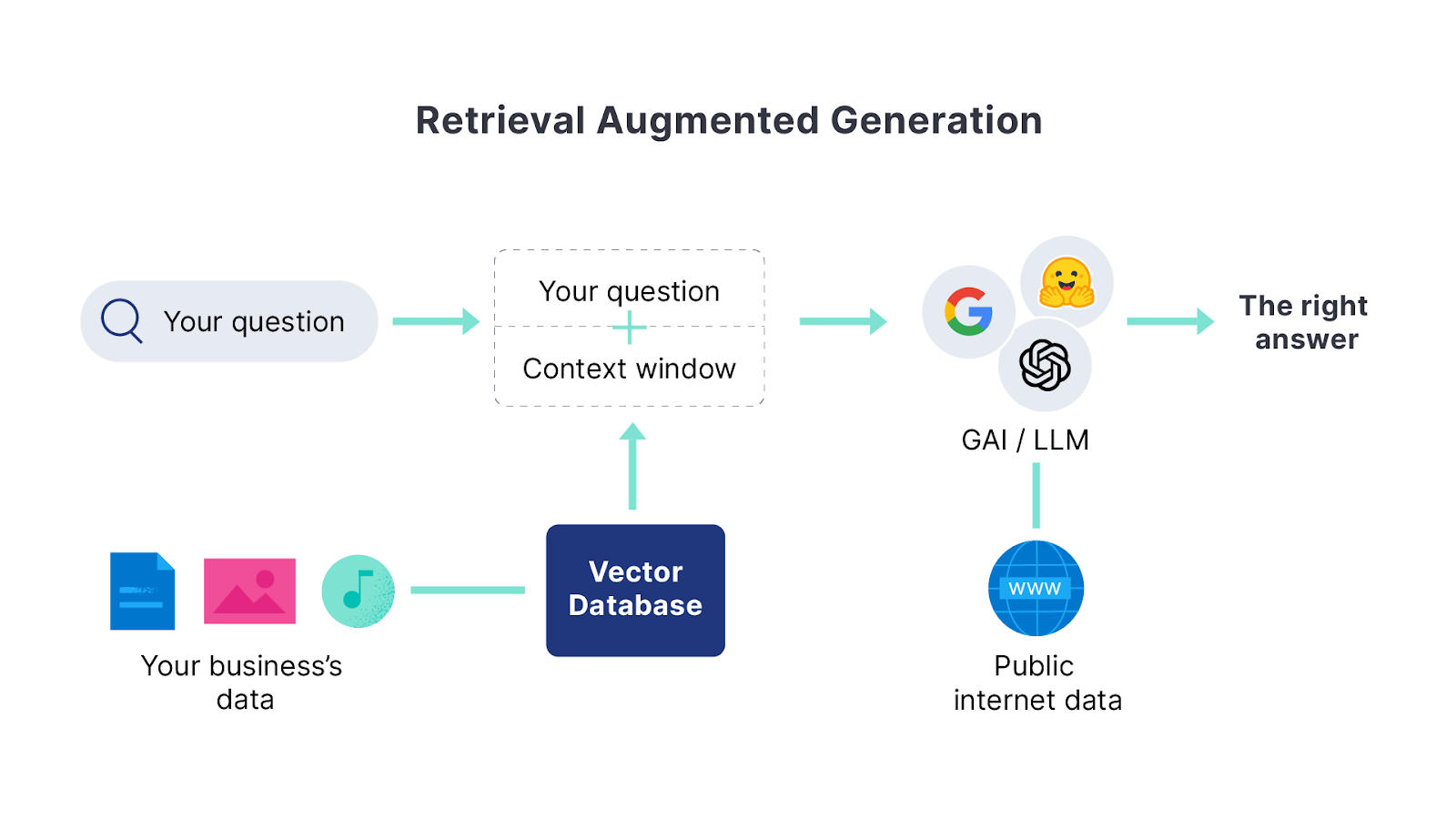
You’ve probably heard about RAG (Retrieval Augmented Generation), the go-to strategy to combine your own documents with an LLM to produce human-like answers to user questions. In this article, we’ll explore how far you can get by taking the LLM out of the equation and using just semantic search and ELSER.
If you’re new to RAG, you can read this article about RAG on Azure and AI, this one about RAG with Mistral, or this article about building a RAG application using Amazon Bedrock.
