In this article, we are going to explore how to use the LlamaIndex RankGPT Reranker and the built-in Elasticsearch semantic reranker. Elastic provides an out-of-the-box experience to deploy and use rerankers as part of the retrievers pipeline in a scalable way without additional effort.
Originally, reranking in Elasticsearch required multiple steps, but now it’s integrated directly into the retrievers pipeline: the first stage runs the search query, and the second stage reranks the results, as shown in the image below:
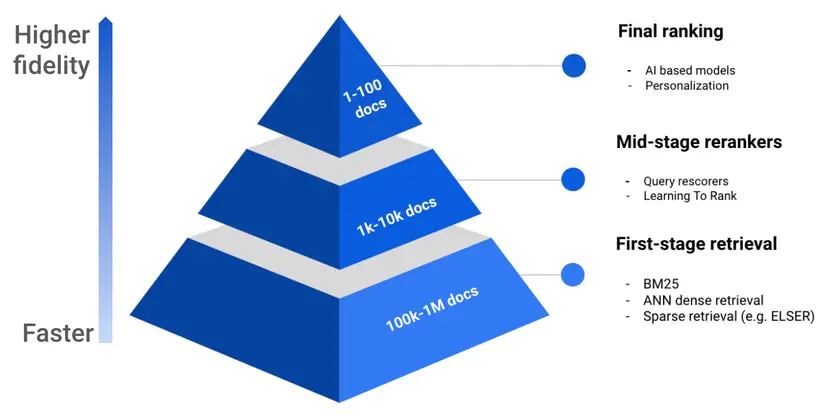
What is reranking?
Reranking is the process of using an expensive mechanism to push the most relevant documents to the top of the results after retrieving a set of documents that are relevant to the user query.
There are many strategies to rerank documents using specialized cross-encoder models, like the Elastic Rerank mode, or Cross encoder for MS Marco (cross-encoder/ms-marco-MiniLM-L6-v2). Other approaches involve using an LLM for reranking. One of the advantages of the Elastic Rerank model is that it can be used as part of a semantic search pipeline or as a standalone tool to improve existing BM25 scoring systems.
A reranker needs a list of candidates and a user query to reorganize the candidates from most to least relevant based on the user query.
In this article, we will explore the LlamaIndex RankGPT Reranker, which is a RankGPT reranker implementation, and the Elastic Semantic Reranker, using the Elastic Rerank model.
The complete example is available in this notebook.
Steps
Products index
Let’s create a reranker for laptops based on a user’s question. If a user is a hardcore gamer, they should get the most powerful machines. If they are a student, they might be okay with the lighter ones.
Let’s start with creating some documents in our Notebook:
products = [
{
"name": "ASUS ROG Strix G16",
"description": "Powerful gaming laptop with Intel Core i9 and RTX 4070.",
"price": 1899.99,
"reviews": 4.7,
"sales": 320,
"features": [
"Intel Core i9",
"RTX 4070",
"16GB RAM",
"512GB SSD",
"165Hz Display",
],
},
{
"name": "Razer Blade 15",
"description": "Premium gaming laptop with an ultra-slim design and high refresh rate." ,
"price": 2499.99,
"reviews": 4.6,
"sales": 290,
"features": [
"Intel Core i7",
"RTX 4060",
"16GB RAM",
"1TB SSD",
"240Hz Display",
],
},
{
"name": "Acer Predator Helios 300",
"description": "Affordable yet powerful gaming laptop with RTX graphics.",
"price": 1399.99,
"reviews": 4.5,
"sales": 500,
"features": [
"Intel Core i7",
"RTX 3060",
"16GB RAM",
"512GB SSD",
"144Hz Display",
],
},
{
"name": "MSI Stealth 17",
"description": "High-performance gaming laptop with a 17-inch display.",
"price": 2799.99,
"reviews": 4.8,
"sales": 200,
"features": ["Intel Core i9", "RTX 4080", "32GB RAM", "1TB SSD", "4K Display"],
},
{
"name": "Dell XPS 15",
"description": "Sleek and powerful ultrabook with a high-resolution display.",
"price": 2199.99,
"reviews": 4.7,
"sales": 350,
"features": [
"Intel Core i7",
"RTX 3050 Ti",
"16GB RAM",
"1TB SSD",
"OLED Display",
],
},
{
"name": "HP Omen 16",
"description": "Gaming laptop with a balanced price-to-performance ratio.",
"price": 1599.99,
"reviews": 4.4,
"sales": 280,
"features": [
"AMD Ryzen 7",
"RTX 3060",
