Models with over 1 million tokens are not something new; more than 1 year ago, Google announced Gemini 1.5 with 1 million tokens of context. One million tokens is approximately 2000 A5 pages which, in many cases, is more than all the data we have stored.
Then the question arises: “What if I just send everything in the prompt?”
In this article, we will compare RAG with just sending everything to a long context model and letting the LLM analyze the context and answer a question.
You can find a notebook with the full experiment here.
Initial thoughts
Before we begin, we can make some statements to put to the test:
- Convenience: Not many models have long context versions, so our alternatives are limited.
- Performance: The speed of processing 1M tokens by an LLM should be slower than retrieving from Elasticsearch + LLM processing smaller token contexts.
- Price: The price per question should be significantly higher.
- Precision: A RAG system can effectively help us filter out noise and keep the LLM’s attention on what matters.
Though sending everything as context is an advantage, it presents the challenge of making sure you are capturing every relevant document on your query. Elasticsearch allows you to mix and match different strategies to search the right documents: filters, full-text search, semantic search, and hybrid search.
Test definition
Model/RAG specs
- LLM Model: gemini-2.0-flash
- Model provider: Google
- Dataset: Elasticsearch search labs articles
For each of the test cases we are going to evaluate:
- LLM Price
- End-to-end latency
- Answer correctness
Test cases
Based on an Elasticsearch articles dataset, we are going to test the two strategies, RAG and LLM full context, on two different types of questions:
Textual. The question will be about a text that is literally written in the documents.
Non-textual. The question text will not be present in the document and will require the LLM to infer information or use different pieces.
Running tests
1. Index data
Download the dataset in NDJSON format to run the following steps:
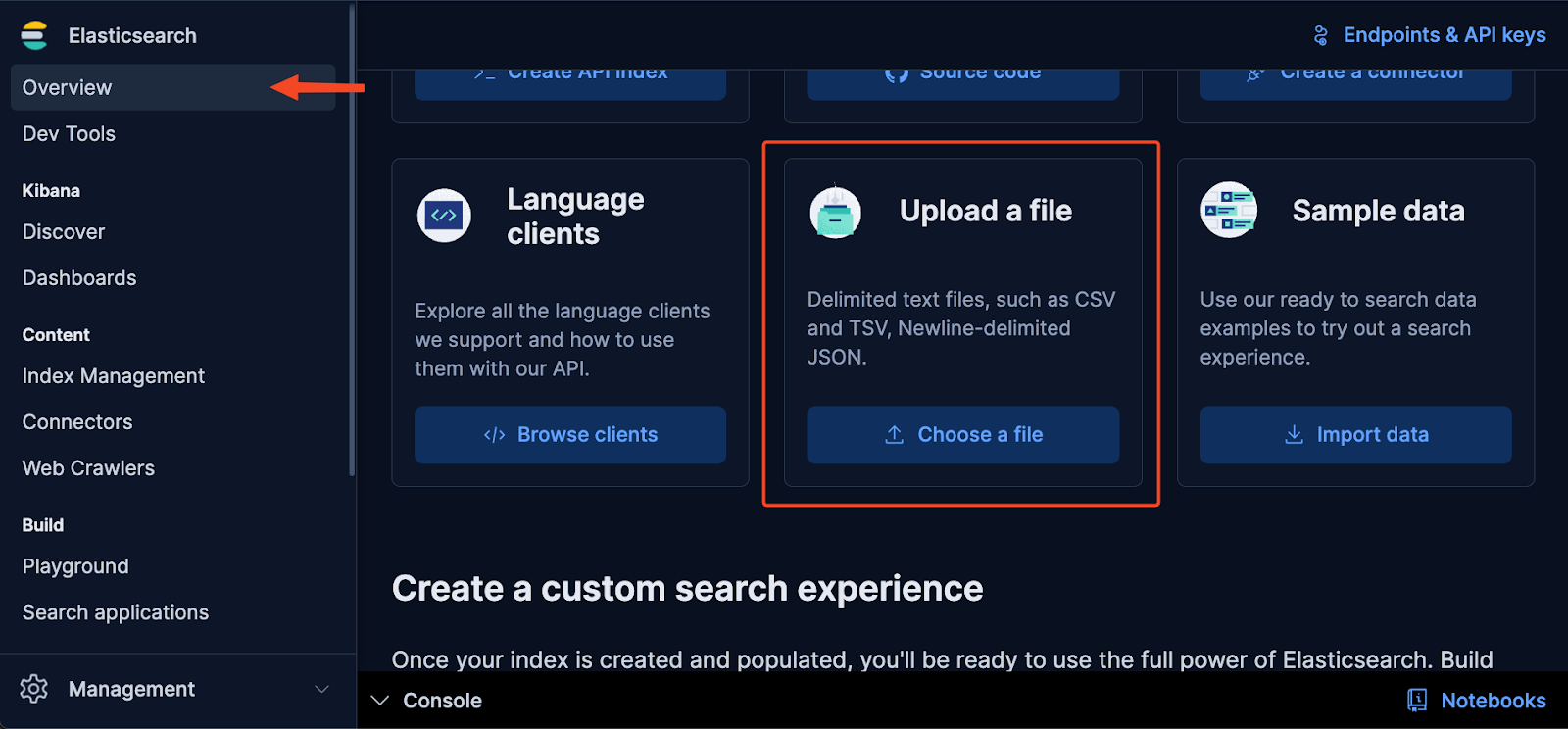
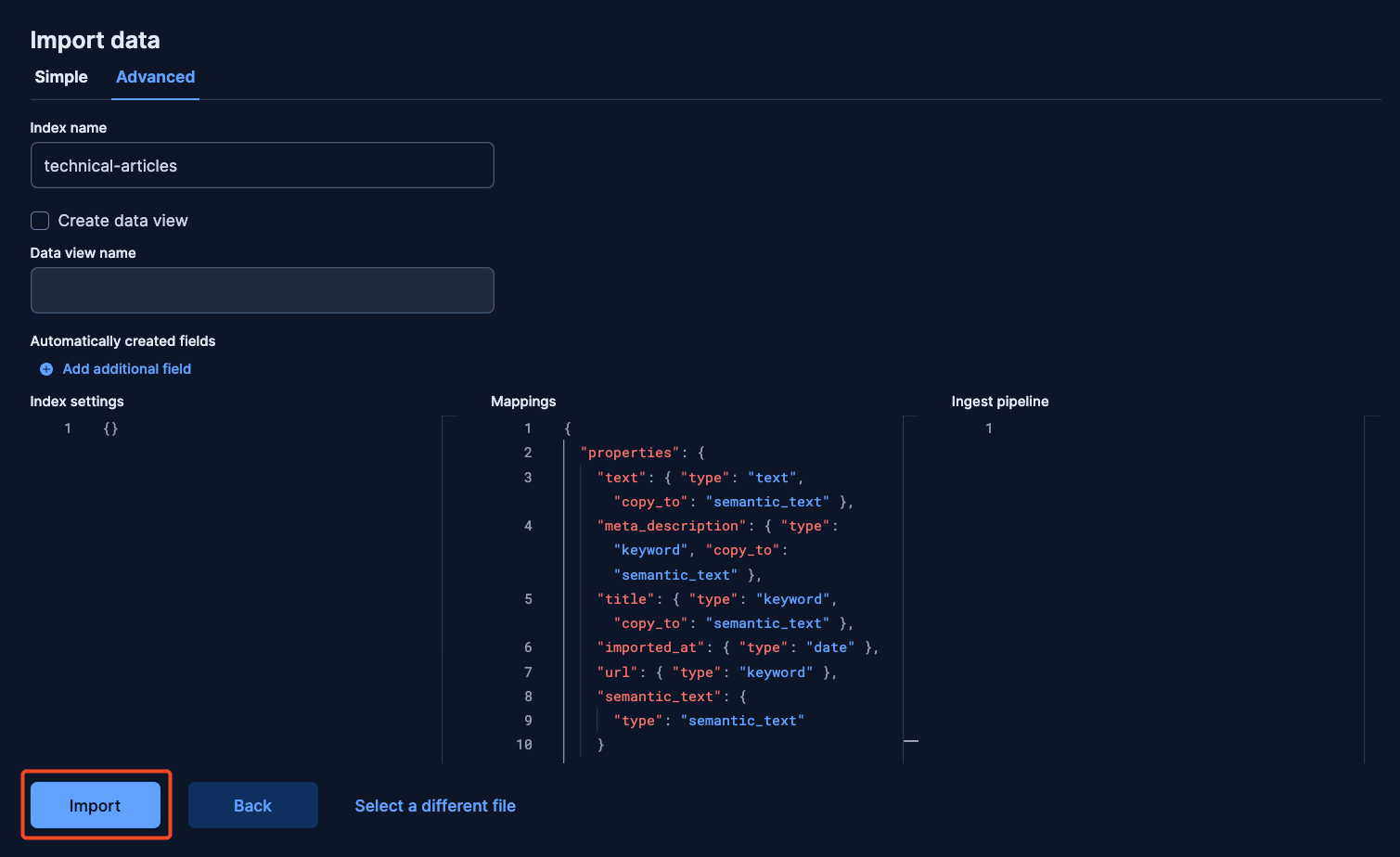
The following steps and screenshots were taken from a Cloud Hosted Deployment. In the deployment, go to “Overview” and scroll down to click “Upload a file.” Then click on “here” since we need to add customized mappings.
