In this article, you will learn how to leverage LlamaIndex Workflows with Elasticsearch to quickly build a self-filtering search application using LLM.
LlamaIndex Workflows propose a different approach to the issue of splitting tasks into different agents by introducing a steps-and-events architecture. This simplifies the design compared to similar methodologies based on DAG (Directed Acyclic Graph) like LangGraph. If you want to read more about agents in general, I recommend you read this article.

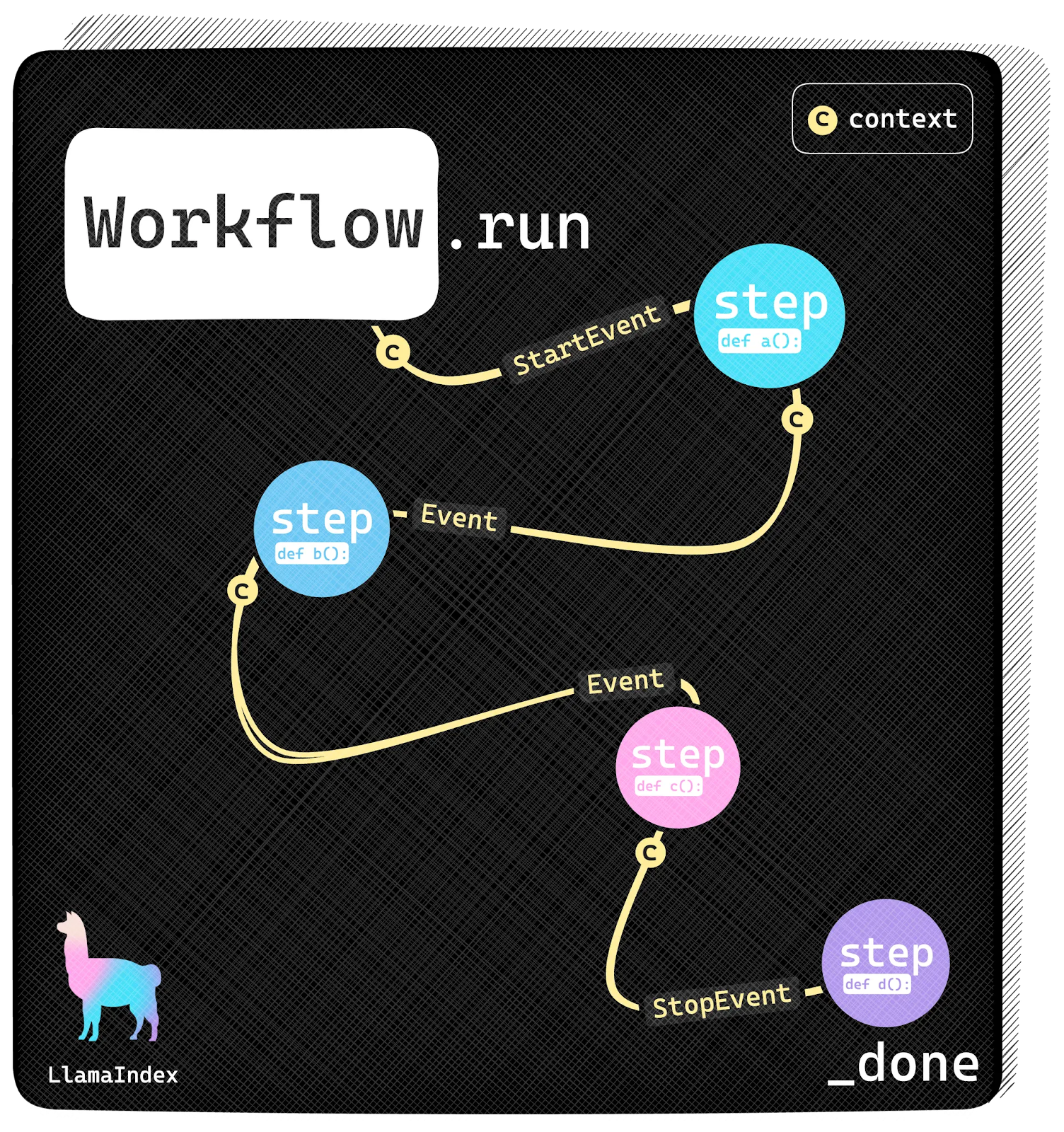
Image Source: https://www.llamaindex.ai/blog/introducing-workflows-beta-a-new-way-to-create-complex-ai-applications-with-llamaindex
One of the main LlamaIndex features is the capacity to easily create loops during execution. Loops can help us with autocorrect tasks since we can repeat a step until we get the expected result or reach a given number of retries.
