In this article, we'll learn how to connect local models to the Elasticsearch inference model using Ollama and then ask your documents questions using Playground.
Elasticsearch allows users to connect to LLMs using the Open Inference API, supporting providers such as Amazon Bedrock, Cohere, Google AI, Azure AI Studio, HuggingFace - as a service, among others.
Ollama is a tool that allows you to download and execute LLM models using your own infrastructure (your local machine/server). Here you can find a list of the available models that are compatible with Ollama.
Ollama is a great option if you want to host and test different open source models without having to worry about the different ways each of the models could have to be set up, or about how to create an API to access the model functions as Ollama takes care of everything.
Since the Ollama API is compatible with the OpenAI API, we can easily integrate the inference model and create a RAG application using Playground.
Prerequisites
- Elasticsearch 8.17
- Kibana 8.17
- Python
Steps
Setting up Ollama LLM server
We're going to set up a LLM server to connect it to our Playground instance using Ollama. We'll need to:
- Download and run Ollama.
- Use ngrok to access your local web server that hosts Ollama over the internet
Download and run Ollama
To use Ollama, we first need to download it. Ollama offers support for Linux, Windows, and macOS so just download the Ollama version compatible with your OS here. Once Ollama is installed, we can choose a model from this list of supported LLMs. In this example, we'll use the model llama3.2, a general multilanguage model. In the setup process, you will enable the command line tool for Ollama. Once that’s downloaded you can run the following line:
ollama pull llama3.2Which will output:
pulling manifest
pulling dde5aa3fc5ff... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████▏ 2.0 GB
pulling 966de95ca8a6... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████▏ 1.4 KB
pulling fcc5a6bec9da... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████▏ 7.7 KB
pulling a70ff7e570d9... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████▏ 6.0 KB
pulling 56bb8bd477a5... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████▏ 96 B
pulling 34bb5ab01051... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████▏ 561 B
verifying sha256 digest
writing manifest
successOnce installed, you can test it with this command:
ollama run llama3.2Let's ask a question:

