AutoGen is a Microsoft framework for building applications that can act with human intervention or autonomously. It provides a complete ecosystem with different abstraction levels, depending on how much you need to customize.
If you want to read more about agents and how they work, I recommend you read this article.
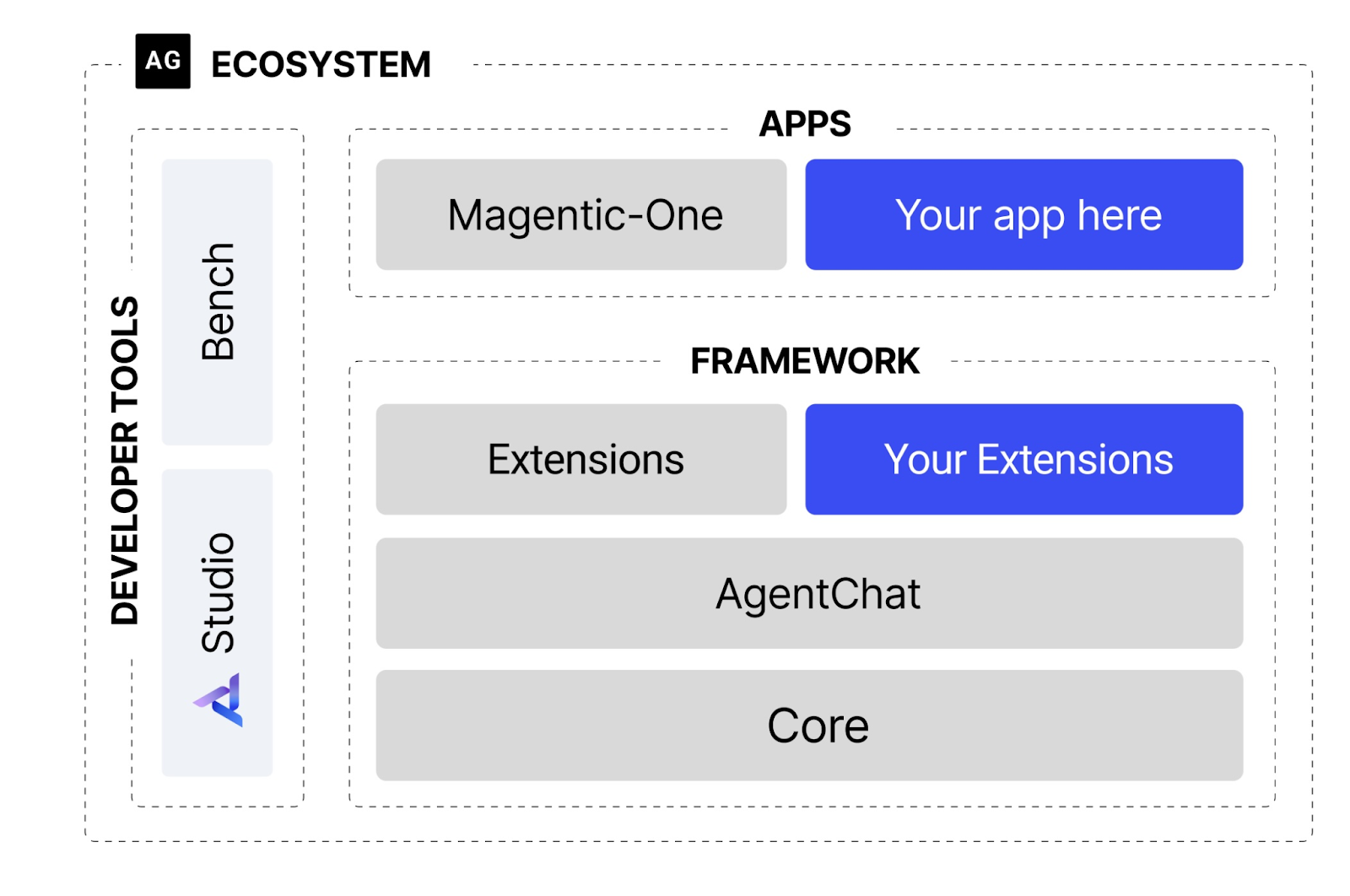
Image Source: https://github.com/microsoft/autogen
AgentChat allows you to easily instantiate preset agents on top of the AutoGen core so you can configure the model prompts, tools, etc.