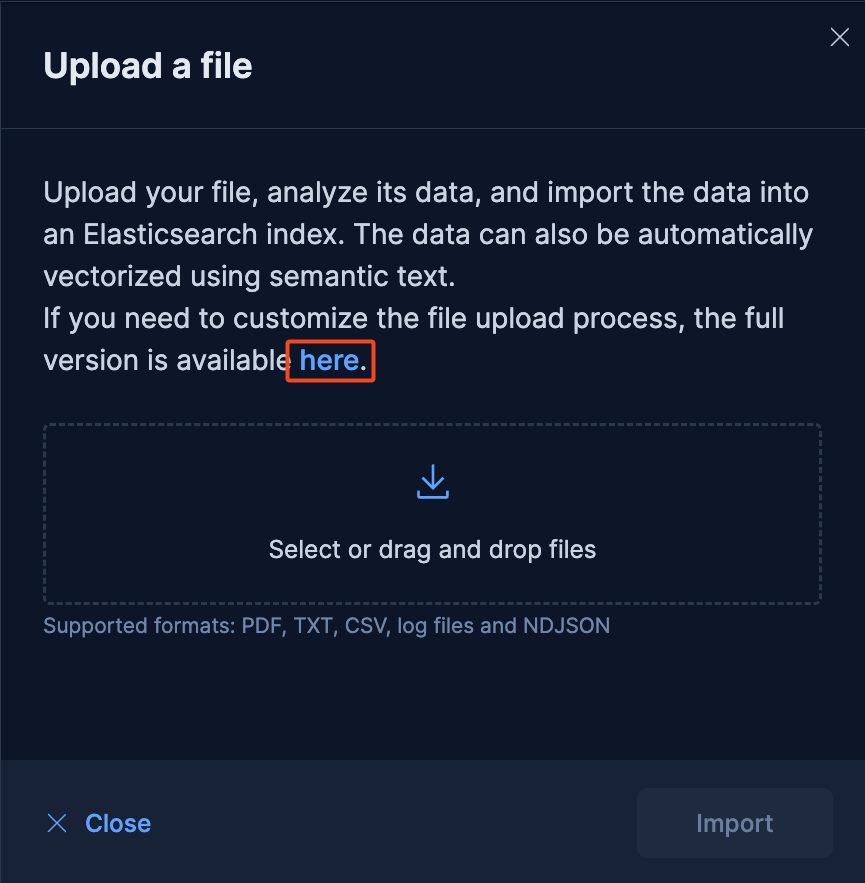
In the new view, drag the ndjson file with the dataset and click on import.
