In Elasticsearch, joining two indices is not as straightforward as it is in traditional SQL relational databases. However, it is possible to achieve similar results using certain techniques and features provided by Elasticsearch.
Historically, many people used the nested field type as a mechanism to join different indices together. However, it was limited due to expensive queries and incomplete support in Kibana, specifically Lens visualizations.
This article will delve into the process of joining two indices in Elasticsearch, focusing on the following approaches:
- Using the
termsquery - Using the
enrichprocessor in ingest pipelines - Logstash
elasticsearchfilter plugin - ES|QL
ENRICH - ES|QL
LOOKUP JOIN
Using the terms query
The terms query is one of the most effective ways to join two indices in Elasticsearch. This query is used to retrieve documents containing one or more exact terms in a specific field. Here we discuss how to use it to join two indices.
First, you need to retrieve the required data from the first index. This can be done using a simple GET request and pulling out the values from the _source attribute.
# Simple GET request
GET first_index/_searchOnce you have the data from the first index, you can use it to query the second index. This is done using the terms query, where you specify the field and the values you want to match.
Here is an example:
GET second_index/_search
{
"query": {
"terms": {
"field_in_second_index": ["value1_from_first_index", "value2_from_first_index"]
}
}
}
In this example, field_in_second_index is the field in the second index that you want to match with the values from the first index. value1_from_first_index and value2_from_first_index are the values from the first index that you want to match in the second index.
The terms query also provides support to perform the two above steps in a single shot using a technique called terms lookup. Elasticsearch will take care of transparently retrieving the values to match from another index. For example, if you have a teams index containing a list of players:
PUT teams/_doc/team1
{
"players": ["john", "bill", "michael"]
}
PUT teams/_doc/team2
{
"players": ["aaron", "joe", "donald"]
}It is possible to query a people index for all the people playing in team1, as shown below:
GET people/_search?pretty
{
"query": {
"terms": {
"name" : {
"index" : "teams",
"id" : "team1",
"path" : "players"
}
}
}
}In the example above, Elasticsearch will transparently retrieve the player names from the document with id team1 in the teams index (i.e. “john”, “bill”, and “michael”) and find all documents in the people index containing any of those values in their name field.
For those who are curious, the equivalent SQL query would be:
SELECT p.* FROM people p
INNER JOIN teams t ON p.name = t.playersUsing the enrich processor
The enrich processor is another powerful tool that can be used to join two indices in Elasticsearch. This processor enriches the data of incoming documents by adding data from a pre-defined enrich index.
Here’s how you can use the enrich processor to join two indices:
1. First, you need to create an enrich policy. This policy defines which index to use for enrichment, which field to match on and which field(s) to use for enriching incoming documents.
Here is an example:
PUT _enrich/policy/my_enrich_policy
{
"match": {
"indices": "first_index",
"match_field": "field_in_first_index",
"enrich_fields": ["field_to_enrich"]
}
}2. Once the policy is created, you need to execute it to create the enrich index from your newly created policy:
PUT _enrich/policy/my_enrich_policy/_executeThis will build a new hidden enriched index that will be used during enrichment. Depending on the size of the source index, this operation might take some time. Make sure that the enrich policy is fully built before proceeding to the next step.
3. After the enrich policy has been built, you can use the enrich processor in an ingest pipeline to enrich the data of incoming documents:
PUT _ingest/pipeline/my_pipeline
{
"processors": [
{
"enrich": {
"policy_name": "my_enrich_policy",
"field": "field_in_second_index",
"target_field": "enriched_field"
}
}
]
}In this example, field_in_second_index is the field in the second index that needs to match with the match_field from the first index. enriched_field is the new field in the second index that will contain the enriched data from the enrich_fields in the first index.
One drawback of this approach is that if the data changes in first_index, the enrich policy needs to be re-executed. The enriched index is not updated or synchronized automatically from the source index it has been built from. However, if first_index is relatively stable, then this approach works well.
Logstash elasticsearch filter plugin
If using Logstash, another option similar to the enrich processor described above is to use the elasticsearch filter plugin to add relevant fields to the event based on a specified query. The configuration for our Logstash pipeline would reside in a .conf file, such as my-pipeline.conf.
