Care is an AI Assistant for caregivers. It was a prototype built by the Elastic team at the first OpenAI hackathon in APAC using:
- OpenAI’s Realtime API for fast speech-to-speech interactions
- Elasticsearch for enrichment of prompts with private medical knowledge and sensitive care instructions
- Agents for care coordination
In this blog, we’ll walk through how it works and what it can do. A clickthrough prototype can be found here and Github project here.
Speech-to-speech app with OpenAI Realtime API

Before the release of Realtime API, to build a speech-to-speech application, developers had to connect systems manually themselves. A typical example would consist of:
- Capture and Transcribe Speech (Audio-to-Text): Detect when someone starts and stops speaking then transcribe the captured audio into text using OpenAI Whisper.
- Generate Response (Text-to-Text): Process the transcribed text with OpenAI GPT-4 to generate a response.
- Convert to Speech (Text-to-Audio): Use OpenAI's Text-to-Speech model to convert the response text into audio and play it back.
The process is slow and it can’t react fast enough to allow for natural interactions. Also, capturing and transcribing speech doesn’t carry as much detail and nuance so it makes it hard to build fluid conversational experiences.

With the release of OpenAI’s Realtime API, it allows for speech generation directly from audio inputs (or other input modalities such as text or visual). Interactions happen in real-time and don't need to go through the 3 steps above, reducing latency.
So… where’s the Elastic part in this?
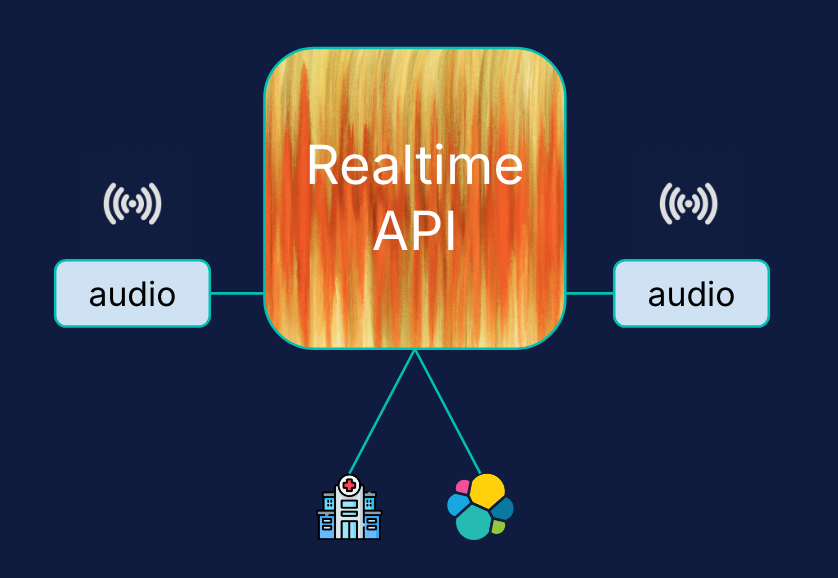
We all know that Search is critical infrastructure for working with large language models (LLMs) like OpenAI, enabling precise and efficient search capabilities to retrieve relevant data for generative AI experiences. Elastic provides a real-time Search AI Platform that complements OpenAI's Realtime API, enabling dynamic, interactive user experiences with quick and relevant hybrid search capabilities across millions of documents.
semantic_text & ELSER for semantic search
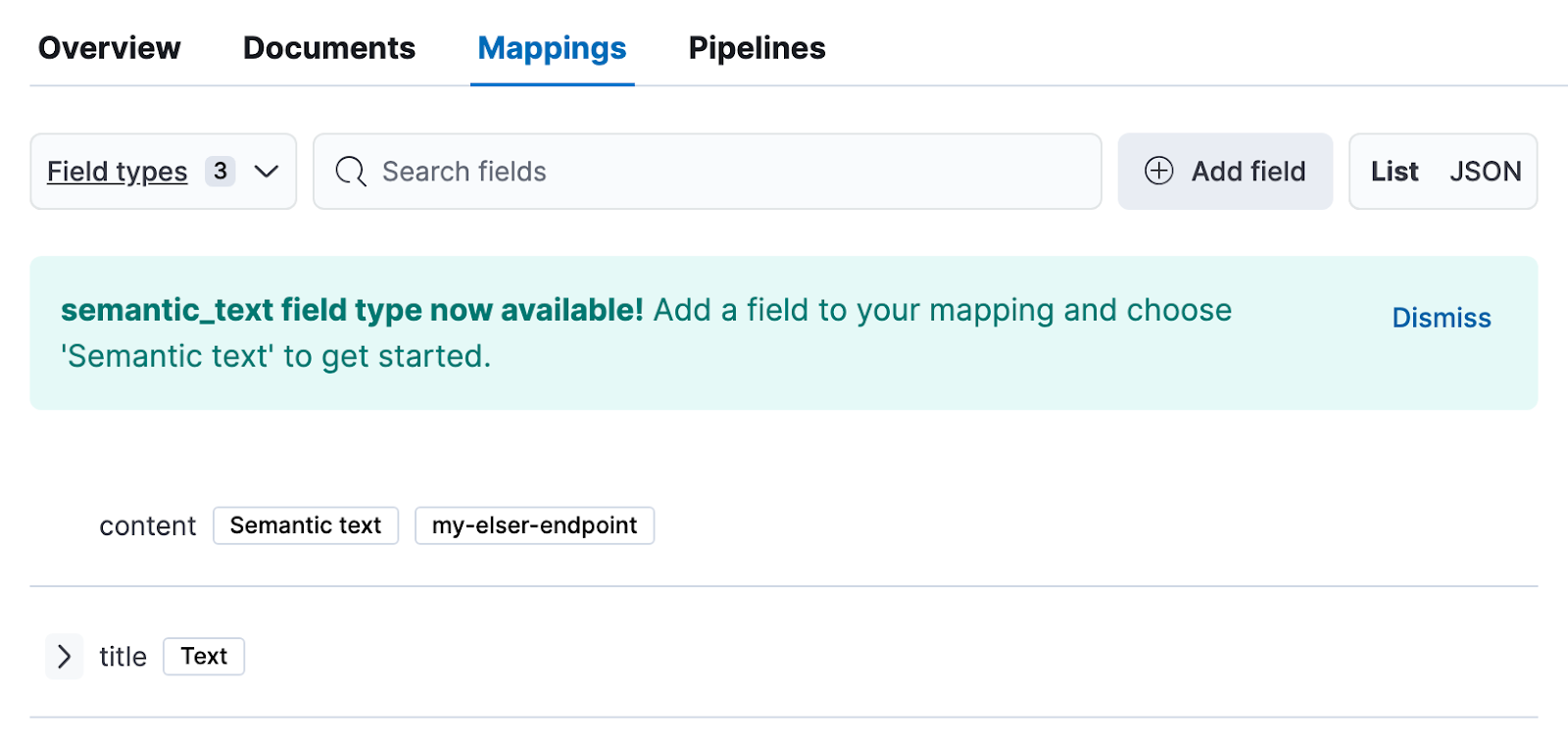
Care used semantic_text to ingest specific medical-care documents into Elastic. semantic_text automatically chunks long passages into smaller sections and generates embeddings for text chunk contents using an ELSER inference endpoint. This improves search performance and more importantly, search relevancy by only returning the most relevant chunk.
Retrievers for hybrid search