LLMs cons
While LLMs offer human-language answers instead of just returning documents, there are several considerations when implementing them, including:
- Cost: Using an LLM service has a cost per token or needs specialized hardware if you want to run the model locally.
- Latency: Adding an LLM step increases the response time.
- Privacy: In cloud models, you’ll be sending your information to a third party, with everything that entails.
- Management: Adding an LLM means that now you need to deal with a new stack component, different model providers and versions, prompt engineering, hallucinations, etc.
ELSER is all you need
If you think about it, a RAG system is as good as the search engine behind it. While it’s good to search for something and read a proper answer instead of getting a list of results, its value lies in:
- Being able to make queries using a question instead of keywords so you don’t need to have the exact same words in the documents since the system “gets” the meaning.
- Not needing to read the entire text to get the desired information since the LLM finds the answer in the context you send it and makes it visible.
Considering these, we can get very far using ELSER to retrieve relevant information via semantic search and structuring our documents so that we generate a user experience in which the user types a question and the interface leads them directly to an answer, without reading the entire document.
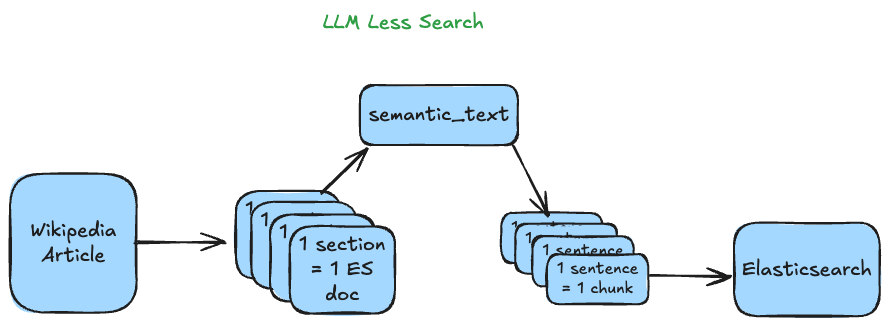
To get these benefits, we’ll use the semantic_text field, text chunking, and semantic highlighting. To learn about the latest semantic_text features, I recommend reading this article.
We’ll create an app using Streamlit to put everything together. It should look something like this:
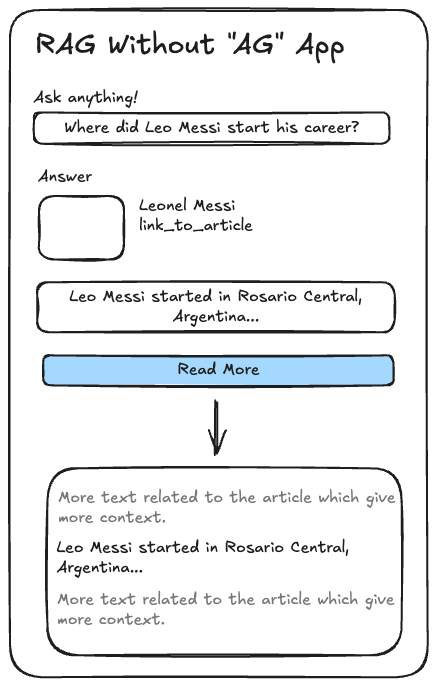
The goal is to ask a question, get the sentence that answers it from the source documents, and then have a button to see the sentence in context. To improve the user experience, we’ll also add some metadata, like the article’s thumbnail, title, and link to the source. This way, depending on the article, the card with the answer will be different.
Requirements:
- Elastic Serverless instance. Start your trial here
- Python
Regarding the document structure, we’ll index Wikipedia pages so that each article’s section becomes an Elasticsearch document, and then, each document will be chunked into sentences. This way, we’ll get precision for the sentences that answer our question and a reference to see the sentence in context.
These are the steps to create and test the app:
I’ve only included the main blocks in this article, but you can access the full repository here.
Configure Inference endpoint
Import dependencies
from elasticsearch import Elasticsearch
import os
os.environ["ELASTIC_ENDPOINT"] = (
"your_es_endpoint"
)
os.environ["ELASTIC_API_KEY"] = (
"your_es_key"
)
es = Elasticsearch(
os.environ["ELASTIC_ENDPOINT"],
api_key=os.environ["ELASTIC_API_KEY"],
)
INDEX_NAME = "wikipedia"To begin, we’ll configure the inference endpoint where we will define ELSER as our model and establish the chunking settings:
- strategy: It can be “sentence” or “word.” We’ll choose “sentence” to make sure all of our chunks have complete sentences, and therefore, the highlighting works for phrases and not words to make the answers more fluid.
