Hybrid search combines traditional lexical search with semantic search, allowing results to benefit from both precision and contextual understanding. By adding a reranker, you can reorder the retrieved documents to display the most relevant ones first. With Elasticsearch, you can build this whole system within the same cloud provider—in this case, Google Cloud Platform (GCP).

In this article, you’ll learn how to create an application to query articles from a mock encyclopedia in Playground using Elasticsearch Cloud Serverless on GCP and Vertex AI. We chose Serverless because it is fully managed and autoscaled, but using Elastic Cloud on GCP also serves the purpose of this article.
For embedding, we’ll use the gemini-embedding-001 model, which generates vectors of up to 3,072 dimensions (you can adjust this to 1,536 or 768 with MRL). The model can handle up to 2,048 tokens per input, and supports over 100 languages. Embeddings turn text into numerical vectors that capture meaning and context, making it possible to compare queries and documents semantically rather than just by exact words.
Then, we’ll use the semantic-ranker-fast-004 model as the reranker. This is the low-latency variant of the Ranking API, designed to reorder results without compromising speed. After an initial retrieval step, rerankers take the candidate results and reorder them so that the most relevant ones appear at the top.
For Completions/Chat, we’ll use gemini-2.5-flash-lite. This is a model optimized for high speed and low cost. It has thinking capacities, supports very long contexts (up to 1M tokens), enables tools for running code, offers grounding with Google Search, and provides multimodal support. The completions model is designed for generating answers in natural language.
GCP preparation
To be able to use the Vertex AI models, you’ll need to have a GCP service account. If you don’t have an account, you can follow this tutorial, which also creates a Vertex AI connection to use as RAG in Kibana’s Playground.
If you already have one, you skip the tutorial, but make sure you have the authentication JSON file at hand and that the account has the following roles:
- Vertex AI User
- Service Account Token Creator
- Discovery Engine Viewer
- AI Platform Developer
Elasticsearch Serverless installation
To build our app, you’ll first create an Elasticsearch Serverless deployment. If you don’t have an account, you can register for free here.
Enter the information requested and select the Search use case to continue with this tutorial.
When asked about the deployment type, select Elastic Cloud Serverless and then select Google Cloud as the provider in US Central 1 (Iowa).
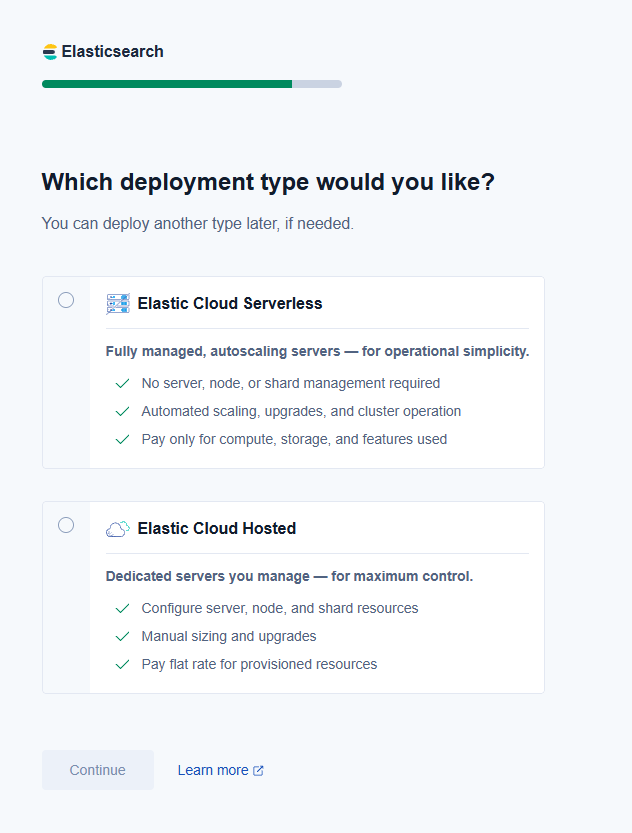
Elasticsearch Cloud Serverless removes the need to plan for capacity or manage deployments by automatically adapting to demand and optimizing performance based on load. Its design allows you to integrate services like Vertex AI to benefit from hybrid searches and advanced processing without worrying about the underlying infrastructure. This makes it ideal for workflows where fast iterations are key.