With the model running, Ollama enables an API that would run by default on port "11434". Let's make a request to that API, following the official documentation:
curl http://localhost:11434/api/generate -d '{
"model": "llama3.2",
"prompt": "What is the capital of France?"
}'This is the response we got:
{"model":"llama3.2","created_at":"2024-11-28T21:48:42.152817532Z","response":"The","done":false}
{"model":"llama3.2","created_at":"2024-11-28T21:48:42.251884485Z","response":" capital","done":false}
{"model":"llama3.2","created_at":"2024-11-28T21:48:42.347365913Z","response":" of","done":false}
{"model":"llama3.2","created_at":"2024-11-28T21:48:42.446837322Z","response":" France","done":false}
{"model":"llama3.2","created_at":"2024-11-28T21:48:42.542367394Z","response":" is","done":false}
{"model":"llama3.2","created_at":"2024-11-28T21:48:42.644580384Z","response":" Paris","done":false}
{"model":"llama3.2","created_at":"2024-11-28T21:48:42.739865362Z","response":".","done":false}
{"model":"llama3.2","created_at":"2024-11-28T21:48:42.834347518Z","response":"","done":true,"done_reason":"stop","context":[128006,9125,128007,271,38766,1303,33025,2696,25,6790,220,2366,18,271,128009,128006,882,128007,271,3923,374,279,6864,315,9822,30,128009,128006,78191,128007,271,791,6864,315,9822,374,12366,13],"total_duration":6948567145,"load_duration":4386106503,"prompt_eval_count":32,"prompt_eval_duration":1872000000,"eval_count":8,"eval_duration":684000000}Note that the specific response for this endpoint is a streaming.
Expose endpoint to the internet using ngrok
Since our endpoint works in a local environment, it cannot be accessed from another point–like our Elastic Cloud instance–via the internet. ngrok allows us to expose a port offering a public IP. Create an account in ngrok and follow the official setup guide.
Once the ngrok agent has been installed and configured, we can expose the port Ollama is using:
ngrok http 11434 --host-header="localhost:11434"Note: The header --host-header="localhost:11434" guarantees that the "Host" header in the requests matches "localhost:11434"
Executing this command will return a public link that will work as long as the ngrok and the Ollama server run locally.
Session Status online
Account xxxx@yourEmailProvider.com (Plan: Free)
Version 3.18.4
Region United States (us)
Latency 561ms
Web Interface http://127.0.0.1:4040
Forwarding https://your-ngrok-url.ngrok-free.app -> http://localhost:11434
Connections ttl opn rt1 rt5 p50 p90
0 0 0.00 0.00 0.00 0.00 ```In "Forwarding" we can see that ngrok generated a URL. Save it for later.
Let's try making an HTTP request to the endpoint again, now using the ngrok-generated URL:
curl https://your-ngrok-endpoint.ngrok-free.app/api/generate -d '{
"model": "llama3.2",
"prompt": "What is the capital of France?"
}'The response should be similar to the previous one.
Creating mappings
ELSER endpoint
For this example, we'll create an inference endpoint using the Elasticsearch inference API. Additionally, we'll use ELSER to generate the embeddings.
PUT _inference/sparse_embedding/medicines-inference
{
"service": "elasticsearch",
"service_settings": {
"num_allocations": 1,
"num_threads": 1,
"model_id": ".elser_model_2_linux-x86_64"
}
}For this example, let's imagine that you have a pharmacy that sells two types of drugs:
- Drugs that require a prescription.
- Drugs that DO NOT require a prescription.
This information would be included in the description field of each drug.
The LLM must interpret this field, so this is the data mappings we'll use:
PUT medicines
{
"mappings": {
"properties": {
"name": {
"type": "text",
"copy_to": "semantic_field"
},
"semantic_field": {
"type": "semantic_text",
"inference_id": "medicines-inference"
},
"text_description": {
"type": "text",
"copy_to": "semantic_field"
}
}
}