On top of AgentChat, you can use extensions that allow you to extend its functionalities. The extensions are both from the official library and community-based.
The highest level of abstraction is Magnetic-One, a generalist multi-agent system designed for complex tasks. It comes preconfigured in the paper explaining this approach.
AutoGen is known for fostering communication among agents, proposing groundbreaking patterns like:
In this article, we will create an agent that uses Elasticsearch as a semantic search tool to collaborate with other agents and look for the perfect match between candidate profiles stored in Elasticsearch and job offers online.
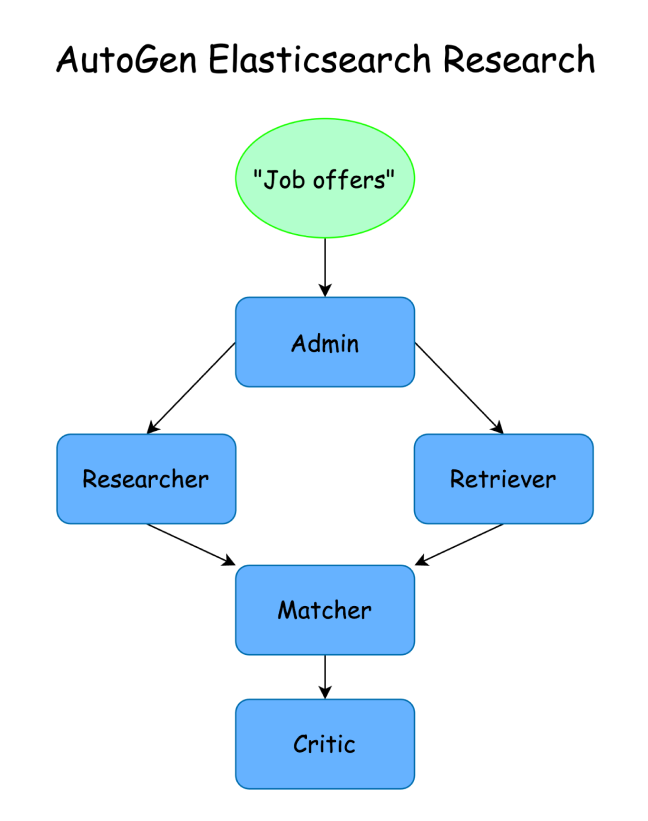
We will create a group of agents that share Elasticsearch and online information to try to match the candidates with job offers. We'll use the ´Group Chat´ pattern where an admin moderates the conversation and runs tasks while each agent specializes in a task.
The complete example is available in this Notebook.
Steps
Install dependencies and import packages
pip install autogen elasticsearch==8.17 nest-asyncioimport json
import os
import nest_asyncio
import requests
from getpass import getpass
from autogen import (
AssistantAgent,
GroupChat,
GroupChatManager,
UserProxyAgent,
register_function,
)
from elasticsearch import Elasticsearch
from elasticsearch.helpers import bulk
nest_asyncio.apply()Prepare data
Setup keys
For the agent AI endpoint, we need to provide an OpenAI API key. We will also need a Serper API key to give the agent search capabilities. Serper gives 2,500 search calls for free on sign-up. We use Serper to give our agent internet access capabilities, more specifically finding Google results. The agent can send a search query via API and Serper will return the top Google results.
os.environ["SERPER_API_KEY"] = "serper-api-key"
os.environ["OPENAI_API_KEY"] = "openai-api-key"
os.environ["ELASTIC_ENDPOINT"] = "elastic-endpoint"
os.environ["ELASTIC_API_KEY"] = "elastic-api-key"Elasticsearch client
_client = Elasticsearch(
os.environ["ELASTIC_ENDPOINT"],
api_key=os.environ["ELASTIC_API_KEY"],
)Inference endpoint and mappings
To enable semantic search capabilities, we need to create an inference endpoint using ELSER. ELSER allows us to run semantic or hybrid queries, so we can give broad tasks to our agents and semantically related documents from Elasticsearch will show up with no need of typing keywords that are present in the documents.
