In this article, we'll cover the CLIP multimodal model, explore alternatives, and analyze their pros and cons through a practical example of a mock real estate website that allows users to search for properties using pictures as references.
What is OpenAI's CLIP?
CLIP (Contrastive Language–Image Pre-training) is a neural network created by OpenAI, trained with pairs of images and texts to solve tasks of finding similarities between text and images and categorize "zero-shot" images so the model was not trained with fixed tags but instead, we provide unknown classes for the model so it can classify the image we provide to it.
CLIP has been the state-of-the-art model for a while and you can read more articles about it here:
However, over time more alternatives have come up.
In this article, we'll go through the pros and cons of two alternatives to CLIP using a real estate example. Here’s a summary of the steps we’ll follow in this article:
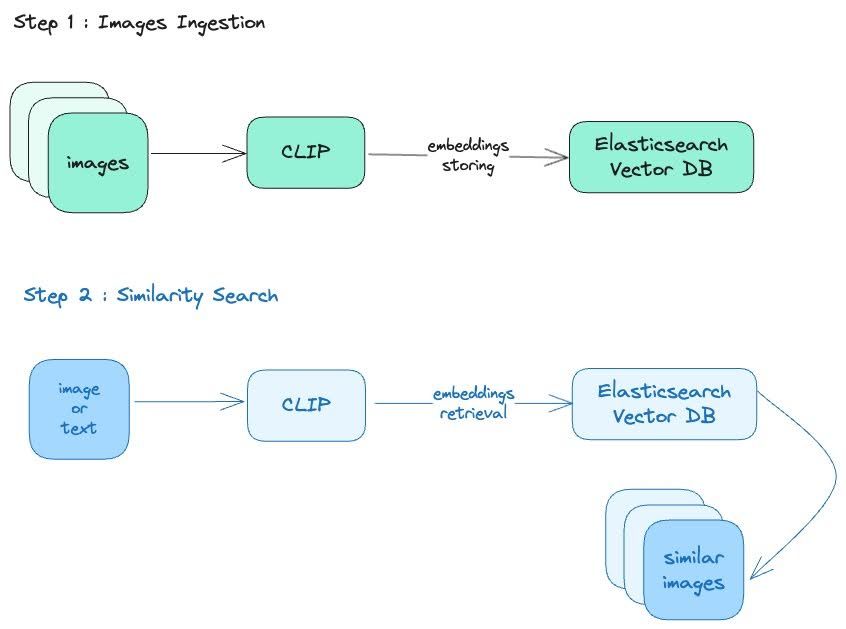
Basic configuration: CLIP and Elasticsearch
For our example, we will create a small project with an interactive UI using Python. We will install some dependencies, like the Python transformers, which will grant us access to some of the models we'll use.
Create a folder /clip_comparison and follow the installation instructions located here. Once you're done, install the Elasticsearch's Python client, the Cohere SDK and Streamlit:
NOTE: As an option, I recommend using a Python virtual environment (venv). This is useful if you don't want to install all of the dependencies on your machine.
pip install elasticsearch==8.15.0 cohere streamlitStreamlit is an open-source Python framework that allows you to easily get a UI with little code.
We'll also create some files to save the instructions we'll use later:
app.py: UI logic./services/elasticsearch.py: Elasticsearch client initialization, queries, and bulk API call to index documents./services/models.py: Model instances and methods to generate embeddings.index_data.py: Script to index images from a local source./data: our dataset directory.
Our App structure should look something like this:
/clip_comparison
|--app.py
|--index_data.py
|--/data
|--/venv # If you decide to use venv
|--/services
|-- __init__.py
|-- models.py
|-- elasticsearch.pyConfiguring Elasticsearch
Follow the next steps to store the images for the example. We'll then search for them using knn vector queries.
Note: We could also store text documents but for this example, we will only search in the images.
Index Mappings
Access Kibana Dev Tools (from Kibana: Management > Dev Tools) to build the data structure using these mappings:
[ ]
PUT clip-images
{
"mappings": {
"properties": {
"image_name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"image_embedding": {
"type": "dense_vector",
"dims": 768,
"index": "true",
"similarity": "cosine"
},
"image_data": {
"type": "binary"
}
}
}
}
PUT embed-images
{
"mappings": {
"properties": {
"image_name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"image_embedding": {
"type": "dense_vector",
"dims": 1024,
"index": "true",
"similarity": "cosine"
},
"image_data": {
"type": "binary"
}
}
}
}
PUT jina-images
{
"mappings": {
"properties": {
"image_name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"image_embedding": {
"type": "dense_vector",
"dims": 768,
"index": "true",
"similarity": "cosine"
},
"image_data": {
"type": "binary"
}
}
}
}The field type dense_vector will store the embeddings generated by the models. The field binary will store the images as base64.
Note: It's not a good practice to store images in Elasticsearch as binary. We're only doing it for the practical purpose of this example. The recommendation is to use a static files repository.