}The field text_description will store the plain text of the descriptions while semantic_field, which is a semantic_text field type, will store the embeddings generated by ELSER.
The property copy_to will copy the content from the fields name and text_description into the semantic field so that the embeddings for those fields are generated.
Indexing data
Now, let's index the data using the _bulk API.
POST _bulk
{"index":{"_index":"medicines"}}
{"id":1,"name":"Paracetamol","text_description":"An analgesic and antipyretic that does NOT require a prescription."}
{"index":{"_index":"medicines"}}
{"id":2,"name":"Ibuprofen","text_description":"A nonsteroidal anti-inflammatory drug (NSAID) available WITHOUT a prescription."}
{"index":{"_index":"medicines"}}
{"id":3,"name":"Amoxicillin","text_description":"An antibiotic that requires a prescription."}
{"index":{"_index":"medicines"}}
{"id":4,"name":"Lorazepam","text_description":"An anxiolytic medication that strictly requires a prescription."}
{"index":{"_index":"medicines"}}
{"id":5,"name":"Omeprazole","text_description":"A medication for stomach acidity that does NOT require a prescription."}
{"index":{"_index":"medicines"}}
{"id":6,"name":"Insulin","text_description":"A hormone used in diabetes treatment that requires a prescription."}
{"index":{"_index":"medicines"}}
{"id":7,"name":"Cold Medicine","text_description":"A compound formula to relieve flu symptoms available WITHOUT a prescription."}
{"index":{"_index":"medicines"}}
{"id":8,"name":"Clonazepam","text_description":"An antiepileptic medication that requires a prescription."}
{"index":{"_index":"medicines"}}
{"id":9,"name":"Vitamin C","text_description":"A dietary supplement that does NOT require a prescription."}
{"index":{"_index":"medicines"}}
{"id":10,"name":"Metformin","text_description":"A medication used for type 2 diabetes that requires a prescription."}Response:
{
"errors": false,
"took": 34732020848,
"items": [
{
"index": {
"_index": "medicines",
"_id": "mYoeMpQBF7lnCNFTfdn2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1,
"status": 201
}
},
{
"index": {
"_index": "medicines",
"_id": "mooeMpQBF7lnCNFTfdn2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1,
"status": 201
}
},
{
"index": {
"_index": "medicines",
"_id": "m4oeMpQBF7lnCNFTfdn2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 1,
"status": 201
}
},
{
"index": {
"_index": "medicines",
"_id": "nIoeMpQBF7lnCNFTfdn2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 3,
"_primary_term": 1,
"status": 201
}
},
{
"index": {
"_index": "medicines",
"_id": "nYoeMpQBF7lnCNFTfdn2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 4,
"_primary_term": 1,
"status": 201
}
},
{
"index": {
"_index": "medicines",
"_id": "nooeMpQBF7lnCNFTfdn2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 5,
"_primary_term": 1,
"status": 201
}
},
{
"index": {
"_index": "medicines",
"_id": "n4oeMpQBF7lnCNFTfdn2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 6,
"_primary_term": 1,
"status": 201
}
},
{
"index": {
"_index": "medicines",
"_id": "oIoeMpQBF7lnCNFTfdn2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 7,
"_primary_term": 1,
"status": 201
}
},
{
"index": {
"_index": "medicines",
"_id": "oYoeMpQBF7lnCNFTfdn2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 8,
"_primary_term": 1,
"status": 201
}
},
{
"index": {
"_index": "medicines",
"_id": "oooeMpQBF7lnCNFTfdn2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 9,
"_primary_term": 1,
"status": 201
}
}
]
}Asking questions using Playground
Playground is a Kibana tool that allows you to quickly create a RAG system using Elasticsearch indexes and a LLM provider. You can read this article to learn more about it.
Connecting the local LLM to Playground
We first need to create a connector that uses the public URL we've just created. In Kibana, go to Search>Playground and then click on "Connect to an LLM".