try:
_client.options(
request_timeout=60, max_retries=3, retry_on_timeout=True
).inference.put(
task_type="sparse_embedding",
inference_id="jobs-candidates-inference",
body={
"service": "elasticsearch",
"service_settings": {
"adaptive_allocations": {"enabled": True},
"num_threads": 1,
"model_id": ".elser_model_2",
},
},
)
print("Inference endpoint created successfully.")
except Exception as e:
print(
f"Error creating inference endpoint: {e.info['error']['root_cause'][0]['reason'] }"
)Mappings
For the mappings, we are going to copy all the relevant text fields into the semantic_text field so we can run semantic or hybrid queries against the data.
try:
_client.indices.create(
index="available-candidates",
body={
"mappings": {
"properties": {
"candidate_name": {
"type": "text",
"copy_to": "semantic_field"
},
"position_title": {
"type": "text",
"copy_to": "semantic_field"
},
"profile_description": {
"type": "text",
"copy_to": "semantic_field"
},
"expected_salary": {
"type": "text",
"copy_to": "semantic_field"
},
"skills": {
"type": "keyword",
"copy_to": "semantic_field"
},
"semantic_field": {
"type": "semantic_text",
"inference_id": "positions-inference"
}
}
}
}
)
print("index created successfully")
except Exception as e:
print(f"Error creating inference endpoint: {e.info['error']['root_cause'][0]['reason'] }")Ingesting documents to Elasticsearch
We are going to load data about the job applicants and ask our agents to find the ideal job for each of them based on their experience and expected salary.
documents = [
{
"candidate_name": "John",
"position_title": "Software Engineer",
"expected_salary": "$85,000 - $120,000",
"profile_description": "Experienced software engineer with expertise in backend development, cloud computing, and scalable system architecture.",
"skills": ["Python", "Java", "AWS", "Microservices", "Docker", "Kubernetes"]
},
{
"candidate_name": "Emily",
"position_title": "Data Scientist",
"expected_salary": "$90,000 - $140,000",
"profile_description": "Data scientist with strong analytical skills and experience in machine learning and big data processing.",
"skills": ["Python", "SQL", "TensorFlow", "Pandas", "Hadoop", "Spark"]
},
{
"candidate_name": "Michael",
"position_title": "DevOps Engineer",
"expected_salary": "$95,000 - $130,000",
"profile_description": "DevOps specialist focused on automation, CI/CD pipelines, and infrastructure as code.",
"skills": ["Terraform", "Ansible", "Jenkins", "Docker", "Kubernetes", "AWS"]
},
{
"candidate_name": "Sarah",
"position_title": "Product Manager",
"expected_salary": "$110,000 - $150,000",
"profile_description": "Product manager with a technical background, skilled in agile methodologies and user-centered design.",
"skills": ["JIRA", "Agile", "Scrum", "A/B Testing", "SQL", "UX Research"]
},
{
"candidate_name": "David",
"position_title": "UX/UI Designer",
"expected_salary": "$70,000 - $110,000",
"profile_description": "Creative UX/UI designer with experience in user research, wireframing, and interactive prototyping.",
"skills": ["Figma", "Adobe XD", "Sketch", "HTML", "CSS", "JavaScript"]
},
{
"candidate_name": "Jessica",
"position_title": "Cybersecurity Analyst",
"expected_salary": "$100,000 - $140,000",
"profile_description": "Cybersecurity expert with experience in threat detection, penetration testing, and compliance.",
"skills": ["Python", "SIEM", "Penetration Testing", "Ethical Hacking", "Nmap", "Metasploit"]
},
{
"candidate_name": "Robert",
"position_title": "Cloud Architect",
"expected_salary": "$120,000 - $180,000",
"profile_description": "Cloud architect specializing in designing secure and scalable cloud infrastructures.",
"skills": ["AWS", "Azure", "GCP", "Kubernetes", "Terraform", "CI/CD"]
},
{
"candidate_name": "Sophia",
"position_title": "AI/ML Engineer",
"expected_salary": "$100,000 - $160,000",
"profile_description": "Machine learning engineer with experience in deep learning, NLP, and computer vision.",