Now to the code. The first thing we need to do is initialize the Elasticsearch client using the cloud id and api-key. Write the following code at the beginning of the file /services/elasticsearch.py:
[ ]
from elasticsearch import Elasticsearch, exceptions, helpers
ELASTIC_ENDPOINT = "https://your-elastic-endpoint.com:9243"
ELASTIC_API_KEY = "your-elasticsearch-api-key"
# Elasticsearch client
es_client = Elasticsearch(
ELASTIC_ENDPOINT,
api_key=ELASTIC_API_KEY,
)
# index documents using bulk api
def index_images(index_name: str, images_obj_arr: list):
actions = [
{
"_index": index_name,
"_source": {
"image_data": obj["image_data"],
"image_name": obj["image_name"],
"image_embedding": obj["image_embedding"],
},
}
for obj in images_obj_arr
]
try:
response = helpers.bulk(es_client, actions)
return response
except exceptions.ConnectionError as e:
return e
# knn search
def knn_search(index_name: str, query_vector: list, k: int):
query = {
"size": 4,
"_source": ["image_name", "image_data"],
"query": {
"knn": {
"field": "image_embedding",
"query_vector": query_vector,
"k": k,
"num_candidates": 100,
"boost": 10,
}
},
}
try:
response = es_client.search(index=index_name, body=query)
return response
except exceptions.ConnectionError as e:
return e
# match all query
def get_all_query(index_name: str):
query = {
"size": 400,
"source": ["image_name", "image_data"],
"query": {"match_all": {}},
}
try:
return es_client.search(index=index_name, body=query)
except exceptions.ConnectionError as e:
return eConfiguring models
To configure the models, put the model instances and their methods in this file: /services/models.py.
The Cohere Embed-3 model works as a web service so we need an API key to use it. You can get a free one here. The trial is limited to 5 calls per minute, and 1,000 calls per month.
To configure the model and make the images searchable in Elasticsearch, follow these steps:
- Convert images to vectors using CLIP
- Store the image vectors in Elasticsearch
- Vectorize the image or text we want to compare to the stored images.
- Run a query to compare the entry of the previous step to the stored images and get the most similar ones.
[ ]
# /services/models.py
# dependencies
import base64
import io
import cohere
from PIL import Image
from transformers import CLIPModel, CLIPProcessor, AutoModel
COHERE_API_KEY = "your-cohere-api-key"
## CLIP model call
clip_model = CLIPModel.from_pretrained("openai/clip-vit-large-patch14")
clip_processor = CLIPProcessor.from_pretrained("openai/clip-vit-large-patch14")
# JinaCLip model call
jina_model = AutoModel.from_pretrained("jinaai/jina-clip-v1", trust_remote_code=True)
# Cohere client initialization
co = cohere.ClientV2(COHERE_API_KEY)Configuring CLIP
To configure CLIP, we need to add to the file models.py, the methods to generate the image and text embeddings.
# /services/models.py
# convert images to vector using CLIP
async def clip_image_embeddings(image: Image.Image):
try:
inputs = clip_processor(images=image, return_tensors="pt", padding=True)
outputs = clip_model.get_image_features(**inputs)
return outputs.detach().cpu().numpy().flatten().tolist()
except Exception as e:
print(f"Error generating embeddings: {e}")
return None
# convert text to to vector
async def clip_text_embeddings(description: str):