Creating AI connectors
Once we have deployed Elastic Cloud Serverless and have access to Vertex AI, we can create the AI connectors. These are the links between Elasticsearch and the models.
In the Kibana connectors screen (you have to access from the vertical menu, go to Management > Stack Management > Alerts and Insights > Connectors), create a connector and select AI Connector as the type.
We need to create one connector for each of the model capabilities we want to use: text_embedding, rerank, and chat_completion. Since all come from Vertex AI, the configurations are almost identical; you just need to change the type of connector and the model’s ID.
- text_embedding: This task receives text and returns the vector embeddings of that text. It is used on ingestion to store the embeddings and then to convert the search query into embeddings.
- rerank: The input of this task is a query and an array of candidates. The output is the list of candidates, ranked by the relevance relative to the query.
- chat_completion: Chat completion will receive an array of messages of different types (System, User, Assistant, etc.) and use an LLM to generate an incremental answer based on the conversation provided.
These are the parameters we need to configure for the three connectors:
- Connector name: Vertex AI.
- Service: Google Vertex AI.
- JSON Credentials: Here, you need to copy/paste the access key of the GCP service account.
- GCP Project: ID of the project that has the service account and the Vertex AI models.
- GCP Region: us-central1 (same as the Elastic Cloud Serverless deployment).
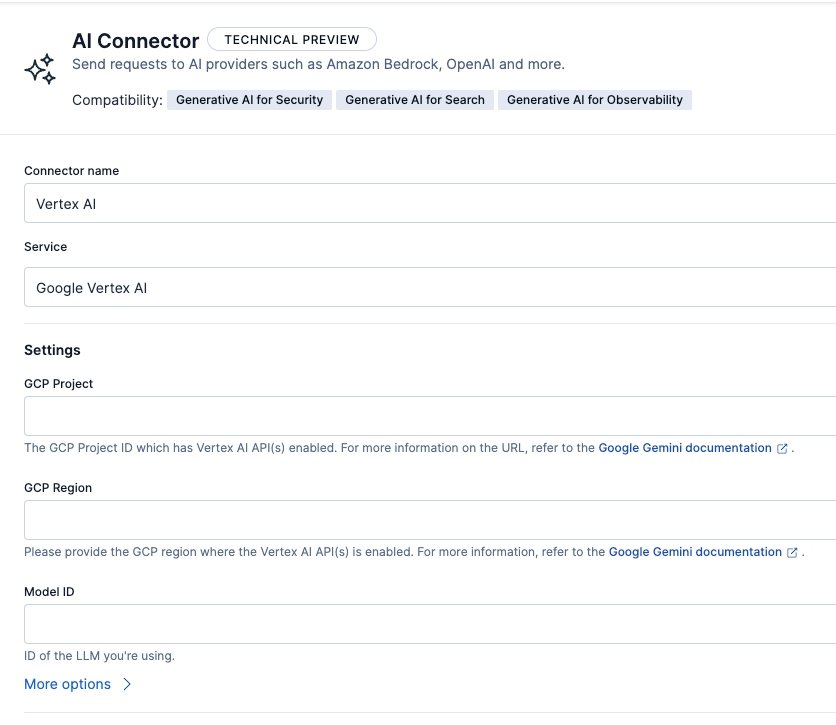
Below is the specific configuration for each connector:
- Embeddings
- Connector name: Vertex AI - Embeddings.
- Model ID: gemini-embedding-001.
- Task type: chat_completion. This type of connector transforms text into numerical vectors that can be stored and searched in Elasticsearch. We use it since we need to represent our documents and queries in a vector space to enable semantic search and combine it with BM25 in hybrid search.
