Organizations rely on natural language queries to gain insights from unstructured data, but achieving high-quality answers starts with effective data preparation. Aryn DocParse and DocPrep streamline this process by converting complex documents into structured JSON or markdown, delivering up to 6x better data chunking and 2x improved recall for hybrid search and Retrieval-Augmented Generation (RAG) applications. Powered by the open-source Aryn Partitioner and effective, deep learning DETR AI model trained on 80K+ enterprise documents, these tools ensure higher accuracy and relevance compared to off-the-shelf solutions.
In this blog, we’ll demonstrate how to use DocParse and DocPrep to prepare and load a dataset of complex PDFs into Elasticsearch for a RAG application. We will use ~75 PDF reports from the National Transportation Safety Board (NTSB) about aircraft incidents. An example document from the collection is here.
What is Aryn DocParse and DocPrep
Aryn DocParse segments and labels documents, extracts tables, and images, and does OCR – turning 30+ document types into structured JSON. It runs the open-source Aryn Partitioner and its open-source deep learning DETR AI model trained on 80k+ enterprise documents. This leads to up to 6x more accurate data chunking and 2x improved recall on hybrid search or RAG compared to off-the-shelf systems.
Aryn DocPrep is a tool for creating document ETL pipelines to prepare and load this data into vector databases and hybrid search indexes like Elasticsearch. The first step in a pipeline is using DocParse to process each document. DocPrep creates Python code using Sycamore, an open-source, scalable, LLM-powered document ETL library. Though DocPrep can easily create ETL pipelines using Sycamore code, you will likely need to customize the pipeline using additional Sycamore data transforms, chunking/merging, extraction, and cleaning functions.
As can be seen, these documents are complex, containing tables, images, section headings, and complicated layouts. Let’s begin!
Building high-quality RAG apps with effective data preparation
Launch an Elasticsearch vector database container
We’ll install Elasticsearch locally using a Docker container for the demo RAG application. Follow these instructions to deploy it.
Prepare data for RAG using Aryn DocPrep and DocParse
Aryn DocPrep is a tool for creating document ETL pipelines that prepare and load data into vector databases and hybrid search indexes like Elasticsearch. The first step in a pipeline is using DocParse to process each document.
We will use Aryn DocParse in Aryn Cloud to generate our initial ETL pipeline code. You can sign up for free to use Aryn Cloud and go to the DocPrep UI in the Aryn Cloud console.
You can also write an ETL pipeline and run a version of the Aryn Partitioner (used in DocParse) locally. Visit the Sycamore documentation to learn more.
Create ETL pipeline with Aryn DocPrep
DocPrep creates Python code using Sycamore, an open-source, scalable, LLM-powered document ETL library. While DocPrep can easily create ETL pipelines using Sycamore code, you may need to customize the pipeline further with additional Sycamore data transforms, extraction, and cleaning functions.
DocPrep simplifies the creation of a base ETL pipeline to prepare unstructured data for RAG and semantic search.
First, we provide the document type (PDF) and the source location of our PDFs in Amazon S3 (s3://aryn-public/ntsb/):
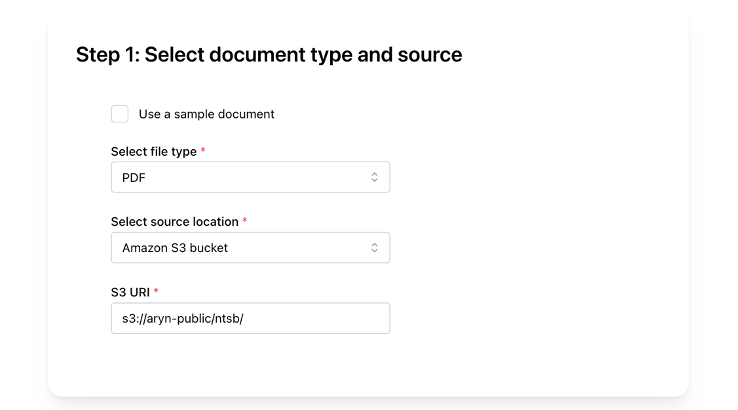
Select document type and source
Next, we will select MiniLM for our embedding model to create our vector embeddings locally. DocPrep uses DocParse for document segmentation, extraction, and other processing, but we don’t need to change the default configuration.