try:
inputs = clip_processor([description], padding=True, return_tensors="pt")
outputs = clip_model.get_text_features(**inputs)
return outputs.detach().cpu().numpy().flatten().tolist()
except Exception as e:
print(f"Error generating embeddings: {e}")
return NoneFor all the models, you need to declare similar methods: one to generate embeddings from an image (clip_image_embeddings) and another one to generate embeddings from text (clip_text_embeddings).
The outputs.detach().cpu().numpy().flatten().tolist() chain is a common operation to convert pytorch tensors into a more usable format:
.detach(): Removes the tensor from the computation graph as we no longer need to compute gradients.
.cpu(): Moves tensors from GPU to CPU as numpy only supports CPU.
.numpy(): Converts tensor to numPy array.
.flatten(): Converts into a 1D array.
.toList(): Converts into Python List.
This operation will convert a multidimensional tensor into a plain list of numbers that can be used for embeddings operations.
Let's now take a look at some CLIP alternatives.
OpenAI CLIP alternative 1: JinaCLIP
JinaCLIP is a CLIP variant developed by Jina AI, designed specifically to improve the search of images and text in multimodal applications. It optimizes CLIP performance by adding more flexibility in the representation of images and text.
Compared to the original OpenAI CLIP model, JinaCLIP performs better in text-to-text, text-to-image, image-to-text, and image-to-image tasks as we can see in the chart below:
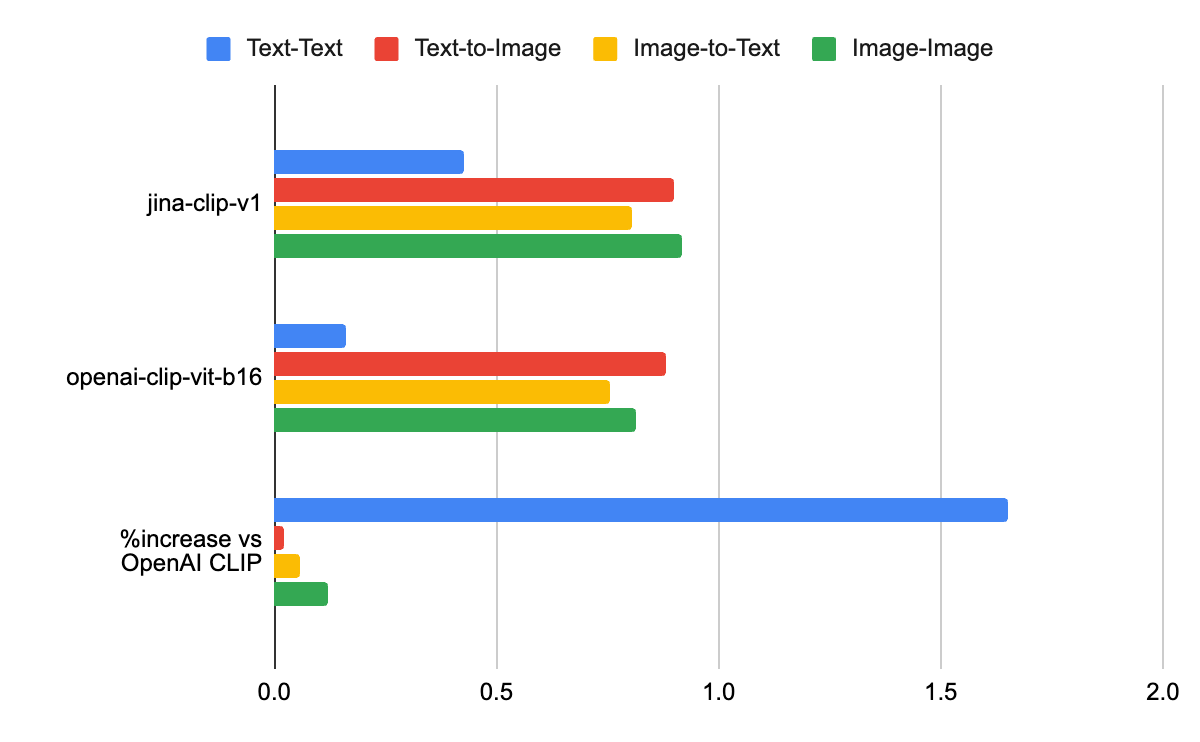
| Model | Text-Text | Text-to-Image | Image-to-Text | Image-Image |
|---|---|---|---|---|
| jina-clip-v1 | 0.429 | 0.899 | 0.803 | 0.916 |
| openai-clip-vit-b16 | 0.162 | 0.881 | 0.756 | 0.816 |
| %increase vs OpenAI CLIP | 165% | 2% | 6% | 12% |
The capacity to improve precision in different types of queries makes it a great tool for tasks that require a more precise and detailed analysis.
You can read more about JinaCLIP here.
To use JinaCLIP in our app and generate embeddings, we need to declare these methods:
[ ]
# /services/models.py
# convert images to vector using JinaClip model
async def jina_image_embeddings(image: Image.Image):
try:
image_embeddings = jina_model.encode_image([image])
return image_embeddings[0].tolist()
except Exception as e:
print(f"Error generating embeddings: {e}")
return None
# convert text to vector
async def jina_text_embeddings(description: str):
try:
text_embeddings = jina_model.encode_text(description)
return text_embeddings.tolist()
except Exception as e:
print(f"Error generating embeddings: {e}")
return NoneOpenAI CLIP alternative 2: Cohere Image Embeddings V3
Cohere has developed an image embedding model called Embed-3, which is a popular alternative to CLIP. The main difference is that Cohere focused on the representation of enterprise data like charts, product images, and design files. Embed-3 uses an advanced architecture that reduces the bias risk towards text data, which is currently a disadvantage in other multimodal models like CLIP, so it can provide more precise results between text and image.
You can see below a chart by Cohere showing the improved results using Embed 3 versus CLIP in this kind of data:
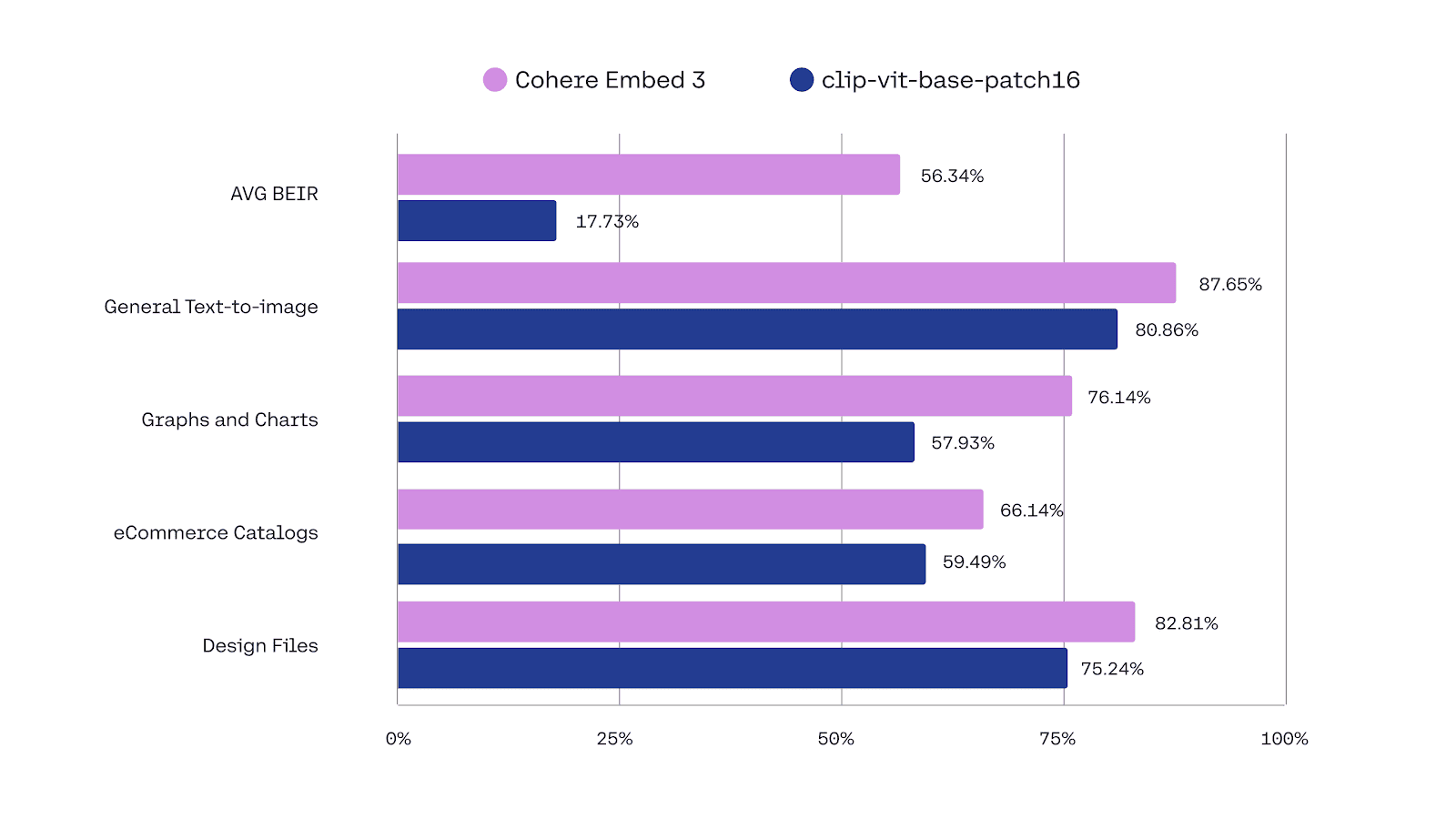
For more info, go to Embed3.
