Elasticsearch is a powerful search engine that provides fast and relevant search results by calculating a score for each document in the index. This score is a crucial factor in determining the order of the search results. In this article, we will delve into the scoring mechanism of Elasticsearch and explore the Explain API, which helps in understanding the scoring process.
Scoring mechanisms in Elasticsearch
Elasticsearch uses a scoring model called the Practical Scoring Function (BM25) by default. This model is based on the probabilistic information retrieval theory and takes into account factors such as term frequency, inverse document frequency, and field-length normalization. Let’s briefly discuss these factors:
- Term Frequency (TF): This represents the number of times a term appears in a document. A higher term frequency indicates a stronger relationship between the term and the document.
- Inverse Document Frequency (IDF): This factor measures the importance of a term in the entire document collection. A term that appears in many documents is considered less important, while a term that appears in fewer documents is considered more important.
- Field-length Normalization: This factor accounts for the length of the field in which the term appears. Shorter fields are given more weight, as the term is considered more significant in a shorter field.
Using the Explain API
The Explain API in Elasticsearch is a valuable tool for understanding the scoring process. It provides a detailed explanation of how the score for a specific document was calculated. To use the Explain API, you need to send a GET request to the following endpoint:
GET /<index>/_explain/<document_id>In the request body, you need to provide the query for which you want to understand the scoring. Here’s an example:
{
"query": {
"match": {
"title": "elasticsearch"
}
}
}The response from the Explain API will include a detailed breakdown of the scoring process, including the individual factors (TF, IDF, and field-length normalization) and their contributions to the final score. Here’s a sample response:
{
"_index": "example_index",
"_type": "_doc",
"_id": "1",
"matched": true,
"explanation": {
"value": 1.2,
"description": "weight(title:elasticsearch in 0) [PerFieldSimilarity], result of:",
"details": [
{
"value": 1.2,
"description": "score(doc=0,freq=1.0 = termFreq=1.0\n), product of:",
"details": [
{
"value": 2.2,
"description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:",
"details": [
{
"value": 1,
"description": "docFreq",
"details": []
},
{
"value": 1,
"description": "docCount",
"details": []
}
]
},
{
"value": 0.5,
"description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:",
"details": [
{
"value": 1,
"description": "termFreq=1.0",
"details": []
},
{
"value": 1.2,
"description": "parameter k1",
"details": []
},
{
"value": 0.75,
"description": "parameter b",
"details": []
},
{
"value": 1,
"description": "avgFieldLength",
"details": []
},
{
"value": 1,
"description": "fieldLength",
"details": []
}
]
}
]
}
]
}
}In this example, the response shows that the score of 1.2 is a product of the IDF value (2.2) and the tfNorm value (0.5). The detailed explanation helps in understanding the factors contributing to the score and can be useful for fine-tuning the search relevance.
Conclusion
Elasticsearch scoring is a critical aspect of providing relevant search results. By understanding the scoring mechanisms and using the Explain API, you can gain insights into the factors affecting the search results and optimize your search queries for better relevance and performance.