- Inference Endpoint: vertex_embeddings
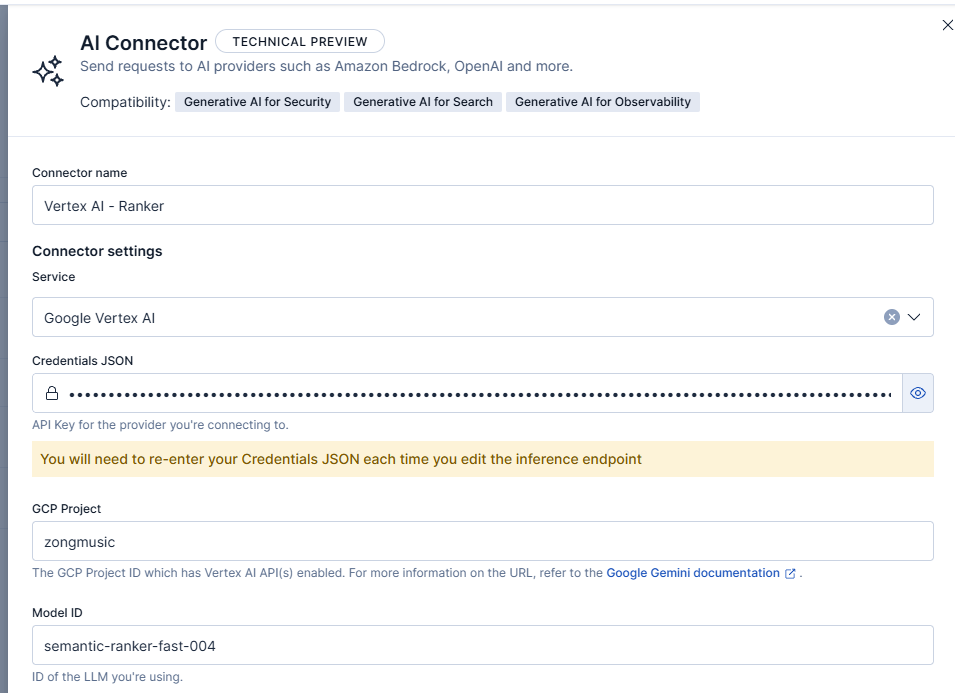
- Reranker
- Connector name: Vertex AI - Ranker.
- Model ID: semantic-ranker-fast-004.
- Task type: rerank. This type is designed to get a set of initial results and return them sorted by relevance. We use it since we show the results ranked better using a model.
- Inference Endpoint: vertex_ranker
- Completions/Chat
- Connector name: Vertex AI - Chat.
- Model ID: gemini-2.5-flash-lite.
- Task type: chat_completion. This type allows you to send a message and get an answer generated by the model. We use it for the final RAG phase, where the model generates a natural-language-based answer in a chat.
- Inference Endpoint: vertex_chat
For example, the rerank connector configuration should look like this:
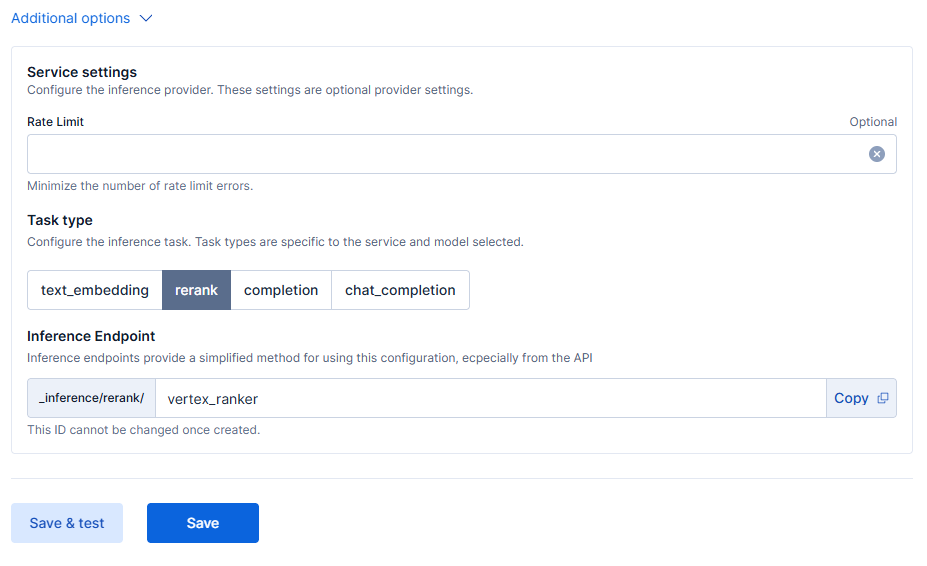
And here are the additional parameters:
Data ingestion
To test the capabilities of the models we’re configuring, we’ll index information from a mock encyclopedia that has information on several topics. You can download the dataset here.