Just like we did with the previous models, let's declare the methods to use Embed 3:
[ ]
# /services/models.py
# convert images to vector using Cohere Embed model
async def embed_image_embeddings(image: Image.Image):
try:
img_byte_arr = io.BytesIO()
image.save(img_byte_arr, format="JPEG")
img_byte_arr = img_byte_arr.getvalue()
stringified_buffer = base64.b64encode(img_byte_arr).decode("utf-8")
content_type = "image/jpeg"
image_base64 = f"data:{content_type};base64,{stringified_buffer}"
response = co.embed(
model="embed-english-v3.0",
input_type="image",
embedding_types=["float"],
images=[image_base64],
)
return response.embeddings.float_[0]
except Exception as e:
print(f"Error generating embeddings: {e}")
return None
# convert text to vector
async def embed_text_embeddings(description: str):
try:
response = co.embed(
texts=[description],
model="embed-english-v3.0",
input_type="classification",
embedding_types=["float"],
)
return response.embeddings.float_[0]
except Exception as e:
print(f"Error generating embeddings: {e}")
return NoneWith the functions ready, let's index the dataset in Elasticsearch by adding the following code to the file index_data.py:
[ ]
# dependencies
import asyncio
import base64
import os
from PIL import Image
from services.elasticsearch import index_images
from services.models import (
clip_image_embeddings,
embed_image_embeddings,
jina_image_embeddings,
)
# function to encode images
def encode_image_to_base64(image_path):
with open(image_path, "rb") as img_file:
return base64.b64encode(img_file.read()).decode("utf-8")
async def main():
# folder with images
folder_path = "./data"
jina_obj_arr = []
embed_obj_arr = []
clip_obj_arr = []
for filename in os.listdir(folder_path):
img_path = os.path.join(folder_path, filename)
print(f"Processing {filename}...")
try:
image_data = Image.open(img_path)
# generating images embeddings
clip_result, embed_result, jina_result = await asyncio.gather(
clip_image_embeddings(image_data),
embed_image_embeddings(image_data),
jina_image_embeddings(image_data),
)
image_base64 = encode_image_to_base64(img_path)
# building documents
jina_obj_arr.append(
{
"image_name": filename,
"image_embedding": jina_result,
"image_data": image_base64,
}
)
embed_obj_arr.append(
{
"image_name": filename,
"image_embedding": embed_result,
"image_data": image_base64,
}
)
clip_obj_arr.append(
{
"image_name": filename,
"image_embedding": clip_result,
"image_data": image_base64,
}
)
except Exception as e:
print(f"Error with {filename}: {e}")
print("Indexing images in Elasticsearch...")
# indexing images
jina_count, _ = index_images(jina_index, jina_obj_arr)
cohere_count, _ = index_images(embed_index, cohere_obj_arr)
openai_count, _ = index_images(clip_index, openai_obj_arr)
print("Cohere count: ", cohere_count)
print("Jina count: ", jina_count)
print("OpenAI count: ", openai_count)
if __name__ == "__main__":
asyncio.run(main())Index the documents using the command:
python index_data.pyThe response will show us the amount of elements indexed by index:
Cohere response: 215
Jina response: 215
OpenAI response: 215Once the dataset has been indexed, we can create the UI.
Test UI
Creating the UI
We are going to use Streamlit to build a UI and compare the three alternatives side-by-side.