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content
September 5, 2025
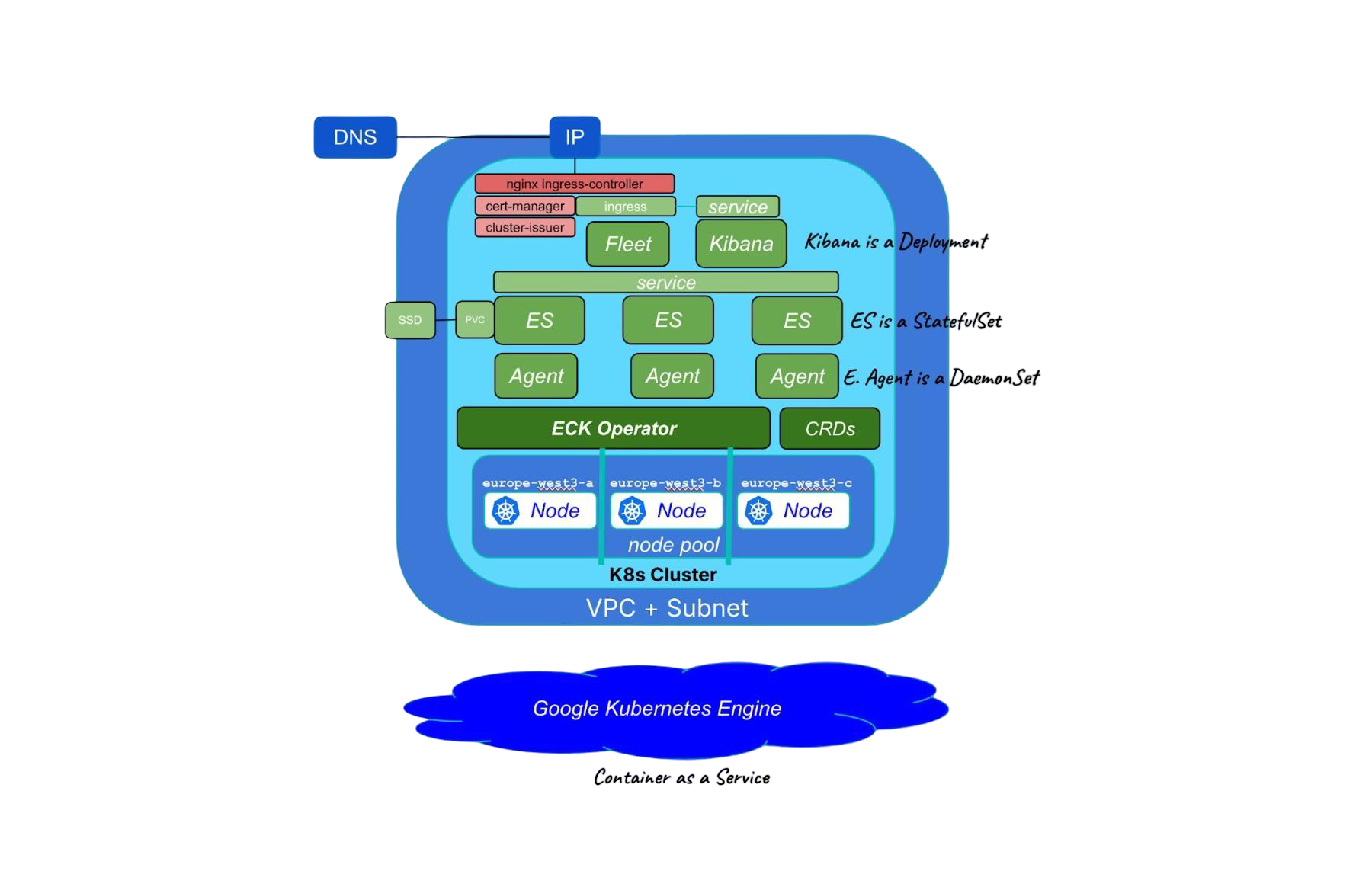
Running cloud-native Elasticsearch with ECK
Learn how to provision a GKE cluster with Terraform and run the Elastic Stack on Kubernetes using ECK.
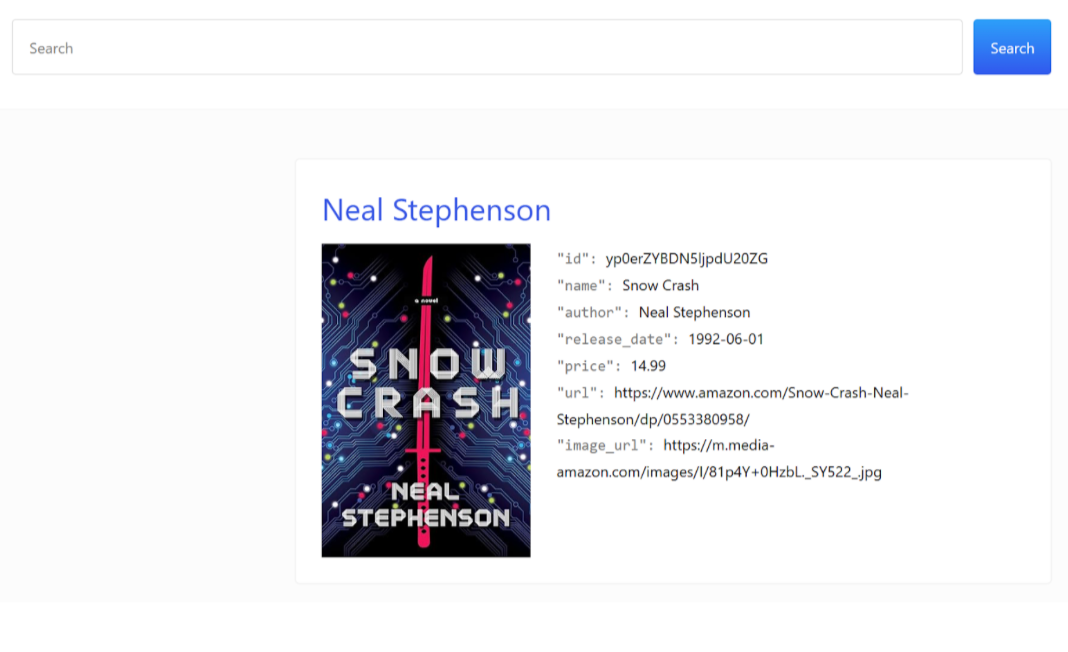
September 1, 2025
Using UBI in Elasticsearch: Creating an app with UBI and search-ui
Learn how to use UBI in Elasticsearch through a practical example. We’ll be creating an application that produces UBI events on search and click results.