"16GB RAM",
"512GB SSD",
"165Hz Display",
],
},
{
"name": "Lenovo Legion 5 Pro",
"description": "Powerful Ryzen-powered gaming laptop with high refresh rate.",
"price": 1799.99,
"reviews": 4.6,
"sales": 400,
"features": [
"AMD Ryzen 9",
"RTX 3070 Ti",
"16GB RAM",
"1TB SSD",
"165Hz Display",
],
},
{
"name": "MacBook Pro 16",
"description": "Apple's most powerful laptop with M3 Max chip.",
"price": 3499.99,
"reviews": 4.9,
"sales": 500,
"features": [
"Apple M3 Max",
"32GB RAM",
"1TB SSD",
"Liquid Retina XDR Display",
],
},
{
"name": "Alienware m18",
"description": "High-end gaming laptop with extreme performance.",
"price": 2999.99,
"reviews": 4.8,
"sales": 150,
"features": [
"Intel Core i9",
"RTX 4090",
"32GB RAM",
"2TB SSD",
"480Hz Display",
],
},
{
"name": "Samsung Galaxy Book3 Ultra",
"description": "Ultra-lightweight yet powerful laptop with AMOLED display.",
"price": 2099.99,
"reviews": 4.5,
"sales": 180,
"features": [
"Intel Core i7",
"RTX 4070",
"16GB RAM",
"512GB SSD",
"AMOLED Display",
],
},
{
"name": "Microsoft Surface Laptop 5",
"description": "Sleek productivity laptop with great battery life.",
"price": 1699.99,
"reviews": 4.3,
"sales": 220,
"features": ["Intel Core i7", "16GB RAM", "512GB SSD", "Touchscreen"],
},
{
"name": "Gigabyte AORUS 17",
"description": "Performance-focused gaming laptop with powerful cooling.",
"price": 1999.99,
"reviews": 4.6,
"sales": 250,
"features": [
"Intel Core i9",
"RTX 4070",
"16GB RAM",
"1TB SSD",
"360Hz Display",
],
},
]User question
Let's define the question we are going to use to rerank the results.
user_query = "Best laptops for gaming"LlamaIndex reranking
Install dependencies and import packages
We install all the dependencies needed to execute the RankGPT reranker of Llamaindex and Elasticsearch for document retrieval. Then, we load the laptops into an ElasticsearchStore, which is the LlamaIndex abstraction for the Elasticsearch vector database, and retrieve them using the VectorStoreIndex class.
pip install llama-index-core llama-index-llms-openai rank-llm llama-index-postprocessor-rankgpt-rerank llama-index-vector-stores-elasticsearch elasticsearch -q
import os
import nest_asyncio
from getpass import getpass
from llama_index.vector_stores.elasticsearch import ElasticsearchStore
from llama_index.core import (
Document,
VectorStoreIndex,
QueryBundle,
Settings,
StorageContext,
)
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.postprocessor.rankgpt_rerank import RankGPTRerank
from llama_index.llms.openai import OpenAI
from elasticsearch import Elasticsearch
nest_asyncio.apply()Setup keys
os.environ["OPENAI_API_KEY"] = "OPENAI_API_KEY"
os.environ["ELASTICSEARCH_ENDPOINT"] = "ELASTIC_ENDPOINT"
os.environ["ELASTICSEARCH_API_KEY"] = "ELASTIC_API_KEY"
INDEX_NAME = "products-laptops"Elasticsearch client
We instantiate the Elasticsearch client to index documents and run queries against our cluster.
_client = Elasticsearch(
os.environ["ELASTICSEARCH_ENDPOINT"],
api_key=os.environ["ELASTICSEARCH_API_KEY"],
)Mappings
We are going to use regular text fields for full-text search and also create a semantic_field with a copy of all the content so we can run semantic and hybrid queries. In Elasticsearch 8.18+, an inference endpoint will be deployed automatically.