The documents we’re indexing have this format:
{
"title":"Why the Sky Appears Blue",
"author":"Daniel Wright",
"content":"Sunlight looks white, but it contains many colors. As that light passes through Earth’s atmosphere it collides with tiny gas molecules. The shorter, bluer wavelengths scatter much more strongly than the longer, redder ones, so blue light is sent to your eyes from every direction and the sky appears blue.\n\nAt sunrise and sunset, sunlight travels through a longer slice of atmosphere. Along that path, much of the blue light is scattered out before it reaches you, leaving the transmitted light enriched in reds and oranges—hence the warm colors near the horizon.",
"date":"2023-10-05"
}On the side menu, go to Elasticsearch > Home > Upload a file.
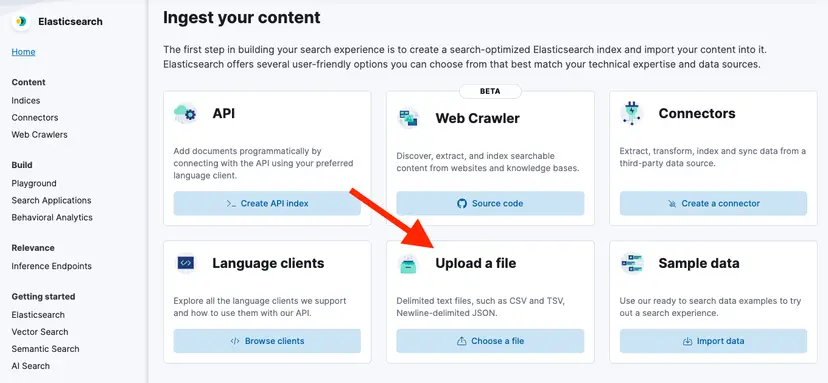
Then, click Upload a file and select the file you’ve just downloaded.
Now click the blue Import button, and in the next menu, select the “Advanced” tab and name the index: “encyclopedia_articles.”
Then, select Add additional field, choose Add semantic text field, and set the inference endpoint to vertex_embeddings, and the field to content, like this:
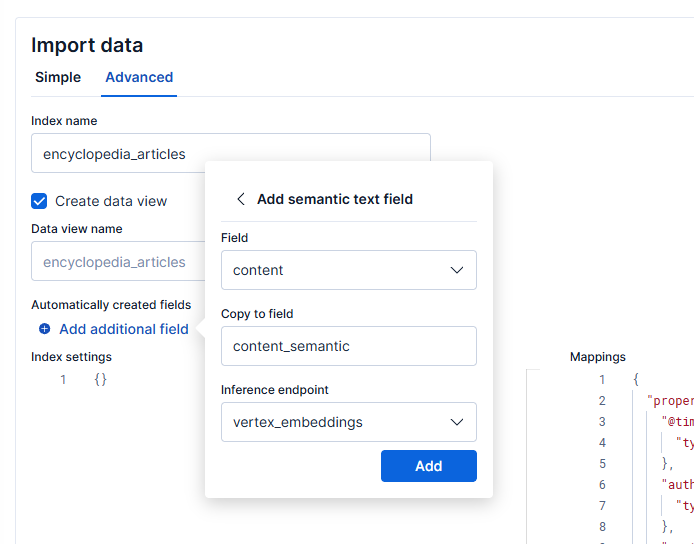
This will create a field that will store the vector generated from each document, allowing you to run semantic searches using the embeddings model we’ve just configured.