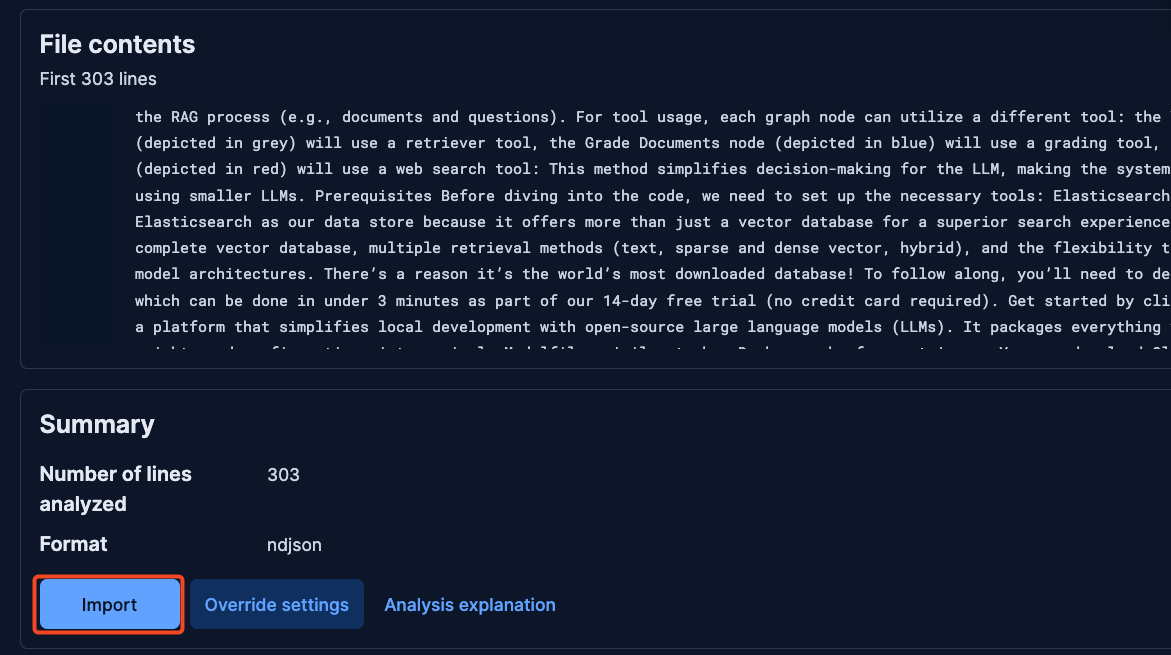
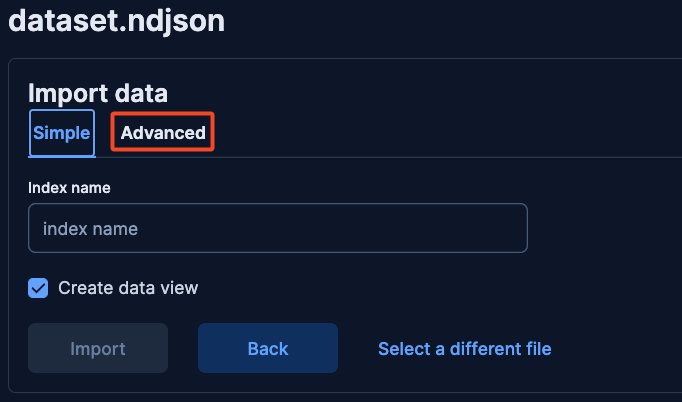
Then, click on advanced and enter the index’s name and add the following mappings:
{
"properties": {
"text": { "type": "text", "copy_to": "semantic_text" },
"meta_description": { "type": "keyword", "copy_to": "semantic_text" },
"title": { "type": "keyword", "copy_to": "semantic_text" },
"imported_at": { "type": "date" },
"url": { "type": "keyword" },
"semantic_text": {
"type": "semantic_text"
}
}
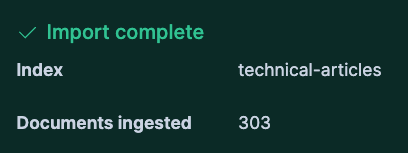
}Click import to finalize and wait for the data to be indexed.
2. Textual RAG
I’ve extracted a fragment of the article Elasticsearch in JavaScript the proper way, part II to use as the query string.
query_str = """
Let’s now create a test.js file and install our mock client: Now, add a mock for semantic search: We can now create a test for our code, making sure that the Elasticsearch part will always return the same results: Let’s run the tests.