# Creating mapping for the index
try:
_client.indices.create(
index=INDEX_NAME,
body={
"mappings": {
"properties": {
"metadata": {
"properties": {
"name": {"type": "text", "copy_to": "semantic_field"},
"description": {
"type": "text",
"copy_to": "semantic_field",
},
"price": {
"type": "float",
},
"reviews": {
"type": "float",
},
"sales": {"type": "integer"},
"features": {
"type": "keyword",
"copy_to": "semantic_field",
},
}
},
"semantic_field": {"type": "semantic_text"},
"text": {
"type": "text"
}, # Field to store the text content for LlamaIndex
"embeddings": {"type": "dense_vector", "dims": 512},
}
}
},
)
print("index created successfully")
except Exception as e:
print(
f"Error creating inference endpoint: {e.info['error']['root_cause'][0]['reason'] }"
)Indexing data to LlamaIndex
Create an ElasticsearchStore from the array of products we defined. This will create an Elasticsearch vector store that we can consume later using VectorStoreIndex.
document_objects = []
es_store = ElasticsearchStore(
es_url=os.environ["ELASTICSEARCH_ENDPOINT"],
es_api_key=os.environ["ELASTICSEARCH_API_KEY"],
index_name=INDEX_NAME,
embedding_field="embeddings",
text_field="text",
)
storage_context = StorageContext.from_defaults(vector_store=es_store)
for doc in products:
text_content = f"""
Product Name: {doc["name"]}
Description: {doc["description"]}
Price: ${doc["price"]}
Reviews: {doc["reviews"]} stars
Sales: {doc["sales"]} units sold
Features: {', '.join(doc["features"])}
"""
metadata = {
"name": doc["name"],
"description": doc["description"],
"price": doc["price"],
"reviews": doc["reviews"],
"sales": doc["sales"],
"features": doc["features"],
}
document_objects.append(Document(text=text_content, metadata=metadata))
index = VectorStoreIndex([], storage_context=storage_context)
for doc in document_objects:
index.insert(doc)LLM setup
Define the LLM that will work as a reranker:
Settings.llm = OpenAI(temperature=0, model="gpt-4.1-mini")
Settings.chunk_size = 512Rerank feature
We now create a function that executes a retriever to get the most similar documents to the user question from the vector index, then applies a RankGPTRerank reranking on top and finally returns the documents reordered.
def get_retrieved_nodes(
query_str, vector_top_k=10, reranker_top_n=5, with_reranker=False
):
query_bundle = QueryBundle(query_str)
# configure retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=vector_top_k,
)
retrieved_nodes = retriever.retrieve(query_bundle)
if with_reranker:
# configure reranker
reranker = RankGPTRerank(
llm=OpenAI(
model="gpt-4.1-mini",
temperature=0.0,
api_key=os.environ["OPENAI_API_KEY"],
),
top_n=reranker_top_n,
verbose=True,
)
retrieved_nodes = reranker.postprocess_nodes(retrieved_nodes, query_bundle)
return retrieved_nodesWe also create a function to format the resulting documents.
def visualize_retrieved_nodes(nodes):
formatted_results = []
for node in nodes:
text = node.node.get_text()
product_name = text.split("Product Name:")[1].split("\n")[0].strip()
price = text.split("Price:")[1].split("\n")[0].strip()
reviews = text.split("Reviews:")[1].split("\n")[0].strip()
features = text.split("Features:")[1].strip()
formatted_result = f"{price} - {product_name} ({reviews}) {features}"
formatted_results.append(formatted_result)
return formatted_resultsWithout rerank
We first run the request without reranking.
new_nodes = get_retrieved_nodes(
query_str=user_query,
vector_top_k=5,
with_reranker=False,
)
results = visualize_retrieved_nodes(new_nodes)
print("\nTop 5 results without rerank:")
for idx, result in enumerate(results, start=1):
print(f"{idx}. {result}")Answer:
Top 5 results without rerank:
1. $2499.99 - Razer Blade 15 (4.6 stars) Intel Core i7, RTX 4060, 16GB RAM, 1TB SSD, 240Hz Display
2. $1899.99 - ASUS ROG Strix G16 (4.7 stars) Intel Core i9, RTX 4070, 16GB RAM, 512GB SSD, 165Hz Display
3. $1999.99 - Gigabyte AORUS 17 (4.6 stars) Intel Core i9, RTX 4070, 16GB RAM, 1TB SSD, 360Hz Display
4. $2799.99 - MSI Stealth 17 (4.8 stars) Intel Core i9, RTX 4080, 32GB RAM, 1TB SSD, 4K Display
5. $2999.99 - Alienware m18 (4.8 stars) Intel Core i9, RTX 4090, 32GB RAM, 2TB SSD, 480Hz DisplayWith rerank
Now we enable reranking, which will execute the same vector search and then rerank the results using an LLM by applying the Best laptops for gaming criteria to the top 5 results. We can see subtle differences, like the Intel Core i7 processor being pushed to the bottom and the Alienware m18 being promoted to position 2.