- max_chunk_size: Defines the maximum amount of words in a chunk.
- sentence_overlap: Number of overlapping sentences. It goes from 1 to 0. We’ll set it to 0 to have better highlighting precision. Number 1 is recommended when you want to capture adjoining content.
You can read this article to learn more about chunking strategies.
es.options(request_timeout=60, max_retries=3, retry_on_timeout=True).inference.put(
task_type="sparse_embedding",
inference_id="wiki-inference",
body={
"service": "elasticsearch",
"service_settings": {
"adaptive_allocations": {"enabled": True},
"num_threads": 1,
"model_id": ".elser_model_2",
},
"chunking_settings": {
"strategy": "sentence",
"max_chunk_size": 25,
"sentence_overlap": 0,
},
},
)Configure mappings
We’ll configure the following fields to define our mappings:
mapping = {
"mappings": {
"properties": {
"title": {"type": "text"},
"section_name": {"type": "text"},
"content": {"type": "text", "copy_to": "semantic_content"},
"wiki_link": {"type": "keyword"},
"image_url": {"type": "keyword"},
"section_order": {"type": "integer"},
"semantic_content": {
"type": "semantic_text",
"inference_id": "wiki-inference",
},
}
}
}
# Create the index with the mapping
if es.indices.exists(index=INDEX_NAME):
es.indices.delete(index=INDEX_NAME)
es.indices.create(index=INDEX_NAME, body=mapping)It’s crucial to make sure you copy the content field into our semantic_content field to run semantic searches.
Upload documents
We’ll use the following script to upload the document from this Wikipedia page about Lionel Messi.
# Define article metadata
title = "Lionel Messi"
wiki_link = "https://en.wikipedia.org/wiki/Lionel_Messi"
image_url = "https://upload.wikimedia.org/wikipedia/commons/b/b4/Lionel-Messi-Argentina-2022-FIFA-World-Cup_%28cropped%29.jpg"
# Define sections as array of objects
sections = [
{
"section_name": "Introduction",
"content": """Lionel Andrés "Leo" Messi (Spanish pronunciation: [ljoˈnel anˈdɾes ˈmesi] ⓘ; born 24 June 1987) is an Argentine professional footballer who plays as a forward for and captains both Major League Soccer club Inter Miami and the Argentina national team. Widely regarded as one of the greatest players of all time, Messi set numerous records for individual accolades won throughout his professional footballing career such as eight Ballon d'Or awards and eight times being named the world's best player by FIFA. He is the most decorated player in the history of professional football having won 45 team trophies, including twelve Big Five league titles, four UEFA Champions Leagues, two Copa Américas, and one FIFA World Cup. Messi holds the records for most European Golden Shoes (6), most goals in a calendar year (91), most goals for a single club (672, with Barcelona), most goals (474), hat-tricks (36) and assists (192) in La Liga, most assists (18) and goal contributions (32) in the Copa América, most goal contributions (21) in the World Cup, most international appearances (191) and international goals (112) by a South American male, and the second-most in the latter category outright. A prolific goalscorer and creative playmaker, Messi has scored over 850 senior career goals and has provided over 380 assists for club and country.""",
},
{
"section_name": "Early Career at Barcelona",
"content": """Born in Rosario, Argentina, Messi relocated to Spain to join Barcelona at age 13, and made his competitive debut at age 17 in October 2004. He gradually established himself as an integral player for the club, and during his first uninterrupted season at age 22 in 2008–09 he helped Barcelona achieve the first treble in Spanish football. This resulted in Messi winning the first of four consecutive Ballons d'Or, and by the 2011–12 season he would set La Liga and European records for most goals in a season and establish himself as Barcelona's all-time top scorer. The following two seasons, he finished second for the Ballon d'Or behind Cristiano Ronaldo, his perceived career rival. However, he regained his best form during the 2014–15 campaign, where he became the all-time top scorer in La Liga, led Barcelona to a historic second treble, and won a fifth Ballon d'Or in 2015. He assumed Barcelona's captaincy in 2018 and won a record sixth Ballon d'Or in 2019. During his overall tenure at Barcelona, Messi won a club-record 34 trophies, including ten La Liga titles and four Champions Leagues, among others. Financial difficulties at Barcelona led to Messi signing with French club Paris Saint-Germain in August 2021, where he would win the Ligue 1 title during both of his seasons there. He joined Major League Soccer club Inter Miami in July 2023.""",
},
{
"section_name": "International Career",