Care leveraged on Elastic’s latest retrievers made generally available in 8.16 by having multi-stage retrieval pipelines within a single _search call and integrated it to OpenAI’s Realtime API via function calling. Retrievers are built to help simplify hybrid search development for developers.
const query = {
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"nested": {
"path": "content.inference.chunks",
"query": {
"sparse_vector": {
"inference_id": "my-elser-endpoint",
"field": "content.inference.chunks.embeddings",
"query": search_term
}
},
"inner_hits": {
"size": 2,
"name": "content",
"_source": [
"content.inference.chunks.text"
]
}
}
}
}
},
{
"standard": {
"query": {
"match": {
"title": search_term
}
}
}
}
]
}
}
}In the above query, we leveraged on the Reciprocal Rank Fusion (RRF) retriever to perform a hybrid search (lexical search + ELSER sparse vector nested search). The API was made composable and flexible allowing us to build pipelines and seamlessly integrate different retrieval strategies into these pipelines. More advanced techniques such as text similarity re-ranking retrievers can also be added if necessary.
Conclusion
With the latest advancements in LLMs, we're moving beyond the boundaries of traditional text-based chatbots. Now, we can utilize and benefit from interactive speech-to-speech interfaces that can translate, understand, and interact across languages and modalities. Search remains a critical cornerstone of generative AI experiences, grounding responses with real information and helping prevent hallucinations.
Ready to try this out on your own? Start a free trial.
Elasticsearch has integrations for tools from LangChain, Cohere and more. Join our advanced semantic search webinar to build your next GenAI app!
Related content

October 23, 2025
Low-memory benchmarking in DiskBBQ and HNSW BBQ
Benchmarking Elasticsearch latency, indexing speed, and memory usage for DiskBBQ and HNSW BBQ in low-memory environments.

October 22, 2025
Deploying a multilingual embedding model in Elasticsearch
Learn how to deploy an e5 multilingual embedding model for vector search and cross-lingual retrieval in Elasticsearch.

October 23, 2025
Introducing a new vector storage format: DiskBBQ
Introducing DiskBBQ, an alternative to HNSW, and exploring when and why to use it.
September 19, 2025
Using TwelveLabs’ Marengo video embedding model with Amazon Bedrock and Elasticsearch
Creating a small app to search video embeddings from TwelveLabs' Marengo model.

September 15, 2025
Balancing the scales: Making reciprocal rank fusion (RRF) smarter with weights
Exploring weighted reciprocal rank fusion (RRF) in Elasticsearch and how it works through practical examples.