new_nodes = get_retrieved_nodes(
user_query,
vector_top_k=5,
reranker_top_n=5,
with_reranker=True,
)
results = visualize_retrieved_nodes(new_nodes)
print("\nTop 5 results with reranking:")
for idx, result in enumerate(results, start=1):
print(f"{idx}. {result}")Answer:
Top 5 results with reranking:
1. $1899.99 - ASUS ROG Strix G16 (4.7 stars) Intel Core i9, RTX 4070, 16GB RAM, 512GB SSD, 165Hz Display
2. $2999.99 - Alienware m18 (4.8 stars) Intel Core i9, RTX 4090, 32GB RAM, 2TB SSD, 480Hz Display
3. $2799.99 - MSI Stealth 17 (4.8 stars) Intel Core i9, RTX 4080, 32GB RAM, 1TB SSD, 4K Display
4. $1999.99 - Gigabyte AORUS 17 (4.6 stars) Intel Core i9, RTX 4070, 16GB RAM, 1TB SSD, 360Hz Display
5. $2499.99 - Razer Blade 15 (4.6 stars) Intel Core i7, RTX 4060, 16GB RAM, 1TB SSD, 240Hz DisplayElasticsearch semantic reranking
Inference rerank endpoint
Create an inference endpoint that we can call in a standalone fashion to re-rank a list of candidates based on a query or when used as part of a retriever:
INFERENCE_RERANK_NAME = "my-elastic-rerank"
try:
_client.options(
request_timeout=60, max_retries=3, retry_on_timeout=True
).inference.put(
task_type="rerank",
inference_id=INFERENCE_RERANK_NAME,
body={
"service": "elasticsearch",
"service_settings": {
"model_id": ".rerank-v1",
"num_threads": 1,
"adaptive_allocations": {
"enabled": True,
"min_number_of_allocations": 1,
"max_number_of_allocations": 4,
},
},
},
)
print("Inference endpoint created successfully.")
except Exception as e:
print(
f"Error creating inference endpoint: {e.info['error']['root_cause'][0]['reason'] }"
)We define a function to execute search queries and then parse the hit back.
async def es_search(query):
response = _client.search(index=INDEX_NAME, body=query)
hits = response["hits"]["hits"]
if not hits:
return ""
return hitsAs with LlamaIndex, we create a function to format the resulting documents.
def format_es_results(hits):
formatted_results = []
for hit in hits:
metadata = hit["_source"]["metadata"]
name = metadata.get("name")
price = metadata.get("price")
reviews = metadata.get("reviews")
features = metadata.get("features")
formatted_result = f"{price} - {name} ({reviews}) {features}"
formatted_results.append(formatted_result)
return formatted_resultsSemantic query
We will start with a semantic query to return the most similar results to the user’s question.