Let’s imagine our pipeline is pulling logs from Elasticsearch using the elasticsearch input plugin, with a query to narrow down the selection:
input {
# Read all documents from Elasticsearch matching the given query
elasticsearch {
hosts => "localhost"
query => '{ "query": { "match": { "statuscode": 200 } }, "sort": [ "_doc" ] }'
}
}If we want to enrich these messages with information from a given index, we can use the elasticsearch filter plugin in the filter section to enrich our logs:
filter {
elasticsearch {
hosts => ["localhost"]
index => "index_name"
query => "type:start AND operation:%{[opid]}"
fields => { "@timestamp" => "started" }
}
}The above code will find the documents from index index_name where type is start and the operation field matches the specified opid, and then copy the value of the @timestamp field into a new field named started.
The enriched documents would then be sent to the appropriate output source, in this case to Elasticsearch using the elasticsearch output plugin:
output {
elasticsearch {
hosts => "localhost"
data_stream => "true"
}
}If you are already using Logstash, this option may be useful to consolidate your enrichment logic in a single place and process as new events come in. However, if you are not it does add complexity to your solution, and another component that you need to run and maintain.
ES|QL ENRICH
The introduction of ES|QL, which went GA in version 8.14, is a piped query language supported by Elasticsearch that allows for the filtering, transforming and analysing of data. Using the ENRICH processing command allows us to add data from existing indices using an enrich policy.
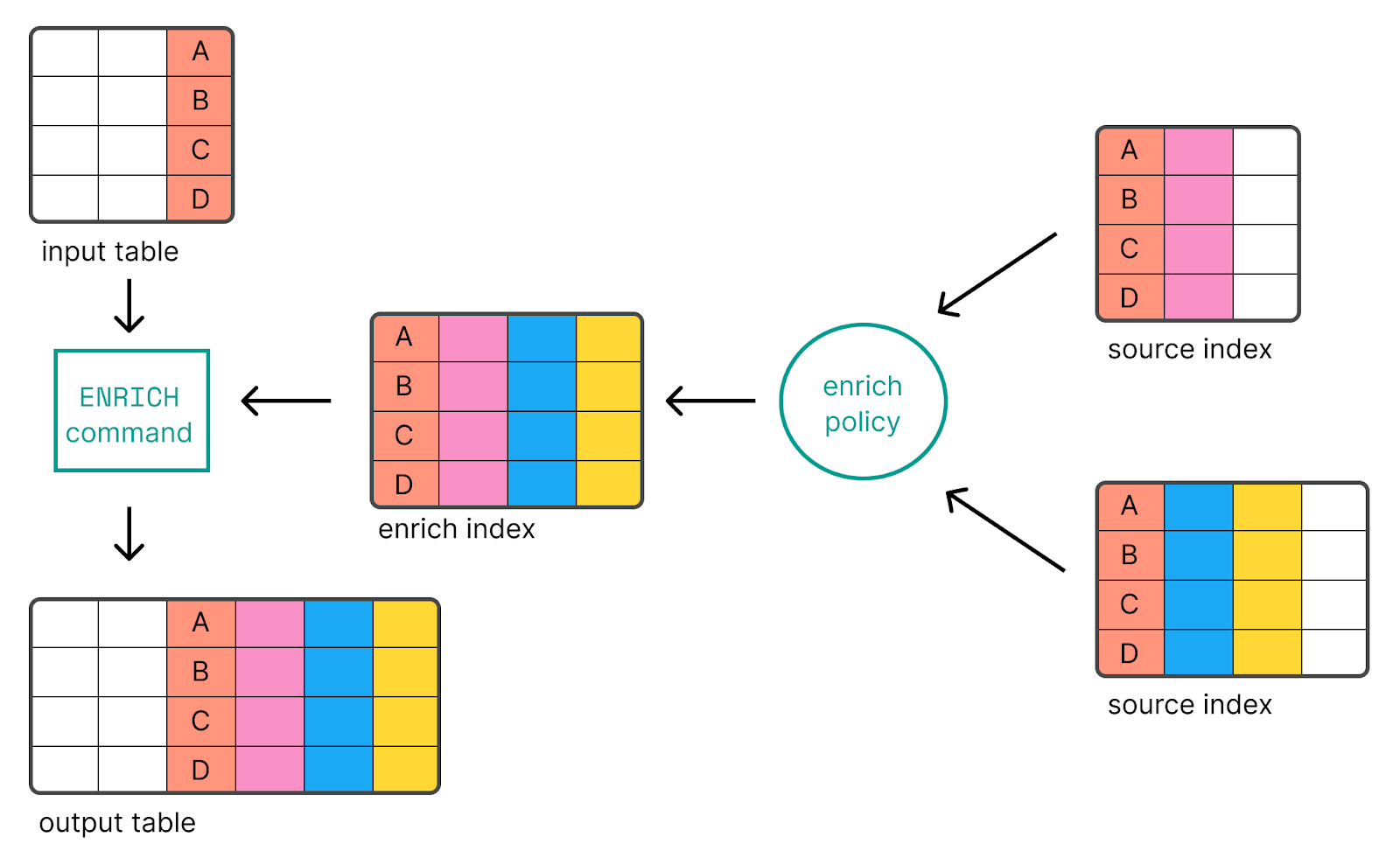
Taking the same policy my_enrich_policy from the original enrich processor example, the ES|QL example would look like the following:
FROM first_index
| WHERE field_in_first_index IS NOT NULL
| ENRICH my_enrich_policyIt is also possible to override the match and enrichment fields, which in our example are field_in_first_index and field_to_enrich respectively:
FROM first_index
| WHERE field_in_first_index IS NOT NULL
| ENRICH my_enrich_policy ON another_field_in_first_index WITH different_field_to_enrichWhile the obvious limitation is that you need to specify an enrich policy first, ES|QL does provide the flexibility to tweak the fields as required.