"""Running match phrase query
This is the query we're going to use to retrieve the results from Elasticsearch using match phrase search capabilities. We will pass the query_str as input to the match phrase search.
textual_rag_summary = {} # Variable to store results
start_time = time.time()
es_query = {
"query": {"match_phrase": {"text": {"query": query_str}}},
"_source": ["title"],
"highlight": {
"pre_tags": [""],
"post_tags": [""],
"fields": {"title": {}, "text": {}},
},
"size": 10,
}
response = es_client.search(index=index_name, body=es_query)
hits = response["hits"]["hits"]
textual_rag_summary["time"] = (
time.time() - start_time
) # save time taken to run the query
textual_rag_summary["es_results"] = hits # save hits
print("ELASTICSEARCH RESULTS: \n", json.dumps(hits, indent=4))Returned hits:
ELASTICSEARCH RESULTS:
[
{
"_index": "technical-articles",
"_id": "tnWcO5cBTbKqUnB5yeVn",
"_score": 36.27694,
"_source": {
"title": "Elasticsearch in JavaScript the proper way, part II - Elasticsearch Labs"
},
"highlight": {
"text": [
"Let\u2019s now create a test.js file and install our mock client: Now, add a mock for semantic search: We can now create a test for our code, making sure that the Elasticsearch part will always return the same results: Let\u2019s run the tests"
]
}
}
]This prompt template gives the LLM the instructions to answer the question and the context to do so. At the end of the prompt, we're asking for the article that contains the information we are looking for.
The prompt template will be the same for all tests.
# LLM prompt template
template = """
Instructions:
- You are an assistant for question-answering tasks.
- Answer questions truthfully and factually using only the context presented.
- If you don't know the answer, just say that you don't know, don't make up an answer.
- Use markdown format for code examples.
- You are correct, factual, precise, and reliable.
- Answer
Context:
{context}
Question:
{question}.
What is the title article?
"""Run results through LLM
Elasticsearch results will be provided as context for the LLM so we can get the result we need. We are going to extract the article title and the highlights relevant to the user query. After that we send the question, article titles, and highlights to the LLM to find the answer.
start_time = time.time()
prompt = ChatPromptTemplate.from_template(template)
context = ""
for hit in hits:
# For semantic_text matches, we need to extract the text from the highlighted field
if "highlight" in hit:
highlighted_texts = []
for values in hit["highlight"].values():
highlighted_texts.extend(values)
context += f"{hit['_source']['title']}\n"
context += "\n --- \n".join(highlighted_texts)
# Use LangChain for the LLM part
chain = prompt | llm | StrOutputParser()
printable_prompt = prompt.format(context=context, question=query_str)
print("PROMPT WITH CONTEXT AND QUESTION:\n ", printable_prompt) # Print prompt
with get_openai_callback() as cb:
response = chain.invoke({"context": context, "question": query_str})
# Save results
textual_rag_summary["answer"] = response
textual_rag_summary["total_time"] = (time.time() - start_time) + textual_rag_summary[
"time"
] # Sum of time taken to run the semantic search and the LLM
textual_rag_summary["tokens_sent"] = cb.prompt_tokens
textual_rag_summary["cost"] = calculate_cost(
input_tokens=cb.prompt_tokens, output_tokens=cb.completion_tokens
)
print("LLM Response:\n ", response)LLM response:
What is the title article?
LLM Response:
Elasticsearch in JavaScript the proper way, part II - Elasticsearch LabsThe model finds the right article.
3. LLM Textual
Match All Query
To provide context to the LLM, we're going to get it from the indexed documents in Elasticsearch. We are going to send all the 303 articles we have indexed, which are about 1 million tokens long.
textual_llm_summary = {} # Variable to store results
start_time = time.time()
es_query = {"query": {"match_all": {}}, "sort": [{"title": "asc"}], "size": 1000}
es_results = es_client.search(index=index_name, body=es_query)
hits = es_results["hits"]["hits"]
# Save results
textual_llm_summary["es_results"] = hits
textual_llm_summary["time"] = time.time() - start_time
print("ELASTICSEARCH RESULTS: \n", json.dumps(hits, indent=4))ELASTICSEARCH RESULTS:
[
{
"_index": "technical-articles",
"_id": "J3WUI5cBTbKqUnB5J83I",
"_score": null,
"_source": {
"meta_description": ".NET articles from Elasticsearch Labs",
"imported_at": "2025-05-30T18:43:20.036600",
"text": "Tutorials Examples Integrations Blogs Start free trial .NET Categories All Articles Agent AutoOps ... API Reference Elastic.co Change theme Change theme Sitemap RSS 2025. Elasticsearch B.V. All Rights Reserved.",
"title": ".NET - Elasticsearch Labs",
"url": "https://www.elastic.co/search-labs/blog/category/dot-net-programming"
},
"sort": [
".NET - Elasticsearch Labs"
]
},
...