"skills": ["Python", "PyTorch", "TensorFlow", "Scikit-Learn", "OpenCV", "NLP"]
},
{
"candidate_name": "Daniel",
"position_title": "QA Engineer",
"expected_salary": "$60,000 - $100,000",
"profile_description": "Quality assurance engineer focused on automated testing, test-driven development, and software reliability.",
"skills": ["Selenium", "JUnit", "Cypress", "Postman", "Git", "CI/CD"]
},
{
"candidate_name": "Emma",
"position_title": "Technical Support Specialist",
"expected_salary": "$50,000 - $85,000",
"profile_description": "Technical support specialist with expertise in troubleshooting, customer support, and IT infrastructure.",
"skills": ["Linux", "Windows Server", "Networking", "SQL", "Help Desk", "Scripting"]
}
]def build_data():
for doc in documents:
yield {"_index": "available-candidates", "_source": doc}
try:
success, errors = bulk(_client, build_data())
if errors:
print("Errors during indexing:", errors)
else:
print(f"{success} documents indexed successfully")
except Exception as e:
print(f"Error: {str(e)}")Configure agents
AI endpoint configuration
Let’s configure the AI endpoint based on the environment variables we defined in the first step.
config_list = [{"model": "gpt-4o-mini", "api_key": os.environ["OPENAI_API_KEY"]}]
ai_endpoint_config = {"config_list": config_list}Create agents
We´ll begin by creating the admin that will moderate the conversation and run the tasks the agents propose.
Then, we´ll create the agents that will carry out each task:
- Admin: leads the conversation and executes the other agents’ actions.
- Researcher: navigates online searching for job offers.
- Retriever: looks up candidates in Elastic.
- Matcher: tries to match the offers and the candidates.
- Critic: evaluates the quality of a match before providing the final answer.
user_proxy = UserProxyAgent(
name="Admin",
system_message="""You are a human administrator.
Your role is to interact with agents and tools to execute tasks efficiently.
Execute tasks and agents in a logical order, ensuring that all agents perform
their duties correctly. All tasks must be approved by you before proceeding.""",
human_input_mode="NEVER",
code_execution_config=False,
is_termination_msg=lambda msg: msg.get("content") is not None
and "TERMINATE" in msg["content"],
llm_config=ai_endpoint_config,
)
researcher = AssistantAgent(
name="Researcher",
system_message="""You are a Researcher.
Your role is to use the 'search_in_internet' tool to find individual
job offers realted to the candidates profiles. Each job offer must include a direct link to a specific position,
not just a category or group of offers. Ensure that all job offers are relevant and accurate.""",
llm_config=ai_endpoint_config,
)
retriever = AssistantAgent(
name="Retriever",
llm_config=ai_endpoint_config,
system_message="""You are a Retriever.
Your task is to use the 'elasticsearch_hybrid_search' tool to retrieve
candidate profiles from Elasticsearch.""",
)
matcher = AssistantAgent(
name="Matcher",
system_message="""Your role is to match job offers with suitable candidates.
The matches must be accurate and beneficial for both parties.
Only match candidates with job offers that fit their qualifications.""",
llm_config=ai_endpoint_config,
)
critic = AssistantAgent(
name="Critic",
system_message="""You are the Critic.
Your task is to verify the accuracy of job-candidate matches.
If the matches are correct, inform the Admin and include the word 'TERMINATE' to end the process.""", # End condition
llm_config=ai_endpoint_config,
)Configure tools
For this project, we need to create two tools: one to search in Elasticsearch and another to search online. Tools are a Python function that we will register and assign to agents next.
Tools methods
async def elasticsearch_hybrid_search(question: str):
"""
Search in Elasticsearch using semantic search capabilities.