To build the UI, we'll start by adding the imports and dependencies to the file app.py:
[ ]
# app.py
import asyncio
import base64
from io import BytesIO
import streamlit as st
from PIL import Image
from services.elasticsearch import get_all_query, knn_search
# declared functions imports
from services.models import (
clip_image_embeddings,
clip_text_embeddings,
embed_image_embeddings,
embed_text_embeddings,
jina_image_embeddings,
jina_text_embeddings,
)For this example, we'll use two views; one for the image search and another one to see the image dataset:
[ ]
# app.py
if "selected_view" not in st.session_state:
st.session_state.selected_view = "Index"
def change_view(view):
st.session_state.selected_view = view
st.sidebar.title("Menu")
if st.sidebar.button("Search image"):
change_view("Index")
if st.sidebar.button("All images"):
change_view("Images")Let's add the view code for Search Image:
[ ]
if st.session_state.selected_view == "Index":
# Index page
st.title("Image Search")
col1, col_or, col2 = st.columns([2, 1, 2])
uploaded_image = None
with col1:
uploaded_image = st.file_uploader("Upload image", type=["jpg", "jpeg", "png"])
with col_or:
st.markdown(
"<h3 style='text-align: center; margin-top: 50%;'>OR</h3>",
unsafe_allow_html=True,
)
input_text = None
with col2:
st.markdown(
"<div style='display: flex; margin-top: 3rem; align-items: center; height: 100%; justify-content: center;'>",
unsafe_allow_html=True,
)
input_text = st.text_input("Type text")
st.markdown("</div>", unsafe_allow_html=True)
st.write("")
st.write("")
search_button = st.markdown(
"""
<style>
.stButton>button {
width: 50%;
height: 50px;
font-size: 20px;
margin: 0 auto;
display: block;
}
</style>
""",
unsafe_allow_html=True,
)
submit_button = st.button("Search")
if uploaded_image:
st.image(uploaded_image, caption="Uploaded Image", use_container_width=True)
if submit_button:
if uploaded_image or input_text:
async def fetch_embeddings():
data = None
if uploaded_image:
image = Image.open(uploaded_image)
data = image
elif input_text:
data = input_text
# Getting image or text embeddings
if uploaded_image:
openai_result, cohere_result, jina_result = await asyncio.gather(