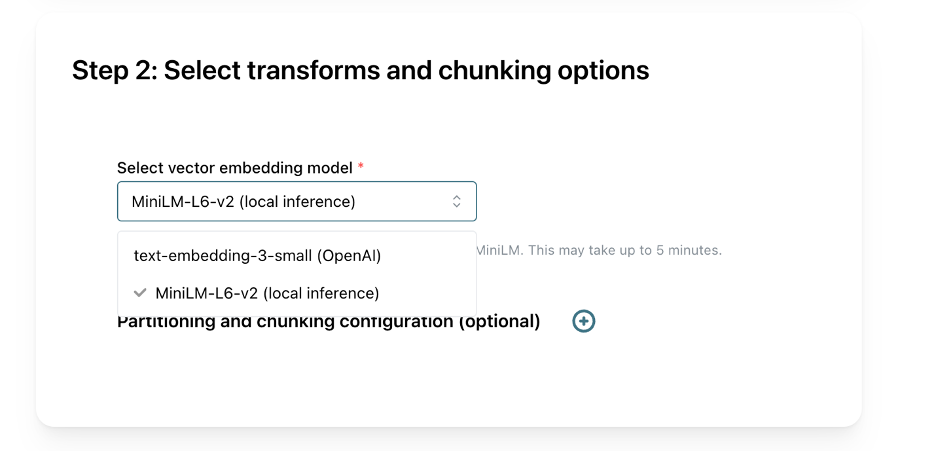
Select chunking options
Finally, we select Elasticsearch as our target database and add the Host URL and Index name. Note that the URL is set to “localhost” because we are running Elasticsearch locally. We will also run DocPrep/Sycamore ETL pipeline locally so it can easily load the cluster.
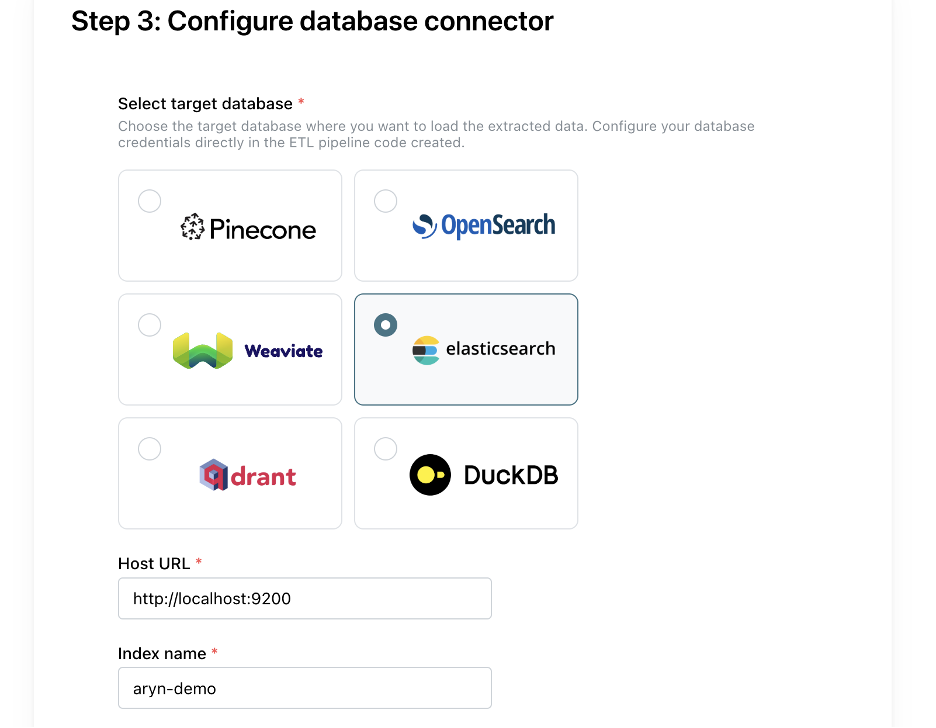
Configure Elasticsearch Connector
Now, click “Generate pipeline” to create the ETL pipeline. Click “Download notebook” on the next page to download the code as a Jupyter notebook file.