Finally, click Add, and finish creating the index by clicking Import. Once you’re done, you’ll see a screen with the index importing status, which should look like this:
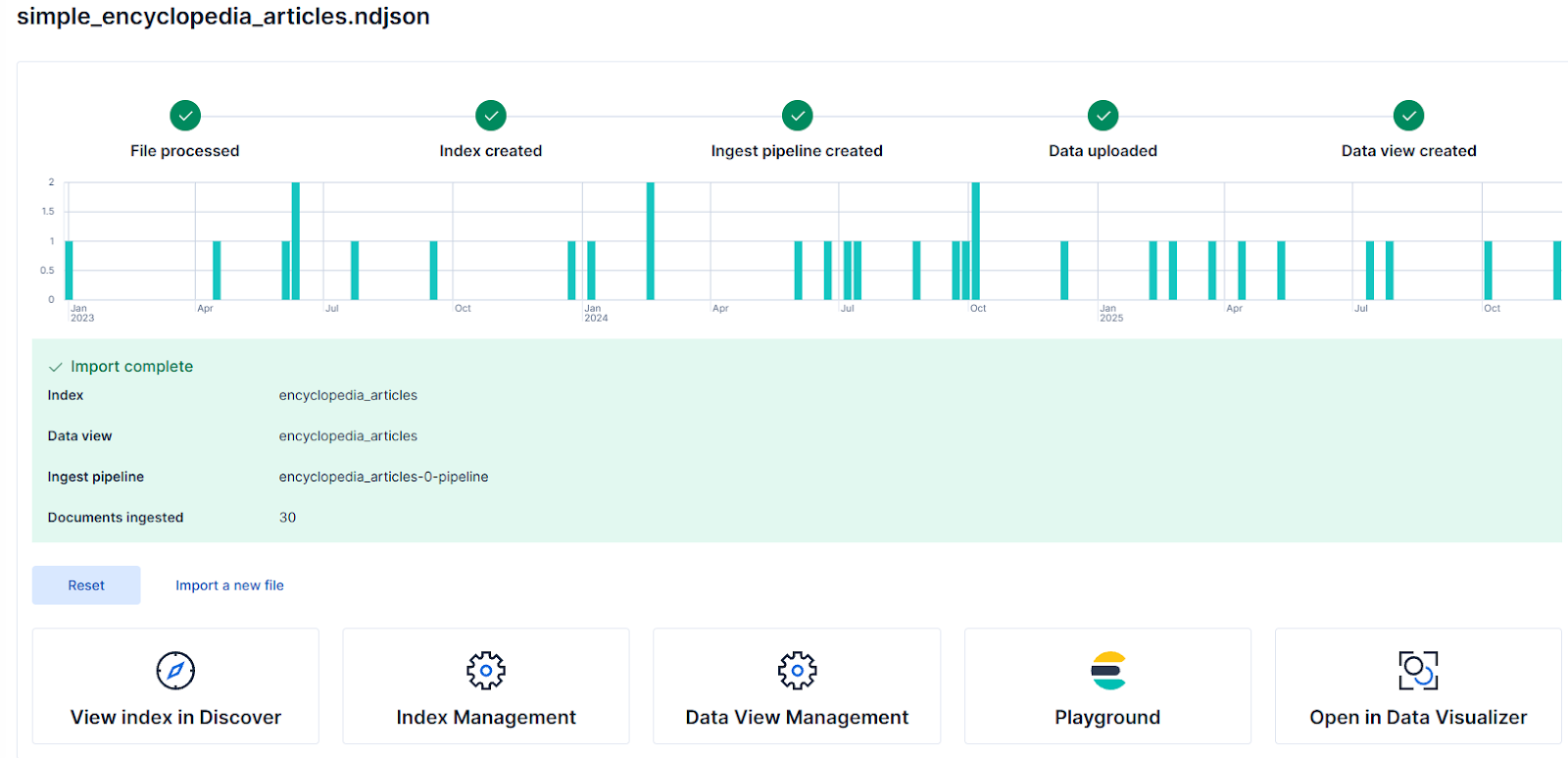
Hybrid query
A hybrid query is a combination of lexical search and semantic search, leveraging the benefits of both strategies: the keyword precision of lexical search and the ability of semantic search to capture similar concepts.
Hybrid queries allow us to cover both users who know exactly what they are looking for and use exact keywords, as well as users who are less certain and search for related words or concepts to those present in our index documents. You can learn more about hybrid search in this article.
On top of the hybrid search, we’ll place a reranker. This reranker will give a last pass to the top results, ranking them based on their relevance to the query using a specialized model.
We’ll now use the retriever functionality with RRF and a semantic reranker to leverage semantic search, text search, and reranking in a single API call.
Go to Kibana DevTools (Side menu > Developer Tools) and run this query:
{
"retriever": {
"text_similarity_reranker": {
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"match": {
"content": "gas refrigerators"
}
}
}
},
{
"standard": {
"query": {
"semantic": {
"query": "gas refrigerators",
"field": "content_semantic"
}
}
}
}
]
}
},
"field": "content",
"rank_window_size": 10,
"inference_id": "vertex_ranker",
"inference_text": "gas refrigerators",
"min_score": 0.1
}
}
}This query combines semantic and text search with an RRF, and then uses vertex_ranker to order the results based on their relevance, which was calculated by the model. The rank_window_size controls how many initial results will be evaluated during the ranking stage, while min_score filters the documents with low scores.