To test this feature, we’ll build a flow to generate Elasticsearch queries based on the user’s question using a LLM with an autocorrect mechanism in case the generated query is not valid. If after a given amount of attempts the LLM cannot generate a valid query, we’ll change the model and keep trying until timeout.
To optimize resources, we can use the first query with a faster and cheaper model, and if the generation still fails, we can use a more expensive one.
Understanding steps and events
A step is an action that needs to be run via a code function. It receives an event together with a context, which can be shared by all steps. There are two types of base events: StartEvent, which is a flow-initiating event, and StopEven, to stop the event’s execution.
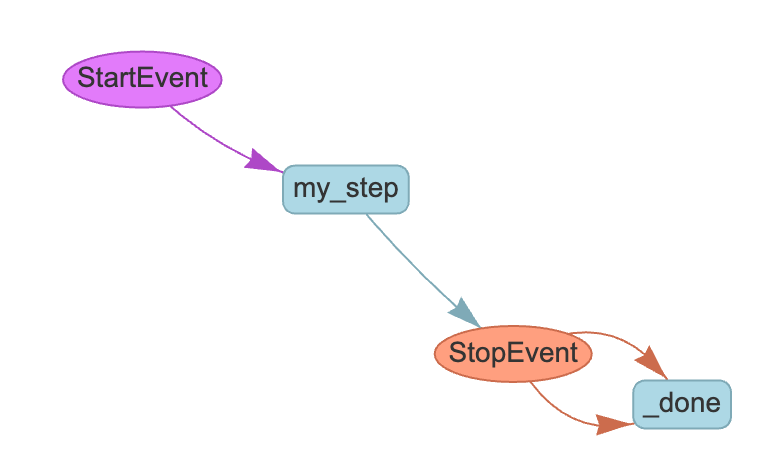
A Workflow is a class that contains all the steps and interactions and puts them all together.
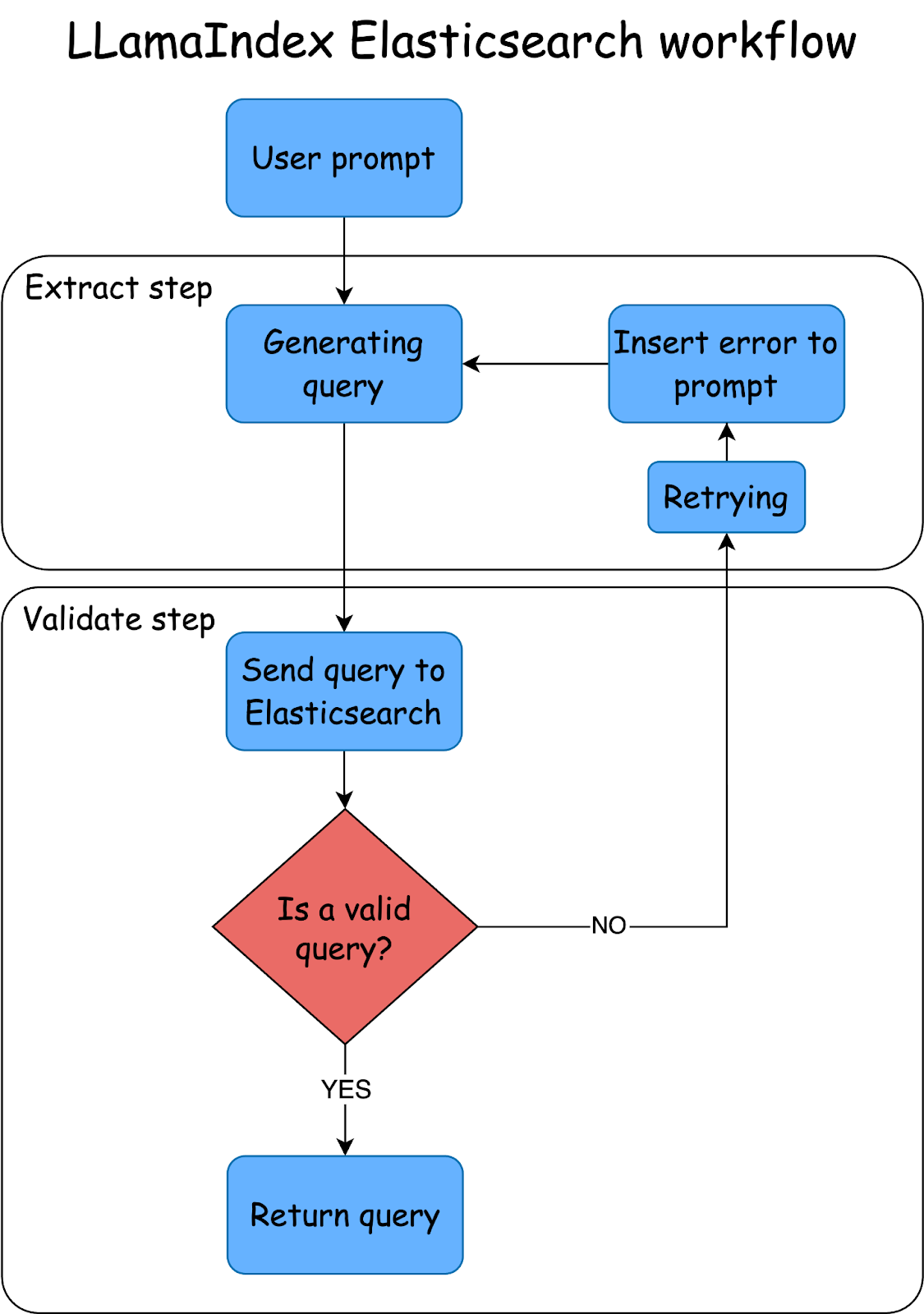
We’ll create a Workflow to receive the user’s request, expose mappings and possible fields to filter, generate the query, and then make a loop to fix an invalid query. A query could be invalid for Elasticsearch because it does not provide valid JSON or because it has syntax errors.
To show you how this works, we’ll use a practical case of searching for hotel rooms with a workflow to extract values to create queries based on the user’s search.
The complete example is available in this Notebook.
Steps
- Install dependencies and import packages
- Prepare data
- Llama-index workflows
- Execute workflow tasks
1. Install dependencies and import packages