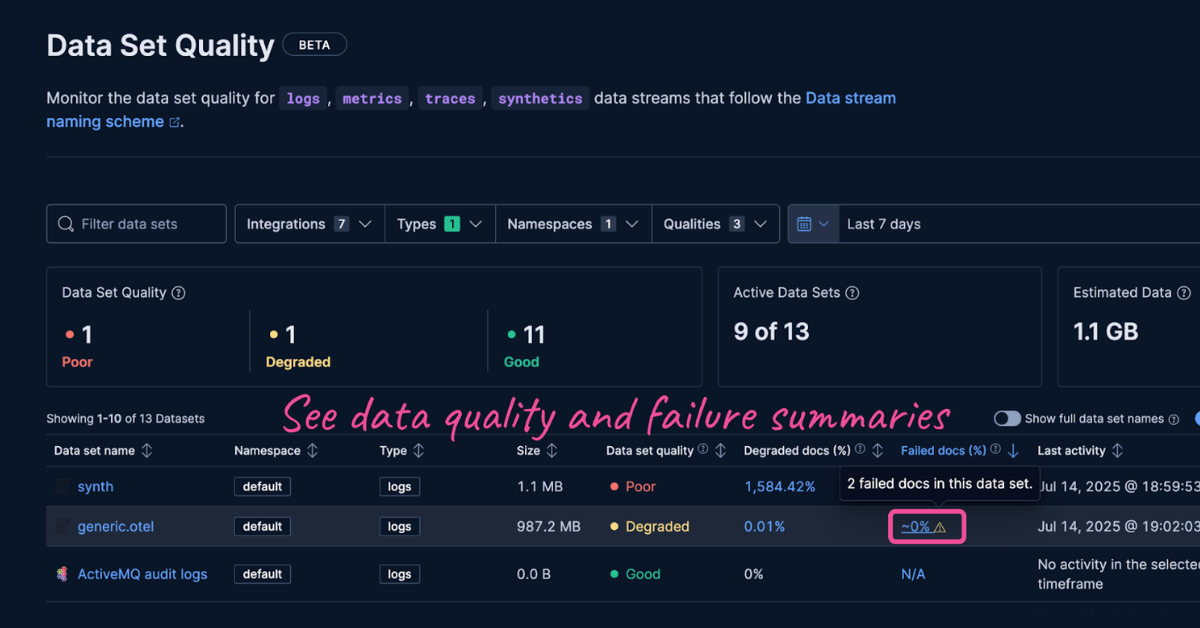
August 13, 2025
Failure store: see what didn’t make it
Learn about failure store, a new feature in the Elastic Stack that captures and indexes previously lost events.

August 14, 2025
Elasticsearch shards and replicas: A practical guide
Master the concepts of Elasticsearch shards and replicas and learn how to optimize them.

August 4, 2025
Working with your App Search data in a post Enterprise Search world
With Enterprise Search decommissioned in the Elastic Stack version 9, you can still work with your existing App Search data—we’ll show you how.