ES|QL LOOKUP JOIN
Elasticsearch 8.18 introduces a new way to join indices in Elasticsearch, namely the LOOKUP JOIN command. This command operates as an SQL-style LEFT OUTER JOIN using the new lookup index mode on the right-hand side of the join.
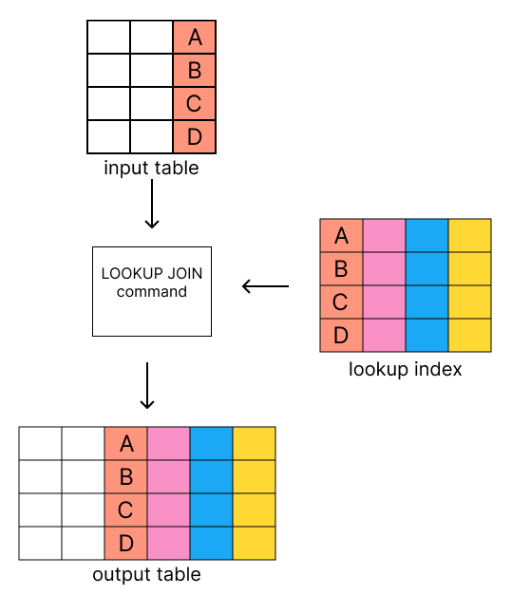
Revisiting our prior example, the new query is as follows, where match_field needs to be present in both first_index and second_index:
FROM first_index
| WHERE field_in_first_index IS NOT NULL
| LOOKUP JOIN second_index ON match_fieldThe advantage of LOOKUP JOIN over the other approaches is that it does not require any enrich policy, and therefore the additional processing associated with setting the policy up. It is useful when working with enrichment data that changes frequently, unlike the other approaches discussed in this piece.
Conclusion
In conclusion, while Elasticsearch does not support traditional join operations, it provides various features that can be used to achieve similar results. Specifically, we have covered how to achieve join operations using:
- The
termsquery - The
enrichprocessor in ingest pipelines - Logstash
elasticsearchfilter plugin - ES|QL
ENRICH - ES|QL
LOOKUP JOIN
It’s important to note that these methods have their limitations and should be used judiciously based on the specific requirements and the nature of the data.
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content
October 31, 2025
How to install and configure Elasticsearch on AWS EC2
Learn how to deploy Elasticsearch and Kibana on an Amazon EC2 instance in this step-by-step guide.
October 29, 2025
How to deploy Elasticsearch on an Azure Virtual Machine
Learn how to deploy Elasticsearch on Azure VM with Kibana for full control over your Elasticsearch setup configuration.
How to use the Synonyms UI to upload and manage Elasticsearch synonyms
Learn how to use the Synonyms UI in Kibana to create synonym sets and assign them to indices.

October 8, 2025
How to reduce the number of shards in an Elasticsearch Cluster
Learn how Elasticsearch shards affect cluster performance in this comprehensive guide, including how to get the shard count, change it from default, and reduce it if needed.
October 3, 2025
How to deploy Elasticsearch on AWS Marketplace
Learn how to set up and run Elasticsearch using Elastic Cloud Service on AWS Marketplace in this step-by-step guide.