semantic_results = await es_search(
{
"size": 5,
"query": {
"semantic": {
"field": "semantic_field",
"query": user_query,
}
},
"_source": {
"includes": [
"metadata",
]
},
}
)
semantic_formatted_results = format_es_results(semantic_results)
print("Query results:")
for idx, result in enumerate(semantic_formatted_results, start=1):
print(f"{idx}. {result}")Query results:
1. 2999.99 - Alienware m18 (4.8) ['Intel Core i9', 'RTX 4090', '32GB RAM', '2TB SSD', '480Hz Display']
2. 2799.99 - MSI Stealth 17 (4.8) ['Intel Core i9', 'RTX 4080', '32GB RAM', '1TB SSD', '4K Display']
3. 1599.99 - HP Omen 16 (4.4) ['AMD Ryzen 7', 'RTX 3060', '16GB RAM', '512GB SSD', '165Hz Display']
4. 1399.99 - Acer Predator Helios 300 (4.5) ['Intel Core i7', 'RTX 3060', '16GB RAM', '512GB SSD', '144Hz Display']
5. 1999.99 - Gigabyte AORUS 17 (4.6) ['Intel Core i9', 'RTX 4070', '16GB RAM', '1TB SSD', '360Hz Display']rerank_results = await es_search(
{
"size": 5,
"_source": {
"includes": [
"metadata",
]
},
"retriever": {
"text_similarity_reranker": {
"retriever": {
"standard": {
"query": {
"semantic": {
"field": "semantic_field",
"query": user_query,
}
}
}
},
"field": "semantic_field",
"inference_id": INFERENCE_RERANK_NAME,
"inference_text": "reorder by quality-price ratio",
"rank_window_size": 5,
}
},
}
)
rerank_formatted_results = format_es_results(rerank_results)
print("Query results:")
for idx, result in enumerate(rerank_formatted_results, start=1):
print(f"{idx}. {result}")Query result:
1. 1399.99 - Acer Predator Helios 300 (4.5) ['Intel Core i7', 'RTX 3060', '16GB RAM', '512GB SSD', '144Hz Display']
2. 2999.99 - Alienware m18 (4.8) ['Intel Core i9', 'RTX 4090', '32GB RAM', '2TB SSD', '480Hz Display']
3. 2799.99 - MSI Stealth 17 (4.8) ['Intel Core i9', 'RTX 4080', '32GB RAM', '1TB SSD', '4K Display']
4. 1999.99 - Gigabyte AORUS 17 (4.6) ['Intel Core i9', 'RTX 4070', '16GB RAM', '1TB SSD', '360Hz Display']
5. 1599.99 - HP Omen 16 (4.4) ['AMD Ryzen 7', 'RTX 3060', '16GB RAM', '512GB SSD', '165Hz Display']
In the following table, we can see a position comparison across the different tests:
| Laptop model | Llama (no rerank) | Llama (with rerank) | Elastic (no rerank) | Elastic (with rerank) |
|---|---|---|---|---|
| Razer Blade 15 | 1 | 5 | - | - |
| ASUS ROG Strix G16 | 2 | 1 | - | - |
| Gigabyte AORUS 17 | 3 | 4 | 5 | 4 |
| MSI Stealth 17 | 4 | 3 | 2 | 3 |
| Alienware m18 | 5 | 2 | 1 | 2 |
| HP Omen 16 | - | - | 3 | 5 |
| Acer Predator Helios 300 | - | - | 4 | 1 |
Legend: A dash (-) indicates the item did not appear in the top 5 for that method.
It maintains consistency by keeping high-end laptops, like the Alienware m18 and MSI Stealth 17, in the top positions—just like LlamaIndex reranking—while achieving a better quality-price balance.
Conclusion
Rerankers are a powerful tool to increase the quality of our search systems and ensure we always retrieve the most important information for each user’s question.
LlamaIndex offers a variety of reranker strategies using specialized models, or LLMs. In their simplest implementation, you can create an in-memory vector store and store your documents locally, then retrieve and rerank, or use Elasticsearch as the vector store for persistence.
Elasticsearch, on the other hand, provides an out-of-the-box inference endpoints framework where you can use rerankers as part of the retrieval pipeline or as a standalone endpoint. You can also choose from many providers like Elastic itself, Cohere, Jina, or Alibaba, or deploy any third-party compatible model. With the simplest implementation of Elasticsearch, both your documents and your reranking model live on your Elasticsearch cluster, allowing you to scale.
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content
October 27, 2025
Building agentic applications with Elasticsearch and Microsoft’s Agent Framework
Learn how to use Microsoft Agent Framework with Elasticsearch to build an agentic application that extracts ecommerce data from Elasticsearch client libraries using ES|QL.
October 21, 2025
Introducing Elastic’s Agent Builder
Introducing Elastic Agent Builder, a framework to easily build reliable, context-driven AI agents in Elasticsearch with your data.

October 20, 2025
Elastic MCP server: Expose Agent Builder tools to any AI agent
Discover how to use the built-in Elastic MCP server in Agent Builder to securely extend any AI agent with access to your private data and custom tools.
How to use the Synonyms UI to upload and manage Elasticsearch synonyms
Learn how to use the Synonyms UI in Kibana to create synonym sets and assign them to indices.

October 13, 2025
AI Agent evaluation: How Elastic tests agentic frameworks
Learn how we evaluate and test changes to an agentic system before releasing them to Elastic users to ensure accurate and verifiable results.