]Run results through LLM
As in the previous step, we're going to provide the context to the LLM and ask for the answer.
start_time = time.time()
prompt = ChatPromptTemplate.from_template(template)
# Use LangChain for the LLM part
chain = prompt | llm | StrOutputParser()
printable_prompt = prompt.format(context=context, question=query_str)
print("PROMPT:\n ", printable_prompt) # Print prompt
with get_openai_callback() as cb:
response = chain.invoke({"context": hits, "question": query_str})
# Save results
textual_llm_summary["answer"] = response
textual_llm_summary["total_time"] = (time.time() - start_time) + textual_llm_summary[
"time"
] # Sum of time taken to run the match_all query and the LLM
textual_llm_summary["tokens_sent"] = cb.prompt_tokens
textual_llm_summary["cost"] = calculate_cost(
input_tokens=cb.prompt_tokens, output_tokens=cb.completion_tokens
)
print("LLM Response:\n ", response) # Print LLM responseLLM response:
...
What is the title article?
LLM Response:
The title of the article is "Testing your Java code with mocks and real Elasticsearch".It failed! When multiple articles contain similar information, the LLM might struggle to pinpoint the exact text you’re searching for.
RAG non-textual
For the second test we're going to use a semantic query to retrieve the results from Elasticsearch. For that we built a short synopsis of Elasticsearch in JavaScript, the proper way, part II article as query_str and provided it as input to RAG.
query_str = "This article explains how to improve code reliability. It includes techniques for error handling, and running applications without managing servers."From now on, the code mostly follows the same pattern as the tests with the textual query, so we’ll refer to the code in the notebook for those sections.
Running semantic search
Notebook reference: 2. Run Comparisons > Test 2: Semantic Query > Executing semantic search.
Semantic search response hits:
ELASTICSEARCH RESULTS:
[
...
{
"_index": "technical-articles",
"_id": "KHV7MpcBTbKqUnB5TN-F",
"_score": 0.07619048,
"_source": {
"title": "Elasticsearch in JavaScript the proper way, part II - Elasticsearch Labs"
},
"highlight": {
"text": [
"We will review: Production best practices Error handling Testing Serverless environments Running the",
"how long you want to have access to it.",
"Conclusion In this article, we learned how to handle errors, which is crucial in production environments",
"DT By: Drew Tate Integrations How To May 21, 2025 Get set, build: Red Hat OpenShift AI applications powered",
"KB By: Kofi Bartlett Jump to Production best practices Error handling Testing Serverless environments"
]
}
},
...
]Run results through LLM
Notebook reference: 2. Run Comparisons > Test 2: Semantic Query > Run results through LLM
LLM response:
...
What is the title article?
LLM Response:
Elasticsearch in JavaScript the proper way, part II - Elasticsearch Labs4. LLM non-textual
Match-all query
Notebook reference: 2. Run Comparisons > Test 2: Semantic Query > Match all query
Match-all-query response:
ELASTICSEARCH RESULTS:
[
{
"_index": "technical-articles",
"_id": "J3WUI5cBTbKqUnB5J83I",
"_score": null,
"_source": {
"meta_description": ".NET articles from Elasticsearch Labs",
"imported_at": "2025-05-30T18:43:20.036600",
"text": "Tutorials Examples Integrations Blogs Start free trial .NET Categories All Articles ... to easily utilize Elasticsearch to build advanced search experiences including generative AI, embedding models, reranking capabilities and more. Let's connect Menu Tutorials Examples Integrations Blogs Search Additional Resources Elasticsearch API Reference Elastic.co Change theme Change theme Sitemap RSS 2025. Elasticsearch B.V. All Rights Reserved.",
"title": ".NET - Elasticsearch Labs",
"url": "https://www.elastic.co/search-labs/blog/category/dot-net-programming"
},
"sort": [
".NET - Elasticsearch Labs"
]
},
...
]Run results through LLM
Notebook reference: 2. Run Comparisons > Test 2: Semantic Query > Run results through LLM
LLM response:
...
