilities.
Getting started with Elastic in the Validated Pattern
Let's walk through setting up the pattern with Elasticsearch as your vector database:
Prerequisites
- Podman installed on your local system
- An OpenShift cluster running in AWS
- Your OpenShift pull secret
- OpenShift CLI (
oc) installed - An installation configuration file
Step 1: Fork the repository
Create a fork of the rag-llm-gitops repository.
Step 2: Clone the forked repository
Clone your forked repository and go to the root directory of the repository.
git clone git@github.com:your-username/rag-llm-gitops.git
cd rag-llm-gitopsStep 3: Configure and deploy
Create a local copy of the secret values file:
cp values-secret.yaml.template ~/values-secret-rag-llm-gitops.yamlConfigure the pattern to use Elasticsearch by editing the values-global.yaml file:
# Open the file in your favorite editor
vi values-global.yaml
# Look for the 'db' section under 'global':
# global:
# db:
# type: DEFAULT_VALUE
# Change the db.type from "EDB" (default) or "REDIS" to "ELASTIC"IF NECESSARY: Configure AWS settings (if your cluster is in an unsupported region):
mkdir -p ~/.aws
echo -e "[default]\nregion = <your-region>" > ~/.aws/configAdd GPU nodes to your cluster:
./pattern.sh make create-gpu-machinesetInstall the pattern:
./pattern.sh make installThe installation process automatically deploys:
- Pattern operator components
- HashiCorp Vault for secrets management
- Elasticsearch operator and cluster
- RAG application UI and backend
Step 4: Verify deployment
After installation completes, check that all components are running.
In the OpenShift web console, go to the Workloads > Pods menu. Select the rag-llm project from the drop-down.
The following pods should be up and running:

Alternatively, you can check via the CLI:
oc get pods -n rag-llmYou should see pods including:
elastic-operator- The Elasticsearch operatores-vectordb-es-default-0- The Elasticsearch clusterui-multiprovider-rag-redis- The RAG application UI (despite the name, it uses the configured database type, which in our case is Elastic)
Step 5: Try out the application
Navigate to the UI in your browser to start generating content with your RAG application backed by Elasticsearch.
From any page of your OpenShift console, click on the Application Menu and select the application:

Then:
- Select your configured LLM provider, or configure your own
- When configuring with OpenAI, the application appends the appropriate endpoint. So, in the ‘URL’ field, provide ‘https://api.openai.com/v1’ rather than ‘https://api.openai.com/v1/chat/completions’
- Enter the ‘Product’ as ‘RedHat OpenShift AI’
- Click “Generate”
- Watch as the Proposal is created for you in real-time

So what just happened?
When you deploy the pattern with Elasticsearch, here's what happens behind the scenes:
- The Elasticsearch operator is deployed to manage Elasticsearch resources
- An Elasticsearch cluster is provisioned with vector search capabilities
- Sample data is processed and stored as vector embeddings in Elasticsearch
- The RAG application is configured to connect to Elasticsearch for retrieval
- When you generate content, the application queries Elasticsearch to find relevant context for the LLM

What's next?
This initial integration showcases just the beginning of what's possible when you combine Elasticsearch vector search with OpenShift AI. Elastic brings rich information retrieval capabilities that make it ideal for production RAG applications, and we are considering the following for future enhancement:
- Advanced semantic understanding - Utilize Elastic's ELSER model for more accurate retrieval without fine-tuning
- Intelligent data processing using Elastic's native text chunking and preprocessing capabilities
- Hybrid search superiority - Combine vector embeddings with traditional keyword search and BM25 ranking for the most relevant results
- Production-ready monitoring - Leverage Elastic's comprehensive observability stack to monitor RAG application performance and gain insights into LLM usage patterns
We welcome feedback and contributions as we continue to bring powerful vector search capabilities to OpenShift AI applications! If you are at Red Hat Summit 2025, stop by Booth #1552 to learn more about Elastic!
Resources:
https://validatedpatterns.io/patterns/rag-llm-gitops/
https://validatedpatterns.io/patterns/rag-llm-gitops/deploying-different-db/
Ready to try this out on your own? Start a free trial.
Elasticsearch has integrations for tools from LangChain, Cohere and more. Join our advanced semantic search webinar to build your next GenAI app!
Related content