clip_image_embeddings(data),
embed_image_embeddings(data),
jina_image_embeddings(data),
)
elif input_text:
openai_result, cohere_result, jina_result = await asyncio.gather(
clip_text_embeddings(data),
embed_text_embeddings(data),
jina_text_embeddings(data),
)
return openai_result, cohere_result, jina_result
results = asyncio.run(fetch_embeddings())
openai_result, cohere_result, jina_result = results
if openai_result and cohere_result and jina_result:
# calling knn query
clip_search_results = knn_search("clip-images", openai_result, 5)
jina_search_results = knn_search("jina-images", jina_result, 5)
embed_search_results = knn_search("embed-images", cohere_result, 5)
clip_search_results = clip_search_results["hits"]["hits"]
jina_search_results = jina_search_results["hits"]["hits"]
embed_search_results = embed_search_results["hits"]["hits"]
st.subheader("Search Results")
col1, spacer1, col2, spacer2, col3 = st.columns([3, 0.2, 3, 0.2, 3])
def print_results(results):
for hit in results:
image_data = base64.b64decode(hit["_source"]["image_data"])
image = Image.open(BytesIO(image_data))
st.image(image, use_container_width=True)
st.write("score: ", hit["_score"])
# printing results
with col1:
st.write("CLIP")
print_results(clip_search_results)
with col2:
st.write("JinaCLIP")
print_results(jina_search_results)
with col3:
st.write("Cohere")
print_results(embed_search_results)
else:
st.warning("Please upload an image or type text to search.")And now, the code for the Images view:
[ ]
elif st.session_state.selected_view == "Images":
# images page
st.header("All images")
# getting all images
images = get_all_query("jina-images")
hits = images["hits"]["hits"]
columns = st.columns(5)
for idx, hit in enumerate(hits):
image_data = base64.b64decode(hit["_source"]["image_data"])
image = Image.open(BytesIO(image_data))
with columns[idx % 5]:
st.image(image, use_container_width=True)We'll run the app with the command:
streamlit run app.pyThanks to multimodality, we can run searches in our image database based on text (text-to-image similarity) or image (image-to-image similarity).
Searching with the UI