What is the title article?
LLM Response:
"Elasticsearch in JavaScript the proper way, part II" and "A tutorial on building local agent using LangGraph, LLaMA3 and Elasticsearch vector store from scratch - Elasticsearch Labs" and "Advanced integration tests with real Elasticsearch - Elasticsearch Labs" and "Automatically updating your Elasticsearch index using Node.js and an Azure Function App - Elasticsearch Labs"As the LLM has more options to choose from that were not filtered on a search stage, it will pick every similar article.
Test results
Now we are going to visualize the results of the test.
Textual Query
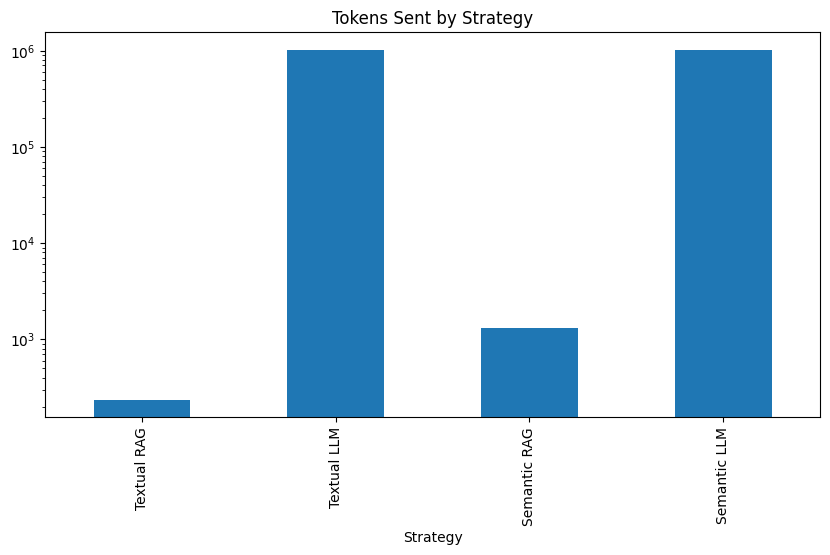
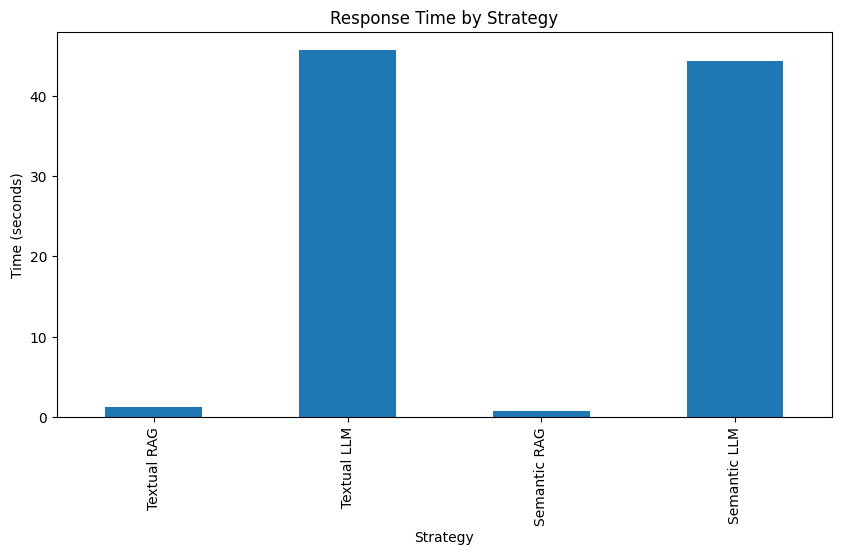
| Strategy | Answer | Tokens Sent | Time(s) | LLM Cost | |
|---|---|---|---|---|---|
| 0 | Textual RAG | Elasticsearch in JavaScript the proper way, part II - Elasticsearch Labs | 237 | 1.281432 | 0.000029 |
| 1 | Textual LLM | The title of the article is "Testing your Java code with mocks and real Elasticsearch" | 1,023,231 | 45.647408 | 0.102330 |
Semantic Query
| Strategy | Answer | Tokens Sent | Time(s) | LLM Cost | |
|---|---|---|---|---|---|
| 0 | Semantic RAG | Elasticsearch in JavaScript the proper way, part II - Elasticsearch Labs | 1,328 | 0.878199 | 0.000138 |
| 1 | Semantic LLM | "Elasticsearch in JavaScript the proper way, part II" and "A tutorial on building local agent using LangGraph, LLaMA3 and Elasticsearch vector store from scratch - Elasticsearch Labs" and "Advanced integration tests with real Elasticsearch - Elasticsearch Labs" and "Automatically updating your Elasticsearch index using Node.js and an Azure Function App - Elasticsearch Labs" | 1,023,196 | 44.386912 | 0.102348 |
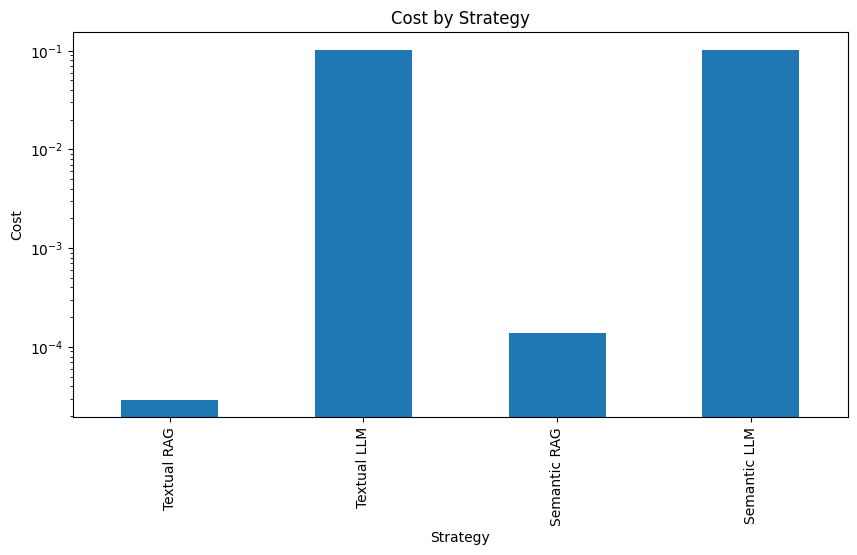
Conclusion
RAG is still highly relevant. Our tests show that using massive context models to send data without filtering in the context window is inferior to a RAG system in price, latency, and precision. It is common to see models losing attention when processing large amounts of context.