Install Jupyter and Sycamore
We will run the ETL pipeline locally in a Jupyter notebook and use the Sycamore document ETL library. As a first step, install Jupyter and Sycamore with the Elasticsearch connector and local inference libraries to create vector embeddings.
pip install jupyter
pip install 'sycamore-ai[elasticsearch,local-inference]'Run Pipeline
Run Jupyter and open the notebook with the ETL pipeline downloaded in the earlier step.
If you haven’t set your Aryn Cloud API key as an environmental variable called ARYN_API_KEY, you can set it directly in the notebook.
In the second-to-last cell, update the Elasticsearch loading configuration. Replace the es_client_args from setting an Elasticsearch password to the Elasticsearch basic auth config from your container:
es_client_args={"basic_auth": (“<YOUR-USERNAME>”, os.getenv("ELASTIC_PASSWORD"))}If the password isn’t set as an environment variable, you can add it directly here.
Now, run the cells in the notebook. Each of the ~75 PDFs is sent to DocParse for processing, and this step in the pipeline will take a few minutes. One of the cells will output three pages of a document with bounding boxes to show how DocParse segments the data.
The final cell runs a read query to verify if the data has been loaded correctly. Now, you can use the prepared data in the Elasticsearch index with your RAG application.
Add additional data enrichment and transforms
The code generated in DocPrep is great for a basic ETL pipeline, however, you may want to extract metadata and perform data cleaning. The pipeline code is fully customizable, and you can use additional transformations in Sycamore or arbitrary Python code.
Here is an example notebook with additional data transforms, metadata extraction, and data cleaning steps. You can use this metadata in your RAG applications to filter your results.
Conclusion
This blog used Aryn DocParse, DocPrep, and Sycamore to parse, extract, enrich, clean, embed, and load data into vector and keyword indexes in the Elasticsearch vector database. We used DocPrep to create an initial ETL pipeline and then used a notebook with additional Sycamore code to demonstrate additional data enrichment and cleaning.
How your documents are parsed, enriched, and processed significantly impacts the quality of your RAG queries. Use the examples in this blog post to quickly and easily build your own RAG systems with Aryn and Elasticsearch and iterate on the processing and retrieval strategies as you build your GenAI application.
Below are some resources for your next steps:
- Sample notebook with Aryn DataPrep and Elasticsearch
- start-local with Elasticsearch vector database
- Get started with Aryn Cloud DocPrep
- Sycamore documentation
- Elasticsearch vector database ecosystem integrations
Ready to try this out on your own? Start a free trial.
Elasticsearch has integrations for tools from LangChain, Cohere and more. Join our advanced semantic search webinar to build your next GenAI app!
Related content

October 23, 2025
Low-memory benchmarking in DiskBBQ and HNSW BBQ
Benchmarking Elasticsearch latency, indexing speed, and memory usage for DiskBBQ and HNSW BBQ in low-memory environments.

October 22, 2025
Deploying a multilingual embedding model in Elasticsearch
Learn how to deploy an e5 multilingual embedding model for vector search and cross-lingual retrieval in Elasticsearch.

October 23, 2025
Introducing a new vector storage format: DiskBBQ
Introducing DiskBBQ, an alternative to HNSW, and exploring when and why to use it.
September 19, 2025
Using TwelveLabs’ Marengo video embedding model with Amazon Bedrock and Elasticsearch
Creating a small app to search video embeddings from TwelveLabs' Marengo model.

September 15, 2025
Balancing the scales: Making reciprocal rank fusion (RRF) smarter with weights
Exploring weighted reciprocal rank fusion (RRF) in Elasticsearch and how it works through practical examples.