"""
response = _client.search(
index="available-candidates",
body={
"_source": {
"includes": [
"candidate_name",
"position_title",
"profile_description",
"expected_salary",
"skills",
],
},
"size": 10,
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {"match": {"position_title": question}}
}
},
{
"standard": {
"query": {
"semantic": {
"field": "semantic_field",
"query": question,
}
}
}
},
]
}
},
},
)
hits = response["hits"]["hits"]
if not hits:
return ""
result = json.dumps([hit["_source"] for hit in hits], indent=2)
return result
async def search_in_internet(query: str):
"""Search in internet using Serper and retrieve results in json format"""
url = "https://google.serper.dev/search"
headers = {
"X-API-KEY": os.environ["SERPER_API_KEY"],
"Content-Type": "application/json",
}
payload = json.dumps({"q": query})
response = requests.request("POST", url, headers=headers, data=payload)
original_results = response.json()
related_searches = original_results.get("relatedSearches", [])
original_organics = original_results.get("organic", [])
for search in related_searches:
payload = json.dumps({"q": search.get("query")})
response = requests.request("POST", url, headers=headers, data=payload)
original_organics.extend(response.json().get("organic", []))
return original_organicsAssigning tools to agents
For the tools to work properly, we need to define a caller that will determine the parameters for the function and an executor that will run said function. We will define the admin as the executor and the respective agent as the caller.
register_function(
elasticsearch_hybrid_search,
caller=retriever,
executor=user_proxy,
name="elasticsearch_hybrid_search",
description="A method retrieve information from Elasticsearch using semantic search capabilities",
)
register_function(
search_in_internet,
caller=researcher,
executor=user_proxy,
name="search_in_internet",
description="A method for search in internet",
)Run task
We will now define a group chat with all agents, where the administrator assigns turns for each agent to define the task it wants to call and end it once the defined conditions are met based on previous instructions.
groupchat = GroupChat(
agents=[user_proxy, researcher, retriever, matcher, critic],
messages=[],
max_round=50,
)
manager = GroupChatManager(groupchat=groupchat, llm_config=ai_endpoint_config)
user_proxy.initiate_chat(
manager,
message="""Compare the candidate profiles retrieved by the Retriever with the job offers
found by the Researcher on the internet.
Both candidate profiles and job offers are related to the software industry.
Ensure that each match is accurate and beneficial for both parties.
Each candidate should be matched with a single job offer.
Include the job offer link provided by the Researcher.""",
)Reasoning
(Formatted for readability)
The output will look like this:
Admin (to chat_manager):
Compare the candidate profiles retrieved by the Retriever with the job offers
found by the Researcher on the internet.
Both candidate profiles and job offers are related to the software industry.
Ensure that each match is accurate and beneficial for both parties.
Each candidate should be matched with a single job offer.
Include the job offer link provided by the Researcher.Next speaker: Matcher
Matcher (to chat_manager):
I currently do not have access to external databases or the ability to retrieve specific candidate profiles or job offers. However, I can help guide you on how to effectively match candidates with job offers based on their qualifications and the requirements of the jobs.
1. **Identify Key Qualities**: For each job offer, list the key qualifications, skills, and experience required. Look for programming languages, technologies, years of experience, and any other competencies that are mentioned.
2. **Analyze Candidate Profiles**: For each candidate, evaluate their skills, education, and experience. Pay special attention to their technical skills and past roles to ensure they align with the job requirements.
3. **Create Matching Criteria**: Develop criteria for grading matches, such as:
- Exact match (essential skills/experience)
- General match (related skills/experience)
- Desirable match (preferred qualifications)
4. **Match Candidates to Job Offers**: Based on the above analysis, start matching candidates to job offers. Aim to find roles that play to the candidate's strengths and career aspirations.
5. **Link Job Offers**: Ensure that for every candidate matched, the corresponding job offer link is provided.