Playground
To use our data in RAG, go to Kibana’s Playground and use the Gemini model we previously connected. On the side menu, go to Elasticsearch > Playground.
On the Playground screen, you should see a green checkmark and the text “LLM Connected” if the connector exists. You can refer to a more extensive Playground guide here.
Click the “Data” button and choose the encyclopedia_articles index we’ve just created.
Now, any question you ask the LLM will be answered based on the index you selected and will include references to the documents used to generate the answer.
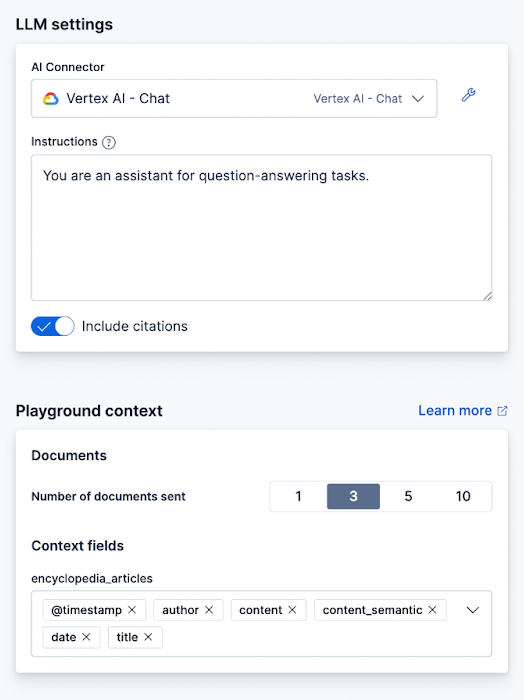
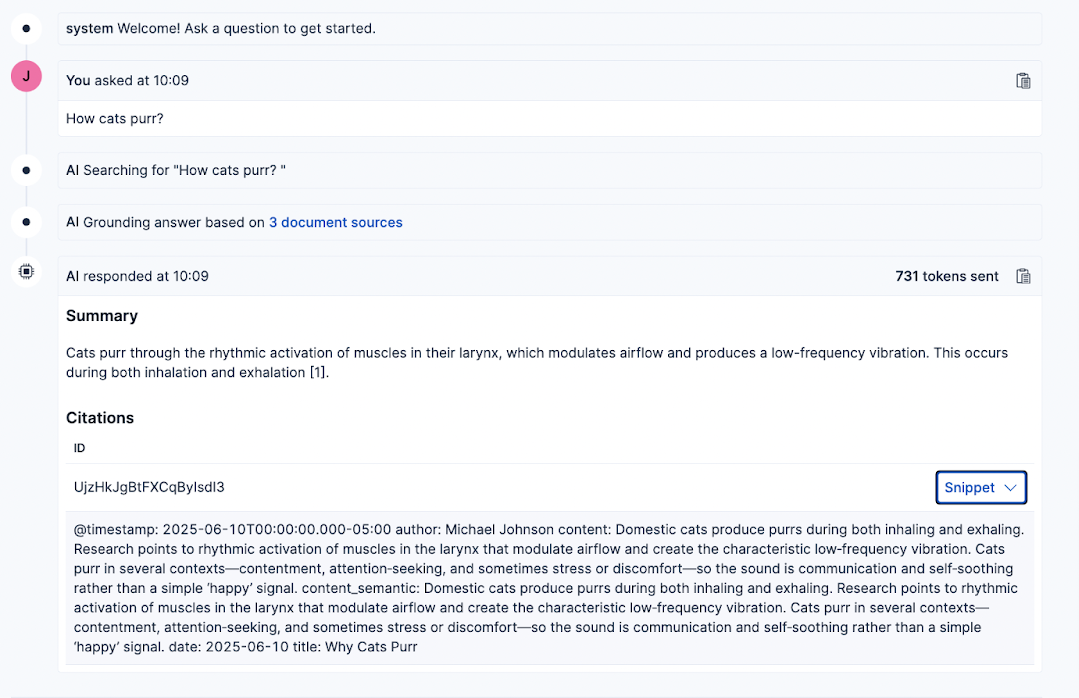
In Playground, we can edit the Elasticsearch query used to get the context for the answers. Click the Query button at the top of the page.