"content": """An Argentine international, Messi is the national team's all-time leading goalscorer and most-capped player. His style of play as a diminutive, left-footed dribbler, drew career-long comparisons with compatriot Diego Maradona, who described Messi as his successor. At the youth level, he won the 2005 FIFA World Youth Championship and gold medal in the 2008 Summer Olympics. After his senior debut in 2005, Messi became the youngest Argentine to play and score in a World Cup in 2006. Assuming captaincy in 2011, he then led Argentina to three consecutive finals in the 2014 FIFA World Cup, the 2015 Copa América and the Copa América Centenario, all of which they would lose. After initially announcing his international retirement in 2016, he returned to help his country narrowly qualify for the 2018 FIFA World Cup, which they would exit early. Messi and the national team finally broke Argentina's 28-year trophy drought by winning the 2021 Copa América, which helped him secure his seventh Ballon d'Or that year. He then led Argentina to win the 2022 Finalissima, as well as the 2022 FIFA World Cup, his country's third overall world championship and first in 36 years. This followed with a record-extending eighth Ballon d'Or in 2023, and a victory in the 2024 Copa América.""",
},
# Add more sections as needed...
]
# Load each section as a separate document
for i, section in enumerate(sections):
document = {
"title": title,
"section_name": section["section_name"],
"content": section["content"],
"wiki_link": wiki_link,
"image_url": image_url,
"section_order": i,
}
# Index the document
es.index(index=INDEX_NAME, document=document)
# Refresh the index to make documents searchable immediately
es.indices.refresh(index=INDEX_NAME)Create App
We’ll create an app that will get a question, then search in Elasticsearch for the most relevant sentences, and then create an answer using highlighting to showcase the most relevant answer individually while also showing the section from which the sentence came. This way, the user can read the answer the right way and then go deeper in a similar way to an LLM-generated answer that includes citations.
Install dependencies
pip install elasticsearch streamlit st-annotated-textLet’s begin by creating the function that runs the question’s semantic query:
# es.py
from elasticsearch import Elasticsearch
import os
os.environ["ELASTIC_ENDPOINT"] = (
"your_serverless_endpoint"
)
os.environ["ELASTIC_API_KEY"] = (
"your_search_key"
)
es = Elasticsearch(
os.environ["ELASTIC_ENDPOINT"],
api_key=os.environ["ELASTIC_API_KEY"],
)
INDEX_NAME = "wikipedia"
# Ask function
def ask(question):
print("asking question")
print(question)
response = es.search(
index=INDEX_NAME,
body={
"size": 1,
"query": {"semantic": {"field": "semantic_content", "query": question}},
"highlight": {"fields": {"semantic_content": {}}},
},
)
print("Hits",response)
hits = response["hits"]["hits"]
if not hits:
print("No hits found")
return None
answer = hits[0]["highlight"]["semantic_content"][0]
section = hits[0]["_source"]
return {"answer": answer, "section": section}In the ask method, we’ll return the first document corresponding to the complete section as full context and the first chunk from the highlight section as the answer, ordered by _score, that is, the most relevant to the question.
Now, we put everything together in a Streamlit app. To highlight the answer, we’ll use annotated_text, which is a component that makes it easier to color and identify the highlighted text.
# ui.py
import streamlit as st
from es import ask
from annotated_text import annotated_text
def highlight_answer_in_section(section_text, answer):
"""Highlight the answer within the section text using annotated_text"""
before, after = section_text.split(answer, 1)
# Return the text with the answer annotated
return annotated_text(
before,
(answer, "", "rgb(22 97 50)"),
after
)
def main():
st.title("Wikipedia Q&A System")
question = st.text_input("Ask a question about Lionel Messi:")
if question:
try:
# Get response from elasticsearch
result = ask(question)
if result and "section" in result:
section = result["section"]
answer = result["answer"]
# Display article metadata
col1, col2 = st.columns([1, 2])
with col1:
st.image(
section["image_url"],
caption=section["title"],
use_container_width=True,
)
with col2:
st.header(section["title"])
st.write(f"From section: {section['section_name']}")
st.write(f"[Read full article]({section['wiki_link']})")
# Display the answer
st.subheader("Answer:")
st.markdown(answer)
# Add toggle button for full context
on = st.toggle("Show context")
if on:
st.subheader("Full Context:")
highlight_answer_in_section(
section["content"], answer
)
else:
st.error("Sorry, I couldn't find a relevant answer to your question.")
except Exception as e:
st.error(f"An error occurred: {str(e)}")
st.error("Please try again with a different question.")
if __name__ == "__main__":
main()Final test
To test, we only need to run the code and ask our question:
streamlit run ui.py
Not bad! The quality of the answers will be as good as our data and the correlation between the question and the available sentences.