We’ll use mistral-saba-24b and llama3-70b Groq models, so besides elasticsearch and llama-index, we’ll need the llama-index-llms-groq package to handle the interaction with the LLMs.
Groq is an inference service that allows us to use different open available models from providers like Meta, Mistral, and OpenAI. In this example, we’ll use its free layer. You can get the API KEY that we’ll use later here.
Let’s proceed to install the required dependencies: Elasticsearch, the LlamaIndex core library, and the LlamaIndex Groq LLM’s package.
pip install elasticsearch==8.17 llama-index llama-index-llms-groqWe start by importing some dependencies to handle environment variables (os), and managing JSON.
After that, we import the Elasticsearch client with the bulk helper to index using the bulk API. We finish by importing the Groq class from LlamaIndex to interact with the model, and the components to create our workflow.
import os
import json
from getpass import getpass
from elasticsearch import Elasticsearch
from elasticsearch.helpers import bulk
from llama_index.llms.groq import Groq
from llama_index.core.workflow import (
Event,
StartEvent,
StopEvent,
Workflow,
step,
)2. Prepare data
Setup keys
We set the environment variables needed for Groq and Elasticsearch. The getpass library allows us to enter them via a prompt without echoing them.
os.environ["GROQ_API_KEY"] = getpass("Groq Api key: ")
os.environ["ELASTIC_ENDPOINT"] = getpass("Elastic Endpoint: ")
os.environ["ELASTIC_API_KEY"] = getpass("Elastic Api key: ")Elasticsearch client
The Elasticsearch client handles the connection with Elasticsearch and allows us to interact with Elasticsearch using the Python library.