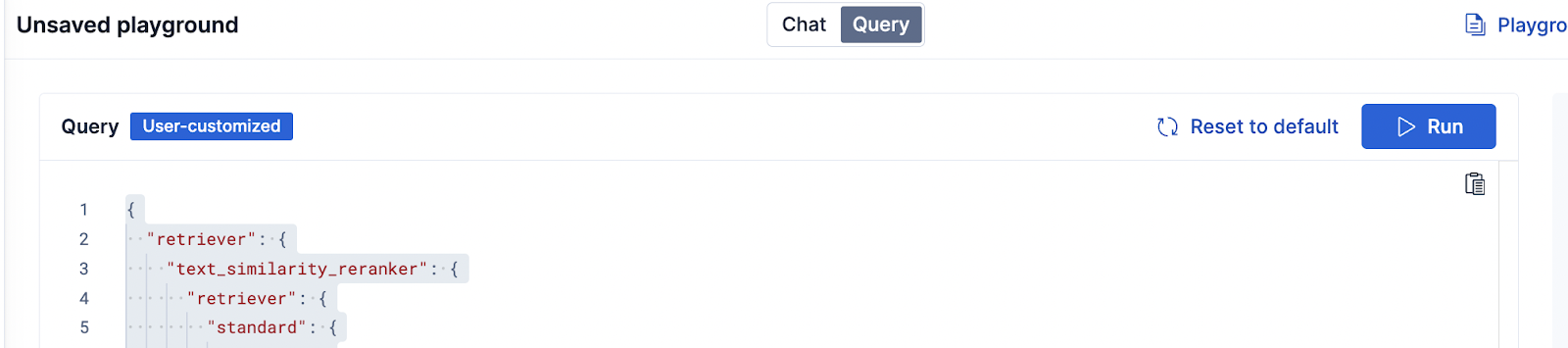
We can add the same functionalities we just covered. Below is an example of the reranking functionality:
{
"retriever": {
"text_similarity_reranker": {
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"match": {
"content": "{query}"
}
}
}
},
{
"standard": {
"query": {
"semantic": {
"field": "content_semantic",
"query": "{query}"
}
}
}
}
],
"rank_constant": 60
}
},
"field": "content",
"rank_window_size": 25,
"inference_id": "vertex_ranker",
"inference_text": "Articles about animals",
"min_score": 1
}
},
"highlight": {
"fields": {
"content_semantic": {
"type": "semantic",
"number_of_fragments": 2,
"order": "score"
}
}
}
}Deploy to Google Cloud Run
Once you’re satisfied with how the app works in Playground, you can deploy the code to Google Cloud Run so your app can be accessed by an external API.
To begin, in the upper right corner of Playground, click View Code.
There, you’ll find a script detailing the libraries and workflow needed to build your own RAG application. You can pick between a LangChain implementation or the OpenAI client. We chose LangChain because it allows us to switch LLM models easily.
You can learn how to deploy the code in Google Cloud Run by following this tutorial: Build and deploy a LangChain app on Cloud Run. Pay special attention to step no. 6: Write the web application.
Conclusion
With Elasticsearch and the GCP models, you can build a RAG application from start to end to index information, perform semantic searches, reorder results based on relevance, and generate answers based on these features—all within an integrated workflow on Google Cloud Platform.
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content

October 30, 2025
Context engineering using Mistral Chat completions in Elasticsearch
Learn how to utilize context engineering with Mistral Chat completions in Elasticsearch to ground LLM responses in domain-specific knowledge for accurate outputs.
October 27, 2025
Building agentic applications with Elasticsearch and Microsoft’s Agent Framework
Learn how to use Microsoft Agent Framework with Elasticsearch to build an agentic application that extracts ecommerce data from Elasticsearch client libraries using ES|QL.
October 21, 2025
Introducing Elastic’s Agent Builder
Introducing Elastic Agent Builder, a framework to easily build reliable, context-driven AI agents in Elasticsearch with your data.

October 20, 2025
Elastic MCP server: Expose Agent Builder tools to any AI agent
Discover how to use the built-in Elastic MCP server in Agent Builder to securely extend any AI agent with access to your private data and custom tools.
How to use the Synonyms UI to upload and manage Elasticsearch synonyms
Learn how to use the Synonyms UI in Kibana to create synonym sets and assign them to indices.