This action will reveal a menu on the left side of the Kibana interface. There, click on "OpenAI".

We can now start configuring the OpenAI connector.
Go to "Connector settings" and for the OpenAI provider, select "Other (OpenAI Compatible Service)":

Now, let's configure the other fields. For this example, we'll name our model "medicines-llm". In the URL field, use the one generated by ngrok (/v1/chat/completions). On the "Default model" field, select "llama3.2". We won't use an API Key so just put any random text to proceed:

Click on "Save" and add the index medicines by clicking on "Add data sources":


Great! We now have access to Playground using the LLM we're running locally as RAG engine.

Before testing it, let's add more specific instructions to the agent and up the number of documents sent to the model to 10, so that the answer has the most possible documents available. The context field will be semantic_field, which includes the name and description of the drugs, thanks to the copy_to property.

Now let's ask the question: Can I buy Clonazepam without a prescription? and see what happens:
As expected, we got the correct answer.
Next steps
The next step is to create your own application! Playground provides a code script in Python that you can run on your machine and customize it to meet your needs. For example, by putting it behind a FastAPI server to create a QA medicines chatbot consumed by your UI.
You can find this code by clicking the View code button in the top right section of Playground:

And you use the Endpoints & API keys to generate the ES_API_KEY environment variable required in the code.
For this particular example the code is the following:
## Install the required packages
## pip install -qU elasticsearch openai
import os
from elasticsearch import Elasticsearch
from openai import OpenAI
es_client = Elasticsearch(
"https://your-deployment.us-central1.gcp.cloud.es.io:443",
api_key=os.environ["ES_API_KEY"]
)
openai_client = OpenAI(
api_key=os.environ["OPENAI_API_KEY"],
)
index_source_fields = {
"medicines": [
"semantic_field"
]
}
def get_elasticsearch_results():
es_query = {
"retriever": {
"standard": {
"query": {
"nested": {
"path": "semantic_field.inference.chunks",
"query": {
"sparse_vector": {
"inference_id": "medicines-inference",
"field": "semantic_field.inference.chunks.embeddings",
"query": query
}
},
"inner_hits": {
"size": 2,
"name": "medicines.semantic_field",
"_source": [
"semantic_field.inference.chunks.text"
]
}
}
}
}
},
"size": 3
}
result = es_client.search(index="medicines", body=es_query)
return result["hits"]["hits"]
def create_openai_prompt(results):
context = ""
for hit in results:
inner_hit_path = f"{hit['_index']}.{index_source_fields.get(hit['_index'])[0]}"
## For semantic_text matches, we need to extract the text from the inner_hits
if 'inner_hits' in hit and inner_hit_path in hit['inner_hits']:
context += '\n --- \n'.join(inner_hit['_source']['text'] for inner_hit in hit['inner_hits'][inner_hit_path]['hits']['hits'])
else:
source_field = index_source_fields.get(hit["_index"])[0]
hit_context = hit["_source"][source_field]
context += f"{hit_context}\n"
prompt = f"""
Instructions:
- You are an assistant specializing in answering questions about the sale of medicines.
- Answer questions truthfully and factually using only the context presented.
- If you don't know the answer, just say that you don't know, don't make up an answer.
- You must always cite the document where the answer was extracted using inline academic citation style [], using the position.
- Use markdown format for code examples.
- You are correct, factual, precise, and reliable.
Context:
{context}
"""
return prompt
def generate_openai_completion(user_prompt, question):
response = openai_client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": user_prompt},
{"role": "user", "content": question},
]
)
return response.choices[0].message.content
if __name__ == "__main__":
question = "my question"
elasticsearch_results = get_elasticsearch_results()
context_prompt = create_openai_prompt(elasticsearch_results)
openai_completion = generate_openai_completion(context_prompt, question)
print(openai_completion)To make it work with Ollama, you have to change the OpenAI client to connect to the Ollama server instead of the OpenAI server. You can find the full list of OpenAI examples and compatible endpoints here.
openai_client = OpenAI(
# you can use http://localhost:11434/v1/ if running this code locally.
base_url='https://your-ngrok-url.ngrok-free.app/v1/',
# required but ignored
api_key='ollama',