_client = Elasticsearch(
os.environ["ELASTIC_ENDPOINT"],
api_key=os.environ["ELASTIC_API_KEY"],
)Ingesting data to Elasticsearch
We are going to create an index with hotel rooms as an example:
INDEX_NAME="hotel-rooms"Mappings
We’ll use text-type fields for the properties where we want to run full-text queries; “keyword” for those where we want to apply filters or sorting, and “byte/integer” for numbers.
try:
_client.indices.create(
index=INDEX_NAME,
body={
"mappings": {
"properties": {
"room_name": {"type": "text"},
"description": {"type": "text"},
"price_per_night": {"type": "integer"},
"beds": {"type": "byte"},
"features": {"type": "keyword"},
}
}
},
)
print("index created successfully")
except Exception as e:
print(
f"Error creating inference endpoint: {e.info['error']['root_cause'][0]['reason'] }"
)Ingesting documents to Elasticsearch
Let’s ingest some hotel rooms and amenities so users can ask questions that we can turn into Elasticsearch queries against the documents.
documents = [
{
"room_name": "Standard Room",
"beds": 1,
"description": "A cozy room with a comfortable queen-size bed, ideal for solo travelers or couples.",
"price_per_night": 80,
"features": ["air conditioning", "wifi", "flat-screen TV", "mini fridge"]
},
{
"room_name": "Deluxe Room",
"beds": 1,
"description": "Spacious room with a king-size bed and modern amenities for a luxurious stay.",
"price_per_night": 120,
"features": ["air conditioning", "wifi", "smart TV", "mini bar", "city view"]
},
{
"room_name": "Family Room",
"beds": 2,
"description": "A large room with two queen-size beds, perfect for families or small groups.",
"price_per_night": 150,
"features": ["air conditioning", "wifi", "flat-screen TV", "sofa", "bath tub"]
},
{
"room_name": "Suite",
"beds": 1,
"description": "An elegant suite with a separate living area, offering maximum comfort and luxury.",
"price_per_night": 200,
"features": ["air conditioning", "wifi", "smart TV", "jacuzzi", "balcony"]
},
{
"room_name": "Penthouse Suite",
"beds": 1,
"description": "The ultimate luxury experience with a panoramic view and top-notch amenities.",
"price_per_night": 350,
"features": ["air conditioning", "wifi", "private terrace", "jacuzzi", "exclusive lounge access"]
},
{
"room_name": "Single Room",
"beds": 1,
"description": "A compact and comfortable room designed for solo travelers on a budget.",
"price_per_night": 60,
"features": ["wifi", "air conditioning", "desk", "flat-screen TV"]
},
{
"room_name": "Double Room",
"beds": 1,
"description": "A well-furnished room with a queen-size bed, ideal for couples or business travelers.",
"price_per_night": 100,
"features": ["air conditioning", "wifi", "mini fridge", "work desk"]
},
{
"room_name": "Executive Suite",
"beds": 1,
"description": "A high-end suite with premium furnishings and exclusive business amenities.",
"price_per_night": 250,
"features": ["air conditioning", "wifi", "smart TV", "conference table", "city view"]
},
{
"room_name": "Honeymoon Suite",
"beds": 1,
"description": "A romantic suite with a king-size bed, perfect for newlyweds and special occasions.",
"price_per_night": 220,
"features": ["air conditioning", "wifi", "hot tub", "romantic lighting", "balcony"]
},
{
"room_name": "Presidential Suite",
"beds": 2,
"description": "A luxurious suite with separate bedrooms and a living area, offering first-class comfort.",
"price_per_night": 500,
"features": ["air conditioning", "wifi", "private dining area", "personal butler service", "exclusive lounge access"]
}
]We parse the JSON documents into a bulk Elasticsearch request.
def build_data():
for doc in documents:
yield {"_index": INDEX_NAME, "_source": doc}
try:
success, errors = bulk(_client, build_data())
print(f"{success} documents indexed successfully")
if errors:
print("Errors during indexing:", errors)
except Exception as e:
print(f"Error: {str(e)}")3. LlamaIndex Workflows
We need to create a class with the functions required to send Elasticsearch mapping to the LLM, run the query, and handle errors.
class ElasticsearchRequest:
@staticmethod
def get_mappings(_es_client: Elasticsearch):
"""
Get the mappings of the Elasticsearch index.
"""
return _es_client.indices.get_mapping(index=INDEX_NAME)
@staticmethod
async def do_es_query(query: str, _es_client: Elasticsearch):
"""
Execute an Elasticsearch query and return the results as a JSON string.