Once you have the specific candidate profiles and job offers, you can follow these steps to create accurate and beneficial matches. If you have specific examples or data, I can help you formulate the matches!Next speaker: Retriever
Retriever (to chat_manager):
***** Suggested tool call (call_0yjI5x0gvcLAJeDbiDKYPtFD): elasticsearch_hybrid_search *****
Arguments:
{"question":"Retrieve candidate profiles related to software development and engineering."}
********************************************************************************************Next speaker: Admin
>>>>>>>> EXECUTING FUNCTION elasticsearch_hybrid_search...
Call ID: call_0yjI5x0gvcLAJeDbiDKYPtFD
Input arguments: {'question': 'Retrieve candidate profiles related to software development and engineering.'}Admin (to chat_manager):
***** Response from calling tool (call_0yjI5x0gvcLAJeDbiDKYPtFD) *****
[
{
….Researcher (to chat_manager):
***** Suggested tool call (call_X0bSSvAKuilPJ9hY90AJvMud): search_in_internet *****
Arguments:
{"query": "Software Engineer job offers Python Java AWS Microservices Docker Kubernetes"}
….Next speaker: Critic
Critic (to chat_manager):
The matches are accurate and beneficial for both candidates and job offers.
**Matches Summary:**
1. **John** - Lead Software Engineer, Full Stack (Java, Python, AWS) at Capital One.
2. **Daniel** - Quality Assurance Engineer for Homey - Taro.
3. **Michael** - DevOps Engineer - Kubernetes, Terraform, Jenkins, Ansible, AWS at Cisco.
4. **Sophia** - AI/ML Engineer at Chesterfield, Missouri, United States.
5. **David** - UX/UI Designer at HR Force International in New York.Admin has been informed of the successful candidate-job offer matches.
**TERMINATE**Results
(Formatted for readability)
### Candidate: John
- **Profile**: Experienced software engineer with expertise in backend development, cloud computing, and scalable system architecture.
- **Skills**: Python, Java, AWS, Microservices, Docker, Kubernetes.
- **Expected Salary**: $85,000 - $120,000.
- **Match**: [Lead Software Engineer, Full Stack (Java, Python, AWS) at Capital One](https://www.capitalonecareers.com/en/job/new-york/lead-software-engineer-full-stack-java-python-aws/1732/77978761520)
### Candidate: Daniel
- **Profile**: Quality assurance engineer focused on automated testing, test-driven development, and software reliability.
- **Skills**: Selenium, JUnit, Cypress, Postman, Git, CI/CD.
- **Expected Salary**: $60,000 - $100,000.
- **Match**: [Quality Assurance Engineer for Homey - Taro](https://www.jointaro.com/jobs/homey/quality-assurance-engineer/)
### Candidate: Michael
- **Profile**: DevOps specialist focused on automation, CI/CD pipelines, and infrastructure as code.
- **Skills**: Terraform, Ansible, Jenkins, Docker, Kubernetes, AWS.
- **Expected Salary**: $95,000 - $130,000.
- **Match**: [DevOps Engineer - Kubernetes, Terraform, Jenkins, Ansible, AWS at Cisco](https://jobs.cisco.com/jobs/ProjectDetail/Software-Engineer-DevOps-Engineer-Kubernetes-Terraform-Jenkins-Ansible-AWS-8-11-Years/1436347)
### Candidate: Sophia
- **Profile**: Machine learning engineer with experience in deep learning, NLP, and computer vision.
- **Skills**: Python, PyTorch, TensorFlow, Scikit-Learn, OpenCV, NLP.
- **Expected Salary**: $100,000 - $160,000.
- **Match**: [AI/ML Engineer - Chesterfield, Missouri, United States](https://careers.mii.com/jobs/ai-ml-engineer-chesterfield-missouri-united-states)
### Candidate: David
- **Profile**: Creative UX/UI designer with experience in user research, wireframing, and interactive prototyping.
- **Skills**: Figma, Adobe XD, Sketch, HTML, CSS, JavaScript.
- **Expected Salary**: $70,000 - $110,000.
- **Match**: [HR Force International is hiring: UX/UI Designer in New York](https://www.mediabistro.com/jobs/604658829-hr-force-international-is-hiring-ux-ui-designer-in-new-york)Note that at the end of each Elasticsearch stored candidate, you can see a match field with the job listing that best fits them!