To compare the three models, we'll use a scenario in which a real estate webpage wants to improve its search experience by allowing users to search using image or text. We'll discuss the results provided by each model.
We'll upload the image of a "rustic home":
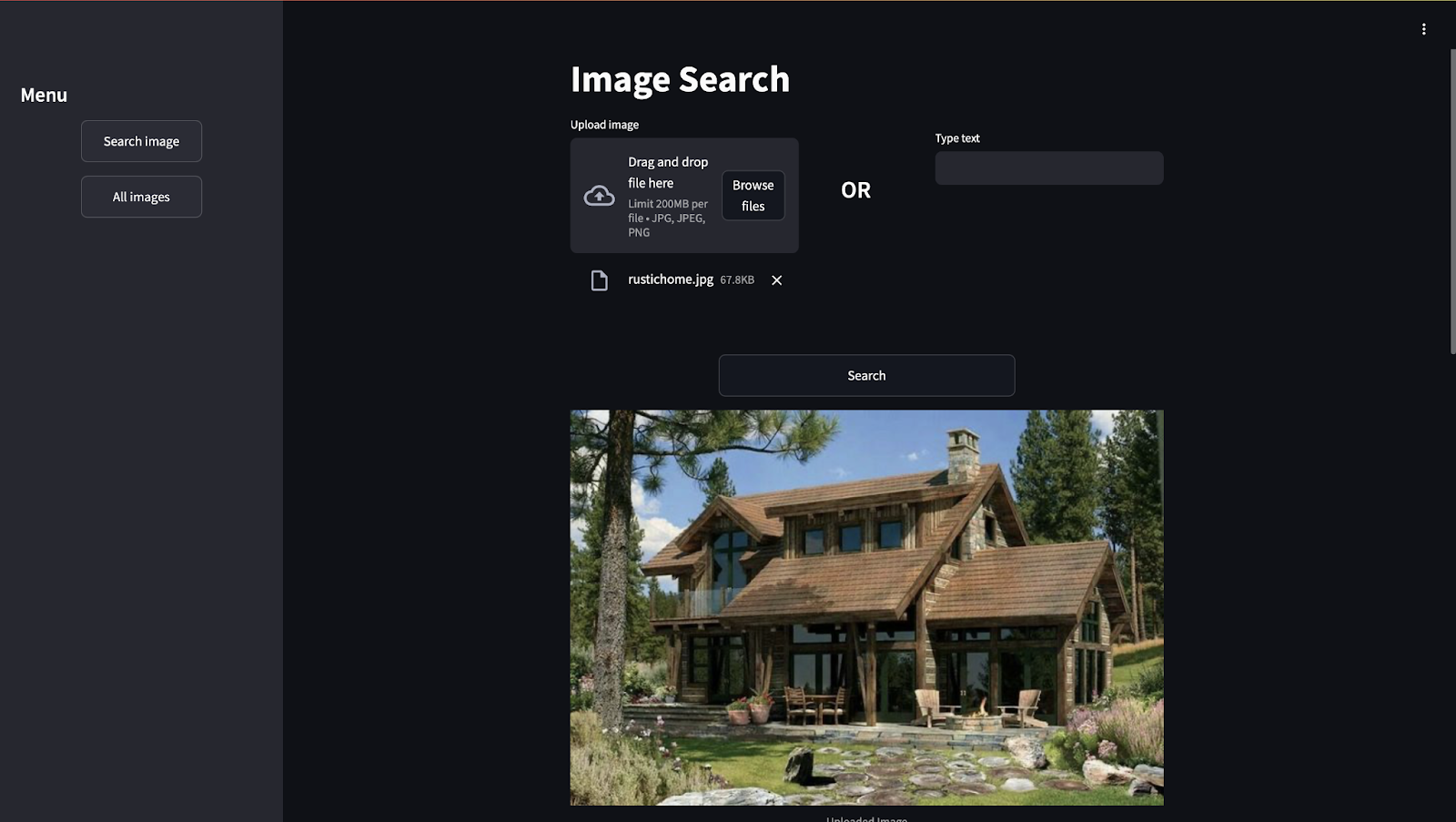
Here we have the search results. As you can see, based on the image we uploaded, each model generated different results:
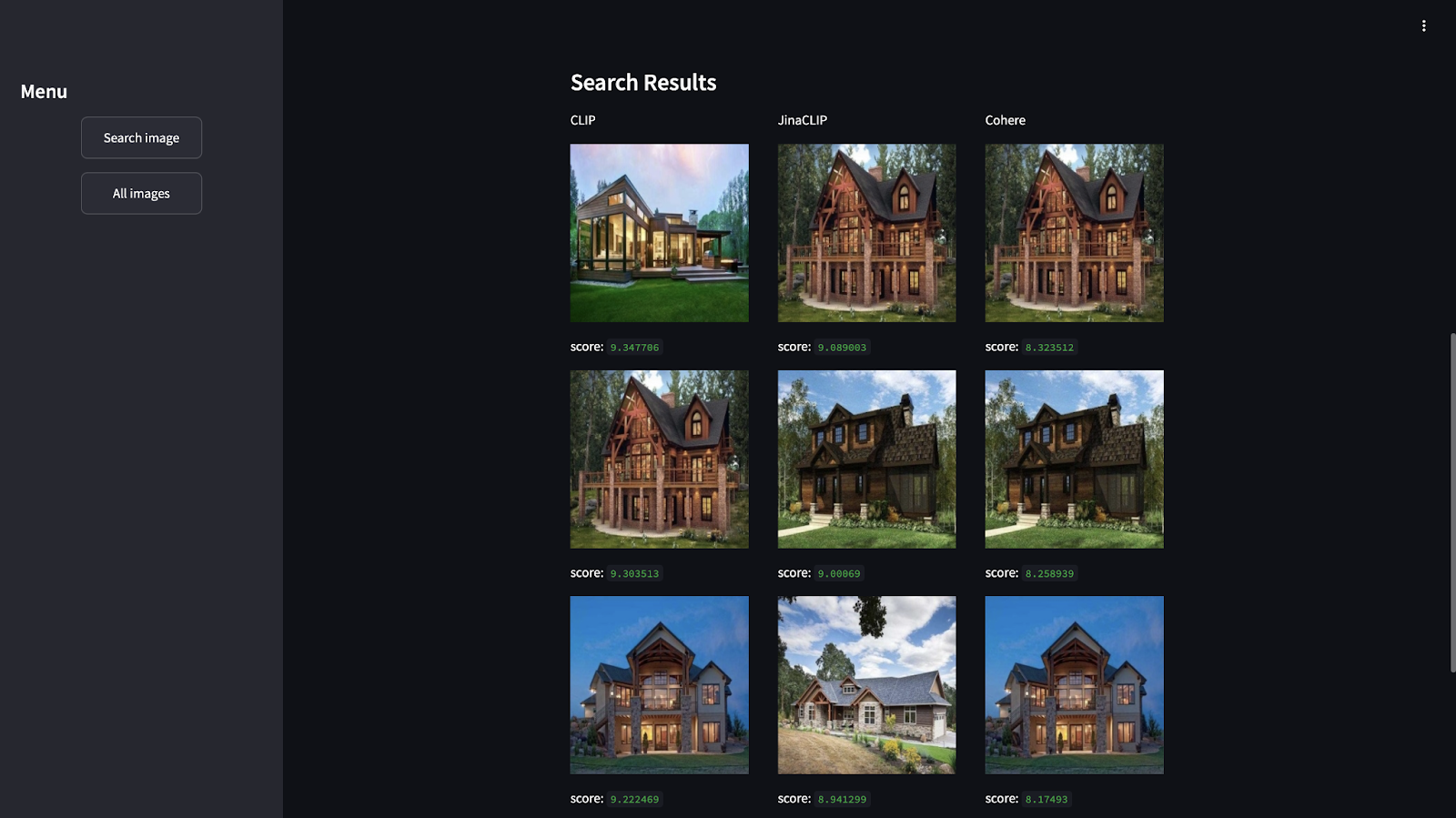
In addition, you can see results based on the text to find the house features:
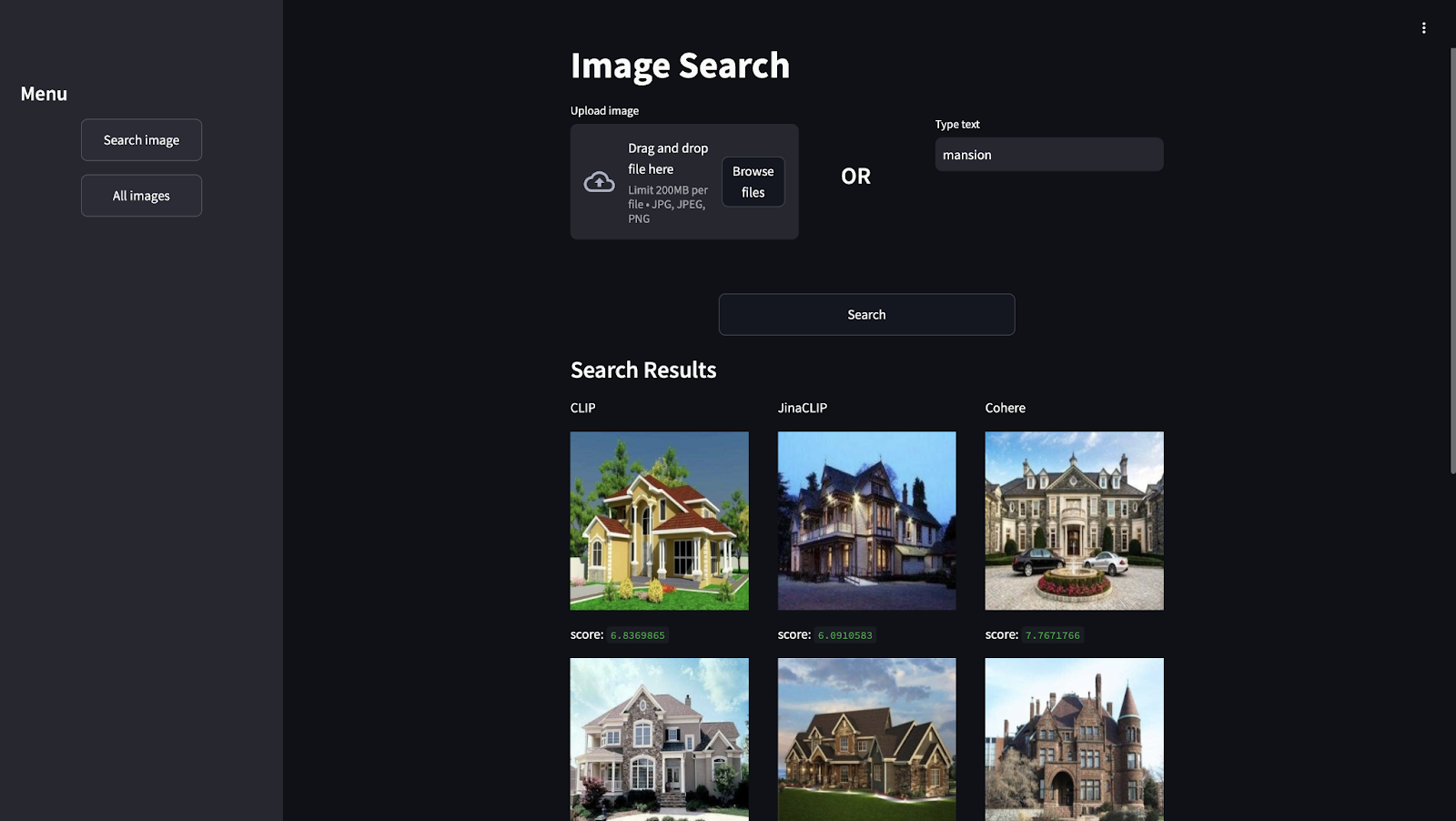
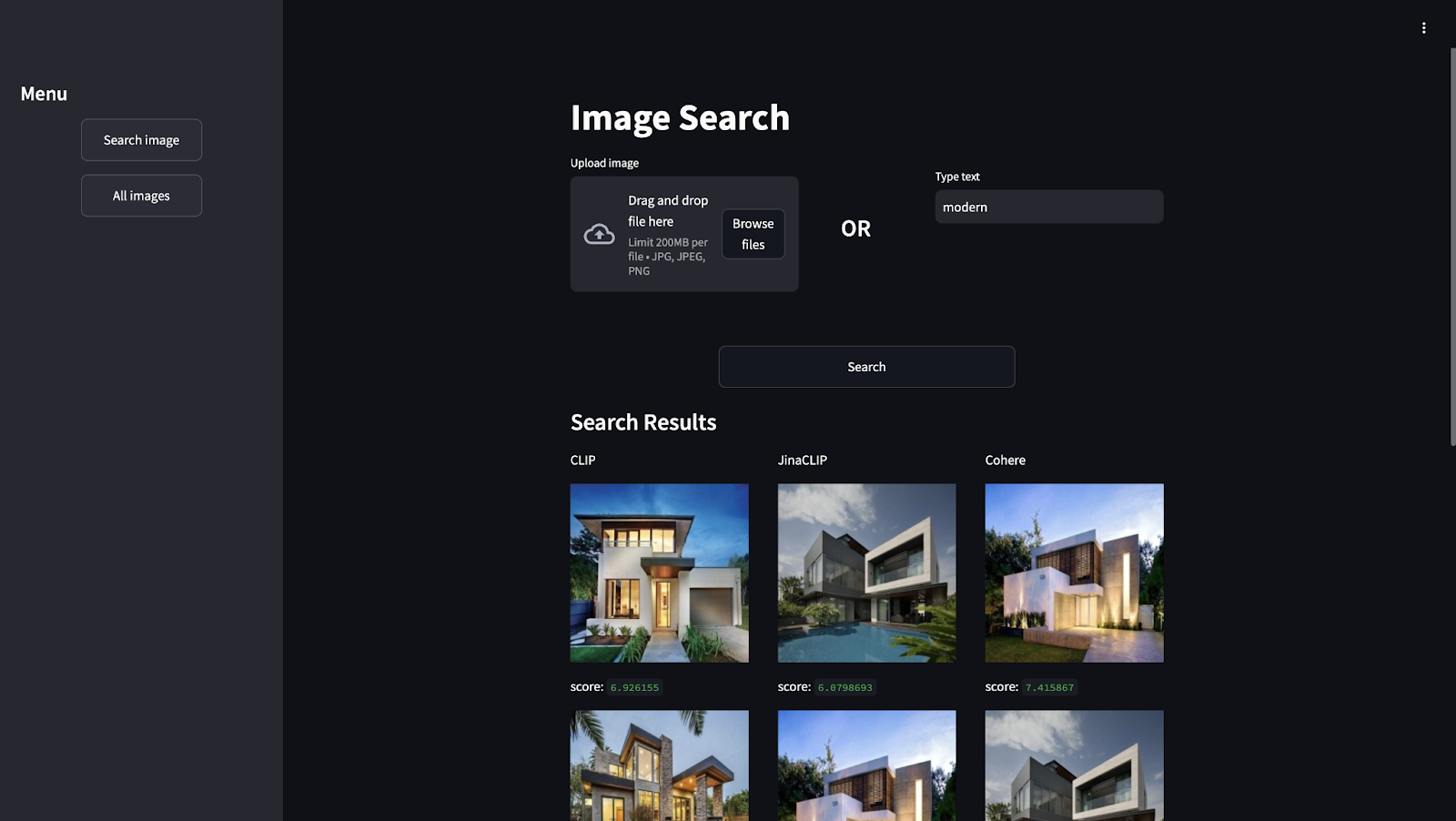
If searching for “modern”, the three models will show good results. But, JinaCLIP and Cohere will be showing the same houses in the first positions.
Features comparison of OpenAI CLIP alternatives
Below you have a summary of the main features and prices of the three options we covered in this article:
| Model | Created by | Estimated Price | Features |
|---|---|---|---|
| CLIP | OpenAI | $0.00058 per run in Replicate (https://replicate.com/krthr/clip-embeddings) | General multimodal model for text and image; suitable for a variety of applications with no specific training. |
| JinaCLIP | Jina AI | $0.018 per 1M tokens in Jina (https://jina.ai/embeddings/) | CLIP variant optimized for multimodal applications. Improved precision retrieving texts and images. |
| Embed-3 | Cohere | $0.10 per 1M tokens, $0.0001 per data and images at Cohere (https://cohere.com/pricing) | Focuses on enterprise data. Improved retrieval of complex visual data like graphs and charts. |
If you will search on long image descriptions, or want to do text-to-text as well as image-to-text, you should discard CLIP, because both JinaCLIP and Embed-3 are optimized for this use case.
Then, JinaCLIP is a general-use model, while Cohere’s one is more focused on enterprise data like products, or charts.
When testing the models on your data, make sure you cover:
- All modalities you are interested in: text-to-image, image-to-text, text-to-text
- Long and short image descriptions
- Similar concept matches (different images of the same type of object)
- Negatives