"""
try:
parsed_query = json.loads(query)
if "query" not in parsed_query:
return Exception(
"Error: Query JSON must contain a 'query' key"
) # if the query is not a valid JSON return an error
response = _es_client.search(index=INDEX_NAME, body=parsed_query)
hits = response["hits"]["hits"]
if not hits or len(hits) == 0:
return Exception(
"Query has not found any results"
) # if the query has no results return an error
return json.dumps([hit["_source"] for hit in hits], indent=2)
except json.JSONDecodeError:
return Exception("Error: Query JSON no valid format")
except Exception as e:
return Exception(str(e))Workflow prompts
The EXTRACTION_PROMPT will provide the user’s question and index the mappings to the LLM so it can return an Elasticsearch query.
Then, the REFLECTION_PROMPT will help the LLM make corrections in case of errors by providing the output from the EXTRACTION_PROMPT, plus the error caused by the query.
EXTRACTION_PROMPT = """
Context information is below:
---------------------
{passage}
---------------------
Given the context information and not prior knowledge, create a Elasticsearch query from the information in the context.
The query must return the documents that match with query and the context information and the query used for retrieve the results.
{schema}
"""
REFLECTION_PROMPT = """
You already created this output previously:
---------------------
{wrong_answer}
---------------------
This caused the error: {error}
Try again; the response must contain only valid Elasticsearch queries. Do not add any sentence before or after the JSON object.
Do not repeat the query.
"""Workflow events
We created classes to handle extraction and query validation events:
class ExtractionDone(Event):
output: str
passage: str
class ValidationErrorEvent(Event):
error: str
wrong_output: str
passage: strWorkflow
Now, let’s put everything together. We first need to set the maximum number of attempts to change the model to 3.
Then, we will do an extraction using the model configured in the workflow. We validate if the event is StartEvent; if so, we capture the model and question (passage).
Afterward, we run the validation step, that is, trying to run the extracted query in Elasticsearch. If there are no errors, we generate a StopEvent and stop the flow. Otherwise, we issue a ValidationErrorEvent and repeat step 1, providing the error to try to correct it and return to the validation step. If there is no valid query after 3 attempts, we change the model and repeat the process until we reach the timeout parameter of 60s running time.
class ReflectionWorkflow(Workflow):
model_retries: int = 0
max_retries: int = 3
@step()
async def extract(
self, ev: StartEvent | ValidationErrorEvent
) -> StopEvent | ExtractionDone:
print("\n=== EXTRACT STEP ===\n")
if isinstance(ev, StartEvent):
model = ev.get("model")
passage = ev.get("passage")
if not passage:
return StopEvent(result="Please provide some text in input")
reflection_prompt = ""
elif isinstance(ev, ValidationErrorEvent):
passage = ev.passage
model = ev.model
reflection_prompt = REFLECTION_PROMPT.format(
wrong_answer=ev.wrong_output, error=ev.error
)
llm = Groq(model=model, api_key=os.environ["GROQ_API_KEY"])
prompt = EXTRACTION_PROMPT.format(
passage=passage, schema=ElasticsearchRequest.get_mappings(_client)
)
if reflection_prompt:
prompt += reflection_prompt
output = await llm.acomplete(prompt)
print(f"MODEL: {model}")
print(f"OUTPUT: {output}")
print("=================\n")
return ExtractionDone(output=str(output), passage=passage, model=model)
@step()
async def validate(self, ev: ExtractionDone) -> StopEvent | ValidationErrorEvent:
print("\n=== VALIDATE STEP ===\n")
try:
results = await ElasticsearchRequest.do_es_query(ev.output, _client)
self.model_retries += 1
if self.model_retries > self.max_retries and ev.model != "llama3-70b-8192":
print(f"Max retries for model {ev.model} reached, changing model\n")
model = "llama3-70b-8192" # if the some error occurs, the model will be changed to llama3-70b-8192
else:
model = ev.model
print(f"Elasticsearch results: {results}")
if isinstance(results, Exception):
print("STATUS: Validation failed, retrying...\n")
print("===================\n")
return ValidationErrorEvent(
error=str(results),
wrong_output=ev.output,
passage=ev.passage,
model=model,
)
# print("results: ", results)
except Exception as e:
print("STATUS: Validation failed, retrying...\n")
print("===================\n")
return ValidationErrorEvent(
error=str(e),
wrong_output=ev.output,
passage=ev.passage,
model=model,
)
return StopEvent(result=ev.output)4. Execute workflow tasks
We will make the following search: Rooms with smart TV, wifi, jacuzzi and price per night less than 300. We’ll start using the mistral-saba-24b model and switch to llama3-70b-8192, if needed, following our flow.