Even with the capabilities of large language models (LLMs), it's crucial to filter data before sending it to them since sending excessive tokens can lower the quality of responses. However, large context LLMs remain valuable when pre-filtering isn't feasible or when answers require drawing from extensive datasets.
Additionally, you still need to make sure you’re using the correct queries on your RAG systems to get a complete and correct answer. You can test different values in your queries to retrieve different amounts of documents until you find what works best for you.
- Convenience: The average tokens sent to the LLM using RAG was 783. Lower than all the mainstream models' maximum context window.
- Performance: RAG delivers significantly faster query speed. An average of 1 second, versus the 45 seconds of the pure LLM approach.
- Price: The average cost of a RAG query ($0,00008) was 1250 times lower than the pure LLM approach ($0,1)
- Precision: The RAG system produced accurate responses across all iterations, while the full-context approach led to inaccuracies.
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content
October 27, 2025
Building agentic applications with Elasticsearch and Microsoft’s Agent Framework
Learn how to use Microsoft Agent Framework with Elasticsearch to build an agentic application that extracts ecommerce data from Elasticsearch client libraries using ES|QL.
October 21, 2025
Introducing Elastic’s Agent Builder
Introducing Elastic Agent Builder, a framework to easily build reliable, context-driven AI agents in Elasticsearch with your data.

October 20, 2025
Elastic MCP server: Expose Agent Builder tools to any AI agent
Discover how to use the built-in Elastic MCP server in Agent Builder to securely extend any AI agent with access to your private data and custom tools.
How to use the Synonyms UI to upload and manage Elasticsearch synonyms
Learn how to use the Synonyms UI in Kibana to create synonym sets and assign them to indices.

October 13, 2025
AI Agent evaluation: How Elastic tests agentic frameworks
Learn how we evaluate and test changes to an agentic system before releasing them to Elastic users to ensure accurate and verifiable results.