- Hard negative: Similar to the expected output but still wrong
- Easy negative: Not similar to the expected output and wrong
- Challenging scenarios:
- Different angles/perspectives
- Various lighting conditions
- Abstract concepts ("modern", "cozy", "luxurious")
- Domain-specific cases:
- Technical diagrams or charts (especially for Embed-3)
- Product variations (color, size, style)
Conclusion
Though CLIP is the preferred model when doing image similarity search, there are both commercial and non-commercial alternatives that can perform better in some scenarios.
JinaCLIP is a robust all-in-one tool that claims to be more precise than CLIP in text-to-text embeddings.
Embed-3 follows Cohere's line of catering to business clients by training models with real data using typical business docs.
In our small experiment, we could see that both JinaClip and Cohere show interesting image-to-image and text-to-image results and perform very similarly to CLIP with these kinds of tasks.
Elasticsearch allows you to search for embeddings, combining vector search with full-text-search, enabling you to search both for images and for the text in them.
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content

September 22, 2025
Elastic Open Web Crawler as a code
Learn how to use GitHub Actions to manage Elastic Open Crawler configurations, so every time we push changes to the repository, the changes are automatically applied to the deployed instance of the crawler.

August 6, 2025
How to display fields of an Elasticsearch index
Learn how to display fields of an Elasticsearch index using the _mapping and _search APIs, sub-fields, synthetic _source, and runtime fields.

July 14, 2025
Run Elastic Open Crawler in Windows with Docker
Learn how to use Docker to get Open Crawler working in a Windows environment.

June 24, 2025
Ruby scripting in Logstash
Learn about the Logstash Ruby filter plugin for advanced data transformation in your Logstash pipeline.

June 4, 2025
3 ingestion tips to change your search game forever
Get your Elasticsearch ingestion game to the next level by following these tips: data pre-processing, data enrichment and picking the right field types.