Conclusion
AutoGen allows you to create groups of agents that work together to solve a problem with different degrees of complexity. One of the available patterns is 'group chat,' where an admin leads a conversation among agents to reach a successful solution.
You can add more features to the project by creating more agents. For example, storing the matches provided back into Elasticsearch, and then automatically applying to the job offers using the WebSurfer agent. The WebSurfer agent can navigate websites using visual models and a headless browser.
To index documents in Elasticsearch, you can use a tool similar to elasticsearch_hybrid_search, but with added ingestion logic. Then, create a special agent “ingestor” to achieve indexing. Once you have that, you can implement the WebSurfer agent by following the official documentation.
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content
September 18, 2025
Using TwelveLabs’ Marengo video embedding model with Amazon Bedrock and Elasticsearch
Creating a small app to search video embeddings from TwelveLabs' Marengo model.
Using LangExtract and Elasticsearch
Learn how to extract structured data from free-form text using LangExtract and store it as fields in Elasticsearch.

Introducing the ES|QL query builder for the Python Elasticsearch Client
Learn how to use the ES|QL query builder, a new Python Elasticsearch client feature that makes it easier to construct ES|QL queries using a familiar Python syntax.
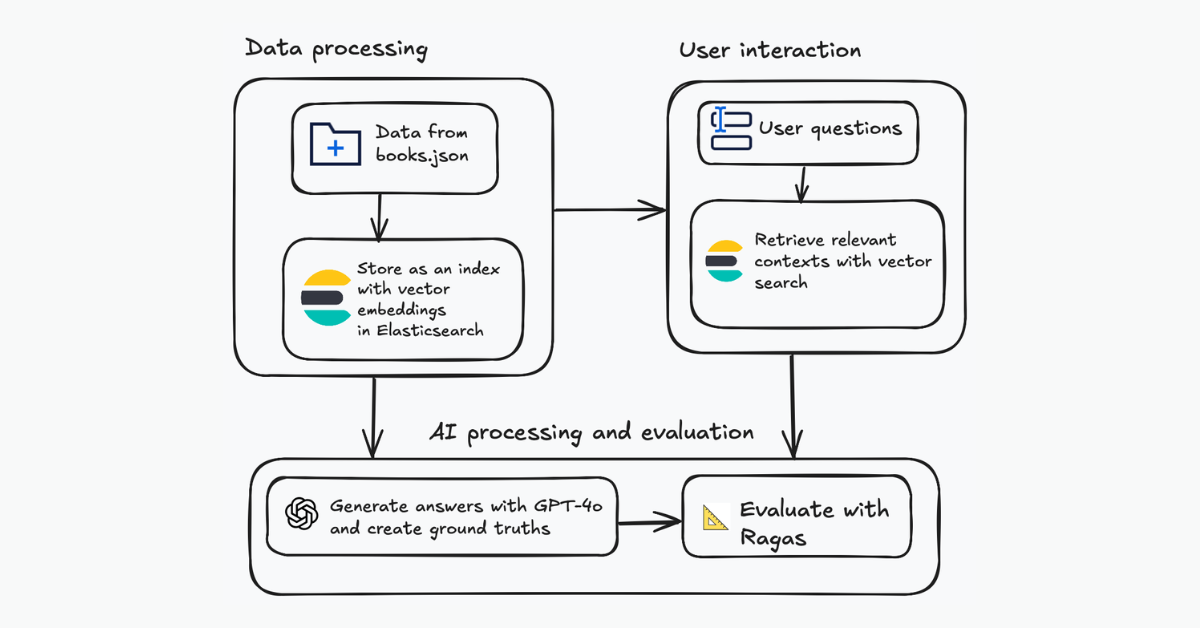
Evaluating your Elasticsearch LLM applications with Ragas
Assessing the quality of a RAG solution using Ragas metrics and Elasticsearch.
August 18, 2025
Using FastAPI’s WebSockets and Elasticsearch to build a real-time app
Learn how to build a real-time application using FastAPI WebSockets and Elasticsearch.