w = ReflectionWorkflow(timeout=60, verbose=True)
user_prompt = "Rooms with smart TV, wifi, jacuzzi and price per night less than 300"
result = await w.run(
passage=f"I need the best possible query for documents that have: {user_prompt}",
model="mistral-saba-24b",
)
print(result)Results
(Formatted for readability)
=== EXTRACT STEP ===
MODEL: mistral-saba-24b
OUTPUT:
{
"query": {
"bool": {
"must": [
{ "match": { "features": "smart TV" }},
{ "match": { "features": "wifi" }},
{ "match": { "features": "jacuzzi" }},
{ "range": { "price_per_night": { "lt": 300 }}}
]
}
}
}Step extract produced event ExtractionDone
Running step validate
=== VALIDATE STEP ===
Max retries for model mistral-saba-24b reached, changing model
Elasticsearch results:
Error: Query JSON no valid format
STATUS: Validation failed, retrying...Step validate produced event ValidationErrorEvent
Running step extract
=== EXTRACT STEP ===
MODEL: llama3-70b-8192
OUTPUT:
{
"query": {
"bool": {
"filter": [
{ "term": { "features": "smart TV" }},
{ "term": { "features": "wifi" }},
{ "term": { "features": "jacuzzi" }},
{ "range": { "price_per_night": { "lt": 300 }}}
]
}
}
}Step extract produced event ExtractionDone
Running step validate
=== VALIDATE STEP ===
Elasticsearch results:
[
{
"room_name": "Suite",
"beds": 1,
"description": "An elegant suite with a separate living area, offering maximum comfort and luxury.",
"price_per_night": 200,
"features": [
"air conditioning",
"wifi",
"smart TV",
"jacuzzi",
"balcony"
]
}
]Step validate produced event StopEvent
{
"query": {
"bool": {
"filter": [
{ "term": { "features": "smart TV" }},
{ "term": { "features": "wifi" }},
{ "term": { "features": "jacuzzi" }},
{ "range": { "price_per_night": { "lt": 300 }}}
]
}
}
}In the example above, the query failed because the mistral-saba-24b model returned it in markdown format, adding ```json at the beginning and ``` at the end. In contrast, the llama3-70b-8192 model directly returned the query using the JSON format. Based on our needs, we can capture, validate, and test different errors or build fallback mechanisms after a number of attempts.
Conclusion
The LlamaIndex workflows offer an interesting alternative to develop agentic flows using events and steps. With only a few lines of code, we managed to create a system that is able to autocorrect with interchangeable models.
How could we improve this flow?
- Along with the mappings, we can send to the LLM possible exact values for the filters, reducing the number of no result queries because of misspelled filters. To do so, we can run a terms aggregation on the features and show the results to the LLM.
- Adding code corrections to common issues—like the Markdown issue we had—to improve the success rate.
- Adding a way to handle valid queries that yield no results. For example, remove one of the filters and try again to make suggestions to the user. A LLM could be helpful in choosing which filters to remove based on the context.
- Adding more context to the prompt, like user preferences or previous searches, so that we can provide customized suggestions together with the Elasticsearch results.
Would you like to try one of these?
Ready to try this out on your own? Start a free trial.
Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running!
Related content

October 15, 2025
Training LTR models in Elasticsearch with judgement lists based on user behavior data
Learn how to use UBI data to create judgment lists to automate the training of your Learning to Rank (LTR) models in Elasticsearch.
September 19, 2025
Using TwelveLabs’ Marengo video embedding model with Amazon Bedrock and Elasticsearch
Creating a small app to search video embeddings from TwelveLabs' Marengo model.
Using LangExtract and Elasticsearch
Learn how to extract structured data from free-form text using LangExtract and store it as fields in Elasticsearch.

Introducing the ES|QL query builder for the Python Elasticsearch Client
Learn how to use the ES|QL query builder, a new Python Elasticsearch client feature that makes it easier to construct ES|QL queries using a familiar Python syntax.
Evaluating your Elasticsearch LLM applications with Ragas
Assessing the quality of a RAG solution using Ragas metrics and Elasticsearch.