June 16, 2025
Elasticsearch open inference API adds support for IBM watsonx.ai rerank models
Exploring how to use IBM watsonx™ reranking when building search experiences in the Elasticsearch vector database.
June 13, 2025
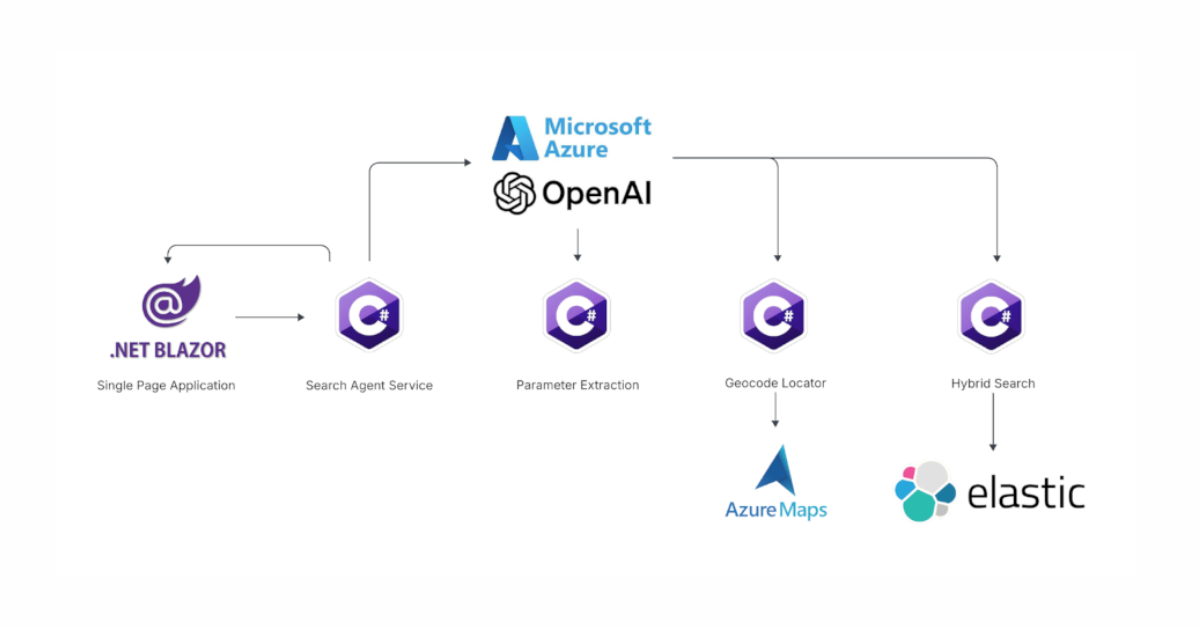
Using Azure LLM Functions with Elasticsearch for smarter query experiences
Try out the example real estate search app that uses Azure Gen AI LLM Functions with Elasticsearch to provide flexible hybrid search results. See step-by-step how to configure and run the example app in GitHub Codespaces.
June 17, 2025
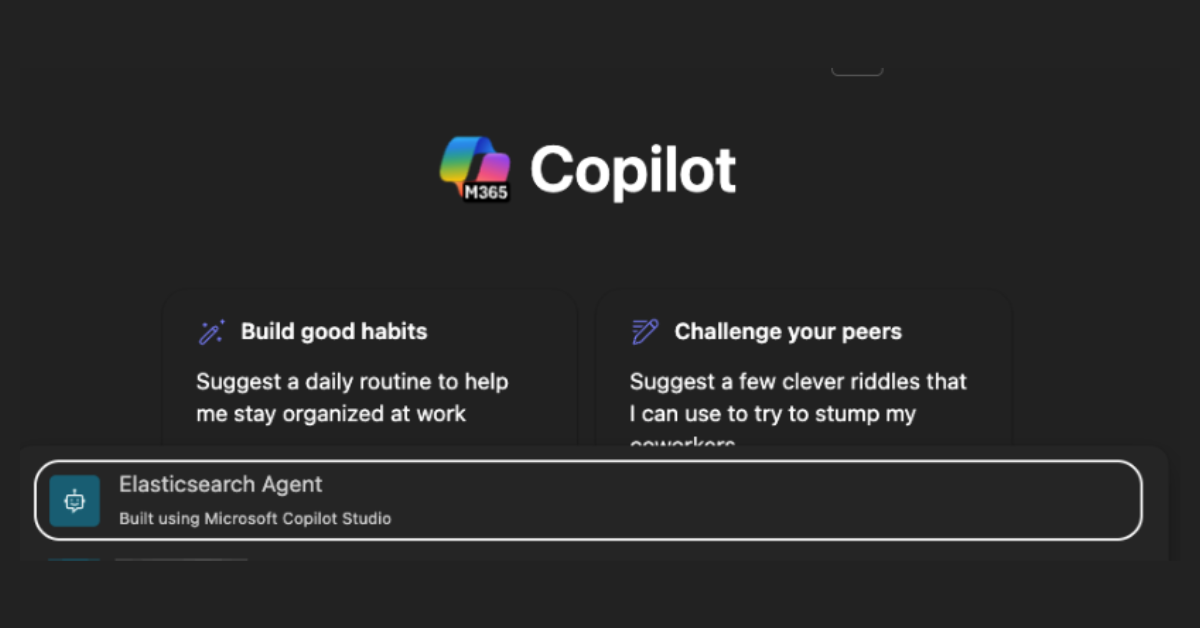