Conclusion
With a good document structure and a good semantic search model like ELSER, it’s possible to build a Q&A experience with no need for an LLM. Though it has limitations, it’s an option worthy of trying to better understand data and not just sending everything to an LLM hoping for the best.
In this article, we showed that using semantic search, semantic highlighting, and a bit of Python code, you can get close to the results from a RAG system without its cons like cost, latency, privacy, and management, among others.
Elements like document structure and user experience in the UI help to compensate for the “human” effect you get from LLM-synthesized answers, focusing on the capacity of the vector database to find the exact sentence that answers the question.
A possible next step would be to complement answers with other data sources to create a richer experience where Wikipedia is only one of the sources used to answer the question, like you get in Perplexity:
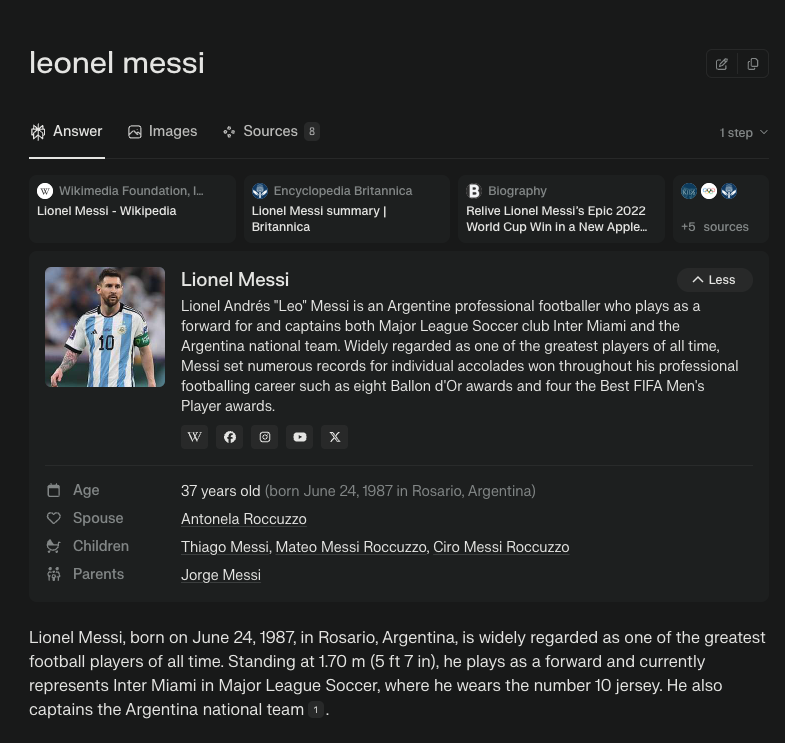
This way, we can create an app that uses different platforms to provide a 360° view of the person or entity you searched.
Are you up for trying?
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content
October 24, 2025
Building agentic applications with Elasticsearch and Microsoft’s Agent Framework
Learn how to use Microsoft Agent Framework with Elasticsearch to build an agentic application that extracts ecommerce data from Elasticsearch client libraries using ES|QL.
October 21, 2025
Introducing Elastic’s Agent Builder
Introducing Elastic Agent Builder, a framework to easily build reliable, context-driven AI agents in Elasticsearch with your data.

October 20, 2025
Elastic MCP server: Expose Agent Builder tools to any AI agent
Discover how to use the built-in Elastic MCP server in Agent Builder to securely extend any AI agent with access to your private data and custom tools.
How to use the Synonyms UI to upload and manage Elasticsearch synonyms
Learn how to use the Synonyms UI in Kibana to create synonym sets and assign them to indices.

October 13, 2025
AI Agent evaluation: How Elastic tests agentic frameworks
Learn how we evaluate and test changes to an agentic system before releasing them to Elastic users to ensure accurate and verifiable results.