)And also change the model to llama3.2 when calling the completion method:
def generate_openai_completion(user_prompt, question):
response = openai_client.chat.completions.create(
model="llama3.2",
messages=[
{"role": "system", "content": user_prompt},
{"role": "user", "content": question},
]
)
return response.choices[0].message.contentLet’s add our question: Can I buy Clonazepam without a prescription? To the Elasticsearch query:
def get_elasticsearch_results():
es_query = {
"retriever": {
"standard": {
"query": {
"nested": {
"path": "semantic_field.inference.chunks",
"query": {
"sparse_vector": {
"inference_id": "medicines-inference",
"field": "semantic_field.inference.chunks.embeddings",
"query": "Can I buy Clonazepam without a prescription?"
}
},
"inner_hits": {
"size": 2,
"name": "medicines.semantic_field",
"_source": [
"semantic_field.inference.chunks.text"
]
}
}
}
}
},
"size": 3
}
result = es_client.search(index="medicines", body=es_query)
return result["hits"]["hits"]And also to the completion call with a couple of prints, so we can confirm we are sending the Elasticsearch results as part of the question context:
if __name__ == "__main__":
question = "Can I buy Clonazepam without a prescription?"
elasticsearch_results = get_elasticsearch_results()
context_prompt = create_openai_prompt(elasticsearch_results)
print("========== Context Prompt START ==========")
print(context_prompt)
print("========== Context Prompt END ==========")
print("========== Ollama Completion START ==========")
openai_completion = generate_openai_completion(context_prompt, question)
print(openai_completion)
print("========== Ollama Completion END ==========")Now let’s run the command
pip install -qU elasticsearch openai
python main.py
You should see something like this:
========== Context Prompt START ==========
Instructions:
- You are an assistant specializing in answering questions about the sale of medicines.
- Answer questions truthfully and factually using only the context presented.
- If you don't know the answer, just say that you don't know, don't make up an answer.
- You must always cite the document where the answer was extracted using inline academic citation style [], using the position.
- Use markdown format for code examples.
- You are correct, factual, precise, and reliable.
Context:
Clonazepam
---
An antiepileptic medication that requires a prescription.A nonsteroidal anti-inflammatory drug (NSAID) available WITHOUT a prescription.
---
IbuprofenAn anxiolytic medication that strictly requires a prescription.
---
Lorazepam
========== Context Prompt END ==========
========== Ollama Completion START ==========
No, you cannot buy Clonazepam over-the-counter (OTC) without a prescription [1]. It is classified as a controlled substance in the United States due to its potential for dependence and abuse. Therefore, it can only be obtained from a licensed healthcare provider who will issue a prescription for this medication.
========== Ollama Completion END ==========Conclusion
In this article, we can see the power and versatility of tools like Ollama when we use them together with the Elasticsearch inference API and Playground.
After some simple steps, we had a working RAG application with a chat that used a LLM running in our own infrastructure at zero cost. This also allows us to have more control over resources and sensitive information, besides giving us access to a variety of models for different tasks.
Ready to try this out on your own? Start a free trial.
Elasticsearch has integrations for tools from LangChain, Cohere and more. Join our Beyond RAG Basics webinar to build your next GenAI app!
Related content
June 2, 2025
AI-powered case deflection: build & deploy in minutes
Exploring the AI Assistant Knowledge Base capabilities combined with Playground to create a self-service case deflection platform.
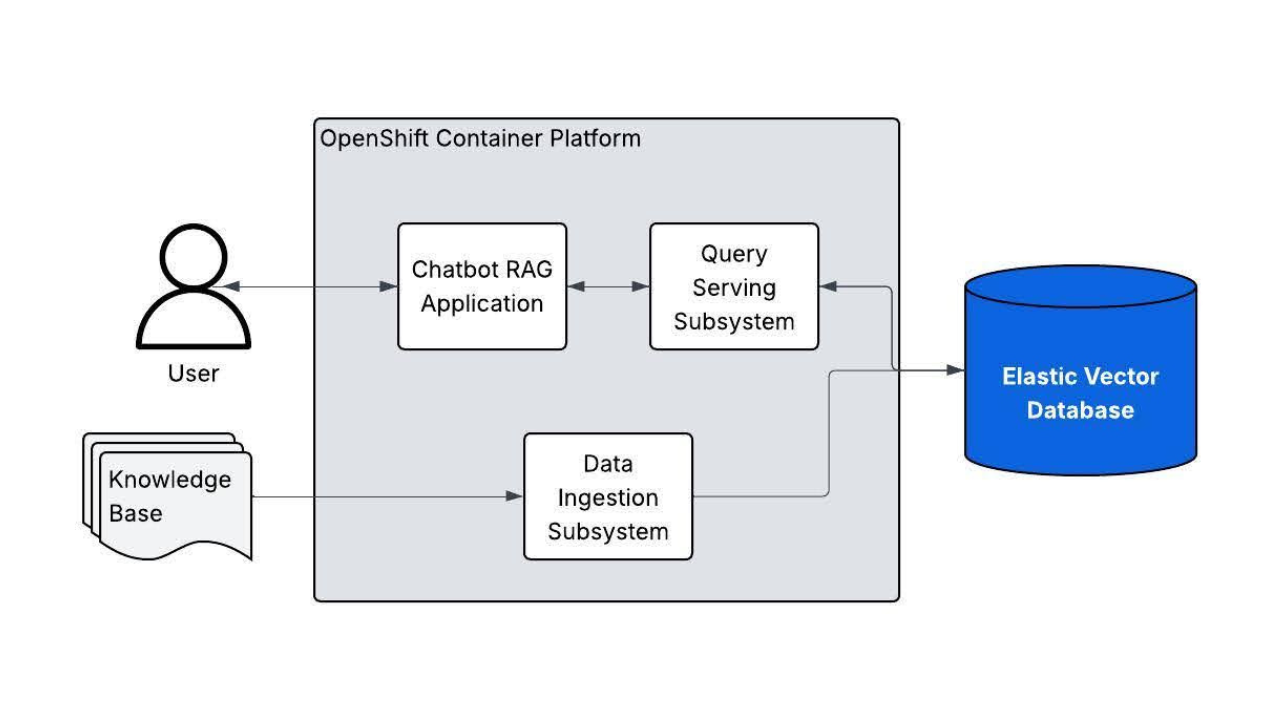
May 21, 2025
Get set, build: Red Hat OpenShift AI applications powered by Elasticsearch vector database
The Elasticsearch vector database is now supported by the ‘AI Generation with LLM and RAG’ Validated Pattern. This blog walks you through how to get started.

May 19, 2025
Elasticsearch in JavaScript the proper way, part II
Reviewing production best practices and explaining how to run the Elasticsearch Node.js client in Serverless environments.

May 15, 2025
Elasticsearch in JavaScript the proper way, part I
Explaining how to create a production-ready Elasticsearch backend in JavaScript.

May 26, 2025
Displaying fields in an Elasticsearch index
Exploring techniques for displaying fields in an Elasticsearch index.