Improving Copilot capabilities using Elasticsearch
Discover how to use Elasticsearch with Microsoft 365 Copilot Chat and Copilot in Microsoft Teams.
June 5, 2025
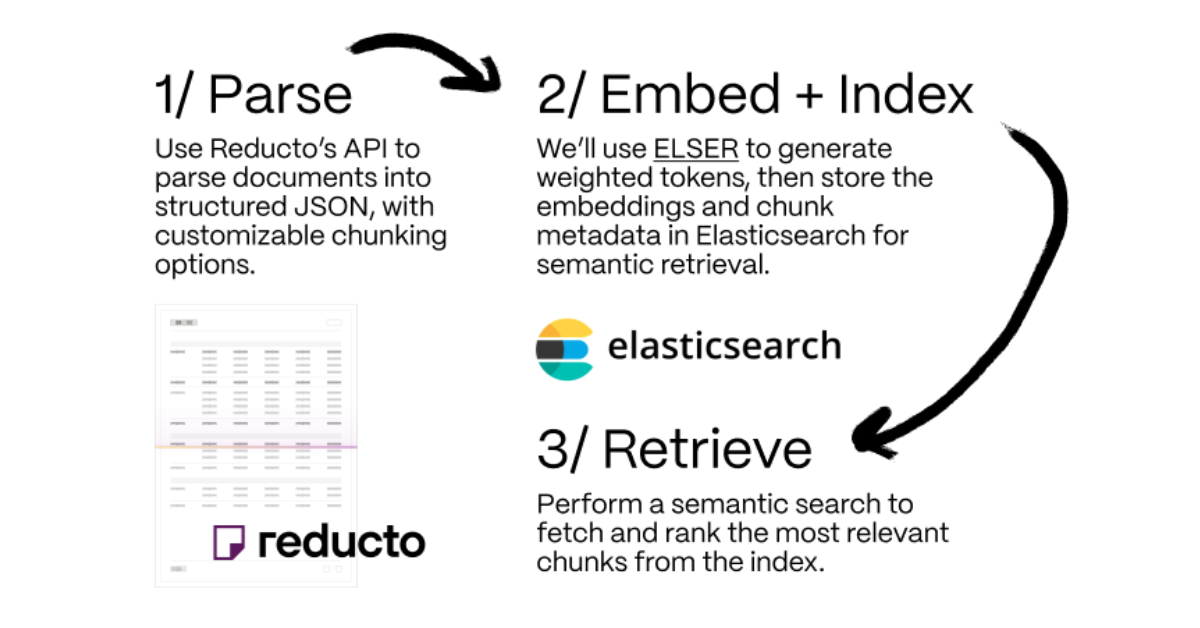
Making sense of unstructured documents: Using Reducto parsing with Elasticsearch
Demonstrating how Reducto's document processing can be integrated with Elasticsearch for semantic search.

May 21, 2025
First to hybrid search: with Elasticsearch and Semantic Kernel
Hybrid search capabilities are now available in the .NET Elasticsearch Semantic Kernel connector. Learn how to get started in this blog post.